
- 1每天五分钟机器学习:基于梯度检验判断神经网络梯度计算的准确性_如何判定神经网络梯度可导
- 2图论之各种找环
- 3系列文章:如何利用PaddleDetection做一个完整的项目_paddledetection实战项目
- 4AES C语言实现
- 5Android基础-SharedPreferences详解_android sharedpreferences
- 6STM32内存分配解析及变量的存储位置_stm32 mmu
- 7spring-mvc底层实现-1_spring mvc基于servlet接口实现
- 8python安装tensorflow_python安装tensorflow教程
- 9Java语法学习集合
- 10Python 形参和实参,局部变量和全局变量的含义理解及使用_形参、实参、变量
对抗软件系统复杂性②:全局一致,统一隐喻
赞
踩

撰文 | 袁进辉
上一篇文章《对抗软件系统复杂性①:若无必要,勿增实体》中,我们讨论了用奥卡姆剃刀准则来对抗软件系统复杂性挑战,强调概念要精简,体现了”少即是多“(less is more) 的极简主义审美。这篇文章则要强调概念要一致、统一、普适,要抓住事物的本质,用最少的概念覆盖和解释最广泛的现象。
1
概念完整性(一致性)
软件工程的宗师Fred Brooks 提出了Conceptual Integrity(我觉得翻译成概念一致性比概念完整性更贴切),并认为这是系统设计里最核心、最重要的原则:
I will contend that conceptual integrity is the most important consideration in system design. It is better to have a system ... to reflect one set of design ideas, than to have one that contains many good but independent and uncoordinated ideas.
简言之,一致的想法要优于一批很好、但独立或无甚关联的想法。
与Fred Brooks不谋而合,Smalltalk的设计者Daniel H. H. Ingalls在讨论Smalltalk背后的设计原则时,描述了Good design的内涵:
A system should be built with a minimum set of unchangeable parts; those parts should be as general as possible; and all parts of the system should be held in a uniform framework.
这个定义非常全面,其中 最小化(minimum)是我们上一篇文章的主题,不变、稳定(unchangeable)、通用(general) 则是本文的主题。
进一步,Daniel H. H Ingalls认为实现好的设计的一个方式使用”统一隐喻“(uniform metaphor):
A language should be designed around a powerful metaphor that can be uniformly applied in all areas.
遵循概念一致性或统一隐喻,有助于程序员理解系统的一个部分就可以很轻松的理解另一个部分,会让整个系统具有统一的灵魂,浑然一体,不会在迭代演化中散架或失控。
我们能想到哪些正面的例子呢?(素材来自 Design Principles Behind Smalltalk (virginia.edu) )
Unix: 一切皆文件 (file) ,目录、设备、文件系统、命名管道和套接字等等都是基于”文件“概念;
Smalltalk: 一切皆对象 (object),以及对象之间消息传递的互动方式;
SQL: 一切数据都在表格 (table) 中,加上键值和关系约束等;
Lisp: 一切皆列表(list)
本文以统一单机和分布式深度学习中依赖引擎的编程模型为例来看看如何靠”全局一致的概念“来简化系统的复杂度。
2
共享内存 VS 消息传递
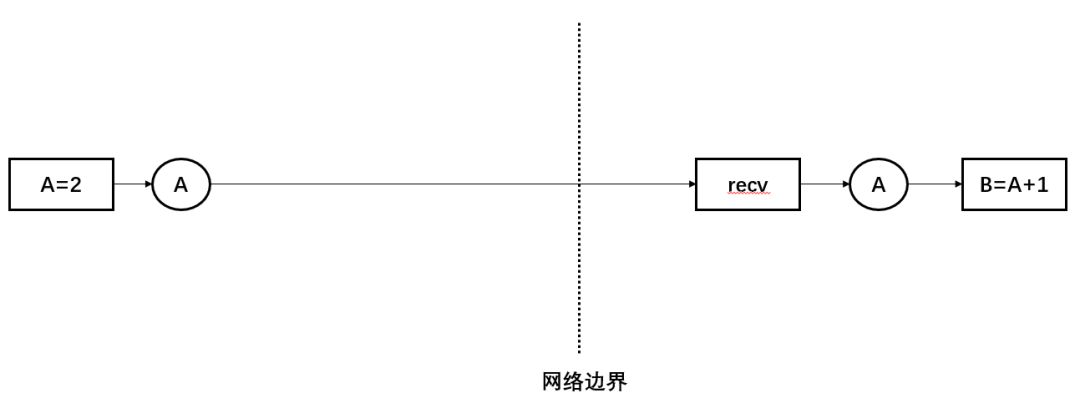
如上图所示,在上一篇文章中我们按照最小化抽象的原则得到了一个最简的分布式依赖引擎,但在这个引擎里同时存在两种并发编程模型:共享内存(shared memory model) 和消息传递(message passing model):整体的计算图按照每个算子所处的机器被分割成多个子图,每个子图内部是以一种共享内存的方式管理并发执行,子图之间是通过消息传递的方式来协调。
共享内存和消息传递是显式并发编程的两种经典模式,二者在功能上等价,实践上各有优劣,下面引用StackOverflow上的一个例子(What's the difference between the message passing and shared memory concurrency models? - Stack Overflow)来说明。
共享内存模式:多个并发模块通过异步地修改共享地址空间的数据来通信,不可避免的引入竞态条件(race conditions),可以使用锁来协调多个并发线程,共享内存模式在多线程编程模型中比较常见,使用这种模式编写高效正确的代码难度较高。
类比的例子:一堆人围着一个桌子协同工作,桌子上摆着一堆大家都可以阅读和书写的纸(数据),每个人只能通过修改桌子上的纸上的内容来和他人通信,需要避免多个人同时修改同一张纸的冲突。
消息传递模式:多个并发模块都维护自己的私有状态或数据,通过同步或异步地传递消息来通信,每个并发模块修改私有的状态或数据不需要加锁,只有消息队列需要加锁,消息传递的代码通常比较容易理解和维护,在分布式场景比较常见,在一些现代编程语言原生支持,譬如Go。
类比的例子:一堆人围着一个桌子协同工作,每个人面前都有一堆纸,每个人只能修改自己面前的那堆纸,当别人需要修改这张纸上的内容时,上一个占有这张纸的人必须把纸当作“消息”交给下一个人,这样就避免了多个人同时修改一张纸的麻烦。
3
如何统一编程模型?
在分布式深度学习框架里,如果能把机器内部和跨机器的依赖引擎机制进行统一,会降低系统的复杂度和用户的认知负担。
根据机器内部和跨机器分别采用共享内存还是消息传递的所有情况进行枚举,得到不同的系统设计:
a、机器内部和跨机器全部使用共享内存模式
b、机器内部和跨机器全部使用消息传递模式
c、机器内部使用共享内存模式,跨机器使用消息传递模式
d、机器内部使用消息传递模式,跨机器使用共享内存模式
哪种方式最合适呢? 可能需要考虑这两个因素:
1、抽象机器内部的依赖时,直接使用系统提供的多线程及锁等机制,共享内存模式比较直接;抽象跨机器的依赖时,使用消息传递比较自然。这也是现在绝大多数深度学习框架的选择,即方案c,而与此完全对立的方案d直接出局。
2、抽象跨机器的依赖时,消息传递模式比共享内存模式更加自然,如果要使用共享内存模式就需要实现分布式共享内存的语义(有点类似于参数服务器或者Key-value store)。虽然方案a也统一了机器内部和跨机器的机制,但在抽象跨机器依赖时不自然。
综合来说,是方案b和方案c的竞争,焦点是:机器内部的依赖引擎到底是倾向于共享内存还是消息传递?
4
为何青睐消息传递?
消息传递模式带来的好处主要是模块化(modularity),这种思维方式迫使程序员把状态或资源的所有权(ownership) 想清楚,每个模块只能修改自己拥有的数据和状态,而没有权限修改别的模块拥有的数据,因此不需要关注与当前模块无关的事情,很好的体现关注点分离(separation of concern)的准则,大大降低了并发编程的门槛。
很多人听到过Go语言设计者Rob Pike的一句话:
Do not communicate by sharing memory; instead, share memory by communicating.
他清晰的表明了自己的观点:在并发编程中,消息传递模式比共享内存模式更优。类似于Go的现代编程语言,为了降低并发编程的难度,提供给开发者的编程模型就是消息传递,而不是共享内存。
C++语言并没有提供内在的消息传递编程模式,不过基于消息队列来支持这个需求非常简单,譬如在OneFlow中仅仅借助有锁队列Channel类就实现了多线程消息传递机制。
消息传递模式不仅仅在分布式计算场景非常自然,在单机多线程场景也有抽象简单且正确性易保证的好处。统一机器内部和跨机器的依赖引擎机制之后,整个系统的理念非常容易理解,实现足够巧妙的话,在概念上不需要考虑单机或分布式的区别,整个分布式系统浑然一体,可以使用“最短的文字描述”就可以把系统的原理解释清楚。
5
Actor-based或Channel-based?
Sharing by communicating 有两种思路,一种是是以对象为中心的,即actor model,还有一种是基于通道(channel)为中心的,基于Communicating sequential processes (CSP)理论的,在业界都有很广泛的应用。
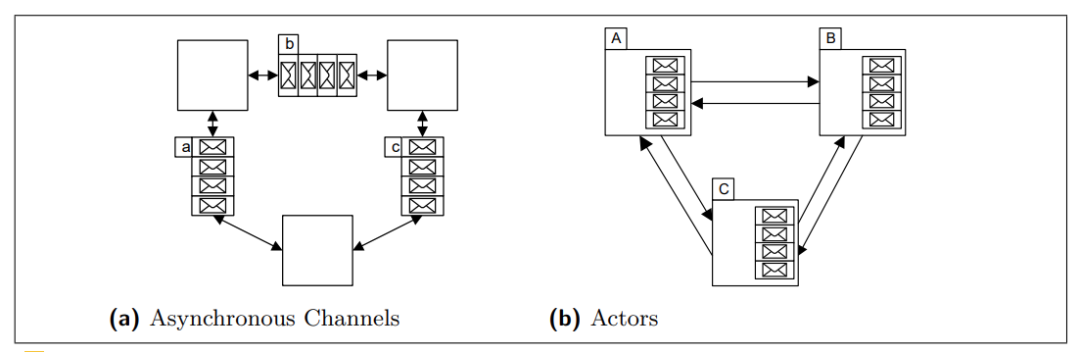
以通道为中心的抽象提供了channel的概念,需要通信的双方通过send和recv操作来向channel中放(put)消息和取(get)消息,同一个channel可以被不同的对象使用,典型的代表是Go语言,提供了内生的通道对象。
在以对象为中心的抽象中,每个actor有自己专属的信箱(mailbox),如果某一个对象要向另一个对象发消息,必须知道接收方的地址才行,典型的代表是Erlang语言,提供了actor的编程模型,一些新的语言,譬如Swift也内生地支持了actor模型。
具体到分布式深度学习框架领域,我们应该选择哪一个思路呢?
我的理解是,如果目的是提供一套基础设施供上层调用,一般是使用channel抽象,因为这个底层基础设施并不知道未来怎么被使用,无法对未来的通信对象进行抽象。这方面的例子包括,TCP/IP的socket模型,ZeroMQ编程库,Go channel 。最近PyTorch为了更好支持分布式场景,也开发了一个TensorPipe库,也是基于channel抽象。
如果是开发一个具体的软件解决方案,当对通信的对象有非常清楚的理解时,可能actor抽象更合适,因为在这样的问题中,除了要解决消息传递问题,更重要的是模块化,提炼出来通信的对象是什么,每个对象有什么样的状态和行为,这些信息都不是channel可以解决的,反而不得不用actor模型来支持。
当然,以上原则并不是绝对的,底层被调用的库也可以使用actor,譬如在基础库里提供一个基类,未来的上层应用从这个基类派生即可;在开发具体的解决方案时,即使对通信对象有清楚的理解,也可以使用channel抽象。
在深度学习框架里,每个op或子图具有自己的状态、资源和行为,我们需要对这些属性进行抽象,使用actor模型就再合适不过了。
actor模型和面向对象编程(OOP)一脉相承,图灵奖得主Alan Kay是OOP的先驱,他认为messaging是比object更本质更重要的思想:
I'm sorry that I long ago coined the term "objects" for this topic because it gets many people to focus on the lesser idea. The big idea is "messaging".
Joe Armstrong发明了Erlang,一种面向并发编程的语言,Erlang语言内生支持了actor机制,他认为面向并发的编程语言应该包含的核心要素包括(列表有删减):
1、一切皆进程(这里的进程不同于操作系统课程里的概念,可以理解成actor)
2、消息传递是进程交互的唯一方式
3、每个进程有唯一的名字(地址)
4、若知道进程的名字,就可以向它发消息
5、进程之间不共享资源
Swift自5.5版本之后内置了actor机制。
OneFlow从设计之处就选用了actor模型,也是业界首个使用这种理念设计的深度学习框架。经常被问到,为什么OneFlow要使用actor模型,actor到底有什么好处。我们的体会是,actor作为用户级线程除了带来效率上的好处,更重要是带来抽象上的简洁性和一致性。
6
Actor在OneFlow里的应用
之前OneFlow小伙伴儿已经写过几篇博客介绍OneFlow的actor机制,这里不再赘述,仅简要介绍其基本原理。
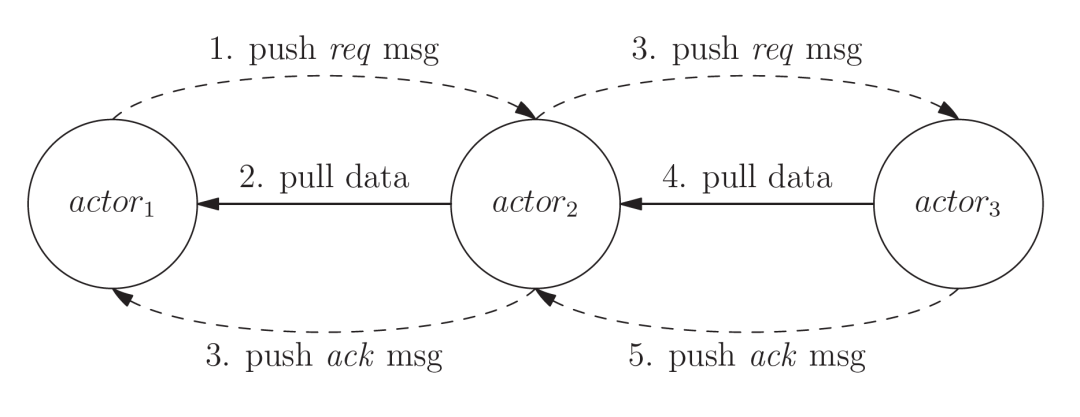
每个op(也可以是op构成的子图)被一个actor所管理,actor可以理解成op之外的一层薄薄的wrapper,用来管理op的状态(依赖条件),op是这个actor的动作(action)。当一个op执行完毕时,管理该op的actor会给需要消费这个op输出数据的actor发送req消息(消息仅包含指向数据的指针,真实数据不用放在消息体,因此消息非常轻量级),通知消费者新的数据就绪了,消费者收到消息后会更新依赖条件的计数器(状态),如果满足所管理op的触发条件,就会启动相应的op,这个op在执行的时候再去读取生产者的数据,当读取完毕会给生产者发送ack消息,通知生产者可以把该数据的内存回收。
在上图的例子中,actor1生产的数据被actor2消费,actor2生产的数据被actor3消费。值得注意的是,这个消息传递协议既适用于属于同一个机器的actor,也适用于跨机器的actor,无论生产者和消费者是否在同一台机器上,都是通过上面描述的逻辑来运转,在actor抽象层次上,二者并没有什么区别。
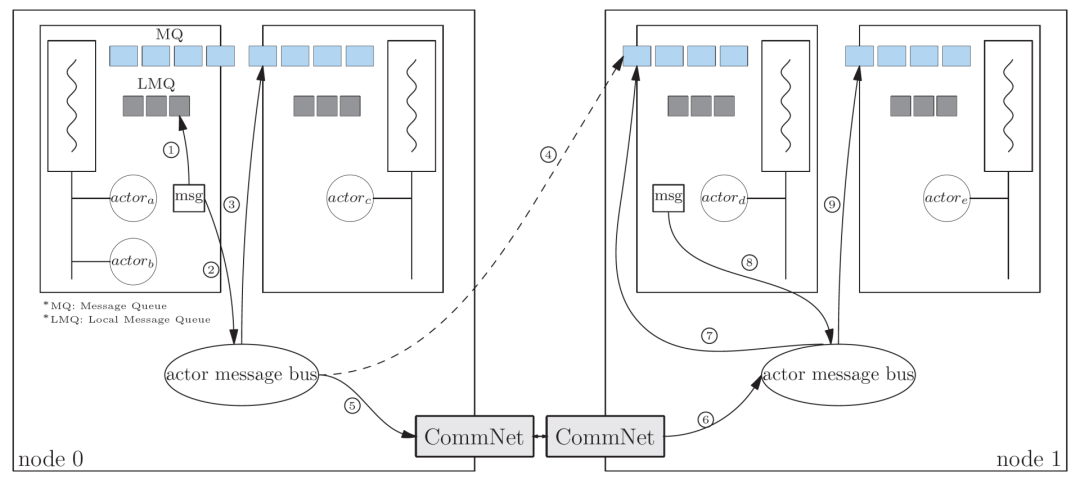
上图展示了运行在两台机器上的一个actor系统,actor类似于用户级线程,具有相同设备上下文的actor会被绑定到相同的内核线程上。
如上图的箭头1所示,在同一个内核线程上的actor之间发送消息可以走快速通道(local message queue,LMQ),譬如actor_a 和 actor_b之间的消息。
如上图的箭头2和箭头3所示,同一机器上不同线程上的actor之间发送消息,需要通过actor message bus路由,譬如actor_a和actor_c之间的消息。
如上图的箭头4所示,actor_a 向 actor_d(actor_d 管理了负责数据搬运的recv op)发送消息时从抽象上是按箭头4的虚线进行的,当然跨机器的实际传递路径是通过箭头5,6,7来实现的,但5,6,7这个路径对actor系统来说是透明的,跨越机器的消息传递和机器内部的消息传递在抽象层次并无二致。
7
分布式深度学习框架的最小抽象
除了本文讨论的用消息传递统一单机和分布式依赖引擎,概念一致性的原则在OneFlow的设计里实际上无处不在,譬如:
1、搬运和计算的一致:通过数据搬运为一等公民的理念,把数据搬运也全部抽象成op,数据搬运和计算的调度机制完全一致。
2、单机和分布式的一致:如上文讨论的,通过消息传递机制,统一了单机器和分布式的依赖引擎,而不是像其它框架一样有两套编程模式并存。
3、调度粒度的一致:actor 作为一种用户级线程,支持了全链路异步,便于线程资源的静态规划。
4、信息传递协议的一致:actor之间的工作协议具有清晰的规定,即生产者向消费者发送(Push) req消息,消费者读取 (Pull)生产者的数据并向生产者发送ack消息等。
5、编译时和运行时的一致:编译器从逻辑图生成的执行计划(execution plan)由一系列task构成,task就是actor在编译阶段的对应物,OneFlow保证编译时的task和和运行时的actor一一对应。因此,只要分析执行计划就可以对运行时的全部信息。
基于以上设计思想,OneFlow可能是分布式深度学习框架的最简抽象,也是从架构上最容易理解的深度学习框架,我们认为这也是对硬件厂商最友好的抽象,大大降低了实现分布式深度学习的难度,硬件厂商只需要开发单设备计算库、通信库,就可以借助OneFlow实现最强大的分布式深度学习功能。
8
actor在深度学习领域的其它应用
传奇芯片架构师Jim Keller最近的一篇采访介绍了他们团队为AI芯片实现的软件栈TensTorrent,从描述上和消息传递机制非常相似。
we have a really nice abstraction in the hardware that says (i) do compute, (ii) when you need to send data to put the data in the pipe, (iii) when you push it in the pipe, the other end pulls it out of the pipe. It's very clean. That has resulted in a fairly small software team, and software you can actually understand. (消息传递,pipe类似于channel)
Then when we hook up multiple chips, the communication on a single chip compared to the communication from chip to chip is not any different at the software layer. So while the physical transport of data is different on-chip with a NOC versus off-chip with Ethernet, the hardware is built so that it looks like it is just sending data from one engine to another engine - the software doesn't care. The only thing that does is the compiler, which knows the latency and bandwidth is a little different between the two.(芯片内和芯片间通信间一致的抽象,与本文的理念异曲同工)
值得注意的是,其它框架也开始跟进实现actor模型,例如华为的Mindspore。
PyTorch最近为支持分布式深度学习引入了很多新的设计,其中很大的一个变化是引入底层通信库TensorPipe,这是一种更接近channel的抽象,不过它仍只用在底层通信里,而不是作为计算图层次的抽象使用的,譬如TensorPipe被作为PyTorch的RPC的底层机制。我认为这种不彻底的用法是囿于PyTorch的动态图设计。
actor机制只适合于静态图模式,只有静态图里,生产者和消费者才有固定的地址,生产者才知道它下游的消费者有哪些,才能通过消息来通信。而动态图模式,每个操作仅能知晓历史,不能看到下游的消费者,也就无法使用这种机制。
动态图是一种增加用户体验必不可少的手段,不过一旦越过了”编写和调试模型“这个阶段,部署、训练、AI芯片角度看,都更喜欢静态图。PyTorch也在强化其静态图以及动态图和静态图的转换机制,我们预计PyTorch迟早也会向actor这种机制演化。
9
结语
OneFlow在追求效率上的极致,但并没有为效率牺牲抽象,相反,对简洁抽象的追求超越于对效率的追求,高效率只是极简系统的一个自然结果,简洁的抽象可以认为是OneFlow更加本质的优势。
在过去的一系列博客中,我们看到了OneFlow如何用actor最小化分布式深度学习系统的抽象:统一了计算和数据搬运、单机和分布式、资源调度粒度、信息传递协议、编译时和运行时的基本单位。
我们喜欢简单的设计,正如我们相信,复杂的本质是简单,纷繁复杂的世间万物背后一定有一种简洁、优雅、一致的原理在支配其运行。
程序员是软件系统的”造物主“,如果以一种漫不经心的方式去构建这个复杂的系统,可能会被自己的作品打败,失去控制;而经过深思熟虑,以一套简洁一致的世界观来架设这个复杂的系统,就会游刃有余,一切尽在掌控中,并最大化的对未知需求开放。
具体到分布式深度学习框架,极简系统更大的优势在于:灵活和通用,一套普适的机制,支持有类似需求的新模型时开发效率更高,免去为新需求定制的苦恼。
注:题图源自Pixabay
其他人都在看
点击“阅读原文”,欢迎下载体验OneFlow新一代开源深度学习框架



