
- 1记录mac环境下,最简单的手动安装nvm方式,看完秒会_mac安装vnm
- 2Python学习---Pandas_python pandas example
- 3使用uniapp编写的微信小程序进行分包
- 4Python PyInstaller安装和使用教程(详解版)_neokylin 安装pyinstaller
- 5躺平吧,平铺的窗口「GitHub 热点速览 v.21.47」
- 6AI人工智能机器学习的类型:监督学习、无监督学习、半监督学习、增强学习和深度学习_algc技术中的机器学习类型之一是
- 7Linux下做一个简单的进度条_linux 终端进度图标
- 8Mac版sublime Text格式化json、压缩json_sublime json压缩
- 9python flask创建服务器实现文件的上传下载,已获千赞_python flask建一个服务接受上传视频和音频
- 10基于django图书管理系统_基于django的图书管理系统
rebalance的详细过程_rebalance 实现
赞
踩
Kafka 是我们最常用的消息队列,它那几万、甚至几十万的处理速度让我们为之欣喜若狂。但是随着使用场景的增加,我们遇到的问题也越来越多,其中一个经常遇到的问题就是:rebalance(重平衡)问题。
什么是消费组
要想了解 rebalance,那就得先了解消费组(consumer group)。
消费组指的是多个消费者(consumer)组成起来的一个组,它们共同消费 topic 的所有消息,并且一个 topic 的一个 partition 只能被一个 consumer 消费。
Kafka 为消费者组定义了 5 种状态,它们分别是:Empty、Dead、PreparingRebalance、CompletingRebalance 和 Stable。

了解了这些状态的含义之后,我们来看一张图片,它展示了状态机的各个状态流转。

一个消费者组最开始是 Empty 状态,当重平衡过程开启后,它会被置于 PreparingRebalance 状态等待成员加入,之后变更到 CompletingRebalance 状态等待分配方案,最后流转到 Stable 状态完成重平衡。
当有新成员加入或已有成员退出时,消费者组的状态从 Stable 直接跳到 PreparingRebalance 状态,此时,所有现存成员就必须重新申请加入组。当所有成员都退出组后,消费者组状态变更为 Empty。Kafka 定期自动删除过期位移的条件就是,组要处于 Empty 状态。因此,如果你的消费者组停掉了很长时间(超过 7 天),那么 Kafka 很可能就把该组的位移数据删除了。我相信,你在 Kafka 的日志中一定经常看到下面这个输出:
Removed ✘✘✘ expired offsets in ✘✘✘ milliseconds.
这就是 Kafka 在尝试定期删除过期位移。现在你知道了,只有 Empty 状态下的组,才会执行过期位移删除的操作。
什么是rebalance?
我们都知道 kafka 主要可以分为三大块:生产者、kafka broker、消费者。
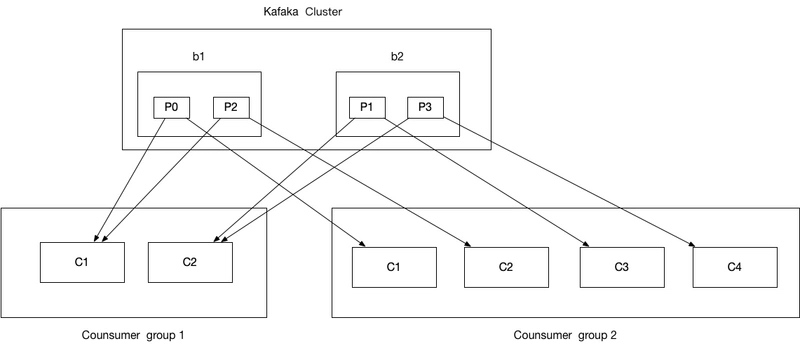
而 kafka 怎么均匀地分配某个 topic 下的所有 partition 到各个消费者,从而使得消息的消费速度达到最快,这就是平衡(balance)。而 rebalance(重平衡)其实就是重新进行 partition 的分配,从而使得 partition 的分配重新达到平衡状态。
文章首发于【陈树义的博客】,点击跳转到原文《线上Kafka突发rebalance异常,如何快速解决?》
rebalance的流程
重平衡的完整流程需要消费者端和协调者组件共同参与才能完成。我们先从消费者的视角来审视一下重平衡的流程。
在消费者端,重平衡分为两个步骤:分别是加入组和等待领导消费者(Leader Consumer)分配方案。这两个步骤分别对应两类特定的请求:JoinGroup 请求和 SyncGroup 请求。
JoinGroup请求
当组内成员加入组时,它会向协调者发送 JoinGroup 请求。在该请求中,每个成员都要将自己订阅的主题上报,这样协调者就能收集到所有成员的订阅信息。一旦收集了全部成员的 JoinGroup 请求后,协调者会从这些成员中选择一个担任这个消费者组的领导者。
通常情况下,第一个发送 JoinGroup 请求的成员自动成为领导者。你一定要注意区分这里的领导者和之前我们介绍的领导者副本,它们不是一个概念。这里的领导者是具体的消费者实例,它既不是副本,也不是协调者。这里的领导者指的是消费组(consumer group)的领导者,消费组领导者的任务是收集所有成员的订阅信息,然后根据这些信息,制定具体的分区消费分配方案。
选出领导者之后,协调者会把消费者组订阅信息封装进 JoinGroup 请求的响应体中,然后发给领导者,由领导者统一做出分配方案后,进入到下一步:发送 SyncGroup 请求。
SyncGroup请求
在这一步中,领导者向协调者发送 SyncGroup 请求,将刚刚做出的分配方案发给协调者。值得注意的是,其他成员也会向协调者发送 SyncGroup 请求,只不过请求体中并没有实际的内容。这一步的主要目的是让协调者接收分配方案,然后统一以 SyncGroup 响应的方式分发给所有成员,这样组内所有成员就都知道自己该消费哪些分区了。
接下来,我用一张图来形象地说明一下 JoinGroup 请求的处理过程。
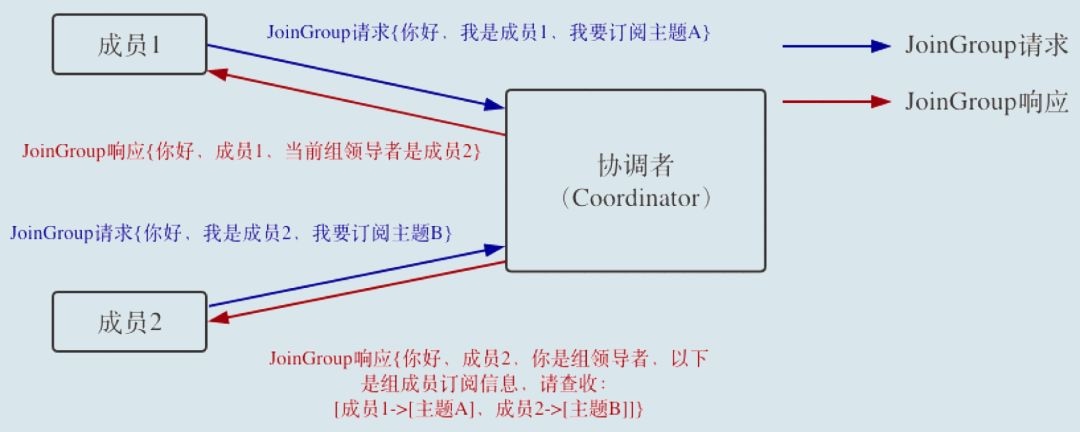
就像前面说的,JoinGroup 请求的主要作用是将组成员订阅信息发送给领导者消费者,待领导者制定好分配方案后,重平衡流程进入到 SyncGroup 请求阶段。
下面这张图描述的是 SyncGroup 请求的处理流程。

SyncGroup 请求的主要目的,就是让协调者把领导者制定的分配方案下发给各个组内成员。当所有成员都成功接收到分配方案后,消费者组进入到 Stable 状态,即开始正常的消费工作。
什么时候会发生rebalance?
前面我们已经说到,rebalance 其实就是对 partition 进行重新分配。那么什么时候会发生 rebalance 呢?其实在以下三种情况下,会触发 rebalance:
- 订阅 Topic 的分区数发生变化。
- 订阅的 Topic 个数发生变化。
- 消费组内成员个数发生变化。例如有新的 consumer 实例加入该消费组或者离开组。
订阅Topic的分区数发生变化
简单地说,就是之前 topic 有 10 个分区,现在变成了 20 个,那么多出来的 10 个分区的数据就没人消费了。那么此时就需要进行重平衡,将新增的 10 个分区分给消费组内的消费者进行消费。所以在这个情况下,会发生重平衡。
订阅的Topic个数发生变化
简单地说,一个 consumer group 如果之前只订阅了 A topic,那么其组内的 consumer 知会消费 A topic 的消息。而如果现在新增订阅了 B topic,那么 kafka 就需要把 B topic 的 partition 分配给组内的 consumer 进行消费。这个分配的过程,其实也是一个 rebalance 的过程。
消费组内成员个数发生变化
我们都知道 kafka 中是以消费组(consumer group)的方式进行消费的,消费组内的消费者共同消费一个 topic 下的消息。而当消费组内成员个数发生变化,例如某个 consumer 离开,或者新 consumer 加入,都会导致消费组内成员个数发生变化,从而导致重平衡。
相比起之前的两个情况,这种情况在实际情况中更加常见。因为订阅分区数、以及订阅 topic 数都是我们主动改变才会发生,而组内消费组成员个数发生变化,则是更加随机的。
下面我们一起分析一下「消费组内成员个数发生变化」的几种情况:
- 新成员加入
- 组成员主动离开
- 组成员崩溃
新成员加入
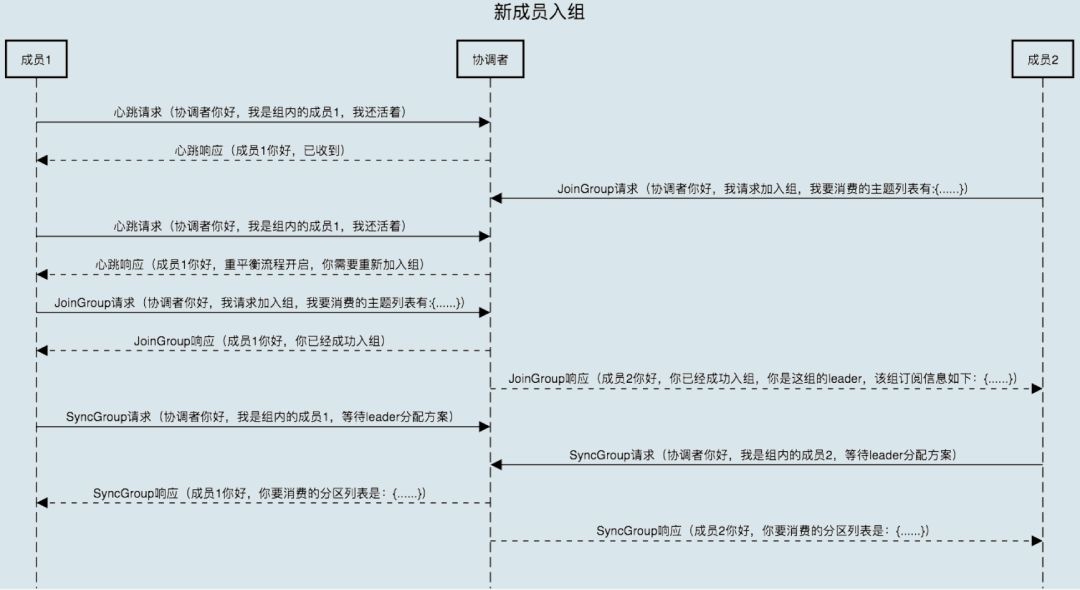
新成员入组是指组处于 Stable 状态后,有新成员加入。如果是全新启动一个消费者组,Kafka 是有一些自己的小优化的,流程上会有些许的不同。我们这里讨论的是,组稳定了之后有新成员加入的情形。
当协调者收到新的 JoinGroup 请求后,它会通过心跳请求响应的方式通知组内现有的所有成员,强制它们开启新一轮的重平衡。具体的过程和之前的客户端重平衡流程是一样的。现在,我用一张时序图来说明协调者一端是如何处理新成员入组的。
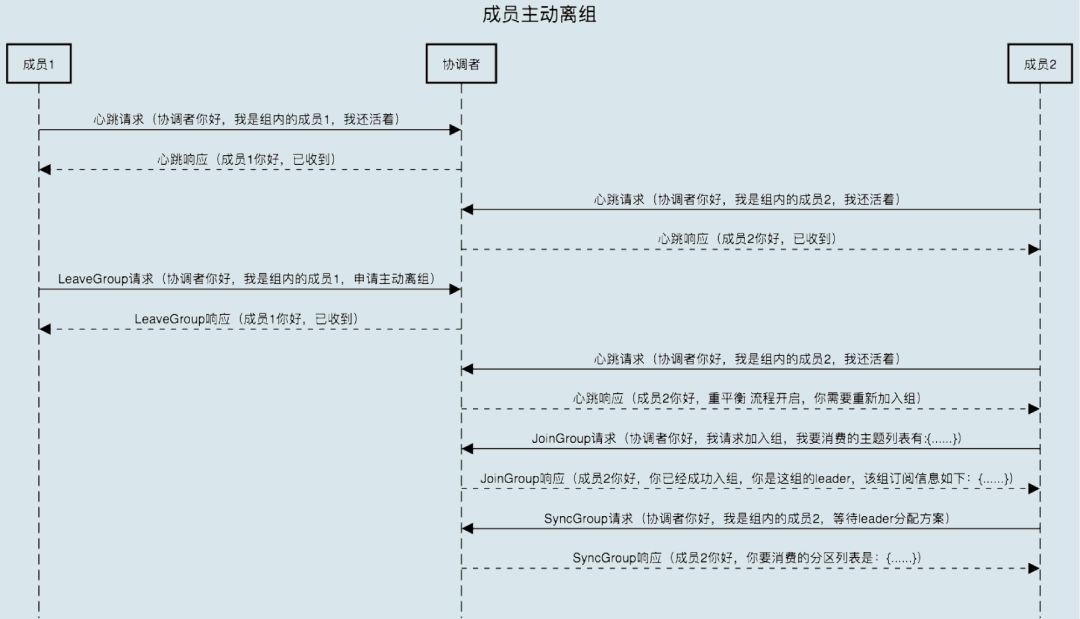
组成员主动离开
何谓主动离组?就是指消费者实例所在线程或进程调用 close() 方法主动通知协调者它要退出。这个场景就涉及到了第三类请求:LeaveGroup 请求。协调者收到 LeaveGroup 请求后,依然会以心跳响应的方式通知其他成员,因此我就不再赘述了,还是直接用一张图来说明。
组成员崩溃
崩溃离组是指消费者实例出现严重故障,突然宕机导致的离组。它和主动离组是有区别的,因为后者是主动发起的离组,协调者能马上感知并处理。但崩溃离组是被动的,协调者通常需要等待一段时间才能感知到,这段时间一般是由消费者端参数 session.timeout.ms 控制的。
也就是说,Kafka 一般不会超过 session.timeout.ms 就能感知到这个崩溃。当然,后面处理崩溃离组的流程与之前是一样的,我们来看看下面这张图。
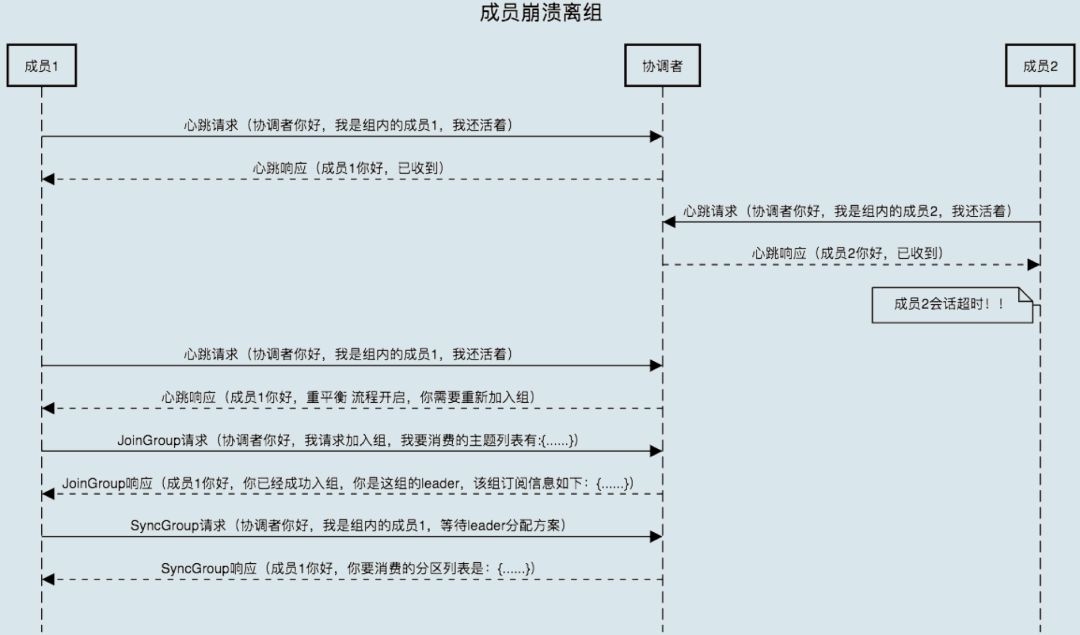
疑惑
在许多文章中,它们会加多了一个 rebalance 场景,即:「重平衡时协调者对组内成员提交位移的处理」。其实这个要说是 rebalance 场景,有点牵强。我们先来了解下这个场景究竟是什么情况。
正常情况下,每个组内成员都会定期汇报位移给协调者。当重平衡开启时,协调者会给予成员一段缓冲时间,要求每个成员必须在这段时间内快速地上报自己的位移信息,然后再开启正常的 JoinGroup/SyncGroup 请求发送。还是老办法,我们使用一张图来说明。

所以这种场景是指 rebalance 发生之时,留有时间给消费者提交 offset,并不是引起 rebalance 的触发原因(并不是因为提交 offset 引发 rebalance)。因此在我这篇文章里,我并没有将其作为 rebalance 的一种场景。
rebalance问题处理思路
前面我们讲过 rebalance 一般会有 3 种情况,分别是:
- 新成员加入
- 组成员主动离开
- 组成员崩溃
对于「新成员加入」、「组成员主动离开」都是我们主动触发的,能比较好地控制。但是「组成员崩溃」则是我们预料不到的,遇到问题的时候也比较不好排查。但对于「组成员崩溃」也是有一些通用的排查思路的,下面我们就来聊聊「rebalance问题的处理思路」。
要学会处理 rebalance 问题,我们需要先搞清楚 kafaka 消费者配置的四个参数:
- session.timeout.ms 设置了超时时间
- heartbeat.interval.ms 心跳时间间隔
- max.poll.interval.ms 每次消费的处理时间
- max.poll.records 每次消费的消息数
session.timeout.ms 表示 consumer 向 broker 发送心跳的超时时间。例如 session.timeout.ms = 180000 表示在最长 180 秒内 broker 没收到 consumer 的心跳,那么 broker 就认为该 consumer 死亡了,会启动 rebalance。
heartbeat.interval.ms 表示 consumer 每次向 broker 发送心跳的时间间隔。heartbeat.interval.ms = 60000 表示 consumer 每 60 秒向 broker 发送一次心跳。一般来说,session.timeout.ms 的值是 heartbeat.interval.ms 值的 3 倍以上。
max.poll.interval.ms 表示 consumer 每两次 poll 消息的时间间隔。简单地说,其实就是 consumer 每次消费消息的时长。如果消息处理的逻辑很重,那么市场就要相应延长。否则如果时间到了 consumer 还么消费完,broker 会默认认为 consumer 死了,发起 rebalance。
max.poll.records 表示每次消费的时候,获取多少条消息。获取的消息条数越多,需要处理的时间越长。所以每次拉取的消息数不能太多,需要保证在 max.poll.interval.ms 设置的时间内能消费完,否则会发生 rebalance。
简单来说,会导致崩溃的几个点是:
- 消费者心跳超时,导致 rebalance。
- 消费者处理时间过长,导致 rebalance。
消费者心跳超时
我们知道消费者是通过心跳和协调者保持通讯的,如果协调者收不到心跳,那么协调者会认为这个消费者死亡了,从而发起 rebalance。
而 kafka 的消费者参数设置中,跟心跳相关的两个参数为:
- session.timeout.ms 设置了超时时间
- heartbeat.interval.ms 心跳时间间隔
这时候需要调整 session.timeout.ms 和 heartbeat.interval.ms 参数,使得消费者与协调者能保持心跳。一般来说,超时时间应该是心跳间隔的 3 倍时间。即 session.timeout.ms 如果设置为 180 秒,那么 heartbeat.interval.ms 最多设置为 60 秒。
为什么要这么设置超时时间应该是心跳间隔的 3 倍时间?因为这样的话,在一个超时周期内就可以有多次心跳,避免网络问题导致偶发失败。
消费者处理时间过长
如果消费者处理时间过长,那么同样会导致协调者认为该 consumer 死亡了,从而发起重平衡。
而 kafka 的消费者参数设置中,跟消费处理的两个参数为:
- max.poll.interval.ms 每次消费的处理时间
- max.poll.records 每次消费的消息数
对于这种情况,一般来说就是增加消费者处理的时间(即提高 max.poll.interval.ms 的值),减少每次处理的消息数(即减少 max.poll.records 的值)。
除此之外,超时时间参数(session.timeout.ms)与 消费者每次处理的时间(max.poll.interval.ms)也是有关联的。max.poll.interval.ms 时间不能超过 session.timeout.ms 时间。 因为在 kafka 消费者的实现中,其是单线程去消费消息和执行心跳的,如果线程卡在处理消息,那么这时候即使到时间要心跳了,还是没有线程可以去执行心跳操作。很多同学在处理问题的时候,明明设置了很长的 session.timeout.ms 时间,但最终还是心跳超时了,就是因为没有处理好这两个参数的关联。
对于 rebalance 类问题,简单总结就是:处理好心跳超时问题和消费处理超时问题。
- 对于心跳超时问题。一般是调高心跳超时时间(session.timeout.ms),调整超时时间(session.timeout.ms)和心跳间隔时间(heartbeat.interval.ms)的比例。阿里云官方文档建议超时时间(session.timeout.ms)设置成 25s,最长不超过 30s。那么心跳间隔时间(heartbeat.interval.ms)就不超过 10s。
- 对于消费处理超时问题。一般是增加消费者处理的时间(max.poll.interval.ms),减少每次处理的消息数(max.poll.records)。阿里云官方文档建议 max.poll.records 参数要远小于当前消费组的消费能力(records < 单个线程每秒消费的条数 x 消费线程的个数 x session.timeout的秒数)。

