
- 1git配置修改.gitignore不上传node_modules文件目录到gitee码云_git不上传node modules
- 2艾默生Movicon Connext引擎:让数据采集、转发、管理更加高效、便捷、安全_micromine数据上传
- 3YOLOv10最详细全面讲解1- 目标检测-准备自己的数据集(YOLOv5,YOLOv8均适用)
- 4【yolov5】yolov5评估网络mAP时屏蔽指定的类_yolo不显示某一类别
- 5从零开始:构建、打包并上传个人前端组件库至私有npm仓库的完整指南_npm 上传组件到私有仓库
- 6RabbitMQ C++客户端SimpleAmqpClient编译总结(32以及64位)_simpleamqpclient 编译
- 7微信小程序添加用户隐私保护指引_微信小程序隐私保护指引弹框实现
- 8ModuleNotFoundError: No module named ‘import_export‘
- 9行为设计模式之策略模式
- 10基于springboot+opencv做人脸识别_org.openpnp.opencv
垂直领域大模型的应用更亲民_大模型在垂直领域的应用
赞
踩
在之前的文章有介绍过: 普通人(包括程序员)怎么follow大模型的发展和如何成为提示词工程师.通用大模型类似ChatGPT等,一般公司和程序员是无法超越。所以今天介绍一下大模型垂直领域的应用的做法.
1、通用大模型离我们有点距离
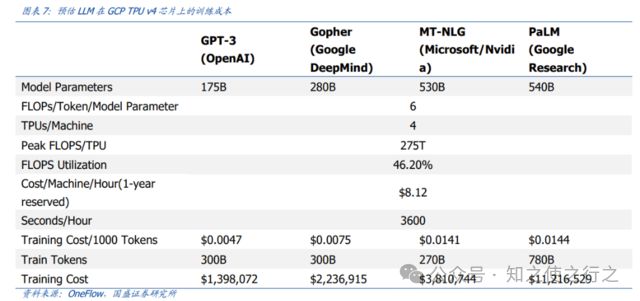
(1)、训练成本贵
国内证劵公司训练大模型花费的钱做过测算。起码100万美金以上,这对一些小型企业是没办法承担的。
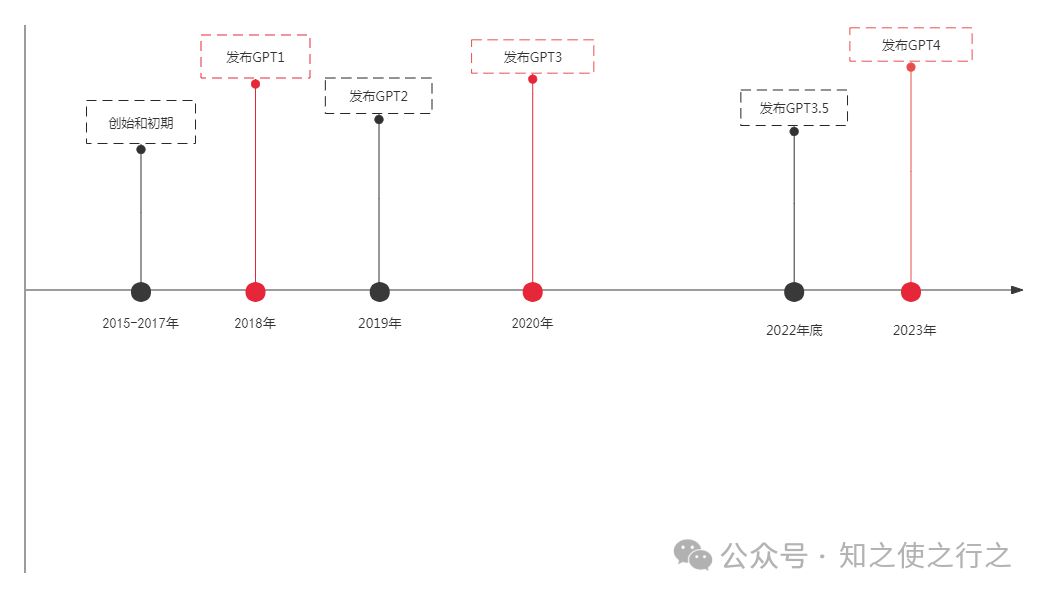
(2)、技术积累时间长
冰冻三尺,非一日之寒,openai的成功并非偶然, ,而是背后无数的努力堆砌而成。
(3)、东施效颦
并不是每块落石,都能激起水花朵。失败是常态。chatgpt的成功是属于幸存者偏差,它的成功,不一定代表所有人都能成功,即使成功也不一定超越过。
(4)、通用模型在生产效率上有受限

虽然2023年以来几乎很多公司都发出了自己的通用大模型,但是都还停留在“开放闲聊”阶段,这种泛娱乐的方式带来生产率是有限的。所以,以“开放闲聊”为产品形态的ChatGPT为例,“尝鲜“的流量在6月达到巅峰之后,就开始了出现下滑。
2、国内垂直领域应用和发展现状
人们需要的是能帮助我们实实在在地解决问题,能提高生产力和工作效率的工具。
下面的垂直领域应用的模型,基本上覆盖我们生活的方方面面:

当然不止上面所列的应用.更多请关注我
3、一般垂直大模型怎么做

Continue PreTraining: 一般垂直大模型是基于通用大模型进行二次的开发。为了给模型注入领域知识,就需要用领域内的语料进行继续的预训练。
SFT: 通过SFT可以激发大模型理解领域内的各种问题并进行回答的能力(在有召回知识的基础上)。
RLHF: 通过RLHF可以让大模型的回答对齐人们的偏好,比如行文的风格。
4、总结
一般垂直领域大模型不会直接让模型生成答案,而是跟先检索相关的知识,然后基于召回的知识进行回答。这种方式能减少模型的幻觉,保证答案的时效性,还能快速干预模型对特定问题的答案。
参考文章
https://blog.nghuyong.top/2023/08/26/NLP/llm-domain-specific/
https://github.com/hiyouga/LLaMA-Factory
https://github.com/HqWu-HITCS/Awesome-Chinese-LLM
https://github.com/liguodongiot/llm-action
https://writerbuddy.ai/blog/ai-industry-analysis
https://zhuanlan.zhihu.com/p/613665464



