
热门标签
热门文章
- 1Java Map接口 - HashMap类
- 2小程序获取图片大小
- 3Mongodb入门--头歌实验MongoDB 实验——数据库优化
- 4深度学习常见的三种模型_深度学习几个模型介绍
- 5ssh-keygen(linux 命令) 创建 private key(私钥) , public key (公钥),实现ssh,scp,sftp命令无密码连接
- 6GpuMall智算云:AUTOMATIC1111/stable-diffusion-webui/stable-diffusion-webui-v1.8.0_xformers 0.0.23.post1
- 7Python知识点14---被规定的资源_在python类的内部,使用def关键字可以定义属于类的方法,这种方法需要使用{ }
- 8数据结构与算法要点总结(4):数组、矩阵、字符串、广义表
- 9Ubuntu22.04安装WordPress教程(利用nginx环境和MariaDB数据库,安装使用WordPress)_ubuntu 22.04安装wordpress
- 10PyTorch使用tensorboard的SummaryWriter报错
当前位置: article > 正文
机器学习中常见的数据分析,处理方式(以泰坦尼克号为例)_数据集及分析处理
作者:从前慢现在也慢 | 2024-06-04 09:08:33
赞
踩
数据集及分析处理
读取数据
查看数据各个参数信息
查看有无空值
如何填充空值
一些特殊字段如何处理
读取数据
train=pd.read_csv('train.csv')
test=pd.read_csv('test.csv')
datas = pd.concat([train, test], ignore_index = True)
# 获取数据集
- 1
- 2
- 3
- 4
查看数据中的参数信息
我们可以使用head函数比如使用train.head()就可以查看到训练集中的数据,默认前五行
- 1
train.head()
- 1
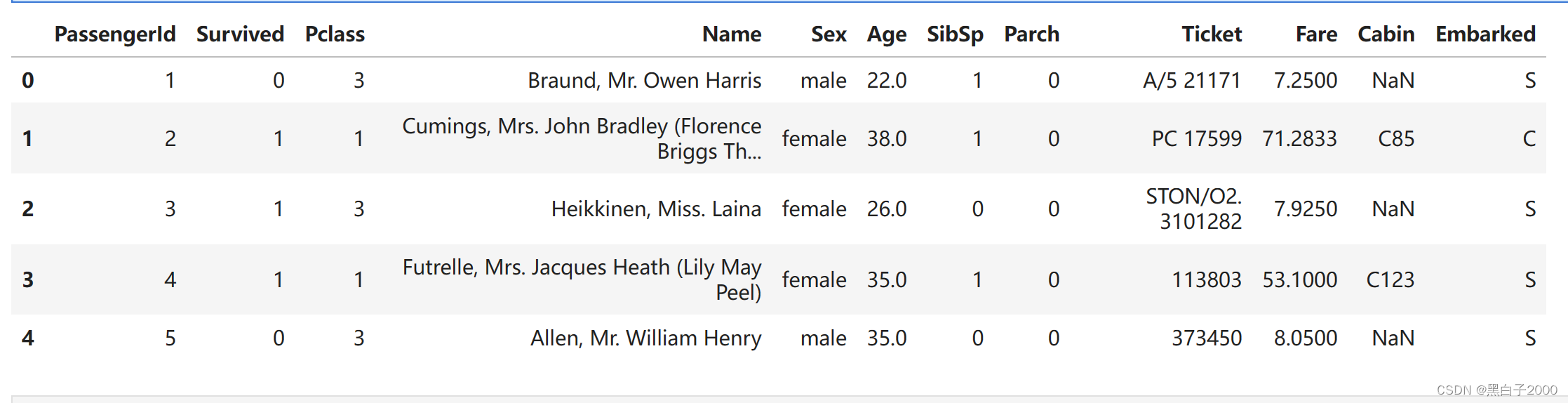
我们可以使用shape函数比如使用train.shape就可以查看到训练集中行列数量
train.shape
#(891, 12)891行,12列
- 1
- 2
我们可以使用info函数比如使用train.info()就可以查看到数据中,每一行的类型和空行
train.info()
- 1
- 2
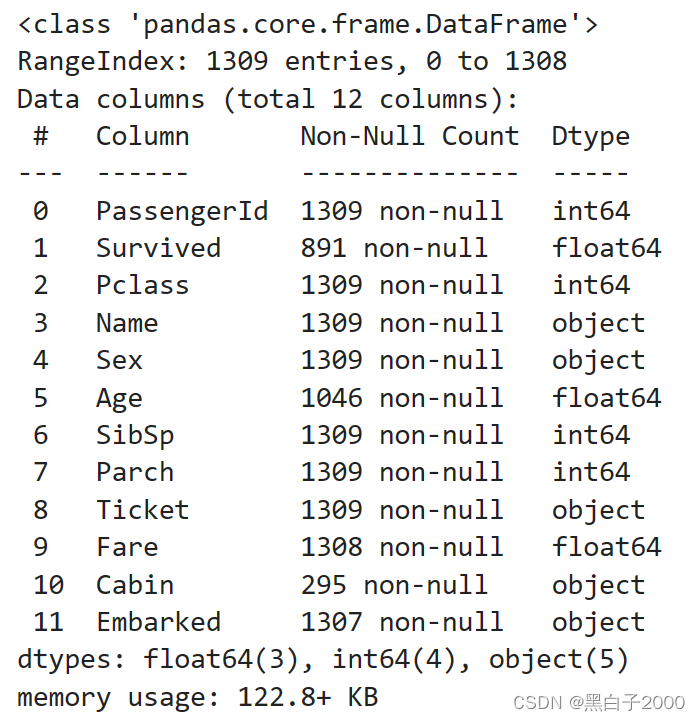
由以上数据可以看出Age,Fare,Cabin,Embarked,几列中数据有空值,应进行相应的填充
- 填充情况当填充目标缺失很多时,建议直接删除
- 当填充对象不多的时候,如果目标时数字型,如年龄,身高,价格,可以用中位数,或者众数,平均值。如果对象很重要建议使用随机森林构建模型预测填充。
- 如果填充值是字符型缺失了一部分,不多也不少,建议将缺失的一部分单独设置为一类。
实操
通过info获知了那些列是空的,因此我们要把空列中的那些行查出,方便后续操作。
# Embarked 填充港口参数
# 查看港口那一列空值行
datas[datas['Embarked'].isnull()]
- 1
- 2
- 3

具体问题具体分析
根据人员信息看出,是两名女性,船票是一等票,建议填充为存活率高的港口分类。
#填充数据集中Embarked列的空白行为C
datas['Embarked'] = datas['Embarked'].fillna('C')
- 1
- 2
- 3
年龄问题
首先寻找特征,使用目标对象的年龄,性别,船票,训练一个模型,然后有那个模型
from sklearn.ensemble import RandomForestRegressor
ages = datas[['Age', 'Pclass','Sex']]
ages=pd.get_dummies(ages)
known_ages = ages[ages.Age.notnull()].values
unknown_ages = ages[ages.Age.isnull()].values
y = known_ages[:, 0]
X = known_ages[:, 1:]
rfr = RandomForestRegressor(random_state=60, n_estimators=100, n_jobs=-1)
rfr.fit(X, y)
pre_ages = rfr.predict(unknown_ages[:, 1::])
datas.loc[ (datas.Age.isnull()), 'Age' ] = pre_ages
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
重新划分数据集
从中取出关键列,或者认为构建的关键列
axis默认为0代表行,axis=1则使用列
#合并两个集合 datas=pd.concat([train, test]) #从集合中取出关键的列,有些是人为构建的 datas=datas[['Survived','Pclass','Sex','Age','Fare','Embarked','Title','Fam_type','Board','Ticketlabels']] #将类别数据转换为向量 datas=pd.get_dummies(datas) #train是有存活数据的数据集 train=datas[datas['Survived'].notnull()] #test是没有没有存活信息的数据集,并且删除掉Survived那一列 test=datas[datas['Survived'].isnull()].drop('Survived',axis=1) # X的值不包含第0列,从第一列开始到后面的所有列 X = train.values[:,1:] # y仅有一列,就是Survived 第0列,用作模型的训练 y = train.values[:,0] #fit(X,y) #训练的数据是X,验证的结果集是y

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
如何删除含有空白值的行
如果数据集非常大,而这些缺失项很少,建议直接删除,该行
datas.dropna(axis=0, how='any')
- 1
根据条件删除一些行
从train数据集中删除票价大于的行
train = train.drop(index= train[train.Fare>= 700].index, axis=0)
- 1
查看特征和标签的相关性
train.corr()['Survived']
- 1
- 2
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/671162
推荐阅读

相关标签

