- 1MATLAB中求解双重积分函数_matlab求解都是参数的双重积分
- 2Windows本地部署Ollama+qwen本地大语言模型Web交互界面并实现公网访问_ollama qwen
- 3python 使用plt画图,解决图片有白边的问题_如何让plt输出的图片没有白边
- 4Verilog Tutorial(2)数据类型和数组简介_verilog 数组
- 5一级造价工程师(安装)- 案例笔记_不平衡报价一定要控制在合理幅度内,为避免引起业主反对,一般可在()以内
- 6pgsql之查看主备复制延迟_pg如何查看主从复制延迟
- 7法律常识(四)消费者权益保护法
- 8【论文阅读笔记】人群计数(Crowd Counting)| 密集群体分析
- 9USB控制器接口手动传递(XHCI Hand Off)的含义及编程实现_xhci hand off什么意思
- 10麒麟V10安装OPenGauss数据库_麒麟操作系统安装opengauss
Linux中进程的创建过程_分析linux进程创建的过程
赞
踩
在终端上运行一个程序main
首先,bash作为一个父进程,运行起来的程序是bash的子进程。
即,当我们在终端输入./main 运行一个可执行程序,bash会调用一个名为fork()系统调用,然后陷入内核,CPU执行内核态的sys_fork()函数,而sys_fork()函数中调用了do_fork(),其中do_fork()会创建一个task_struct,然后将该task_struct加入到内核维护的进程的双向链表中。
然后,fork()调用结束,子进程诞生了,但是fork()做的是复制父进程,实际上我们当然不是期望父进程和子进程执行的指令和数据一模一样了,我们期望的是子进程执行自己的数据和指令,即main可执行程序的数据和指令。
然后,子进程调用exec()族函数,继续陷入内核,执行sys_execve(),调用load_elf_binary()将main的存放在磁盘的数据和指令加载到内存中。
最终,真正意义上main进程诞生了,此时的子进程真正执行的是main的数据和指令。
Linux系统调用 sys_fork()过程
-
用户态调用
fork(),出发系统调用,CPU转向内核,执行内核态的代码; -
通过查询系统调用表,找到内核的
sys_fork()函数,进行调用; -
而
sys_fork()实际上调用的是do_fork(),该函数做的事情较多:从slab分配器中分配一个task_struct实例
分配创建内核栈,并拷贝父进程内核栈,设置thread_info,特别的,父进程在陷入内核前,保存了的上下文也会被子进程进行拷贝,也就是说,如果系统调用结束,父进程和子进程返回用户 态时,返回的位置,以及执行的指令是一样的,有过多进程编程经验的朋友知道,父进程调用fork()创建子进程后,子进程和父进程的返回值不一样,但是都是从fork()函数位置返回的,这就是为什么看起来好像"一个函数可以返回两次一样",其实到了这里,fork()函数已经是两个进程中的函数了,不存在一个函数返回两次的问题。
copy_creds,拷贝父进程的权限
设置进程运行统计信息
sched_fork,设置进程调度相关信息,如将状态设置为TASK_NEW
复制父进程打开文件的信息
复制父进程文件目录信息
复制父进程信号相关信息
copy_mm 复制父进程内存管理信息
配置PID
建立进程间的亲缘关系
将上述task_struct进入到进程的双向链表中
(我们从上述过程可以看出,子进程的信息绝大部分拷贝自父进程,这样做实际上为了提高性能,因为task_struct中记录进程所有的信息,如果一个一个创建和分配的话势必会拉低整个系统效率,Linux惯用做法是COW)
- 唤醒新进程,将进程状态设置为TASK_RUNNING,将task_struct放入到调度队列,等待CPU的调度执行
- 系统调用结束,将返回用户空间,子进程和父进程内核栈一样,包括指令寄存器中的值都是一致的,同时指向的是fork()。但是子进程和父进程返回值不同,如果是父进程,返回值是子进程PID,如果是子进程返回,PID==0。我们都是通过返回值的不同,来区分父子进程接下来各自的指向路线。由于这个过程子进程继承了父进程几乎所有的东西,我们一般希望子进程做与父进程不一样的事情,所以一般fork()都搭配着exec()来使用,替换掉子进程的数据和指令,从而达到改变子进程行为的目的
Linux系统调用sys_execevp()过程
-
用户态调用库函数
execevp()方法 -
发生系统调用,陷入内核,查找系统调用表,调用
sys_execevp()方法 -
sys_execevp()中会调用load_elf_binary()方法,该过程主要分为以下几个过程:设置mmap_base的值
设置函数栈的 vm_area_struct
将ELF文件中的代码部分映射到内存中
设置堆的brk以及堆 vm_area_struct
将依赖的so映射到内存中的内存映射区域
设置mm_struct其他属性,如
end_code,start_code,start_data,end_data等
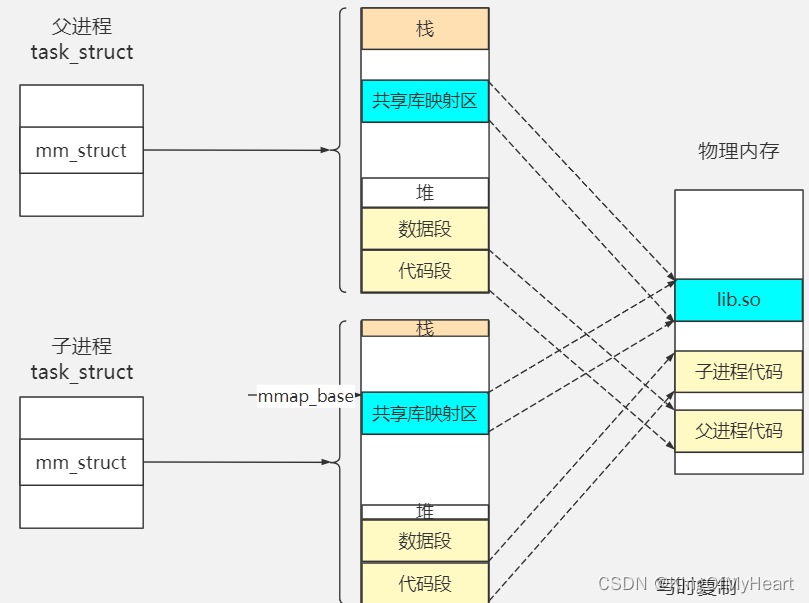
关注父子进程之间的内存关系
上面说到,子进程的虚拟地址空间完全和父进程的虚拟地址空间一样,都是映射到同一部分的物理内存上的。
fork()函数调用完成时,子进程和父进程共享同一份数据和指令。
当exec()系列函数调用后,替换掉子进程的代码和数据后,子进程就有了自己的一份代码,如下图: