
- 1SpringBoot 版本 与 jdk 版本兼容问题_springboot2.7.4对应jdk
- 2物联网毕设选题 机器视觉人脸识别系统 - 单片机 stm32 嵌入式_基于单片机的人脸识别
- 3RocketMQ实战笔记:应用实践_rocketmq设置queue数量
- 4阿里开源大模型 Qwen-72B 私有化部署
- 5智能合约开发中13种最常见的漏洞_智能合约的漏洞有哪些
- 6简师网:教师编制考上之后还需要统一分配吗?_北京教师考编后
- 7Qwen 开源标杆_qwen哪些开源了?
- 8OPENMV与STM32串口通信_uart.init(baudrate=115200, bits=8, parity=none, st
- 9MyBatis学习笔记(五):代码生成器_mybatis代码生成器 beginningdelimiter
- 10tensorflow框架精细讲解(一)_transflow教程
NLP 模型“解语如神”的诀窍:在文本分类模型中注入外部词典_channel concatenation
赞
踩
一. 引言
现实世界的文本表述如恒河沙数,以惊人的速度变换着,人工智能(AI)在快速识别形形色色的文本之前,必须经过充足的训练数据洗礼。然而,面对复杂多变的文本表述,NLP 模型往往无法从有限的训练数据中获得足够的支撑,寻求外部知识注入就成为了一条必经之路。
作为基底模型,ERNIE 等预训练语言模型普遍选择从知识图谱中获取结构化知识。构建完备的知识图谱,本身就是一项复杂课题,而融合训练更是高度的算力依赖。对于情感分析和攻击语言检测等文本分类场景,是否有更简洁的外部知识注入方式呢?
当然,在 NLP 技术还停留在特征工程时期,文本分类模型便搭建在大量的人工编辑或自动抽取的特征词典之上。进入深度学习时代,拥有卓越用户体验的商业落地系统仍然离不开用于干预黑盒模型的外部词典。尤其是对于大部分的应用场景,分类的判定本身就和关键词密不可分。比如,在情感分析中,情绪词“开心”“痛苦”等具有强烈的极性指向,副词“非常”“有一点”等也都是极其重要的程度线索。在攻击语言检测中,辱骂词“白痴”“傻瓜”就更直白了。
二. 词典表征
融入词典的第一步,是使用“向量”来表征词典命中的情况。如果共有 N 个特征词典,那么文本序列中的每个词,都有一个 N 维的特征向量,记为 feature-embedding。向量中的每个维度,代表当前词在对应词典中的权重得分。如果某一词典不包含权重得分,则命中记为 1.0,未命中记为 0.0。如果该词不在词典中,则记为 0.0。如果某一词典的分值超出区间 [-1,1],则应先进行归一化。
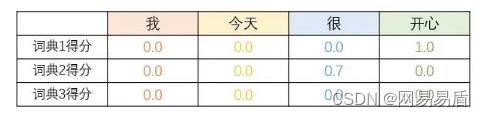
如上图所示,文本序列“我-今天-很-开心”共四个词,共三个特征词典。对应的特征向量分别为 [0.0, 0.0, 0.0],[0.0, 0.0, 0.0],[0.0, 0.7, 0.0],[1.0, 0.0, 0.0]。
三. 特征注入
在神经网络模型中注入额外特征的最直接方式,就是和 word-embedding 拼接在一起,这种朴素方式称为 native concatenation,如下图所示。

仅仅是简单拼接,在情感分类任务上也能获得一定的提升。在论文《Attention-based Conditioning Methods for External Knowledge Integration》中,作者比较了拼接方案在 LSTM 模型上对各个情感分类数据集的效果,如下图所示。

对于 CNN 类模型,还有一种拼接方案为 channel concatenation,即利用网络本身的多通道特定,使用二维卷积核进行编码。对于 feature-embedding比word-embedding 短的位置,用 0 补齐,如下图所示。

然而直接拼接并不是一个普适方案。对于 BERT 等已经完成了预训练的模型,已无法再在 word-embedding 层进行注入。即使是 LSTM 或 CNN 等简单网络,过早地进行融合也会干扰模型对文本本身语义的提取。因此,更加成熟的方案,BERT/LSTM/CNN 在完成了语义编码后,使用隐层向量代替 word-embedding 和 feature-embedding 进行拼接,再输入给 MLP 等单元进行融合,最终完成分类判定。
四. 拼接之后
当然,在完成了拼接注入之后,真正的融合方式不只有线性变换可以选择。从经验来说,效果更好的融合方案,都是“非对称结构”的。即 word 信息和 feature 信息不完全对等,在功能上彼此区别。模型仍然以文本信息作为主要判断依据,综合全局语义进行分类判定。词典信息作为引导,提醒模型关注被标记的关键词。这样的方式也符合人类在完成此类任务时的直观思维方式。
这不就是 attention 机制嘛?不过不是 Transformer 里的 self-attention,而是更古早的 vanilla 版本。该方案不进行任意两个位置之间的关联计算,每个词的权重只由自身决定。先来看看不进行融合时,是怎么对 word-embedding 进行 attention 的。对于一个完整的文本序列,将第 i 个词wi对应的语义向量记为hi,首先计算其 attention 得分:
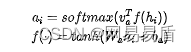
其中va、wa、ba 都是待学习的模型参数。然后,根据 attention 得分进行各个位置的语义向量的加权,获得最终用于分类判定的r:

将第 i 个词 wi对应的词典特征向量记为c(wi) ,在 feature-embedding 的引入过程中,只修改 attention 得分 ai,不影响加权对象hi ,以实现非对称结构。即修改 f()为:
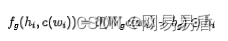
输出 [0~1] 之间的浮点数,再与hi进行点积,实现门控结构。以词典信息为门,对语义信息进行控制。具体的函数形式可以有多种变化,没有定式,应当在业务数据集上进行尝试,找出最佳的方案。
Attention 模型可以根据权重分数,直观地看到语义抽取的重点。以一个 PsychExp 情感分析数据集上的一个 case 为例,注入外部词典后,建模中心出现了变化,最终分类从 anger 变为了 guilt。如下图所示:

五. 总结
与知识图谱等结构化知识相比,外部词典不仅易于构建和维护,更适合文本分类的应用场景。进行知识引入后,一方面能显著提升模型的召回能力,减少业务漏判,另一方面,在中文互联网这个黑话频出的环境,可以在不更新模型的前提下让应用系统适应外部语言环境的变化发展。比起直接注入,与 attention 结合更符合人类的思考习惯,也更直观便于调试。在追求简洁优美的 end2end 模型时,也不应完全舍弃传统方案。各种结构化非结构化的经验知识,能够帮助我们打造用户体验一流的成熟商用 NLP 系统。

