
- 1嵌入式系统中串口通信粘包问题的解决方案(C语言)
- 2Android:禁用全局多点触控_android xml 多指点击禁用
- 3开源免费的物联网网关 IoT Gateway_iotgateway
- 4Flink系列六:Flink SQl 之常用的连接器(Connector)_flink connector
- 5Python 类内置函数__next__()用法记录_python df.next
- 6基于微信小程序的高校新生报道管理系统的设计与实现_基于微信小程序的新生报到管理系统的er图
- 7自然语言处理前馈网络(多层感知机与卷积神经网络)
- 8IntelliJ IDEA全局设置秘籍:JDK、Maven、编码格式全攻略_intellij idea 设置jdk版本
- 9Web实时通信的学习之旅:轮询、WebSocket、SSE的区别以及优缺点_sse 轮询 websocket
- 10Spark调试_spark 调试
大疆&腾讯 | CVPR 2023单目深度估计挑战赛冠军方案分享
赞
踩
作者 | 派星星 编辑 | CVHub
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【深度估计】技术交流群
本文只做学术分享,如有侵权,联系删文

Title: Metric3D: Towards Zero-shot Metric 3D Prediction from A Single Image
Paper: https://arxiv.org/pdf/2307.10984.pdf
导读
将图像精确地重建为3D场景是一个长期以来的视觉任务。由于单目图像重建问题的尺度不确定性,大多数成熟的方法都是基于多视图几何。目前最先进的单目深度估计方法只能处理单个相机模型,并且由于尺度模糊性无法执行混合数据训练。而经过大规模混合数据集训练的最先进的单目方法通过学习仿射不变的深度实现了零样本泛化,但不能恢复真实世界的尺度。在这项工作中,论文表明零样本单目度量深度估计的关键在于大规模数据训练以及解决来自各种相机模型的尺度模糊性。论文提出了一个规范相机空间(canonical camera space)变换模块,明确解决了尺度模糊性问题,并且可以轻松地嵌入到现有的单目模型中。配备了论文的模块,单目模型可以在800万张图像和数千个相机模型上稳定地训练,从而实现了对室外图像的零样本泛化,其中包含未见过的相机设置。
贡献
本文的主要贡献是:
提出了一种规范(canonical)和反规范(de-canonical)相机变换方法来解决来自不同相机设置的深度尺度模糊性问题。这使得论文方法可以从大规模数据集中学习强大的零样本(zero-shot)单目度量深度模型
论文提出了一种随机提议正则化损失函数,有效提高了深度准确性
论文方法在第二届单目深度估计挑战中获得了冠军,论文的模型在7个零样本基准测试上达到了最先进的性能。它能够在户外进行高质量的3D度量结构恢复,并且在几个下游任务中受益,如单目SLAM、3D场景重构和测量学。
方法
尺度模糊性

图3展示了由不同相机在不同距离下拍摄的照片示例。仅从图像外观来看,人们可能会认为最后两张照片是由同一个相机在相似的位置拍摄的。但实际上,由于不同的焦距,这些照片是在不同的位置拍摄的。因此,相机的内部参数对于从单张图像估计度量是至关重要的,否则问题就是不适定的。关于传感器尺寸、像素尺寸和焦距,论文有以下观察结果:
传感器尺寸和像素大小不会影响度量深度估计
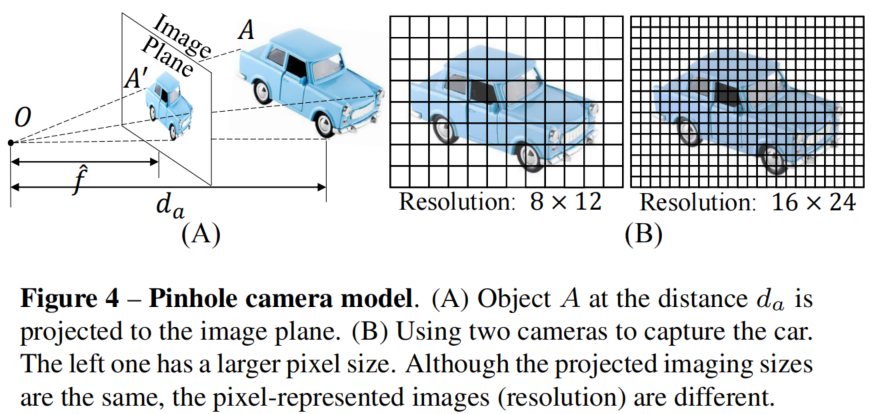
如图4所示,虽然由于像元大小不同,物体在图像的分辨率不同,但是距离是一致的。因此,不同的摄像机传感器不会影响度量深度的估计。
焦距对于度量深度的估计是至关重要的
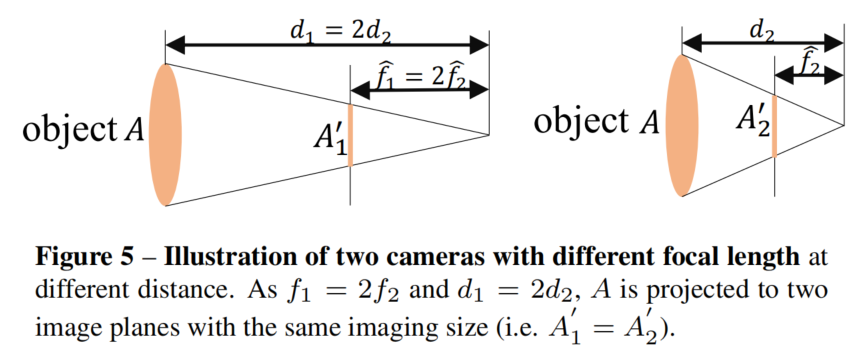
如图4所示,由于焦距不同,不同距离的物体在相机上的成像大小相同,在网络训练的时候,被当作不同的标签进行监督,网络才会被混淆,影响训练
规范相机(Canonical Camera)变换
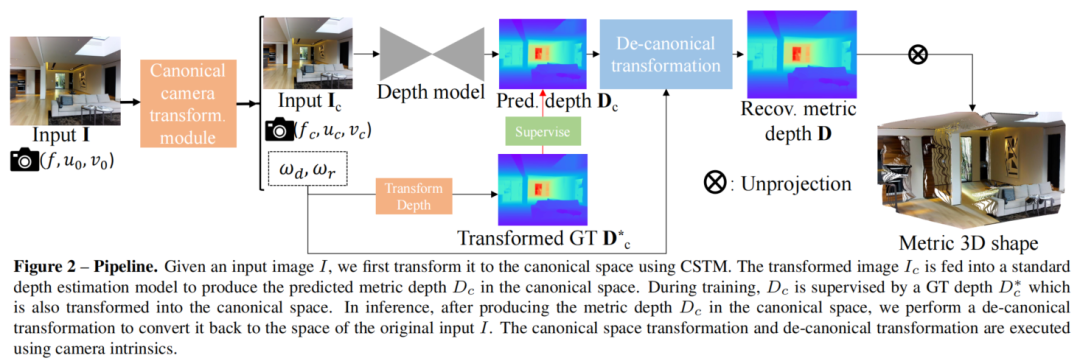
论文核心思想是建立一个规范相机空间,其中,并将所有训练数据转换到这个空间。因此,所有数据可以近似地看作是由规范相机拍摄的。论文提出了两种转换方法,即将输入图像或ground truth标签进行转换。流程如上图所示(本质上就是调整)
方法1:将标签进行转换
首先,图3中的模糊性是针对深度的。因此,第一种方法直接通过转换ground truth深度标签来解决这个问题。在训练阶段,通过乘以一个缩放因子来转换深度标签。在推理阶段,预测的深度处于规范化空间,需要进行反规范化转换以恢复度量信息。
方法2:将输入图像转换
第二种方法是将输入图像转换为模拟规范相机成像效果。具体来说,在训练阶段训练图像根据焦距按比例缩放resize,相机光心也进行了调整,然后进行随机裁剪图像用于训练。在推理阶段,反规范化转换将预测深度调整回原始大小而不进行缩放。
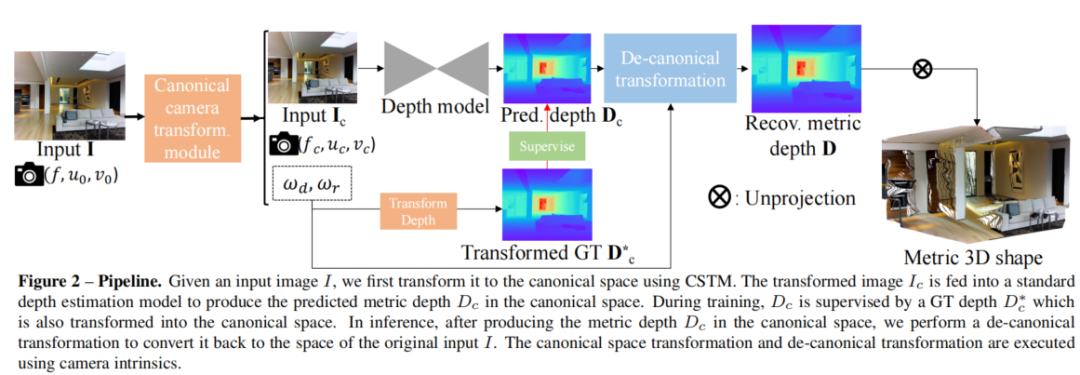
图2展示了论文的流程。在进行转换后,论文随机裁剪小块进行训练,裁剪只调整了视场和光心,不引起度量模糊问题。论文使用混合数据训练,收集了11个数据集,包含10,000多个不同相机的数据,所有训练数据都有配对的相机内参数,用于规范化转换模块。
监督
为了提高性能,论文提出了一种随机提议标准化损失(RPNL)。尺度平移不变损失被广泛应用于仿射不变深度估计,但它会压缩细粒度深度差异,特别是在近距离区域。因此,论文从真值深度和预测深度中随机裁剪若干小块,然后采用中位绝对偏差标准化对它们进行处理。这样,可以增强局部对比度。损失函数如下:
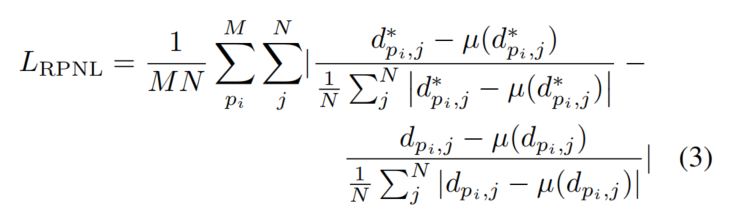
此外,还使用了其他几种损失,包括尺度不变对数损失(Scale-Invariant Logarithmic Loss)、成对标准化回归损失(Pair-wise Normal Regression Loss)和虚拟法线损失(Virtual Normal Loss)。总体损失如下所示:
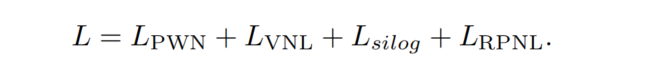
实验
零样本泛化测试
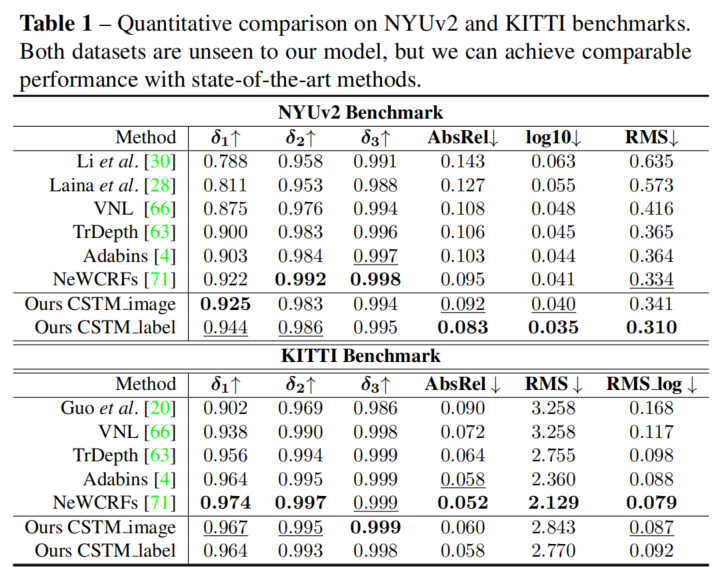
如表1所示,在没有任何微调或尺度调整的情况下,论文的方法能够达到与训练了数百个epochs的SOTA方法相媲美的性能。

论文还使用了6个未见过的数据集进行更多的度量准确性评估,这些数据集包含各种室内和室外场景,相机模型也各不相同。与最先进的方法相比,论文的模型表现更加稳健,而现有方法在类似的数据集上性能下降明显。
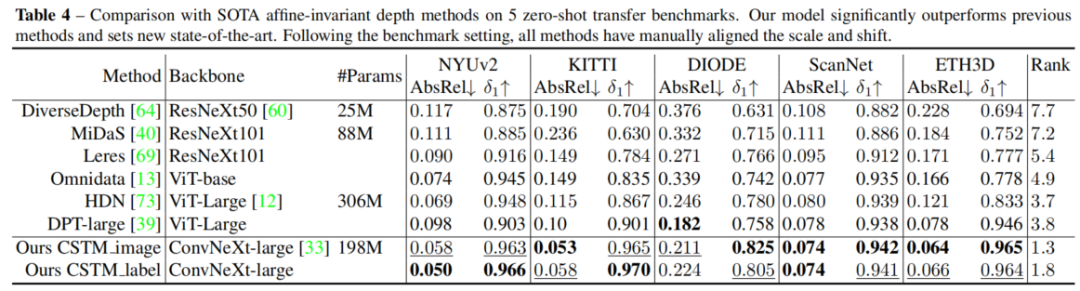
与SOTA仿射不变深度估计方法在5个zero-shot基准上的比较。论文的模型明显优于以前的方法
下游任务应用
三维场景重建

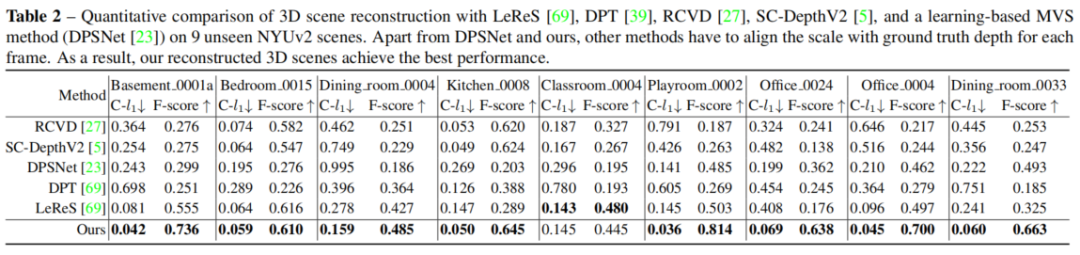
论文在9个未见过的NYUv2场景上进行了定量比较。论文的方法与其他先进方法相比,在这些场景上能够实现更好的三维度量形状恢复。图6的定性比较显示,论文的重建结果噪声和离群点较少。
稠密SLAM
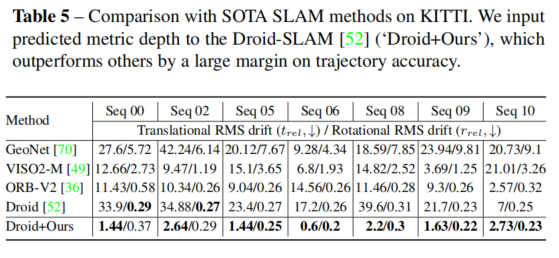
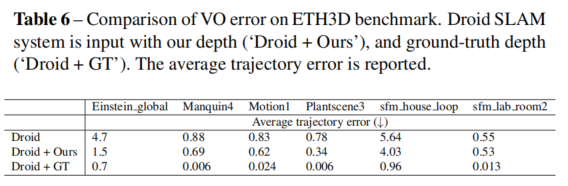
论文的度量深度估计方法可以作为单目SLAM系统的强大深度先验。在KITTI数据集上,将论文的度量深度直接输入到最先进的SLAM系统Droid-SLAM中,结果显示论文的深度使得SLAM系统的性能显著提升。在ETH3D SLAM基准数据集上,论文的深度同样带来了更好的SLAM性能,虽然改进效果相对较小。
户外测距

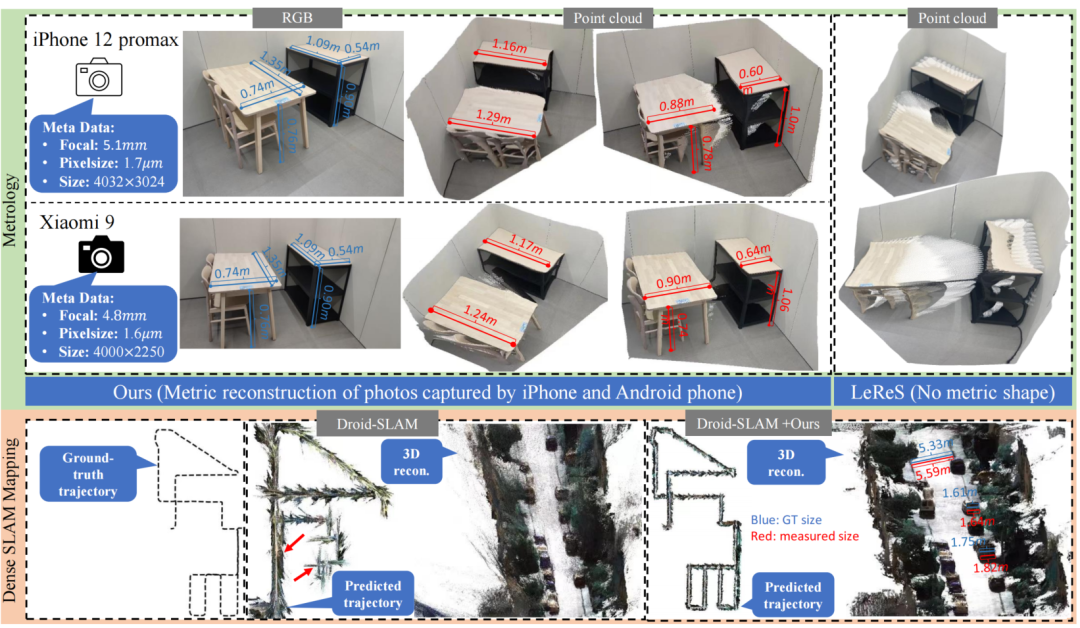
为了展示论文方法恢复的度量三维形状的鲁棒性和准确性,下载了由各种相机拍摄的Flickr照片,并从它们的元数据中收集了粗略的相机内参数。论文使用所提的CSTM图像模型重建它们的度量形状,并测量结构的尺寸(在图7中用红色标记),而真值尺寸用蓝色表示。结果显示,论文测量的尺寸非常接近真值尺寸。
总结
本文解决了从单目图像重构三维度量场景的问题。为了解决由不同焦距引起的图像外观深度不确定性,论文提出了一种规范化相机空间转换方法。使用论文的方法,可以轻松地合并由10,000个相机拍摄的数百万数据,以训练一个度量深度模型。为了提高鲁棒性,论文收集了超过800万数据进行训练。几个零样本评估展示了论文工作的有效性和鲁棒性。论文进一步展示了在随机收集的互联网图像上进行计量学测量以及在大规模场景上进行密集建图的能力。
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!


