
- 1C#中Winform使用OpenFileDialog选择文件打开并获取文件路径_通过openfiledialog选择文件路径
- 2react项目内存溢出,加大内存的方式之一 Ineffective mark-compacts near heap limit Allocation failed - JavaScript heap_vscode的react项目内存溢出
- 3Redis实现分布式锁的原理:常见问题解析及解决方案、源码解析Redisson的使用_分布式事务redis解决方案
- 42024永久免费版CrossOver软件下载及使用方法详细的步骤_crossover安装包
- 5guitar pro 8许可证忘记了怎么办 guitar pro8谱数字可以改吗
- 6基于微信学生新生报到小程序系统设计与实现
- 7ROS Motion Planning运动规划库安装方法及进阶使用方法详细介绍
- 8pom可视化idea_GitHub - haizlin-idea/rsbi-pom: 睿思BI-数据仪表盘,开源商业智能,数据可视化系统...
- 9在CDH集群安装Flink
- 10单片机学习笔记---独立按键控制LED亮灭_单片机按键控制led灯亮灭
2024年大数据最新MobileNet实战:tensorflow2(7)
赞
踩
-
分别从file_pathList和labels,得到图片的路径和对应的label
-
如果是训练就训练的transform,如果不是就执行验证的transform。
-
resize图片
-
将image转数组
-
将图像和label分别放到input_samples和input_labels
-
将list转numpy数组。
-
返回一次迭代
def generator(file_pathList,labels,batch_size,train_action=False):
L = len(file_pathList)
while True:
input_labels = []
input_samples = []
for row in range(0, batch_size):
temp = np.random.randint(0, L)
X = file_pathList[temp]
Y = labels[temp]
image = cv2.imdecode(np.fromfile(X, dtype=np.uint8), -1)
if image.shape[2] > 3:
image = image[:, :, :3]
if train_action:
image=train_transform(image=image)[‘image’]
else:
image = val_transform(image=image)[‘image’]
image = cv2.resize(image, (norm_size, norm_size), interpolation=cv2.INTER_LANCZOS4)
image = img_to_array(image)
input_samples.append(image)
input_labels.append(Y)
batch_x = np.asarray(input_samples)
batch_y = np.asarray(input_labels)
yield (batch_x, batch_y)
ModelCheckpoint:用来保存成绩最好的模型。
语法如下:
keras.callbacks.ModelCheckpoint(filepath, monitor=‘val_loss’, verbose=0, save_best_only=False, save_weights_only=False, mode=‘auto’, period=1)
该回调函数将在每个epoch后保存模型到filepath
filepath可以是格式化的字符串,里面的占位符将会被epoch值和传入on_epoch_end的logs关键字所填入
例如,filepath若为weights.{epoch:02d-{val_loss:.2f}}.hdf5,则会生成对应epoch和验证集loss的多个文件。
参数
- filename:字符串,保存模型的路径
- monitor:需要监视的值
- verbose:信息展示模式,0或1
- save_best_only:当设置为True时,将只保存在验证集上性能最好的模型
- mode:‘auto’,‘min’,‘max’之一,在save_best_only=True时决定性能最佳模型的评判准则,例如,当监测值为val_acc时,模式应为max,当检测值为val_loss时,模式应为min。在auto模式下,评价准则由被监测值的名字自动推断。
- save_weights_only:若设置为True,则只保存模型权重,否则将保存整个模型(包括模型结构,配置信息等)
- period:CheckPoint之间的间隔的epoch数
ReduceLROnPlateau:当评价指标不在提升时,减少学习率,语法如下:
keras.callbacks.ReduceLROnPlateau(monitor=‘val_loss’, factor=0.1, patience=10, verbose=0, mode=‘auto’, epsilon=0.0001, cooldown=0, min_lr=0)
当学习停滞时,减少2倍或10倍的学习率常常能获得较好的效果。该回调函数检测指标的情况,如果在patience个epoch中看不到模型性能提升,则减少学习率
参数
- monitor:被监测的量
- factor:每次减少学习率的因子,学习率将以lr = lr*factor的形式被减少
- patience:当patience个epoch过去而模型性能不提升时,学习率减少的动作会被触发
- mode:‘auto’,‘min’,‘max’之一,在min模式下,如果检测值触发学习率减少。在max模式下,当检测值不再上升则触发学习率减少。
- epsilon:阈值,用来确定是否进入检测值的“平原区”
- cooldown:学习率减少后,会经过cooldown个epoch才重新进行正常操作
- min_lr:学习率的下限
本例代码如下:
checkpointer = ModelCheckpoint(filepath=‘best_model.hdf5’,
monitor=‘val_accuracy’, verbose=1, save_best_only=True, mode=‘max’)
reduce = ReduceLROnPlateau(monitor=‘val_accuracy’, patience=10,
verbose=1,
factor=0.5,
min_lr=1e-6)
model = Sequential()
model.add(InceptionV3(include_top=False, pooling=‘avg’, weights=‘imagenet’))
model.add(Dense(classnum, activation=‘softmax’))
optimizer = Adam(learning_rate=INIT_LR)
model.compile(optimizer=optimizer, loss=‘sparse_categorical_crossentropy’, metrics=[‘accuracy’])
history = model.fit(generator(trainX,trainY,batch_size,train_action=True),
steps_per_epoch=len(trainX) / batch_size,
validation_data=generator(valX,valY,batch_size,train_action=False),
epochs=EPOCHS,
validation_steps=len(valX) / batch_size,
callbacks=[checkpointer, reduce])
model.save(‘my_model.h5’)
print(history)
上篇博文中没有使用预训练模型,这篇在使用的时候,出现了错误,经过查阅资料发现了这种方式是错误的,如下:
#model = MobileNet(weights=“imagenet”,input_shape=(224,224,3),include_top=False, classes=classnum) #include_top=False 去掉最后的全连接层
如果想指定classes,有两个条件:include_top:True, weights:None。否则无法指定classes。
所以指定classes就不能用预训练了,所以采用另一种方式:
model = Sequential()
model.add(MobileNet(include_top=False, pooling=‘avg’, weights=‘imagenet’))
model.add(Dense(classnum, activation=‘softmax’))
另外,上篇文章使用的是fit_generator,新版本中fit支持generator方式,所以改为fit。
loss_trend_graph_path = r"WW_loss.jpg"
acc_trend_graph_path = r"WW_acc.jpg"
import matplotlib.pyplot as plt
print(“Now,we start drawing the loss and acc trends graph…”)
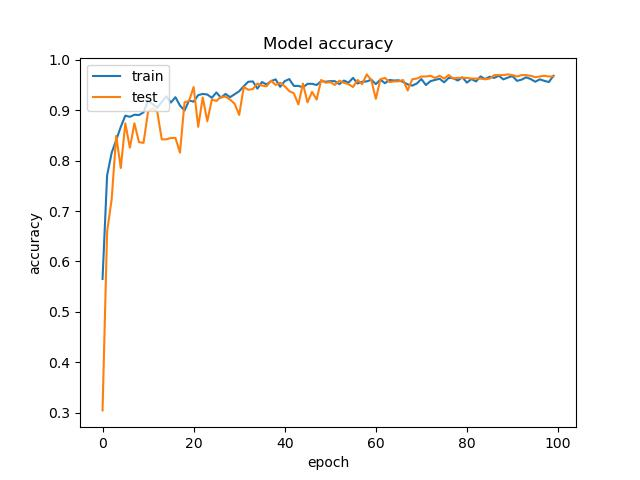
summarize history for accuracy
fig = plt.figure(1)
plt.plot(history.history[“accuracy”])
plt.plot(history.history[“val_accuracy”])
plt.title(“Model accuracy”)
plt.ylabel(“accuracy”)
plt.xlabel(“epoch”)
plt.legend([“train”, “test”], loc=“upper left”)
plt.savefig(acc_trend_graph_path)
plt.close(1)
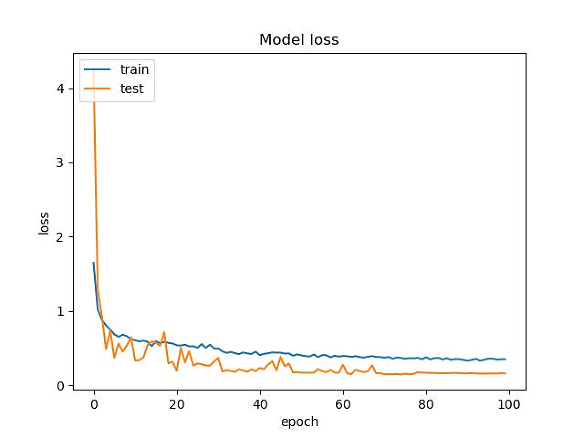
summarize history for loss
fig = plt.figure(2)
plt.plot(history.history[“loss”])
plt.plot(history.history[“val_loss”])
plt.title(“Model loss”)
plt.ylabel(“loss”)
plt.xlabel(“epoch”)
plt.legend([“train”, “test”], loc=“upper left”)
plt.savefig(loss_trend_graph_path)
plt.close(2)
print(“We are done, everything seems OK…”)
#windows系统设置10关机
#os.system(“shutdown -s -t 10”)
===============================================================
1、导入依赖
import cv2
import numpy as np
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
import time
import os
import albumentations
2、设置全局参数
这里注意,字典的顺序和训练时的顺序保持一致
norm_size=224
imagelist=[]
emotion_labels = {
0: ‘Black-grass’,
1: ‘Charlock’,
2: ‘Cleavers’,
3: ‘Common Chickweed’,
4: ‘Common wheat’,
5: ‘Fat Hen’,
6: ‘Loose Silky-bent’,
7: ‘Maize’,
8: ‘Scentless Mayweed’,
9: ‘Shepherds Purse’,
10: ‘Small-flowered Cranesbill’,
11: ‘Sugar beet’,
}
归一化参数的设置和验证的参数保持一致
val_transform = albumentations.Compose([
albumentations.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225), max_pixel_value=255.0, p=1.0)
])
3、加载模型
emotion_classifier=load_model(“my_model.h5”)
4、处理图片
处理图片的逻辑和训练集也类似,步骤:
-
读取图片
-
将图片resize为norm_size×norm_size大小。
-
将图片转为数组。
-
放到imagelist中。
-
将list转为numpy数组。
image = cv2.imdecode(np.fromfile(‘data/test/0a64e3e6c.png’, dtype=np.uint8), -1)
image = val_transform(image=image)[‘image’]
image = cv2.resize(image, (norm_size, norm_size), interpolation=cv2.INTER_LANCZOS4)
image = img_to_array(image)
imagelist.append(image)
imageList = np.array(imagelist, dtype=“float”)
5、预测类别
预测类别,并获取最高类别的index。
pre=np.argmax(emotion_classifier.predict(imageList))
emotion = emotion_labels[pre]
t2=time.time()
print(emotion)
t3=t2-t1
print(t3)
批量预测和单张预测的差别主要在读取数据上,以及预测完成后,对预测类别的处理。其他的没有变化。
步骤:
-
加载模型。
-
定义测试集的目录
-
获取目录下的图片
-
循环循环图片
-
读取图片
-
对图片做归一化处理。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
批量预测和单张预测的差别主要在读取数据上,以及预测完成后,对预测类别的处理。其他的没有变化。
步骤:
-
加载模型。
-
定义测试集的目录
-
获取目录下的图片
-
循环循环图片
-
读取图片
-
对图片做归一化处理。
[外链图片转存中…(img-sDS2xmGo-1714655885260)]
[外链图片转存中…(img-NTDNyYYT-1714655885260)]
[外链图片转存中…(img-BAHXptRw-1714655885261)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新

