
- 1java高级面试题总结_高级java面试
- 2实现c语言中的strstr函数_strstr c语言实现
- 3Android开发:应用百度智能云中的身份证识别OCR实现获取个人信息的功能_百度ai身份证识别 sdk
- 4【python】动态可视化+爬虫(超燃超简单)_python爬虫可视化代码
- 5Redis三种集群模式-Cluster集群模式
- 6混淆矩阵的生成(python实现,含机器学习方法)
- 7探秘双记账系统:DoubleEntry 开源库的奥秘
- 8使用STM32CubeMX读取温度传感器数据的嵌入式应用_stm32读取温度
- 9『大模型笔记』Ollama ModelFile(模型文件)
- 10分布式事务——微服务下的分布式事务问题、分布式事务的解决方案_微服务事务解决方案
点云方向论文阅读笔记(2)_siamese kpconv
赞
踩
笔记(1)中是关于点云配准方向的,(2)和(3)(4)中是点云变化检测和点云分割的,实际上我认为这两种任务的差别不大。都是密集的分类任务,主要是在变化检测中的双时相输入如何好的融合以及融合后映射到特征空间中。由于点云变化检测的论文较少,中间也看了不少的图像变化检测的论文。
3D城市变化检测的综述
变化检测的对象
在复杂的城市环境中的点云变化检测中,主要的感兴趣的对象有四个,①建筑(建筑的加高、缩短等变化);②街景(自动驾驶、道路维护等);③树木的变化;④建筑工地(通常和设计的模型进行变化检测);针对这四种对象,产生了不同的变化检测的方法,由于特性不同,特定对象的变化检测使用的数据、方法也不相同。目前变化检测还停留在针对特征的场景进行的,而没有一统的方法进行所有场景的变化检测。
数据集情况
目前存在的用于城市变化检测的点云数据集有:ALS(无人机载激光扫描,主要用于城市规模的建筑或树木)、MLS(移动激光扫描,适合于街景研究)、TLS(地面激光扫描,适用于单棵树和建筑工地)、SfM(结构摄影测量,主要用于小面积建筑变化检测,大规模的城市研究还未确定)
也存在使用多数据源组合(ALS+SfM用于建筑物变化检测)或者多模态组合(ALS+thoimage(正射图片)用于改进不同时期的变化检测、MLS+image用于街道场景变化检测、MLS和多光束激光雷达用于街道研究)的数据集进行变化检测。
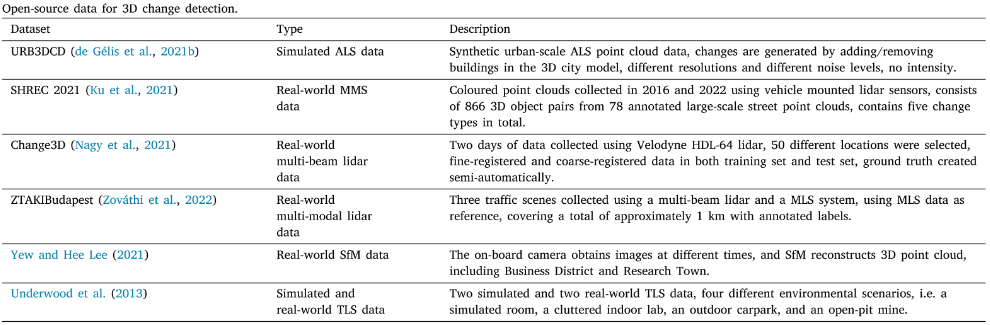
对于城市建筑变化,URB3DCD通过在模型中随机添加或移除建筑物模拟真实改编,其中dBSM、Otus阈值和形态学开放的组合(从两个时相的点云数据生成DSM,计算差分初步反应初始变化检测,利用Otsu阈值(统计图像的灰度直方图,找到阈值将像素分为前景和背景,尽可能让两类的方差和最大)进行变化检测的二值化分割,利用形态学开放运算消除噪声点)在2.5D(通常称深度图像为2.5D而不是3D)变化检测方面都优于包括2D深度学习网络在内的其他方法;在城市规模的尺度上,基于Siamese机构的KPConv能够有更好的表现。
对于街景变化检测,SHREC(对78个场景进行了注释,包含了866个五中变化类别的对象对,无删添和变化和颜色变化),benchmarks为一个手工探测器和两个基于学习的网络,该文章提出的SiamGCN通过随机过采样环节类不平衡问题,大大优于其他的两种网络。
Change3D通过随机模拟配准误差得到粗配准对,包括了50个不同位置的20000个点云对作为训练集,2000个点云对作为测试机,该文章将3D点云投影到距离图像(深度图)中并使用ChangeGAN网络,其性能优于ChangeNet和马尔科夫随机场方法。
ATAKIBudapest是一个用于在线变化检测的多模型街景点云,设置了一个记住,包括三个300米长的道路场景用于可能得实时街道环境变化检测和动态分析。将基于点、体素、分割的方法和所提出的基于深度图的马尔科夫随机场方法进行了比较,分析精度和计算速度。
ChangeDet包含了两种不同的场景,不仅有着建筑施工或者拆除等大的变化,同样包含了车辆移动等小的变化,同时该篇文中提出了一种新的基于深度学习的非刚性配准方法,用于解决数据集中地理位置不准确以及SfM重建过程中可能出现的漂移问题,最终使用双阈值测试和后处理来检测视点和照明不同的两个场景中的变化。
Underwood提供的数据集,利用模拟多波束激光雷达和TLS提供了模拟房间、杂乱的室内实验室、室外停车场、露天矿的四个变化检测点云数据集。可以用于测试能够处理不同环境的通用方法。该文章提出了一种基于光线跟踪的多功能变化检测算法。
除了上面的六个专门用于变化检测的数据集外,其他的多时相开源数据也可以用于变化检测,如TUM-MSL(包含了粗配准TUM-MLS-2016和语义标记TUM-MLS-2018)、也可以使用模拟工具合成的数据进行,如Blender中的Blensor。
对于不同对象使用的比较介质介绍
建筑
2.5D
将点云数据转化为DSM,然后利用差分dDSM得到像素级的变化检测结果,但是是包含了很多假阳性的结果,因此需要利用各种方法进行处理以检测建筑物,例如基于规则的阈值、分割、聚类、分类等,Yadav et al 2022在2D表面投影激光雷达点后使用UNet从背景中分割建筑物(先进行对象检测后对于对象进行变化检测),然后从两个通道中检测片段面积的变化和海拔的变化后利用形态学运算去除噪声。
3D
直接利用点云数据变化检测,①利用点到三角形的距离,利用对应点到另一时期的三角形的最近距离的变化,如果超过某个阈值,则判定为变化点,同时考虑到点位置的不确定性,引入置信区间进行由于噪声产生的假变化的过滤。三角网格化的构建有Delaunay三角刨分、基于增量法的网络重构、基于粘贴的方法,凸包网格化等;
②在①的基础上引入了更复杂的点距离公式C2C、M3C2,考虑点密度、法线、不确定度等因素。
当然都是需要进行后处理的。
③将点转化为体素,可以减轻点密度变化带来的影响。通过对这个体素的点的数量或者一些统计信息,然后进行比较,如果差异超过了某个阈值,则认为这个体素发生了变化,然后进行连通域分析等后处理,确定真正变化的区域。八叉树(将一个三维空间分为8个空间,每一个子节点对应8个子空间中的某一个,同时子节点再次分为8个,直到足够小)
④栅格占用图,将三维空间划分为大小相同的三维立方栅格,对于两期的点云统计每个栅格内点的数量,超过了某个阈值则认为该栅格被占用,绘制栅格占用图,对比两期的栅格占用图,分析栅格的占用情况是否发生变化, 然后将发生变化的相邻栅格进行连接分析,确定真正变化区域,可以构建栅格占用概率图,比较概率变化更加可靠,再利用激光雷达的反射强度数据分析遮挡关系,排除不同视点导致的视觉变化。也可以进一步分析变化栅格的大小,形状特征,进行变化类型识别。
多模态结合
简单而有效的策略是将他们转化为相同的格式。除了这个策略以外,还有将直接在点级别进行比较的方法。
①stal利用立体航空图像和激光雷达点生成DSM,然后计算dDSM作为指示进行细化以消除假警报的变化。Du计算多模态DSM之间的高度差,利用灰度相似性作为变化指标,采用图切割算法来优化变化图,然后通过过滤异常值来细化变化图;zhou利用航空激光点云数据和立体图像结合,用质量较差航空激光点云数据生成DSM后指导立体图像还原为有着质量优良的点云数据。能够消除航空激光点云的视差较大(1米)带来的建筑物边界模糊导致的匹配错误的问题,对于优良的点云数据,同样生成DSM并与激光DSM对比,检测变化,使用部分变化结果指导进行第二次交互式。zhang将激光雷达点云转换为DSM后,将DSM和摄影测量正向之间的差异输入到网络中进行变化检测,正射影像的颜色信息有助于将变化的斑块分离为不变的斑块。

②Basgall使用激光雷达点作为地面控制,用于航空和卫星摄影测量重建,对两期点云进行分类滤波后,提取出建筑物点,计算建筑物区域的点间距差异(a在b中最近点的距离d1和b在a中最近点的距离d2,点间距差异=|d1-d2|),然后提出95%置信区间外的离群点距离,对剩下的距离变化进行分析,检测实际变化和拍摄条件变化而引起的变化,并利用连通域聚类和形态学分析得到最终的变化图。dai使用机载激光雷达和摄影测量数据,利用无监督的方式检测建筑物的变化,首先通过阈值分割特征提取对象,然后利用双向比较激光雷达和摄影测量点(利用PCA求解平面法向量和平面点,对于一期的点P,计算到二期各个建筑物的距离,最小距离即为P到另一期的距离),利用垂直平面到平面的距离来检测建筑物的变化。peng and zhang 利用多时相航空折射图像和相应的激光雷达点云进行精确的建筑物变化检测,从激光雷达数据生成DSM以生成变化图,从正射图像和DSM中提取光谱和纹理特征后,利用决策树分类器构建变化分类,两者的结合提高了建筑变化的完整性和正确性。
街景

2D
Pollard and Mundy利用二维图像通过维护一个更新表面和颜色概率的基于3D体素模型去尽显变化检测。Eden and Cooper根据三维线(主要是建筑屋脊处的,通过平面拟合和直线拟合得到)进行变化检测,Ulusoy and Mundy将图像转为三维场景后进行体素化,计算每个体素被占据的概率,当概率变化大的时候视为变化。
2.5D
将点云转化为深度图后再进行基于图像的卷积网络,Nagy将两个点云作为输入,转化为球面极坐标系下的图像后,使用两个mask表示变化关系后利用siamese的架构和对抗训练得到一对mask表示最终的变化区域的结果。
3D
①点之间的直接比较,Xiao对于参考时相建模每个光线的占用状态(对于每个点计算法向量作为扫描光线的方向,然后沿着光线方向以该点绘制小球采样,如果有其他的MLS点分布,则为占用状态,否则空闲),然后对于目标时相,计算每个点的占用状态(以该点为中心,附近R半径中是否有其他的点),然后对于参考时相中的每个光线,在目标时相中找到其附近点,判断这些点的占用状态与该光线是否一致,一致则该光线对应的空间没有变化,否则,则变化。Yew and Hee-Lee应用SfM生成3D点云后,基于DeepMapping and Feng的深度学习方法实现非刚性配准优化,最后采用双重阈值和滤波方案进行变化检测。
②体素化后进行比较,较多的研究通过占用网格方法对点云进行建模后比较占用网格变化来进行变化检测。Aijazi对点云进行分割,去除非静态物体得到孔洞点云,简历3D矩阵证据网格,每个体素存储激光点占用证据值,对每条激光光线更具与体素的夹角增加对应体素的占用证据值,计算每个体素的占用率得到变化前后的占用率图,定义相似函数,比较两期体素的占用率,计算相似度,根据阈值确定发生变化的体素。
③基于对象进行变化检测,将点云分割成对象后,对于每个对象的行为进行评估。Voelsen将点云数据分割成几个静态和动态类,将分类的静态对象输入体素进行直接比较,通过体素的占有率和分类结果来区分静态环境无法生成的异常。Ku利用图卷积网络对MLS得到的三维点云数据进行变化检测,将来自给定对象中心坐标的两个时期的点云作为输入,相应的颜色和几何变化作为输出。Gehrung提出了基于点云和体素结合的方法,利用两者的优势来处理这档,提高计算效率,使用激光雷达数据和真实世界的公共MLS数据来测试提出的方法,检测3D中不同类型的变化。
多模态
MLS与图像数据或者其他的激光雷达数据
Qin and Fruen比较了MLS点云和MMS摄影测量数据用与街景变化检测,利用处理后的高精度MLS数据作为参考对地面影像进行立体对矫正和重投影,然后监察点云和立体图像之间的几何一致性,进行变化检测。Galai and benedek 使用了密集的MLS点云作为参考,将静态物体分类为背景,与稀疏的多波束激光雷达数据进行对比,进行即时变化检测。将两种数据转距离图像,采用马尔科夫随机场方法对距离内的运动目标和环境变化进行二值分类作为前景。然后反投影到多激光雷达数据中,Zovathi通过对分割后的目标进一步改进了多波束激光雷达与MLS点云的配准,将MRF方法用于实时动态变化检测。
树木

这里是考虑到不同视角对树点分布的影响,分为了空中,地面对树木变化进行检测。
空中
在单个疏的水平上对树木进行3D分割用于估计树木的参数,如高度,半径等,用于检测生长和损失,并用机载激光雷达数据估计地上生物量动态。在3D中检测到树冠的形态变化,如树枝倾斜等。类似于DSM,树点比被转换为曙光高度模型CHM,该模型中,树梢被检测为局部最大值,然后通过分数领算法对单个树冠进行分割。
Xu等人利用八叉树从激光雷达中直接检测建筑物和树木的变化,同样,只能检测一棵树的植株或枝条(由于八叉树考虑点云的拓扑结构,可以检测出建筑物或者树木的整体变化,因此无法区分或分割出单棵树的更细微的变化,如树冠形状、单个树枝的生长等)。Tran等人使用了集成监督分类的方法直接在3D中检测到树的变化,只有整棵树的变化才能被检测到。Xiao等人从机载激光雷达数据中预先匪类的树点钟分割出3D的个别树木,然后对树冠进行建模,提取高度,面积、体积等参数来检测城市树木的生长。Fekete and Cserep使用CHM中的种子点来分割单个树冠,考虑到在水平和垂直方向上与种子的点距离。然后,通过质心距离和豪斯多夫距离两种方法对不同时期的树木进行匹配,并检测高度和体积的变化,在对点进行下采样时使用网格大小来计算体积。
地面
Kaasalainen使用TLS多次采集单个树木的高密度点云,用一系列圆柱体对树枝结构进行定量建模,然后通过这些圆柱体可以估计树枝的分布、大小和体积,然后检测详细的分支变化,从而在3D中检测生长、死亡率和生物量。li从MLS数据中分析了行道树的动态,首先过滤掉非树点(不属于树木的点),并用几何模型拟合树,提取详细的树参数,如位置、DBH(树木的胸径)、干线(树干的主要部分)用于变化检测。Hirt根据MLS数据构建占用网格,实现3D空间的变化分析,通过圆柱体拟合和密度加权距离对单株进行分割,然后从点级几何变化的占用网格和对象及参数变化的树实例中检测变化。
树木中并没有转化为2D或者2.5D的情况,而是从模型或者线段中提取树木参数进行比较,常见的是激光雷达点,而摄影测量数据的使用较为少见。我认为可能是由于结构复杂,遮挡严重。从点云到二维图像后的信息丢失厉害,同样对于摄影测量来说,难以进行3D重建,计算的复杂度高,而对于图像匹配来说,树木的颜色过于单调,纹理信息不够明显。
施工现场
施工现场会涉及到BIM(暂时理解为施工的三维模型示意图)

3D
Girardeau-Montaul将TLS点云利用八叉树的结构加速基于点的直接距离,由于在施工的过程中会导致可视性的变化,会有遮挡区域,比如原来的墙面被新搭建的墙挡住了,会产生误报的情况,因此将原始点云转换为2.5D的深度图像,如果某个位置被遮挡住了,不可见,就可以把该像素的变化排除,最终只保留真正可见区域的变化,过滤了由于被遮挡引起的误报。从三维点云->二维深度图->三维点云。Huang等人使用了多时相无人机摄影测量点云对施工进度进行了三维检测,对外部摄像头的光线建模后,通过占用一致性评估检测几何变化,同时还学习了语义,进一步分析几何和语义变化检测的变化。
多模态
BIM和点云数据进行变化检测
①利用激光扫描,Turkan等人使用了具有进度信息的设计CAD模型和相应的多时相激光扫描进行比较,首先进行手工的粗配准后进行ICP,然后对应的点进行基于点的距离的变化检测即可。Kim等人提出了一种全自动的方法,通过具有颜色信息的激光扫描来注册3D CAD模型,对于CAD模型中的组件进行匹配,以指导激光扫描点的分割(得到对应于CAD模型中各组件的分割),对于每个点云片段在特征提取后,使用支撑向量机分类其对片段进行分类(墙体、屋顶等类别),根据标签和CAD中对应组件匹配,进行配准后检测变化,竣工进度根据施工活动的顺序和组成部分的连通性进行了修订。
②利用日常图像,通过摄影测量重建点云,在体素级别标注场景占用情况,和BIM进行点云配准后,采用贝叶斯概率模型自动检测施工进度。Tuttas利用了二维图像特征来实现多时相点云之间以及点云和BIM的配准。BRAUN采用SfM摄影机视线以及BIM中的语义和几何信息用于改进建筑元素的检测,同时,Mask R-CNN被训练用来从初始的2D图像中检测可见元素。
由于BIM的存在所以在施工现场时多模态变化检测较为常见,激光雷达和摄影测量点云都对其进行了研究。与地面和无人机摄影测量相比,使用TLS更容易捕捉建筑工地的室内和室外区域,但无人机摄影更具成本效益。遮挡是将竣工数据与BIM进行比较时需要考虑的主要问题。
变化检测的方法
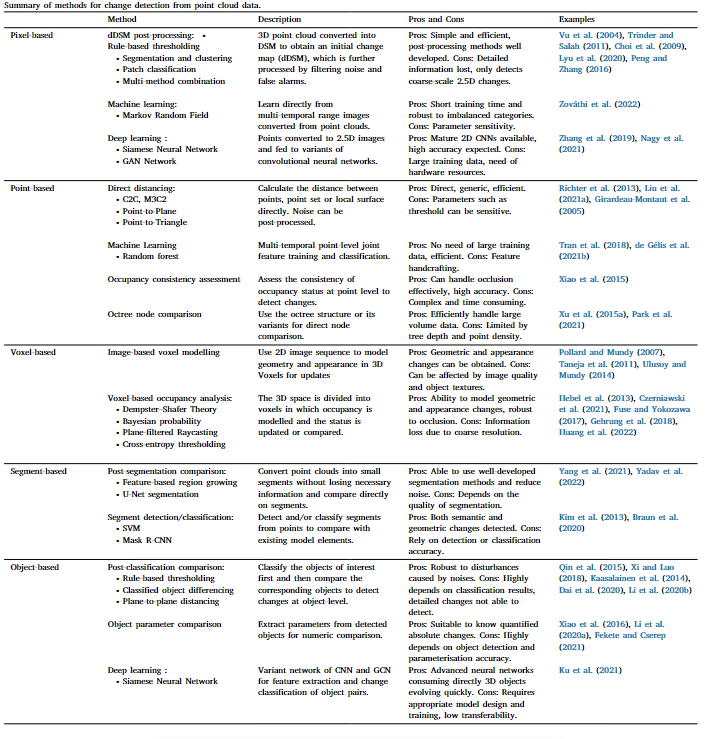
基于像素
将点云投影到2.5D的DSM或者距离图像,,然后利用2D变化检测技术进行。
dDSM
通过简单的减去DSM得到像素级的二进制变化图,后处理有形态学滤波和阈值处理、分割、分类、去除噪声和未配准引起的假警报,但是会由于信息损失而无法检测细致变化,适合更大范围明显变化的检测。比如城市范围内的建筑物变化检测。
2D机器学习
马尔科夫随机场MRF考虑每个图像像素之间的几何和语义距离,并通过二元前景和背景的分类检测变化。该方法比一些基本的基于点的方法更准确、更快,对不平衡类别具有鲁棒性,但是对于分类器的参数敏感,最终比较认为相对于其他的分类器或者方法是更有效的。
2D深度学习
利用Siamese的网络结构,从多时相dsm和相应的正射影图中检测到变化。GAN也可以在Siamese的架构下进行,从输入图像对中提取特征进行变化检测(Nagy,2021)。受到UNet的启发,将下采样快的高分辨率特征添加到相应的专职卷积层中,以提高变化检测结果。
基于点
距离
①点到点的距离C2C,使用Hausdorff被证明是十分有效的。②多尺度模型到模型云比较M3C2,将点到点换成点到三角网格的距离,将点云转换为不同尺度的三角网格,然后计算点到不同尺度下三角网格表面的距离的直方图并进行汇总得到多尺度描述后,根据峰值、方差等判断变化情况。③点到三角形。④点到平面距离,但是这些得到的变化图通常需要后处理,比如阈值过滤等。同时检测到的变化仍然是单独的点。
机器学习
被认为是分类问题,不仅检测几何变化,同时还学习语义类别,实现几何变化检测与语义分割。通过设计点单独特征以及和附近点相关的特征,然后利用随机森林分类器进行训练,最终可以得到稳定和理想的效果,比C2C和M3C2更好。但是这些特征需要手工制作,泛化能力有待考量。
占用一致性评估
Xiao et al, 2013使用图像和激光雷达点作为输入。使用点作为锚点,考虑点法线的情况下在点位置对占用进行建模,并在三维空间中进行插值(使得两个历元的点的占用值都存在),可以直接将其与第二个历元的点进行比较,进行变化检测。这种方法可以有效区分遮挡和真实变化,xiao et al, 2015将点到三角形的距离和这种方法结合,减少对未改变点的占用建模和过滤可穿透物体上的点来提高效率和准确性。
八叉树节点比较
主要用于处理大量的点数据。①通过在八叉树结构中划分点,显著加速搜索最近点或在定义的半径内的点啊,提高基于点的比较的计算效率。②八叉树也可以被直接比较用于变化检测,将两个历元的八叉树节点进行比较,如果找不到该点对应的叶节点,则认为发生了变化。③将八叉树节点与用于网格模型变化检测的曲面网格进行比较,同时实现了点索引和变化检测,但是一方面受八叉树的深度限制,另一方面对于异质点密度敏感。
基于体素
基于图像的体素建模
从图像数据还原到点云数据后,带着丰富的点特征,再进行体素的划分后,对于每个体素中的属性的概率进行建模,然后多时相不断对比进行变化检测,并通过从不同视角拍摄图像来缓解遮挡问题,但是由于这些纹理、色彩等信息会被图像质量所影响,因此最终只考虑环境的几何变化,但是最终仍受影响,如分辨率的一致性和对象纹理等。
基于体素占有率分析
主要有两种理论进行建模,①Dempster–Shafer理论(DST),通过结合独立传感器证据的置信度,体素沿着光线定义为占有和自由,如果没有证据的时候是未知的,然后通过不同角度的射线将证据进行叠加后得到最终的体素状态。②贝叶斯概率,初始为被占用的概率作为先验概率,并用新的获取进行更新,通过贝叶斯规律得到体素的后验概率。然后得到占有率后通过阈值来确定体素的状态进行变化检测。
体素的状态可以从多种数据源进行建模,阈值也可以使用交叉熵进行,(占有和自由进行交叉熵),但是由于体素级的变化可能导致伪影或者噪声形式的错误检测,特别是平面表面的入射角较大时,因此提出了一种平面滤波光线投射算法来有效地防止伪影的产生,有点是他可以对几何和外观信息进行数学建模,并通过投射光线和评估占用冲突来有效地解决遮挡问题,但是通过离散存储在体素上的空间信息来近似3D环境,要么由于分辨率粗糙,要么需要高成本的计算来获得高空间分辨率,要么存在信息丢失的问题。
基于分割
首先将点云数据分割为段,然后进行变化检测,减少噪音和配准误差的影响。
得到分割后的比较
点和体素级别的数据容易导致点或体素的变化,也就是敏感,因此在进行变化检测之前首先将点云聚类成多个片段,可以使用区域生长、深度学习等方法,能够在聚类时减少噪音且不丢失必要的信息,然后通过检查线段距离和比较线段特征来检查变化,这种方法能够避免有噪声的结果,并且提供如建筑面积变化之类的中层变化信息。而最终的变化检测结果无疑取决于分割质量。
分段检测/分类
在聚类完的基础上,对点片段进行分类或者直接进行检测从而获得语义信息用于辅助变化检测,Kim使用SVM对片段进行分类以进行建筑组件比较。Braun使用Mask R-CNN用与对象检测,并于建筑模型进行比较,这类方法的有点事充分利用语义和几何学习来改进变化检测,但是也依赖于检测/分类的结果,对于训练数据和算法有要求。
基于对象
首先识别整个对象,然后在对象级别进行变化检测和分析。对象我认为就是对于分割进行高级语义的提取,分割更多的是对于几何的划分,其中不一定划分出来的每一个区域就是一个对象,而且分割也不会去进行高级语义的提取,比如这块区域是啥,如果是树木那么高度多高、干线多少这样的,而对象则会,对于分割后的区域,进行一些机器学习的算法,赋予一些高级的语义信息,帮助进行变化检测。
分类后比较
决策树和SVM对DSM进行分割和分类,然后通过双阈值计算用于变化检测的对象级特征,如高度、光谱信息。为了便于分类,利用不规则三角网过滤接地点,然后对其余点进行分割,便于提取线段级别的特征。利用SVM将剩余点分为建筑物和植被,并应用形态学运算对非建筑物点进行滤波。然后,通过基于规则的分析,使用建筑高度直接确定变化(Xi和罗,2018;戴等人,2020),Dai等人利用无监督阈值将非地面点分类为建筑、植被和其他。对象级别的变化检测对于噪声具有鲁棒性,但是由于在对象的级别,因此比较依赖分类结果,同时对于细小的变化难以察觉。
对象参数比较
Xiao、Marinelli、li等人从检测到的物体中提取高度、面积和体积等参数进行数值比较,通过这些参数可以量化变化,这种方法最适合于监测树木生长的树木变化检测。通过与参数模型拟合,例如3D树冠模型拟合(Xiao et al.,2016),可以计算面积和体积,从而提取精确的对象(例如,单株树)参数。圆柱体和椭圆形也被用于与语义信息支持的树干和树冠相匹配(Li et al.,2020a)。甚至线段也可以配备主干和分支,用于详细的结构监测(Kaasalainen等人,2014;Li等人,2020a),通过使用这样的参数提取算法,可以准确地检测量化的绝对变化。然而,由于最终的变化结果完全由提取的对象参数决定,因此这种方法高度依赖于对象检测和相应参数化的准确性。
深度学习
目前一般都是将点云数据转化为距离图像,很少直接将点云作为输入用于变化检测的网络当中。主要采取CNN和GCN网络的变体来提取特征并对对象对的变化进行分类,前提是对象已经被定位或识别(已经被分割过,识别出了不同的对象),而Siamese的网络结构在特征提取方面表现出有效性。
总结
基于像素的方法常用于大尺度建筑、城市树木、街景等,从dDSM阈值向基于图像的深度学习转变。点级和体素级的额方法由于是底层表示,四种目标对象都可以使用,主要使用三维距离和占用一致性评估的策略进行几何变化检测。存在这阈值敏感和计算缓慢的缺点。从八叉树数据存储、自适应阈值和机器学习特征提取方面对这些缺点做进一步改进。注意,基于占用率的一致性分析不仅用于激光雷达点,还用于摄影测量数据,以及不同尺度的四种类型的城市物体,显示了其灵活性和可转移性。基于分割的方法使用语义分割,首先对点云进行聚类,获得更有意义的寓意和几何变化信息。在建筑工地上进行了更多尝试,在城市建筑中进行了少量研究。再进一步的基于对象的,首先对整个物体进行识别,然后直接对物体进行比较,实现变化检测。这种基于对象的方法更适合高层次的变化信息提取,如整个建筑变化(Dai et al., 2020;此外,对象级参数的比较更适合于分析城市树木的变化,前提是它们可以被单独检测到(Xiao et al., 2016;Li et al., 2020a)。
挑战和机遇
点云配准
在大多数研究中采用从粗到细的策略进行点云配准。
①配准的效率。②深度特征学习。③泛化能力。
处理数据量和密度
八叉树是最常用的数据结构用于加速点数据的检索以进行领域点搜索和比较。通过体素化可以显著降低数据量和计算成本。
阻碍变化检测的另一个因素是点密度,这可能会因数据采集配置而异。基于点的方法对于密度较为敏感,提取局部表面或几何模型能够减轻这种影响。基于体素的方法也能够减少密度变化的影响,但当体素大小较小时,会出现导致误报的空孔(当变小时,可能会导致原来有点的区域由于密度小,导致被判为空的体素,但是体素过大的时候,会损失细节)。基于分段或对象的方法能够有效的保证变化区域的完整性,因此对点密度具有更强的鲁棒性,但高度依赖上游任务(分割/检测)的能力,Siamese在异构数据中提取特征的能力是有效的,值得进一步探索在不同点密度下的有效性。
遮挡和不连续覆盖
机载激光扫描从俯视图点获取数据,遮挡相对地面系统来说较小。数据不完整性会导致被遮挡区域识别为变化区域。基于距离的方法无法有效区分遮挡和真实变化,而基于占用的方法通过光线投射简历的数学占用模型可以有效的解决遮挡问题。通过点云分割也可以预先识别遮挡,以便处理不完整性。此外,开发了深度学习方法来完成物体形状或场景,可以缓解遮挡的问题。
其他的检测目标
除了这四个,地球变形等其他目标的变化检测也取得了进展,森林、室内场景等,对于滑坡、边坡、冰川变化等地表变形,Teng等(2022)根据点云距离(Lague et al., 2013)或位移场(Gojcic et al., 2021)对TLS数据监测方法进行了分类。Winiwarter et al.(2021)量化了点测量和多数据配准的不确定性,改进了M3C2方法,从而更好地估计了“检测水平”。将该方法应用于岩石冰川的TLS时间序列来量化体积变化。一个好的“检测级别”将能够检测到小的变化。误差传播确实没有得到充分的考虑,特别是在精细尺度的变化分析中,应该给予更多的关注。然而,代表表面运动向量的位移场与本文的变化检测不同。位移检测的关键是在多时相数据的特征空间中提取局部特征并进行相应的特征匹配(Gojcic et al., 2021)。
在林业领域,点云数据被用于有效检测森林结构变化和森林生长。分为三类:CHM差异、基于区域的方法和单个树级分析。至于基于区域的建模,无论是直接方法还是间接方法(Næsset和Gobakken, 2005;Dubayah et al., 2010)已被应用。前者使用单一模型估计森林属性变化(如高度、地上生物量变化),后者使用独立模型预测不同时间的森林属性。在树水平上进行生长监测变得可行。Marinelli et al.(2018)首先检测到森林冠层的剧烈变化,然后描绘出单个树冠,并使用3D模型对树木进行拟合,以估计树木的高度和体积,从而进行变化检测。这与城市树研究中基于对象的参数比较相同。与森林树木变化检测中讨论的问题类似,城市地区全树水平变化的估计虽然重叠较少,但容易受到单个树木检测质量的影响。
在室内环境中,对于室内施工进度监控,主要使用TLS数据检测BIM与点云之间的变化。Meyer等人(2022)利用基于体素的精细分辨率占用分析,考虑到室内场景的特殊条件,利用Dempster-Shafer理论评估空间冲突。Tran和Khoshelham(2019)根据点分类和表面覆盖率确定了BIM和点云之间的差异。根据点到表面的距离(即每个点到最近的模型表面的正交距离)将点分类为现有点或新点。除了施工进度监测外,Koeva等人(2019)还通过检测3D点云的几何变化来更新3D室内地籍。基于kd树计算点对点距离,以检测2D和3D的差异,并进一步分析以排除扫描覆盖。
利用深度学习进行变化检测
变化检测的深度学习
目前的研究主要将深度学习从数据上分为两类,一是将点云映射为2.5D图像,二是直接基于3D点。由于已经有很多二维的深度学习网络的成果,因此第一类较为常见,在某些情况下,2D深度学习网络确实优于非深度学习方法,但并非总是,和网络结构以及研究对象有关。由于难以获得足够的训练数据以及3D中点的不规则和不均匀分布,使得直接基于点云的深度学习研究很少。
另一种可能得操作是先进行语义分割和对象检测后,再进行有效的变化检测。且Siamese网络及其变体在学习相似性和检测输入的变化方面有着良好的表现。
Siamese network
由于KPConv在点云分割中的良好表现,在端到端的变化检测中,使用了KPConv作为编码器,结果优于随机森林分类器。在SiamGCN中,首先对不平衡类进行采样得到平衡的样本,利用EdgeConv进行特征提取用于分类。除了Siamese的网络架构外,还提出了一种伪Siamese(相同的网络结构,权重不同)架构,被证实在大型城市数据集上有效。
由于将变化检测类似于二值分类,因此损失函数最常使用的就是交叉熵损失函数,但是由于变化检测任务重存在的严重的正负样本不平衡,因此通常会加入权重进行调整。除了加权交叉熵损失函数外,还有NLL损失函数。 l = − ∑ l o g ( P G ( x i ; θ ) ) l=-\sum{log(P_G(x^i;\theta))} l=−∑log(PG(xi;θ)),其中 内项 = − [ y l o g ( p ) + ( 1 − y ) l o g ( 1 − p ) ] 内项=-[ylog(p) + (1-y)log(1-p)] 内项=−[ylog(p)+(1−y)log(1−p)]。
在重新评估3D变化检测的Siamese网络时,从近年2D变化检测任务的灵感中,发现Transformer用于改进特征提取,并采用了特征融合的思想。在解码器中,使用集成的通道注意力和空间注意力来加权特征,并有效的融合来自不同域的特征。也可以使用密集连接方法来减轻神经网络深层的信息损失,在损失函数的设计中,提出了UAL(不变域损失函数,就是不变区域的特征尽可能相同),其中通过考虑具有相同语义标签的不变区域来约束特征图。
弱监督和自监督学习
在点云变化检测中,相对的带有标注的数据更加繁琐和复杂,因此数据集和数据量较少。因此需要点云理解中的弱监督和自监督学习(如家铭学长的CrossNet)。
受二维图像弱监督学习的启发,最近一些用于点云语义分割的弱监督方法使用较少的3D标签(仅有一些关键部分的标注信息)(Wang and Yao, 2022),并生成具有有限间接注释的伪3D标签(如图像标签,能够提供一些监督信息)进行训练(Tao et al., 2022)。禁用1%甚至更少的标签就长生了相当的分割结果。同时自监督学习在额外的数据集上预训练网络,通过自监督对比度损失进行学习,然后在下游任务重进行调整,在更平衡的分割方面表现出改进(Hu et al., 2021)。目前,用于三维变化检测的弱/自监督分割或检测尚未得到研究。此外,直接实现弱监督和自监督的端到端3D变化检测是一个值得探索的方向。
总结
本文全面回顾了基于城市环境中点云数据的3D变化检测的最新方法,确定了跨数据源和对象的通用策略,并揭示了仍然存在的挑战和未来的机遇。本文以城市中的建筑物、街道、树木和建筑工地等感兴趣对象为研究对象,总结了每个对象的数据源,对用于变化检测的临时数据格式进行了分类,并分析了相应方法的优缺点。这有助于理解针对不同对象的不同方法,从而选择最合适的方法。鉴于基于学习的方法显示出有希望的结果,对现有的用于变化检测的公共数据集进行了整理。尽管近年来公共数据集显著增加,但3D变化检测的基准仍然很少。相对于目前存在的遮挡、点密度变化、配准误差等问题,点云深度学习的快速发展为三维变化检测带来了新的动力。总体而言,本文旨在帮助研究人员找到针对特定应用的三维变化检测方法,了解现有方法在城市环境中的优缺点,并为点云三维变化检测的未来发展做出贡献。
Objects Can Move-2022-ECCV
新颖点
①将场景表示为超体素
②利用变换一致性去传播变换点。
③利用对象级别的变化检测发现3D对象
④无监督的算法。
流程框架
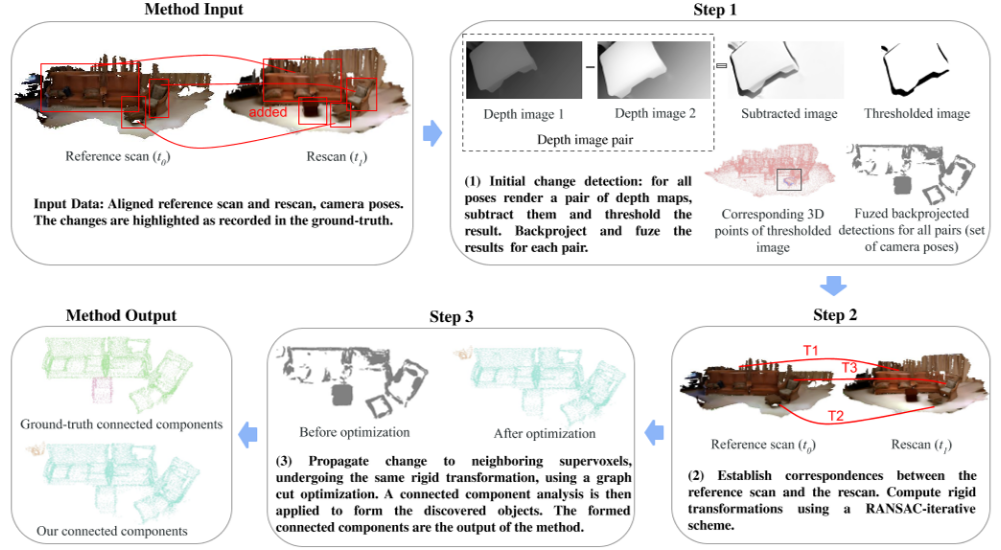
①首先通过初始变化检测,将参考扫描和冲扫描的深度图相减得到初始变化区域,利用阈值得到二值化的变化图,然后反作用回3D空间得到初始变化检测结果。②利用DGCNN提取各点的特征描述符,然后最近邻搜索对应关系,对于移动距离低于某个阈值的对应关系,本文认为是静态背景带来的误差进行去除,然后使用RANSAC计算潜在变化,得到T1变换后,将涉及的内点去除,然后再计算得到T2…TN,取前K个作为真实变换。③对于每个超体素(先滤波和法线估计,随机设立种子点采样,然后进行区域增长(利用色散度、颜色、空间距离作为阈值)),根据得到的k个刚性变换进行软标记,如果某个超体素中存在着改变的点(不管有多少,来自于这个刚性变换如何得到的内点),那么就设为1的可能=0.8,0的可能=0.2,没有改变的点,但是也认为可能存在改变各自设为0.5,构建图割函数,依照该函数在不同的刚性变换T下进行图割(先验项让最后的结果趋于原始变化图,而后验项让这个变化图向外扩展),得到多个变化检测图后,对这些图进行融合得到最终的变化检测图。图割函数如下:
a r g m i n { Φ ( L , Q ) + λ Ψ ( Q ) } arg min\{Φ(L, Q) + λΨ (Q)\} argmin{Φ(L,Q)+λΨ(Q)}, Φ ( L , Q ) = s u m i P ( i ) log P ( i ) Q ( i ) Φ(L, Q)= sum_{i}P(i)\log\frac{P(i)}{Q(i)} Φ(L,Q)=sumiP(i)logQ(i)P(i)
实验方法
数据集:3RScan(包括各个房间,捕捉自然变化的室内环境,共有点云数据,RGB-D图像,场景之间发生了变化的对象有关的信息,相应变换(用于配准的))。训练子集中包括47个不同的参考扫描和110个重新扫描,由于该数据集是为了对象实例重新定位任务构建的,所以还需要根据补充信息生成变化对象的地面实况数据。
Baseline:利用深度图进行dDMS作为第一个基线,第二个基线通过图切割优化,优化方程为,主要用来进行颜色方面的平滑。
评价指标:IoU和Recall

超体素能够构成更有效的表示,而且与光一致性相比,几何一致性在传播变化方面更加成功。同时,凸优化前后的评价指标显示了优化的重要性,IoU提高了14.17%,Recall提高了44.57%。
消融实验
①使用数据集提供的地面实况变换而不是本文计算的+②初始变化检测和图形优化+③利用语义一致性替换了几何一致性(后验项改变)
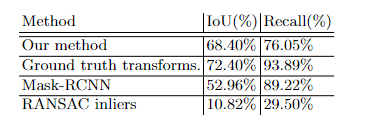
将变化传播到颜色一致性能够提高Recall但是会导致低IoU,本文认为是因为一些变化在某些情况下过度传播了,导致的精度下降。
从MAsk-RCNN看出,语义成分并没有提高整体的性能。这是因为RGB-D图像噪声大,分割结果不准,背景错误检测为前景。因此错误传播到了许多背景区域,导致了Recall高但是IoU低的情况。与真值比较,Recall已经十分接近了,但是在IoU方面还有提升空间。关于变换来说,仍有改进空间,仅有72.40%的IoU解释为扫描之间的遮挡和配准不准所导致的。错误的配准导致与正确估计的区域合并,从而降低IoU分数。仅使用RANSAC内点的结果劣于优化前的结果说明了特征匹配和计算运动一致点(同一个刚性变换下的点就是运动一致点)是不够的。
KPConv-2019-ICCV
事实上我在Predator中简单的介绍过了刚性的KPConv,这里详细的介绍一下。
提出的原因
①由于点云不同于图像的规则化,因此需要不规则的核点帮助进行点云的特征提取。
②考虑到点云不规则的情况,提出了基于输入点云进行卷积核点位置变换的一种策略。
新颖点
①提出了一种可以用于非规则的图卷积的方法(相比于经典的卷积需要规则性相比,我认为KPConv是利用设置的固定的核点得到规则性,而把不规则性下放了一层)
②使用了可学习的偏移向量对核点的位置(本文认为和ReLU类似,简单的线性相关的距离表示就能够得到显著的成效)进行了变形。
核点的放置是在球体中的,我认为按照正多边形放置就行了。
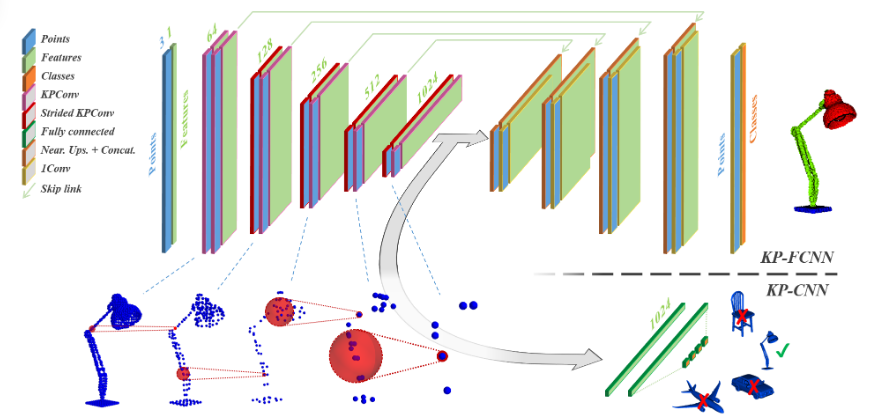
网络架构
KPConv的网络架构
子采样:首先对于点云体素化,对于每一个体素中的输入点云求得质心作为这个体素的支撑点,特征为平价加权和。
池化层:可以通过maxpooling进行池化,或者Strided KPConv进行池化,对于支持点,每个s-1个支撑点进行KPConv就是跨步KPConv了。
KPConv层有输入点的坐标,输入点的特征和(输出点在输入点的k近邻或者球形邻域的点)以及输出点的坐标。
Strided KPConv首先进行子采样得到Strided KPConv之后的点,然后对于这些点进行KPConv,使用的点是之前的原始点云的点。
网络的参数设置:对于第j层,栅格大小为设为dlj,那么设置核心点影响距离σj=∑×dlj,平均的核点半径为1.5σj(求平衡后所有核点到中心点的距离,然后×同一个系数缩放到1.5σj),刚性KPConv的卷积半径为2.5σj,可变形的卷积半径为ρ×dlj,核点数量默认15,∑默认为1,ρ默认为5,dl(j+1)=2*dlj。
使用的KPConv构建的网络架构
损失函数
除了关于分类/分割任务的结果的损失函数外,对于核点设置的损失函数,一方面约束核点之间互相排斥,另一方面为了防止没有邻居在核点的影响范围,设置了离最近邻居的距离的惩罚。
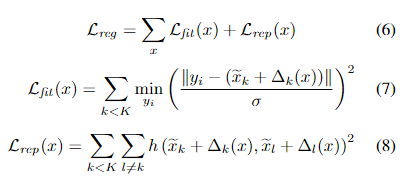
实验方法
数据集:ModelNet40、ShapenetPart(16个类别中的16681个点云的集合,每个类别有2-6部分标签)
第一个子采样网络大小设置为2cm,

在ModelNet40中,rigid优于deform,本文认为是由于任务较为简单,复杂的deform的网络结构反而会干扰正常的收敛,以及到了过拟合的程度。
在ShapeNetPart中,KPConv则能够有更好的性能。
在真实的3D场景分割中。
数据集:Scannet(室内杂乱场景,1513个小型训练场景和100个在线基准测试的场景,均有20个语义类)、S3DIS(室内大空间,三栋不同建筑的六个大型室内区域,13个类别)、Semantic3D(室外固定扫描,8个类,40多亿个点,大多覆盖地面、建筑物、植被,对象实例相对较少)、Paris-Lille-3D(室外移动扫描,4个不同城市超过2公里的街道,1.6亿点,10个语义类)

消融实验
通过限制核点的数量对可变形和刚性的KPConv进行比较,发现了可变形的在少量的核点的情况下损失的mIoU要比刚性的少,同时在仅有15个核点的情况下优于刚性的表现。
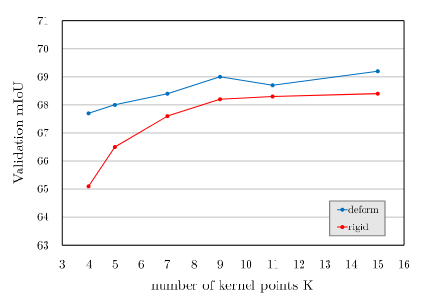
为了更有效的观察可变形的效果,本文使用了ERF,有效感受野进行效果的观察。在Deform中,对于大的物体,视觉野相比于刚性会感觉的更大,对于小的物体,视觉野相比于刚性会感受的更小,更细致,说明了deform相比于rigid来说对于对象几何形状的适应能力更强。

SSL-DCVA-2023-IOJPRS
DEEP UNSUPERVISED LEARNING FOR 3D ALS POINT CLOUDS CHANGE DETECTIO
一种利用KPConv为基础架构去自监督学习点云的特征然后用最近邻特征差异进行二值变化检测的网络。
提出的原因
①光学图像和SAR数据都缺少了一些空间的信息。光学中对于形状的变化不敏感。
②公开数据源中很少用于变化检测的,导致使用无监督学习。
新颖点
①无监督深度学习的方法,利用自监督的学习策略学习网络权重
②在点云上运用深度变化分析框架
无监督学习变化检测的方法
①基于生成可信的变化伪标签来训练深度模型(无监督传统方法(变化向量分析法)的组合、模糊聚类(对某个点的隶属度进行判断,如果显著变化,则设置为变化)、度量学习(通过比较两个相近点在学到的新度量下的距离是否很远,很远则设为变化)、无监督深度框架(如自编码器(AEs)以及GAN网络)),其实就是使用一些方法对点云数据先进行处理,然后得到可能没那么正确的标签。
②由于①方法创建的伪标签本身存在不完全正确性,因此训练的网络虽然准确率能够比原来更高,但是收到了伪标签的影响最终会有瓶颈的问题存在,所以②方法是基于深层特征生成的潜在变化图(通过多层的神经网络提取的特征,然后对应点进行相减或者什么的得到的潜在变化图)。这里的深层特征提取可以用其他数据集(尽可能和目前数据集分布相似)迁移学习得到的网络权重。
自监督学习变化检测的方法
Saha利用多传感器数据,利用对比损失来学习相似(相同空间)和不相似(随机选择的空间)的特征。利用自监督学习的方式提高网络的特征提取能力。Chen将对比学习用在超像素级别,Cai使用基于无监督的图像分割生成相似和不相似的补丁后,利用对比学习。Leenstrash使用了两种不同的前文任务(一种自监督学习的策略,类似于迁移学习,但是这个前文任务的训练是不需要标签的,通常是对数据本身的属性进行的,比如自然语言处理中的大模型(学习自身的语法)):区分重叠和非重叠的补丁(两个图像补丁是否有空间重叠,也就是是否来自同一空间)用于进行特征的提取,第二种任务似乎带来了更好的变更检测结果,Dong使用GAN网络中的判别器来区分双时相图像的样本。Saha通过对图像自然顺序的预测作为一种适合于变化检测的前文任务。一些论文利用其他的策略(特征相似度分析,慢特征分析(一种提取特征的方法,提取的特征在时间的维度上缓慢变化,而变化较大的,则可以视为变化了),特征距离结合互信息度量(计算两个点云特征的互信息度后,和特征距离结合起来),多尺度特征融合(不同层的特征进行拼接))生成潜在变化图,然后利用后处理的方法(阈值化法(二分类)、聚类操作(通过潜在变化图中特征的情况进行聚类,能够得到二分类或者多分类的结果))得到最终的变化图(我觉得可以试试在潜在变化图的基础上也使用深度神经网络进行多分类)。
对于类不平衡问题,可以利用GAN网络进行一些变化样本的生成,以达到数量平衡的目的。
KP-FCNN的训练
这个KP-FCNN网络的具体的训练是,第一个损失函数,通过网络生成的值进行取最大索引后作为伪标签指导网络,从而达到获得区分度高的特征。第二个损失函数,对于新点云中每一个点,在旧点云中找到最靠近的点并使他们的标签尽可能相同,从而达到相近的区域的特征尽可能相似的目标,同时可以学习忽略不同的点分布。第三个损失函数,对于旧点云重新打乱后,认为所有和新点云最近点的旧点云中的点都是不对应的,因此认为他们应该标签尽可能不同。
这个KP-FCNN的网络是利用自监督学习进行训练的,通过不同时期的点云数据的相似位置和不同位置的对比学习训练提取特征的能力,由于点云数据存在由传感器等带来的误差,通过这种自监督学习的方法,训练的特征提取器,能够很好的识别这种分布的误差是由于点云本身的变化而带来的还是由于其他的主观原因所带来的。

伪代码 Initialize KP-FCNN weights for e ← 1 to E do Sample B tiles from P1, denoted as X1 Obtain corresponding B tiles from P2, denoted as X2 Obtain X′2 as random shuffling of X2 for i ← 0 to I − 1 do for b ∈ B do yb1 = fKP-FCNN(xb1) yb2 = fKP-FCNN(xb2) yb′2 = fKP-FCNN(xb′2 ) Compute the weights Wk considering yb1 and yb2 Calculate weighted deep clustering loss L1 Calculate weighted deep clustering loss L2 Calculate temporal consistency loss L1,2 Calculate contrastive loss L′1,2 if i mod 3 = 0 then Use LDC = L1+L22 to modulate KP-FCNN weights else if i mod 3 = 1 then Use L1,2 to modulate KP-FCNN weights else Use L′1,2 to modulate KP-FCNN weights

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
网络架构
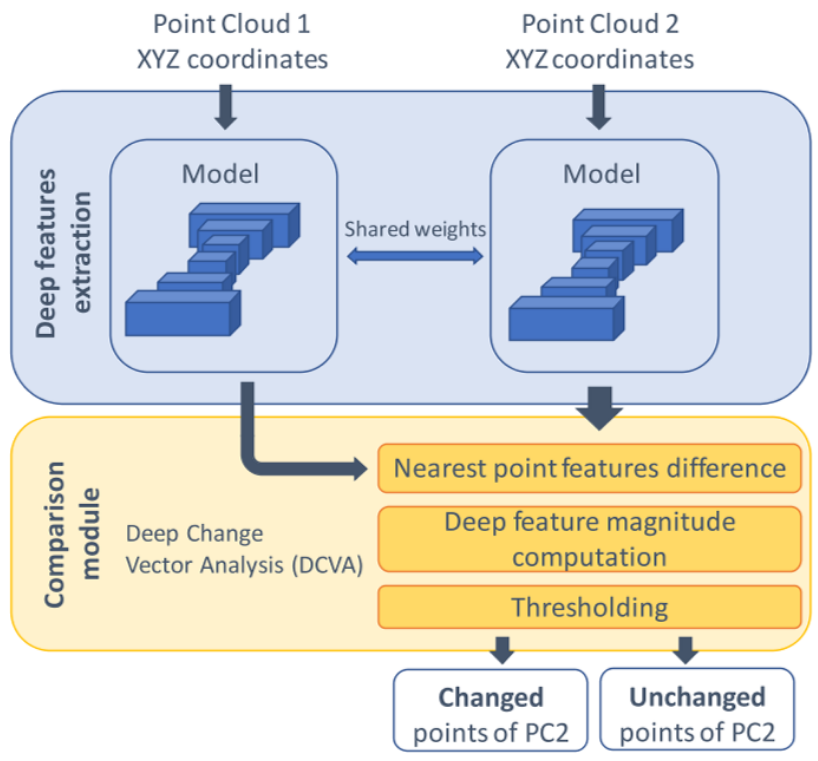
首先通过一个KPConv为基本单元构成的KP-FCNN网络结构(可以不使用最后一层仅有K个值的向量作为特征)进行特征的提取。潜在变化点云为新点云中的每一个点的特征-旧点云中距离最近的点的特征。利用阈值进行后处理得到最终的变化检测点云。
实验方法
数据集:AHN(共包含荷兰的四次调查,允许提取多日期变化,AHN3和AHN4被半自动注释,每一个点分配了一个语义标签,有地面、建筑物、水、土木工程结构(如桥梁)和杂乱物,本文手动为测试机中的每个数据点标注了是否发生了变化(变化的定义为如果一个区域在两次测量中间新建或拆除了建筑、出现了新的植被、出现了新的杂乱物(如车辆、设备或者其他的临时结构)则认为是发生了变化))。训练数据集为AHN的tiles 31HN1_22,31HN1_23,31HZ1_04的子部分,测试集为37EN1_08的子部分。
将手动标注的结果和网络得到的结果比较,该预训练网络是在另一个任务上训练的。li8ru使用公开数据集上的标签进行的语义分割,选择的公开数据集应该和手头的未标注变化检测数据集相似,本文就使用的H3D(包括四个不同日期的点云,以及11个语义类的手动标注)来训练网络进行语义分割,然后把这个预训练的权重移植到本文的任务重,并利用AHN中的数据进行微调。
由于目前没有其他无监督的3D变化检测方法,因此基线方法选择使用有监督的Siamese KPConv网络进行比较,但是这个训练的数据集是在Urb3DCD上进行的,然后直接转移到了这个AHN数据集上,因此也视为无监督的方法。除此之外还有在AHN数据集上训练的Siamese KPConv也作为基线。
本文还和C2C、M3C2基于距离的传统算法进行了比较。这两种方法还利用Otus阈值进行后处理得到最终的变化检测结果。
设置:点云数据被切割为tiles的小块进行,为了确保每块tiles至少可以看到地面,因此选择的分割方法是从地面开始朝上的一个圆柱体。SSST部分的训练设置:KP-FCNN模型,训练使用半径为10米的圆柱和0.2米的初级子采样率(每0.2米采样一个点),一个epoch包含了6000个圆柱,一次处理10个。H3D数据集的11个类被合并成了7个类,用于适应AHN数据集。网络在90个epoch时才能收敛。SSL部分的训练设置:20米半径的圆柱和0.5米的初级子采样率。深度聚类损失中使用6个簇,训练15个epoch得到最佳结果,每个epoch用100个圆柱,一次处理10个,使用0.98的动量梯度下降法,初始学习率设为0.01,随指数递减。两个策略的最终结果都是以这个点云中所有点的特征都在作为输出的。在SSST中使用的特征是KP-FCNN的第7层的输出,而SSL则是第8层的输出。在阈值进行了二分类后,再对孤立的预测进行清理(形态学的方法),以空间平滑结果。
具体的孤立的预测清理的做法:①定义一个结构元素:正方体或者球体(三维,二维的话就是正方形或者圆形),②侵蚀:遍历所有点,在当前点上,如果结构元素的所有点都是前景像素,则该点为1,否则为0。③膨胀:遍历所有点,在当前点上,如果结构元素中存在点为前景像素,则该点设置为1。


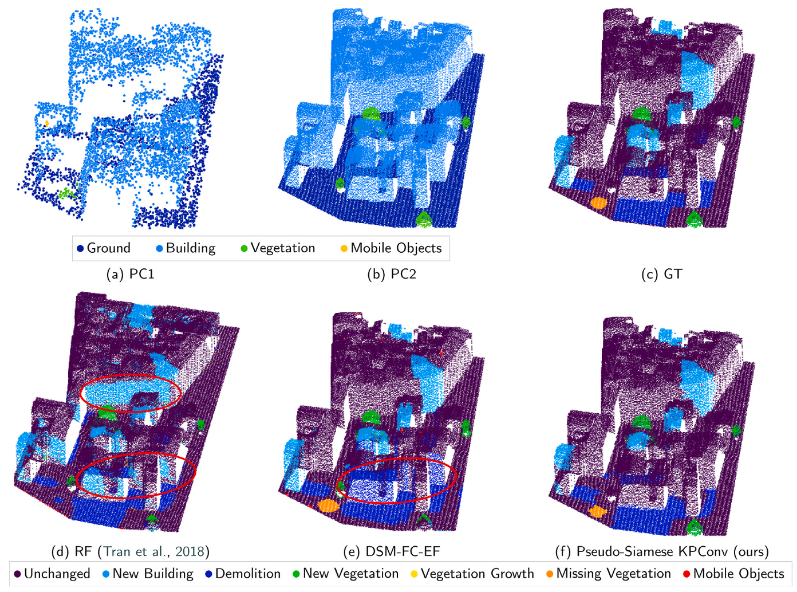
从表一可以看到SSL-DCVA方法在比较中表现最优,优于SSST-DCVA。C2C方法相对简单,也有这不差的性能,但是它有着明显的局限性,当一片树木区域在后续被和树木高度大致相同的建筑物所替代时,C2C难以分辨是否有发生改变(大多认为没有改变)。当然如果是旧建筑被形状和大小相似的新建筑替代,同样也无法准确的检测这种变化,它更多的可能只能用于几何变化的检测。M3C2方法可能是由于两次采集中,地面的高度略有改变,因此几乎所有区域都被认为已改变,可能是由于这种方法是为地球科学(检测地形或地址结构上的微小变化(厘米级别),为了地壳移动、侵蚀、沉积等)背景开发的,可能不适合城市环境。基于距离的方法可能无法区分地形和语义变化,只要对象的几何形状发生了变化。而学习方法似乎也能检索到小的改变的对象,这在基于距离的方法中是不可能的,除非包含太多的变化。
从Urb3DCD模拟数据集学习的Siameses KPConv在AHN上与SSST-DCVA相似,但不如SSL-DCVA,本文认为可能是因为AHN中的建筑和Urb3DCD数据集中的建筑有所不同导致的。对比SSST-DCVA方法,可能是H3D点云与AHN点云的分辨率和质量的不同导致的结果的差异。这表明了直接在与测试集具有相似属性的数据集上进行训练并使用自监督学习的最新发展的优势。与有监督的Siamese KPConv相比,还是有很大的改进空间的。在SSL-DCVA中,主要的差异在车辆、路标或植被等小型物体上,平屋顶的新建筑也有一些遗漏,通过对分割后的数据进行查看,可以发现平顶与地面是被分类到了同一类中,因此在比较特征的时候,没有显著的特征改变。这就导致了后期融合变化识别的难度。最后,在图中看到了有一个梯形的错误检测,这是由于地面的曲面发生了改变,但是实际上是不算到变化当中去的。
在植被区域的问题,在这些区域中即时物体的语义没有发生改变,但是LiDAR数据的复杂性也会导致点的分布有很大的变化,这就会导致预测称变化的点,因此结果在预测中混合了被标为变化和非变化的点。除此之外有可能植被区域已经发生了生长或者季节问题,导致表示存在差异。不仅本文的方法有这种问题,其他的基于学习的方法同样有这种问题,C2C方法在处理植被区域同样也不理想,这可能是由于LiDAR传感器的特征,但是对于植被获得的点比较杂乱,从地面到树冠的顶点都可以获得一些点,因此点到点的距离不是一个有效的变化指标。同时,在采集过程中,由于3DPC的遮挡问题,导致在比较PCs时,隐藏的部分可能不同,这导致DCVA部分比较点时出现困难。在训练时间上:SSL-DCVA较SSST-DCVA更有优势。


这是两幅变化检测的结果对比图
Siamese KPConv-2023-IJPRS
一种使用KPConv提取特征然后进行多值变化检测的网络
提出的原因
①在城市中的大多数物体主要是以垂直轴为特征,因此提倡使用3D数据进行变化检测。
②对于原始点云数据进行栅格化的过程中,栅格的大小的选择是十分困难的。
现有的直接处理3D PCs 变化检测和分类的传统方法主要有两类:前分类和后分类,后分类首先对每个点云进行语义分割,然后比较获得的标签来检测变化。前分类则是首先突出显示变化,然后对他们进行分类。这两种方法都会在每一个步骤(后分类的语义分割的时候可能会出现错误,前分类识别发生变化的地方可能会出现错误)中引入错误并累加后在最终结果出现误差。因此Tran提出了一种随机森林的方法使用点分布、几何属性、地形高程、激光雷达的多目标能力、日期之间的相关手工特征使用单独的步骤直接进行变化检测和分类。
处理3D PCs的深度学习的框架主要有三类:基于投影的方法、基于离散化的方法、基于点的方法,基于投影的方法就是将3D数据投影到2D平面,然后利用现有的2D方法。基于离散化的方法同样,就是将3D数据进行体素化后利用3D方法表示。但是这些方法由于点云数据自身的不规则性,都会带来严重的后果,容易丢失信息以及可能出现空单元。因此在早期很受欢迎,现在应该把注意力放在基于点的方法上。
基于点的开创性工作是PointNet,但是PointNet有较大的局限性,后续引入了替代PointNet的策略卷积,通常将点云数据映射到图结构上后进行变化检测,但仍然局限于2D,因此现在考虑到点卷积的工作,利用点卷积能够使变化检测任务使用现在流行的架构,encoder/decoder,Siamese等。
在点卷积中,存在着核函数定义的问题,主要有两类,第一类是用多层感知机将特征差作为输入,得到输出作为权重。另一类则是利用几何核。利用多层感知机作为核函数,最终需要更多的训练参数却仅能表现出有限的性能,而几何核则是利用几何核作为核函数,几何核可以是基于KNN的线性函数,多项式函数,在体素中的权重或者是核点。KPConv在分割和分类任务重取得了很好的效果,所以在本文中使用KPConv特征提取网络。
网络架构

encoder中共有5个堆,每堆有两个卷积模块,除了第一个堆都是KPConv以外,其他的堆的第一个卷积都是Strided KPConv,得到最后的特征进行,将两个点云的特征差异作为decoder的输入,然后进行上采样后和之前层的特征差异进行拼接,并且进行普通的卷积。得到最终的分类结果。
实验方法
数据集
Urb3DCD(包含了3个类别,其中可以模拟2种不同类型的变化),为了能够评估更困难的条件下的性能,Urb3DCD-V2(新增加了植被(不同模型的树,调整大小以及旋转)和移动物体(车辆等,随机(现实中存在的)他们的大小和长度),包含了7个类别),在Urb3DCD-V2的中共有三个子数据集,通过低密度条件模拟了一个子数据集1。由于本文认为对于变化检测的最具挑战的情况是跨传感器的情况,因此模拟了另一个子数据集2,其中第一个点云具有低密度、高噪声的性质(模拟卫星摄影的PC),另一个点云具有更高密度和非常低的噪声(模拟航空激光雷达采集的PC)。通过对训练、验证、测试区域模拟10,1,3次后得到点云场景。上述的操作都是合成数据集的。由于点云数据的遮挡性,本文决定在数据集2中模拟这种遮挡效果,通过改变模拟的ALS飞行计划,使得两次采集之间的遮挡区域有所不同,达到真实世界的情况。第三个子数据集主要的目标是关注多重变化分类任务,对于整个点云来说的,数据集通过从之前模拟数据中提取一对15米半径的圆柱性区域,每对圆柱形区域的标签是基于其中的主要类别给出,如果一对圆柱中有太多不同的类别了,则删除该对数据。最终共有5类:无变化、新建筑、拆除、新植被、丢失的植被。


AHN-CD(通过荷兰AHN3,4 双时相数据,构建了一个新的数据集,定义了四个变化的标签:未变化、新建筑、拆除、新杂物,桥和杂物合并,删掉了水的点,在这个数据集处理的时候,由于没有直接对应的点,因此在比较的时候,对于新建筑和新杂物,计算最近的点作为对应的情况,然后比较差异,对于地面,则在AHN3中找到2D坐标下最近点,然后比较Z轴高度差异,如果这一部分的点的数量少于200就认为没有发生改变),Change3D(2016、2020的荷兰Schiedam市的街景PC对,还提供了每个点的RGB信息,共有78个3D场景,741个城市对象,通过其坐标和相关标签进行识别,被手动注释为:无更改、删除、添加、更改或颜色更改,存在着类不平衡的问题)

实验设置
变化检测:传统的方法使用Tran提出的手工特征用RF模型进行比较,深度学习方面的baseline由于没有直接使用pc作为输入的方法,因此使用的是从pc提取的dsm作为输入的2D矩阵,然后使用DSM-Siamese(2D卷积)和DSM-FC-EF(全连接层,早期融合),设置共享权重和不共享权重的Siamese。
变化分类:将Siamese KPConv Cls与SiamGCN进行比较,SiamGCN依赖于EdgeConv提取特征且最终进行最大池化后进行合并操作,还有在Change3D上与PochaDeHH(一种基于直方图聚类的完全手工方法)和HGI-CD(依赖于手工制作和基于学习的特征,学习的部分来自于GCN)比较,这两种方法只能在Change3D中使用。
利用圆柱形对大型点云切割成小份点云,在测试集中的重叠的点使用概率均值进行分类,对于类不平衡问题,在训练时,利用加权随机抽样圆柱形对样本数据集进行平衡。以及通过旋转,随机高斯噪声达到数据增强的目的。
第一个子采样率为在模拟数据集设置为1m,圆柱体半径设为50,对于真实数据集AHN-CD,dl0设置为0.5m,圆柱体半径为25。对于Urb3DCD-Cls和Change3D,输入的半径为15米和3米的圆柱,子采样率为0.3,0.06。损失函数为负对数似然损失。0.98的动量梯度下降法。初始学习率为1e-2,对于KPConv Cls外,初始学习率改为1e-3,其他的都相同。
和KP-FCNN相比,本文的网络在最后的分类层中加了dropout用于防止过拟合,但是在Siamese KPConv Cls中没有加。除此之外,为了防止过拟合,还加入了L2损失正则化约束权重。
对于对比的方法RF,在低密度模拟数据集上设置了5m半径,为MS模拟数据集设置了4米半径,AHN-CD设置了3米的半径。
对于Urb3DCD-V,深度学习的方法DSM分辨率设置为0.5米,AHN-CD中,DSM的分辨率设置为0.3米

性能评价分析
mIoU和mAcc(每个类的准确率之和除类数)
虚拟数据集中


可以看到在低密度激光雷达的Urb3DCD-V2数据集中,Siameses KPConv方法在mAcc和mIoU上无论是否共享都大大的改善了结果,与传统的使用手工特征的机器学习算法比较,提高了30%的mIoU,除此之外,相比于光栅化为DSM的方法而言,直接处理3D PC数据是有较大的提升的,而Siamese和早期融合的全连接的方法在性能上相近,但是Siamese的稳定性不是很高。本文认为,在PC光栅化为DSM时,训练集的大小显著减小,而DSM的网络依赖于较小的训练集,所以认为他更容易拟合,因此伪Siamese的网络结构反而mAcc和mIoU有所下降。
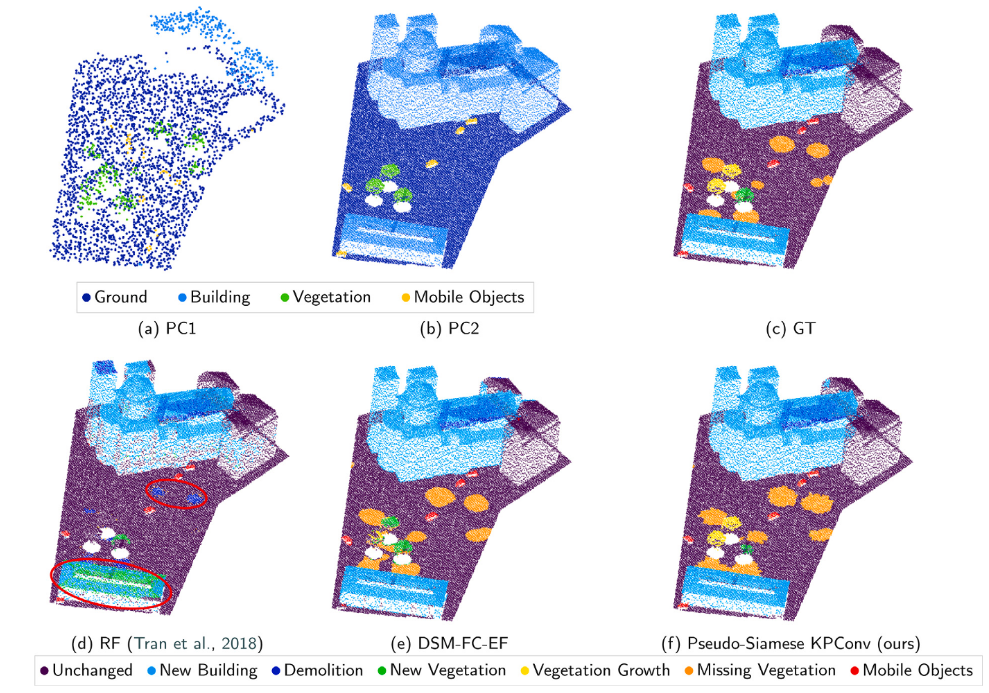
从表八可以看到,本文的方法在新建筑、新植被、移动物体和不变类别方面有着比较好的表现,而其他的DSM的方法在移动物体方面的表现较差,本文认为是由于在0.5m的平均密度下,移动对象仅有几个3D点表示,这导致了在光栅化时会有更加明显的信息丢失,因此基于DSM的方法得分很低,植被生长类别是最难预测的,因为这个和缓慢的变化有关,并不是大规模的变化。而且在植被上,点并不是规则分布在表面的,激光雷达可以穿透树叶。笼统的表示的话本文的方法基本与事实一致,而RF的方法不太令人信服。它混淆了新建筑和新植被类别。与基于手工特征的RF算法相比,基于深度学习的方法在这些不同的被遮挡的点云中表现的更好,本文的方法似乎能够整体的理解对象,这种可能本文认为可能是来自于特征提取过程中不同尺度。DSM的方法在处理隐藏里面的时候也能够提供准确的结果,但是由于DSM的定义,导致预测仅在建筑物的屋顶进行,如果屋顶没有改变,那么在3D重投影时,下面的整个立面也会被标记为没有变化,同时在遮挡时存在着空白像素是由插值进行填充的,这以为着建筑物的边缘的不准确。DSM-FC-ER方法会把小屋顶细节与移动对象混淆,这是由于在低密度数据集上,这些细节与汽车相似。



对于MS数据集,具有共享权重的Siamese KPConv没有伪Siamese KPConv好,这是显然的,因为MS数据集的两个点云模拟了不同的传感器,也就是说编码器应该有着对不同类型点云的独特的权重。而且即使不共享权重,可以看到结果仍然不如之前的数据集,但是与RF方法相比,仍能提高mIoU30%,在基于DSM的方法中,早期融合的全连接方法取得了最佳结果。和刚才的解释一样,由于光栅化的过程导致了训练集的数量大量减少,因此尽管这里的传感器不同,但是在DSM中Siamese仍然比伪Siamese取得更好的结果。在DSM中,大多数的差异来自于建筑物的边缘,这些边缘在无噪声DSM中非常明显,而在有噪声的DSM中模糊。即使是原始差异很大的PCs,经过光栅化成了DSM时,他们也会被转化的相似,因此Siamese比伪Siamese更合适。只有图像对来自不同的传感器图像时,才合适用伪Siamese,如光学和SAR。不同的数据对象,低密度和MS对于DSM的影响结果较小,本文认为可能是转成了DSM后,质量差异的影响由于光栅化时将多个3D点融合为一个2D像素时减小了。对于每一类的结果,总体的趋势和低密度数据集是类似的 。
真实数据集中
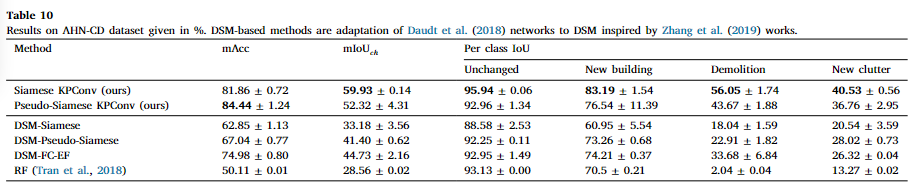
同样Siamese KPConv由于其他方法,Siamese KPConv比RF方法多31%的mIoU,同样有早期融合的全连接优于其他的DSM方法,相比于在虚拟数据集中的情况,所有方法在AHN-CD中的得分都较低。
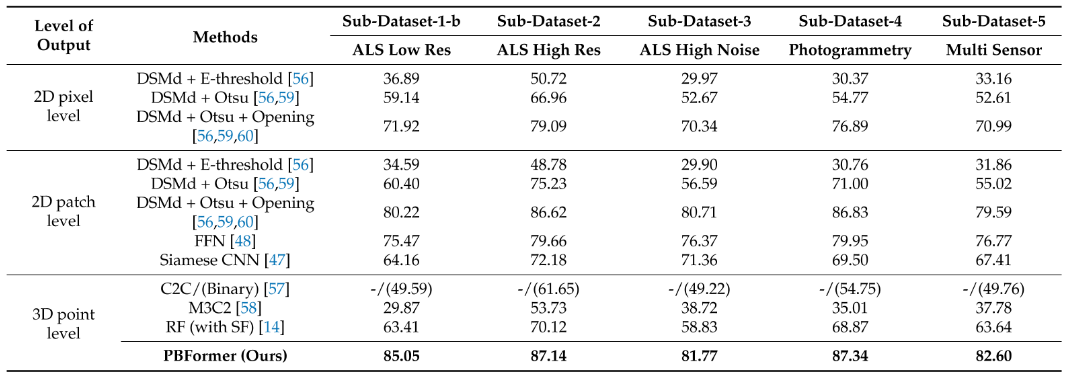
分类任务数据集(合成、真实)
在Cls中,Siamese KPConv Cls在各个类中都有着可靠的表现,且大大的由于SiamGCN,在Change3D中,Siamese KPConv Cls除了无变化以及颜色变化以外优于其它的所有方法。本文认为是由于颜色变化类别的代表性不足(数量过低),导致需要训练的方法得分较低,而且该类是唯一一个不表示几何变化的,尽管Siamese KPConv Cls在变化类中的表现由于其他的方法,但是它的mIoU并不令人满意,同时在不同训练次序中存在着明显的差异,这意味着模型不够稳定。变化这一类别代表的是某个对象中的微小变化,这导致检测这些变化更加困难。

对于AHN-CD的质量评估
在这个数据集中,所有方法都比虚拟数据集低,尽管在这些真实数据上进行变化检测和分类可能更为困难,但当比较AHN3和AHN4时,我们的结果似乎与可见的变化相一致。也就是说主要的困难时来自于对于变化的手动标签,本文通过对两个点云进行了自动比较,导致了许多误分类。这是由于即使标签没有变化,但是对象也可能发生了改变,通过人工手动修正注释,一些原来没有改变的点可能会改变,而本文的方法实际上是预测到了这些变化的。

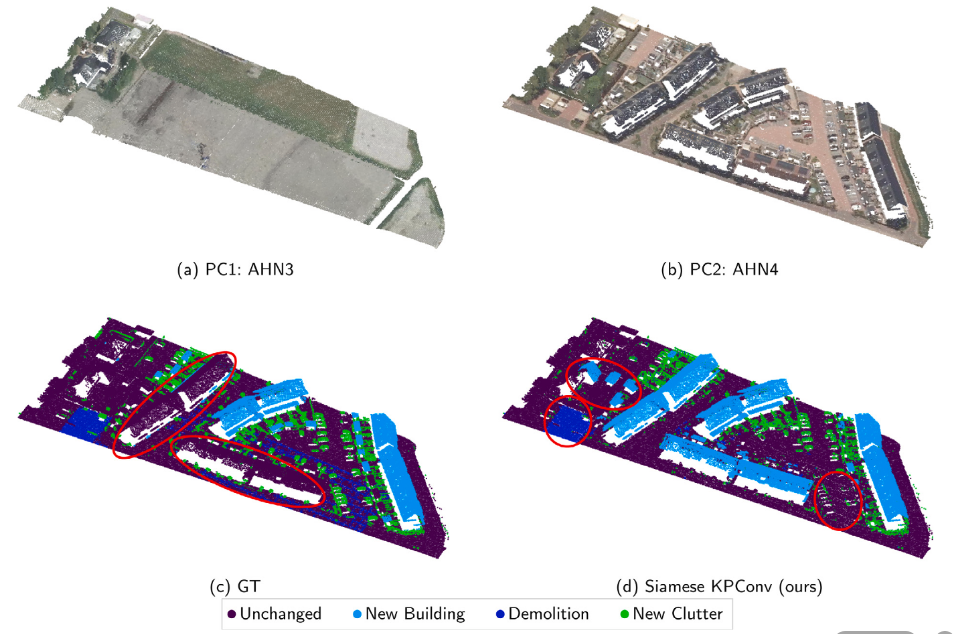
除了由于一些标签的标注错误导致的结果较低以外,还有因为AHN中clutter类包含的对象过多的原因,不够清晰的界定杂物和建筑。且在AHN3和AHN4中,建筑类的定义并不完全相同。同时对于拆除类,在训练数据集中仅占0.2%,这种不平衡分布解释了拆除类得分较低的原因。而且拆除类的情况是比较困难判断的,一个被拆除的温室可能在旧的点云中被映射为地面上的点和其屋顶上的点(由于LiDAR信号部分反射在玻璃表面,部分穿过它并反射在地面上)。
尽管AHN-CD数据集的标注不是完美的,作者仍认为在这样的真实数据上进行测试是有意义的。由于标注的不完美性,分析和解释结果时应小心,并与其他方法进行比较。作者的方法在某些情况下提供的结果比地面真实值更接近现实,这突显出该方法对于错误标注数据的鲁棒性。为了确保某些区域的地面真实值是完全可靠的,对AHN-CD测试集的一部分进行了手动标注。选择的子区域被认为是每个变化类别的代表。这个子区域的结果显示了作者的方法与其他基于手工特征或DSM的最先进方法相比是更好的。尽管“clutter”类的结果不如其他类别那么令人满意,但它仍然比其他方法好。这个类是多种对象类型的混合,这增加了分类的挑战。
迁移学习
本文探索在特定数据集上(模拟数据集)训练模型,并用于其他数据集上(真实数据集)的泛化能力,结果都比直接在其他数据集上训练差,但是伪Siamese KPConv仍然比其他的方法表现好。不同的类别有着不同的泛化能力,比如新植被或植被生成的得分较低,而失去植被得分和直接训练的方法差不多,这意味着在失去植被上面的泛化能力较强,而RF的泛化能力较差,尽管相比于深度学习的方法所需要的训练集是比较小的。由于训练集的棘手问题(自动标注存在错误,手动标注工作量太大),所以本文试想在模拟数据集上预训练,在真实数据的例子上进行微调,由于虚拟数据集和真实数据集的类别不同,因此网络的权重只在最后一层分类前相同,而最后一层重新训练,在训练的数据集相同的情况下,虽然伪Siamese KPConv有着更高的结果,但是共享权重能够提供更好的泛化能力。微调的策略使得在100个训练数据时就能达到饱和的mIoU。
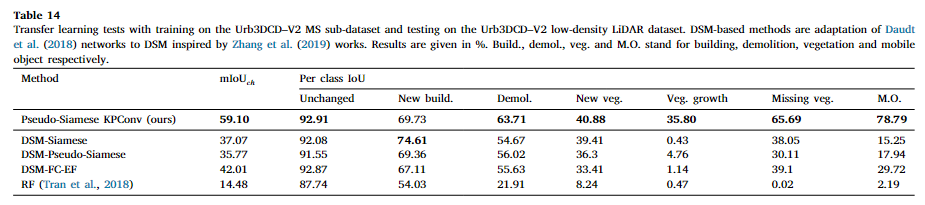
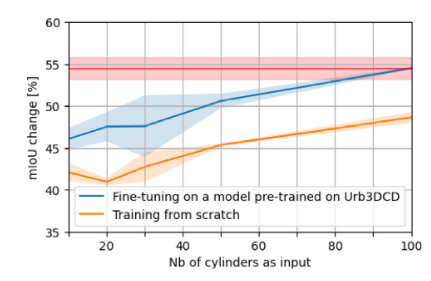
PBFormer-2023-RS
一种对于某点提取k近邻特征然后利用transform(带位置编码)提取局部特征和k点特征然后利用k点特征不断融合双时相局部特征后进行分类的多值变化检测网络。
提出的原因
①由于前CD后分类或者先分类后CD的方法都会依赖于CD或者分类所带来的限制,因此本文选择使用一次性CD和分类防止这种问题的出现。
②相比于手工制作的特征来说,从深度神经中提取的特征更有力且更具有普适性。
网络架构

对于PC1中的每一个点,找到k近邻用于提取特征,首先flatten这些近邻后,利用transformer进行编码,输入为k个点的坐标投影到d维度+k个点的相对位置编码(各点-中心点后进行归一化然后利用MLP进行投影),输出为k*d维度的特征,取第一个特征作为这k个点的全局特征,其他的k-1*d作为局部特征,然后输入到BT中。

对于一个时期的全局和局部的特征,让全局特征不断融合两个时期的局部特征,从而达到交叉融合的目的,最终将两个时期的全局特征求和输出作为PC1的该点的特征。将这个特征输入到Classification Head中得到变化检测/分类的结果。
实验方法
数据集:Urb3DCD(新建、拆除、未改变)
adamW优化器,没有改变任何参数,初始学习率设置为0.0002,通过余弦退火调度,并每次进行暖启动。
50个epoch,一个batchsize = 32,邻居数量为256,交叉熵损失函数,PT中4个transformer Encoder,BT中四个交叉块。
评价指标:mIoU( 1 n ∑ i = 1 n T P F N + F P + T P \frac{1}{n}\sum_{i=1}^n{\frac{TP}{FN+FP+TP}} n1∑i=1nFN+FP+TPTP)
选用的benchmark:①基于dDSM和经验阈值的方法,②在2D图像上的Siamese FFN/CNN,③C2C,一种基于距离的传统方法,④M3C2,在C2C的基础上利用一些其他尺度进行的基于距离的传统方法,⑤利用手工制作的稳定特征并用于RF的机器学习的方法。

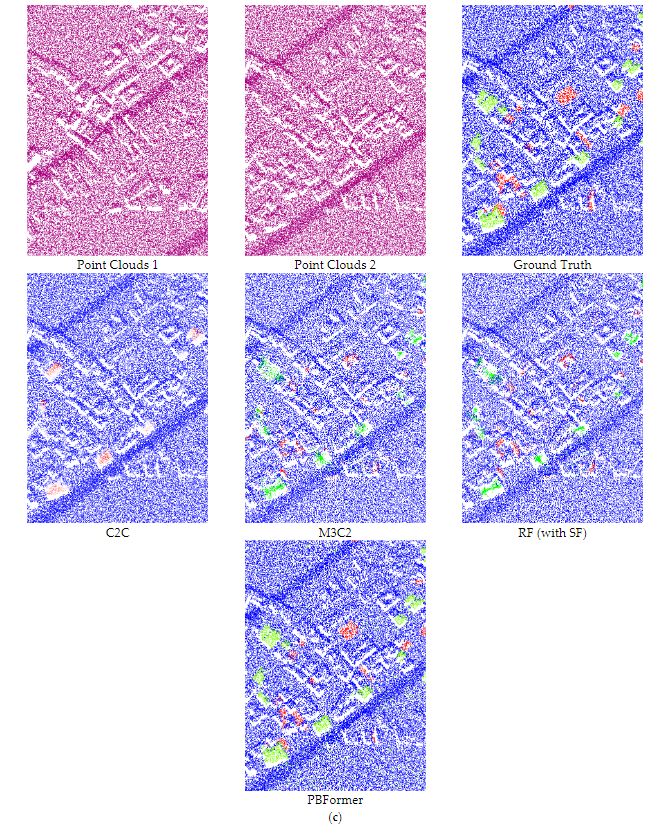
①dDSM的使用经验阈值的表现并不理想,改成Otsu阈值和开放运算可以明显提升性能,但是只能从俯视图的视角观察到三维点云的变化,②由于网络简单以及不是专门为点云设计,导致FFN和CNN的结果不明显,③C2C只是给出了二值结果,具体的准确性完全由经验阈值决定,尽管额外使用了模糊阈值,但即使在视觉效果方面,它仍然不令人满意,④M3C2的结果接近最低mIoU,这是由于是手工制作的特征鲁棒性不够,特别是噪声过多时,⑤RF的结果也仅仅是一般,⑥PBFormer的结果在测试集中表现出色。
消融实验
①去掉 SPE 和 BT,使用 ViT 的共享变压器编码器,并使用差异化作为特征融合方法。
②用学习的位置编码替换SPE。
③使用SPE,但是BT换成直接差分。
④不使用SPE,利用MLP替换掉差分。
⑤学习到的位置编码和MLP。
⑥使用SPE和MLP。
⑦删除SPE,使用BT。
⑧使用学习到的位置编码以及BT。
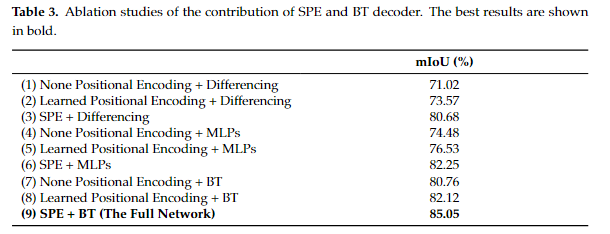

可以看到Transformer的优秀,仅仅只是基本的Transformer结构,也能让mIoU轻松过70。而位置嵌入促进了变压器学习点序列。无论是什么样的位置编码的方法都能够提升mIoU的评分。而SPE的位置编码和BT的融合方法对性能影响都是很大的。
性能分析:
由于C2C的高效率仍然是一个值得考虑的方法,尽管其对阈值的过度依赖以及对局部几何结构的忽略而导致结果的不如意,虽然可以使用模糊阈值处理,但是得到的结果仍然不是很完美。
M3C2的方法在视觉和质量结果上都不好,看起来似乎是被平滑了,导致一些分布在边缘的点无法被识别或者分类。
RF方法展示了基于机器学习的方法和传统方法的差距。
本文认为M3C2和RF方法的较差结果可能是由于数据集的分辨率较低带来的。这点在子数据集一和子数据集二中的结果改善相符合。同时PBFormer也受到分辨率的影响,高分辨率对于PBFormer也能提升质量,但是在处理稀疏点云时,PBFormer也能通过knn获得足够多的点用于学习输入之间的特征,这也是PBFormer优于其他方法的根本原因。
在用于变化检测的数据中,与未变化区域相比,变化区域通常较少。这对 PBFormer 不利,因为它是基于每个类别样本分布均匀的假设而设计的。PBFormer 可能在变化和未变化对象之间的边界上表现不佳,尤其是在噪声很大时。PBFormer 是一个输出逐点变化的网络。如果建筑物的边缘因高噪声而变得模糊,PBFormer 可能无法充分理解建筑物的结构。
FCD-GAN-2023-TPAMI
Fully_Convolutional_Change_Detection_Framework_With_Generative_Adversarial_Network_for_Unsupervised_Weakly_Supervised_and_Regional_Supervised_Change_Detection-TPAMI-2023
一种利用判别器生成器和分割器进行无监督/弱监督/区域监督的网络架构。
周报内容
本文主要讲训练的逻辑和思想。
在变化检测时,可以使用语义分割的数据集,通过语义改变来寻找变化的点。但是语义不改变不一定就代表着是没有发生改变的地方,比如建筑的拆除,增加,植被的增长等,而且这种语义分割后 的标记是十分花费时间的。
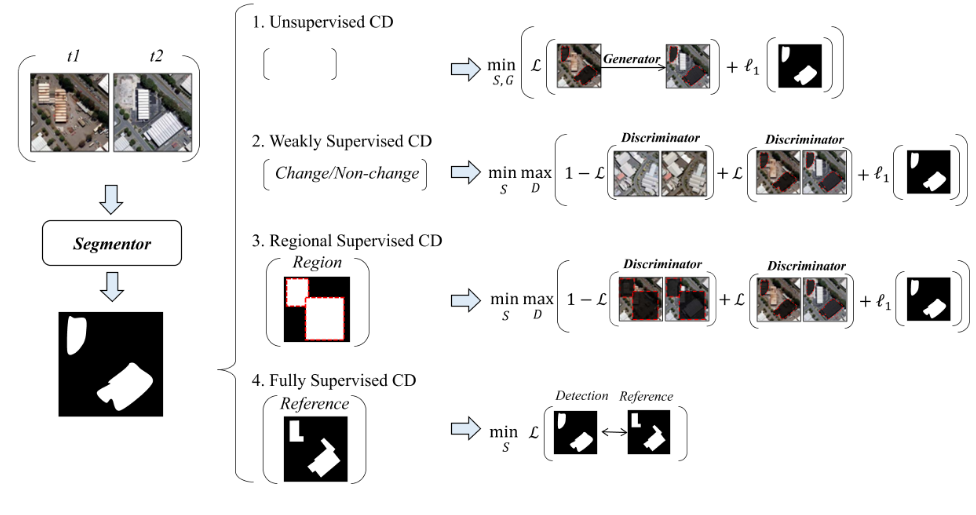
本文的无监督变化检测的思想该模型希望找到一个变化区域,以便在剩余区域中,一幅图像可以准确地预测为另一幅多时相图像。弱监督变化检测的思想该模型希望找到一个最小的变化区域,这样在没有变化区域的情况下,变化的图像对可以被区分为与真实的未变化图像对相同。区域监督变化检测的思想是该模型希望找到一个最小的变化区域,以便在没有变化区域的情况下,通过替换预先给定的参考区域内的内容,可以将变化的图像对与模拟的未变化图像对区分为未变化。
无监督变化检测中的训练
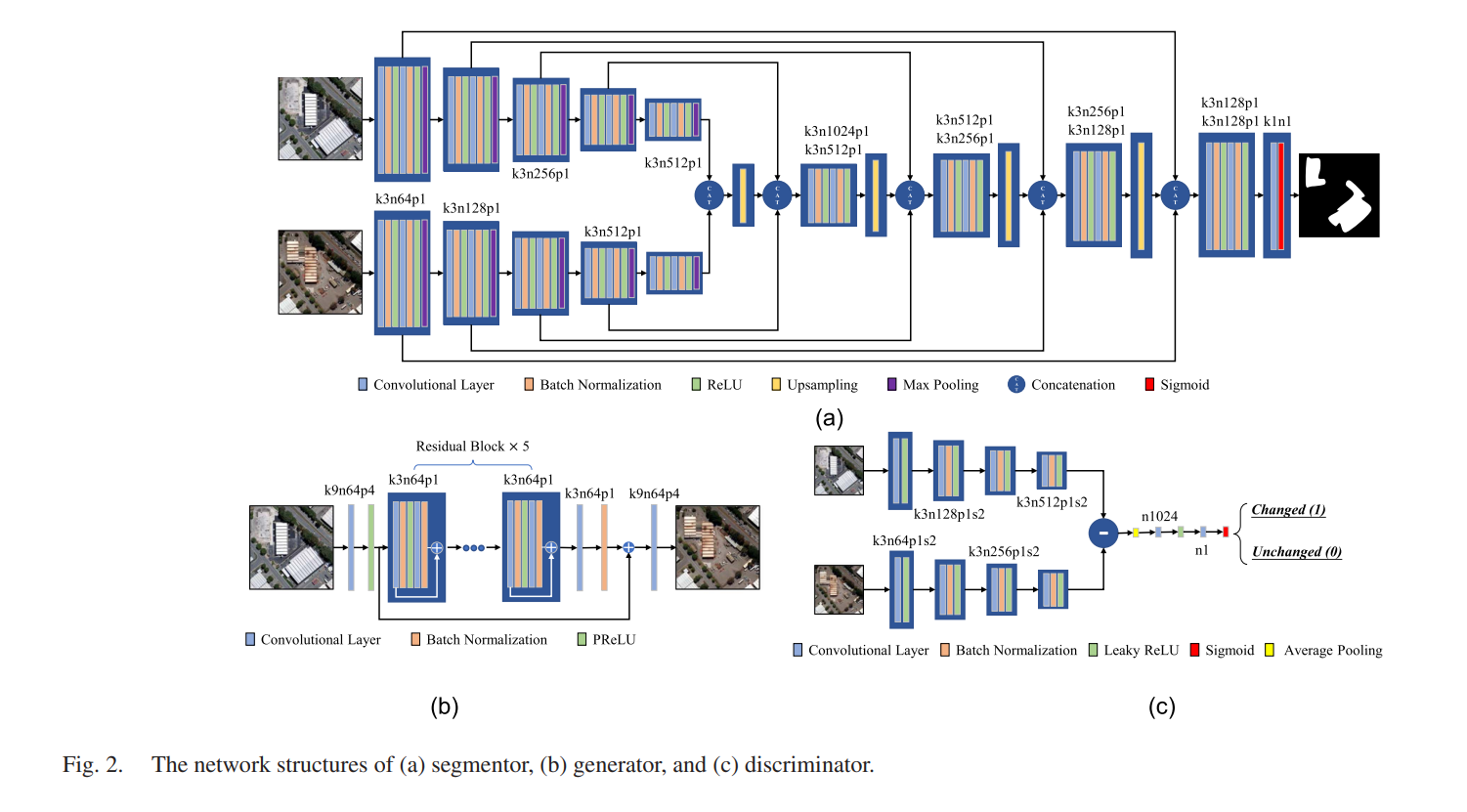
首先分割器进行变化检测,得到了变化检测的结果图后,生成器利用第一期的图像去生成第二期的图像,然后在这两个图像中,挖去变化检测的结果图,然后看生成的挖去了这些地方是否和原来一样,如果不一样,意味着生成器不好/分割器不好,回去训练生成器得到除了变化区域其他生成区域都一样的图像/回去训练分割器得到只检测到变化区域的图像。逐步迭代让生成器变好、分割器也变化。
损失函数
用于最小化生成器损失的函数:分割器产生的区域去除后,生成器的图像和第二期图像尽可能相同。

l1正则化损失:用来约束这个区域尽可能的小
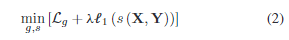
生成器损失:第一项在生成器固定时让差异大的尽可能认为是改变的。在分割器固定时,尽可能差异小。第二项让在vgg16预训练下的第29层中生成器产生的图像和实际图像除了掩码的区域的特征尽可能相似。

弱监督变化检测中的训练
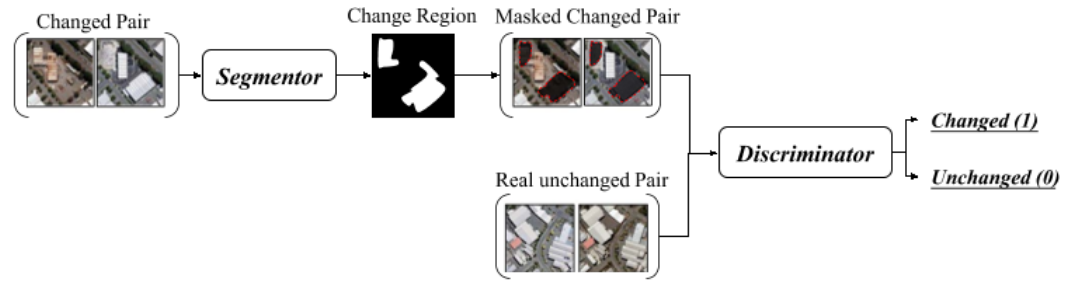
将多时相图像通过分割器得到变化区域后,遮盖后假装是没有发生变化的图片,尝试欺骗判别器,但是由于只有这种情况会导致判别器很容易判断出来mask的存在,而不是真正区分Change和Unchange,因此加入了真实的未改变图像对,让判别器是从图像本身的角度来进行判别。
损失函数
这个损失函数针对于非掩码区域是为了防止判别器通过识别掩码来进行是否是change对进行判断,而不是在输入的时候Real unchanged pair把这些地方给挖掉了。
损失函数①:判别器能够判别出来不变的以及改变的经过了掩码后伪装的不变的。

损失函数②:使分割后的masked作用在了Change图片对后能够尽可能的不被发现,限制不要让change图片对的分割过大,限制不要让unchange的分割出现,生成器损失可以不需要的。
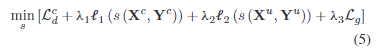

注意在计算不变图片对的判别损失的时候也需要加上同样的分割,这是为了保证最终判别器识别的是图片本身是否发生改变,而不是是否有掩码存在。
区域监督变化检测中的训练
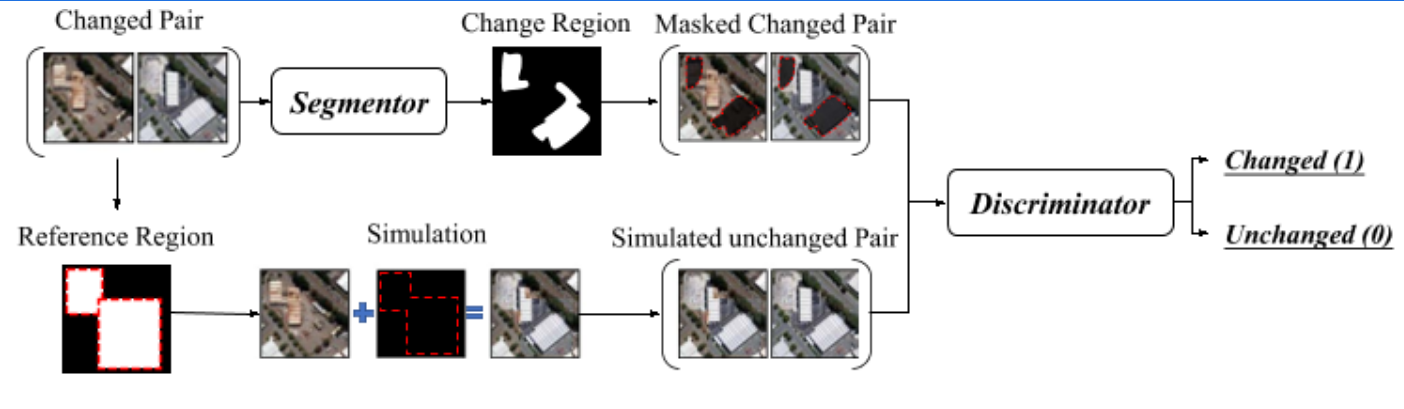
类似于弱监督变化检测中的方法,但是此时的Real unchanged Pari需要修改成第一时期的图像将参考区域的图片挖去后用另一时期的图像进行填充,注意此时的Real unchanged Pair还是原来的图片,并不是其他的图片,这是因为和弱监督学习中的标注不同,这里没有每个图片对的明确的标签,因此需要用这种情况来作为模拟未改变的图片对。其他的就类似于弱监督学习中的方法了。
损失函数
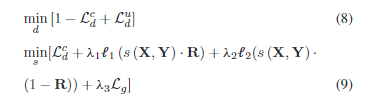

注意进行损失函数的区域为参考区域即可。
实验方法
数据集
在无监督变化检测中,选择了两个高分辨率多时相GF-2遥感图像数据集,时相1在2016.4.4,时相2在2014.9.1,图片大小为1000*1000,RGB+红外,空间分辨率为4m,为了评价泛化能力,使用了一个多时相ZY-3图像数据集,图片大小为458*559,空间分辨率为5.8m,只有RGB。对于弱和区域监督变化检测,本文生成了两个数据集提供使用。弱监督变化检测中使用的是WHU中的建筑变化检测数据集,其中包含了2012、2016两时相的航空高分辨率图像,图像大小为32507*15354,RGB,分辨率为0.3m,目标变化是建筑物变化。为了生成弱监督变化检测数据集,将这两幅大图分割为200*200个小图像以及变化参考,只要有改变,这个图像对就被标记为已更改,最终得到9935个不便对和2616个变化对,其中有一些景观的变化没有碑额定义为目标语义变化。

区域变化检测的数据集是Onera卫星变化检测数据集,包括了由Sentinel-2卫星获取的24对多时相图像,包括了14对训练和10对测试,有13个光谱波段,空间分辨率分别为10、20、60m,只选择了10m分辨率的RGB和红外,对于部分对重新进行配准减小误差,并且裁剪出相同大小的子影像和变化检测参考图。最终在所以变化参考的连通区域绘制一个边界框并向外扩展10个像素。
实验设置与结果
无监督
设置
1000*1000的图像分割为多个小块,考虑到可能处理像素边缘时可能会出现问题,可以使用重叠切片去解决。在WH和HY数据集设置一块patch为220*220,重叠了10像素,对于ZY数据集,patch为200*200,最终都只使用中间的200*200的patch进行使用。adam,epoch大小为50,batchsize=10,分割器中阈值为0.5,归一化预处理,L1损失函数的权重为WH 0.75,HY 0.65,ZY 0.81。生成损失中的μ=0.2
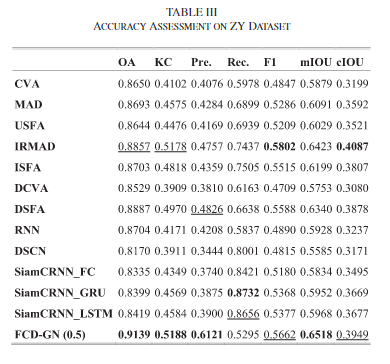
结果
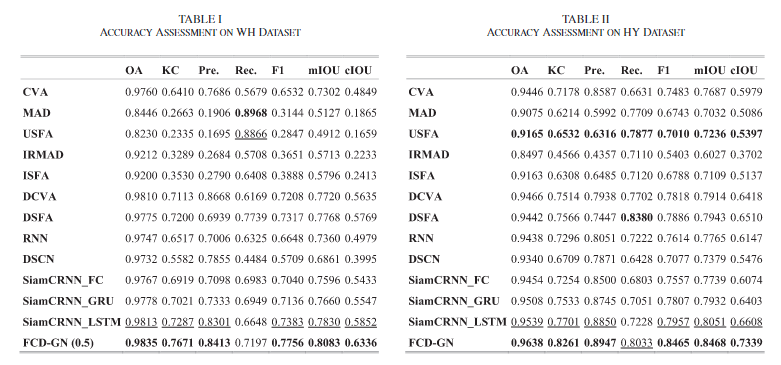
评价指标:OA(整体精度)、KC(Kappa系数)、Pre(查准率)、Rec(查全率)、F1、mIoU、cIoU
相比于之前的方法,包括新的比较方法(DCVA、DSFA),本文提出的方法在几乎所有的指标上都是最好的(除Rec),同时在ZY上有着不错的泛化能力,仅在F1、Rec、cIoU差了一些。

Fig.12为ZY数据集,FCD-GN表现了更好的准确率,但是在查全方面是远低于SiamCRNN_LSTM
弱监督
设置
FCD-GAN中存在两种损失,如果使用生成损失则为无监督学习的方法了,本文认为生成损失用于发现低层变化,判别损失用于发现高层和语义变化。与USCD想要找到所有景观变化相比,WSCD只关注目标变化,例如BCD数据集中的建筑变化。因此,判别损失是主要损失。预处理归一化,adam用标记不变的图像先训练生成器,然后在后续优化中冻结权重,使用RMSProp对分割器和判别器进行优化,由于变化辨别的任务比变化分割的任务更容易,所以分配给判别器的学习率比分割器的学习率低得多。epoch=50,生成时batchsize=50,对抗时batchsize=20。
对于生成器,在训练时使用FCD-GN的架构,内容损失权重为0.5,在训练分割器的时候不使用判别损失,权重为λ1、λ2和λ3的权值分别为0.5、1和1,在不具有生成器的学习中,权重为λ1、λ2和λ3的权值分别为0.5、1.5和0,在具有所有损失的学习中,权重λ1、λ2、λ3的权值分别为1.6、1.5、0.2。利用CAM作为基础提取特征网络。
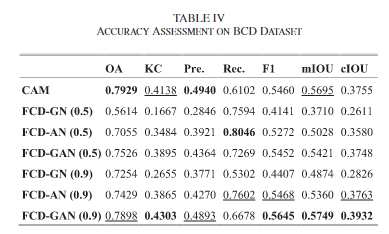
结果
可以看到没有对抗过程的网络结构最终得到的效果只获得了非常低的准确率,这是由于UCD会找到所有变化的点,而不是找到高级语义变化的情况,而BCD这个数据集标注时是语义发生变化才属于变化的标签。因此需要抽象出高级的特征。只有对抗过程的FCD-GAN与CAM具有相似的精度,这意味着GAN结构也可以用于弱监督分割。生成损失权重较小的FCD-GAN能够在Kappa、F1、mIoU和CIoU有更好的表现。

从左图中可以得知,分割器的鉴别损失收敛在0.5左右,这表面鉴别分割器的结果为变化的对是困难的,而鉴别器的鉴别损失收敛在1,说明了在判断真实对为不变化的对也是困难的,这都表明了这是处在一个对抗的过程中,并不容易区分假样本。

从分割的密度以及变化图可以得到一些有趣的结果,与CAM相比,FCD-GAN能够得到更好的变化的轮廓,但是从FCD-GAN的二进制变化图可以看出,FCD-GAN在边界的时候是断断续续的,而不是像CAM有着清晰的连续的分界线。CAM仅在变化景观的中心分配高密度,而FCD-GAN几乎可以以最高的权重标记变化景观的整个形状。CAM发现了一些假警报,这些假警报被改变了,但目标语义结构没有改变。FCD-GAN在某些方面表现更好,同时也突出了车辆的变化。
区域监督
设置
和WSCD基本相似,只有使用另一时相图像参考区域的像素替代该时相的图像参考区域的像素用来模拟不变的图像对有区别。
对于生成器的内容损失权重为0.1。在只用生成器的FCD-GN中,λ1,λ2,λ3的权重分别为0.1,2,1,此时是一个无监督模型。在只用判别器的FCD-AN中,λ1,λ2,λ3的权重为0.1,2,0,完全由区域监督信息训练。与完全监督的模型(使用相同的分割器,利用BCE损失进行监督)进行比较。
结果
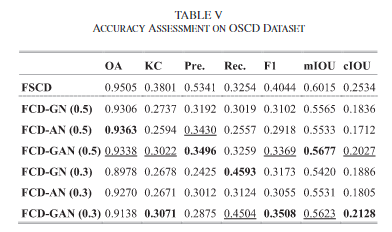
虽然RSCD模型不能与FSCD模型相比较,但是可以作为衡量RSCD性能的一个基线,在无监督的FCD-GN也获得了良好的性能,本文认为Sentinel-2获得的OSCD数据集中标记的变化是根据光谱变化来解释的,而这种光谱变化是可以由USCD模型捕获的,因此能够取得较好的性能。而FCD-AN也能表现出令人满意的精度这说明了本文提出的对抗性过程在解释语义监督信息方面是有效的。FCD-GAN获得了最高的精度,虽然相比于FSCD模型,在F1分数方面的0.4044的精度比FCD-GAN的F1的0.3508高挺多,但是考虑到FSCD模型需要的监督信息,FCD-GAN的F1足够说明本文提出的架构的有效性了,图20说明了对抗性过程在训练中保持平衡。分割器可以有效地混淆鉴别器。图19显示了根据阈值的F1分数。0.3的阈值可以导致该实验中的最佳性能。
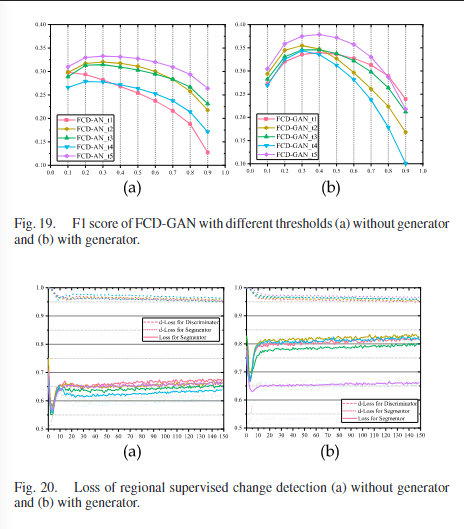

通过上图的检测结果可以得知,FCD-GAN倾向于比Ground Truth标注出更多的变化。这是由于仅靠区域监督无法排出框外所有变化类型,可能框外的一些变化不被标注为变化,但是这种情况是有很多种类型的,比如植被的生长和衰落,建筑的材料改变等(假设这些变化是不被标注为变化的情况),这么多的情况是无法由给定了区域就能够顺利的不被标注为变化的。
讨论
权重
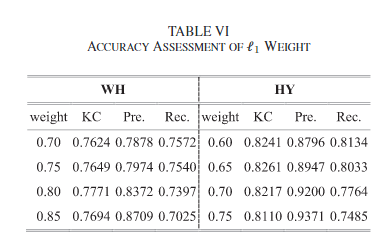
①当l1损失的权重较高时,分割器倾向于从图像中发现较少的变化,从表中的weight变化时的情况,可以权重越高,准确率越高、召回率越低。因此在可视化发现误报过多的时候,可以适当增加l1的权重。


②生成器的内容损失的权重μ,理论上,较高的权重会导致更多的考虑语义相似性(抽象出的特征)而不是光谱相似性。由于内容损失的权重增大会导致l1损失的权重降低,因此使用1.2对生成器损失进行归一化用于平衡l1损失和内容损失,从表中可以看到,内容权重越高,准确率越高,召回率越低。但是这与数据集是相关的。本文使用内容损失权重为0和0.4的情况绘制变化密度图,通过白色圆圈中的情况,可以发现,较高的内容损失权重对同一景观的光谱变化具有更强的鲁棒性,但也会减弱光谱损失的影响带来一些遗漏误差。本文中使用在ImageNet上预训练的模型作为内容提取 backbone。对遥感数据,推荐使用RSP预训练backbone以获得更好的语义表示。内容损失权重的确定与研究区相关,对应无监督变化检测是更关注光谱差异还是语义差异。高权重高语义。
③判别损失和生成损失,如果所有的变化都是目标,生成损失可以有利于无监督谱和语义相似度测量的性能。这是因为生成损失作用于更加低级的语义或者说是光谱的变化,比如OSCD数据集中就可以调高生成损失,但是如果在BCD数据集(只关注建筑物的变化),这个时候就需要抽象出高级的语义用于变化检测,此时需要调高判别损失。
FSCD和RSCD以及WSCD的不同点
由于大规模的训练数据集的标注十分困难,目前还只是二维,在三维点云中相关的数据集更加稀少。因此RSCD和WSCD的使用是十分有价值的,尽管不可能和FSCD有一样高的准确率,本文将FSCD和RSCD以及WSCD的区别认为是从标记点变化到标记语义不变。将维度上升,从高纬度进行学习并进行变化检测的判断。
假设图像中有5类地物,那么两时相图像可能存在5x5=25种变化模式,其中5种是无变化的。而在FSCD中,我们可能只关注4-6种目标变化,如植被-建筑,裸土-建筑等。但是在RSCD和WSCD中,我们不知道具体的目标变化是什么,但其余20种未标注的非目标变化需要通过图像级或区域级标注排除,具体的来说就是FSCD的标注难,但是网络能够比较容易的从这些标注中训练处怎么去找需要的目标变化,但是RSCD和WSCD则是通过反向的排除法去得到不需要哪些变化。因此对于RSCD和WSCD虽然标注的情况容易得到,但是需要大量样本用于训练。
约束条件
本文中的分割器是独立设置的,不依赖于其他的部分而进行改变,不同的变化检测认为的核心在于对应的约束条件(也就是不同任务中对应的假设),这些约束决定了如何使用分割器以及如何评估其输出。
在无监督变化检测中,关键在于生成器进行多时相遥感图像之间相关性进行关系的建立,本文只考虑了单向的生成器,但是多时相的生成器是值得探讨的,即从a->b->a。
在弱监督变化检测以及区域监督变化检测中,则是通过添加语义监督来明确指定什么是实际的变化,判别器和对抗性过程被用作约束,融合这种于语义信息。本文认为像素级的损失更适合分割器,GAN这种对抗型的网络更加适合使用于分割器的输出和参考之间的不等监督(输出为像素级别,参考的标注为图像级别),GAN通过高级语义信息的获取用于对分割器的输出进行对抗优化,对抗性过程可以微调决策边界,使其更加准确。
在完全监督变化检测中,约束是像素级损失,可以使用二值交叉熵损失或者DICE损失(F1得分)/焦点损失等。生成损失可能可以为FSCD进行约束补充,但是判别器以及对抗过程是没有用的,因为图像级或区域级损失与像素级损失相似但较弱的约束。
限制
由于本文主要是考虑架构的情况,对于每个器的具体的网络内部架构没有考虑。很多的先进的模块可以被添加到各个器中,如Transformer/attention可以加入到分割器中,对抗过程可以使用cycleGAN/bigGAN等,本文主要是提供了不同检测下的一个通用的框架约束去帮助分割器取得一个好的结果。
结论
本文主要是提供了一个可以在简单标注的数据集上进行像素级变化检测的框架,由分割器、生成器/判别器组成。但是仍存在一些问题,首先是在进行分割的时候虽然是准确的,但是在分割区域中却存在断断续续的零散的独立的像素,需要保持更改对象的完整性;其次由于由于数据集是使用的FSCD的数据集进行本文所需数据集的生成,所以数据集可能不适合本文提出的架构用于模型的构建,需要构建专属的数据集,同时可以添加其他的高级模块。本文证明了GAN 可用于弱监督分割。

