
- 1初识人脸识别---人脸识别研究报告(概述篇)_机器视觉的人脸识别报告
- 2专科程序员VS本科程序员,如何摆脱学历「魔咒」?_大专选择程序员摆脱了蓝领
- 3基于Java的连连看游戏设计与实现_java数字连连看程序设计项目背景
- 4交换二叉树的左右子树——非递归方式_非递归实现二叉树左右子树交换
- 5Hbase伪分布式搭建时HQuorumeer启动不成功_hquorumpeer进程没起来是什么原因
- 6git命令删除缓存区(git add)的内容_git删除缓冲区文件
- 7使用MacOS M1(ARM)芯片系统搭建CentOS虚拟机,并基于kubeadm部署搭建k8s集群_m1 vmware centos
- 8[python] 使用scikit-learn工具计算文本TF-IDF值(转载学习)_tf-idf算法调用
- 9android radiobutton 设置选中问题_android recyclerview把第一个item的radiobutton设置成选中状态
- 10Java技能点--switch支持的数据类型解释_java 类常量和接口常量 switch
SeetaFace6人脸检测C++代码实现Demo_seetaface6 demo
赞
踩
SeetaFace6包含人脸识别的基本能力:人脸检测、关键点定位、人脸识别,同时增加了活体检测、质量评估、年龄性别估计,并且顺应实际应用需求,开放口罩检测以及口罩佩戴场景下的人脸识别模型。
1. 人脸检测
人脸检测,就是输入待检测的图片,输出检测到的每个人脸位置,用矩形表示。

人脸检测器seeta::FaceDetector 的主要接口
- namespace seeta {
- class FaceDetector {
- FaceDetector(const SeetaModelSetting &setting);
- SeetaFaceInfoArray detect(const SeetaImageData &image) const;
- void set(Property property, double value);
- double get(Property property) const;
- }
- }
构造一个检测器的函数参考如下:
- #include <seeta/FaceDetector.h>
- seeta::FaceDetector *new_fd() {
- seeta::ModelSetting setting;
- setting.append("face_detector.csta");
- return new seeta::FaceDetector(setting);
- }
有了检测器,我们就可以对图片检测人脸,检测图片中所有人脸并打印坐标的函数参考如下:
- #include <seeta/FaceDetector.h>
- void detect(seeta::FaceDetector *fd, const SeetaImageData &image) {
- SeetaFaceInfoArray infos = fd->detect(image);
- for (int i = 0; i<infos.size; i++)
- {
- SeetaRect& face = infos.data[i].pos;
- std::cout << "[" << face.x << ", " << face.y << ", "
- << face.width << ", " << face.height << "]: "
- << infos.data[i].score << std::endl;
- }
- }
人脸检测器可以设置一些参数,通过set方法(set方法只对当次人脸检测器有效)。可以设置的属性有:
- seeta::FaceDetector::PROPERTY_MIN_FACE_SIZE 最小人脸,默认值为20
- seeta::FaceDetector::PROPERTY_THRESHOLD 检测器阈值,默认值为0.90
- seeta::FaceDetector::PROPERTY_MAX_IMAGE_WIDTH 可检测的图像最大宽度,默认值为2000
- seeta::FaceDetector::PROPERTY_MAX_IMAGE_HEIGHT 可检测的图像最大高度,默认值为2000
- seeta::FaceDetector::PROPERTY_NUMBER_THREADS 人脸检测器计算线程数,默认为4
最小人脸是人脸检测器常用的一个概念,默认值为20,单位像素。它表示了在一个输入图片上可以检测到的最小人脸尺度,注意这个尺度并非严格的像素值,例如设置最小人脸80,检测到了宽度为75的人脸是正常的,这个值是给出检测能力的下限。
最小人脸和检测器性能息息相关。主要方面是速度,使用建议上,我们建议在应用范围内,这个值设定的越大越好。SeetaFace采用的是BindingBox Regresion的方式训练的检测器。如果最小人脸参数设置为80的话,从检测能力上,可以将原图缩小的原来的1/4,这样从计算复杂度上,能够比最小人脸设置为20时,提速到16倍。
检测器阈值默认值是0.9,合理范围为[0, 1]。这个值一般不进行调整,除了用来处理一些极端情况。这个值设置的越小,漏检的概率越小,同时误检的概率会提高;
可检测的图像最大宽度和可检测的图像最大高度是相关的设置,默认值都是2000。最大高度和宽度,是算法实际检测的高度。检测器是支持动态输入的,但是输入图像越大,计算所使用的内存越大、计算时间越长。如果不加以限制,一个超高分辨率的图片会轻易的把内存撑爆。这里的限制就是,当输入图片的宽或者高超过限度之后,会自动将图片缩小到限制的分辨率之内。
2. 关键点定位
关键点定位,就是输入待检测的图片,和待检测的人脸位置,输出N个关键点的坐标(图片内)。

这里需要强调说明一下,这里的关键点是指人脸上的关键位置的坐标,在一些表述中也将关键点称之为特征点,但是这个和人脸识别中提取的特征概念没有任何相关性。并不存在结论,关键点定位越多,人脸识别精度越高。
一般的关键点定位和其他的基于人脸的分析是基于5点定位的。而且算法流程确定下来之后,只能使用5点定位。5点定位是后续算法的先验,并不能直接替换。从经验上来说,5点定位已经足够处理人脸识别或其他相关分析的精度需求,单纯增加关键点个数,只是增加方法的复杂度,并不对最终结果产生直接影响。
SeetaFace6提供了2个关键点检测模型:
face_landmarker_pts5.csta:5个关键点检测模型,这里检测到的5点坐标循序依次为,左眼中心、右眼中心、鼻尖、左嘴角和右嘴角。 注意这里的左右是基于图片内容的左右,并不是图片中人的左右,即左眼中心就是图片中左边的眼睛的中心。
face_landmarker_pts68.csta:68个关键点检测模型,其坐标位置可以通过逐个打印出来进行区分。
构造关键点定位器:
- #include <seeta/FaceLandmarker.h>
- seeta::FaceLandmarker *new_fl() {
- seeta::ModelSetting setting;
- setting.append("face_landmarker_pts5.csta");
- return new seeta::FaceLandmarker(setting);
- }
根据人脸检测关键点,并将坐标打印出来的代码如下:
- #include <seeta/FaceLandmarker.h>
- void mark(seeta::FaceLandmarker *fl, const SeetaImageData &image, const SeetaRect &face) {
- std::vector<SeetaPointF> points = fl->mark(image, face);
- for (auto &point : points) {
- std::cout << "[" << point.x << ", " << point.y << "]" << std::endl;
- }
- }
3. 演示Demo
3.1 开发环境
- Seetaface6
- Visual Studio 2015
- Windows 10 Pro x64
3.2 功能介绍
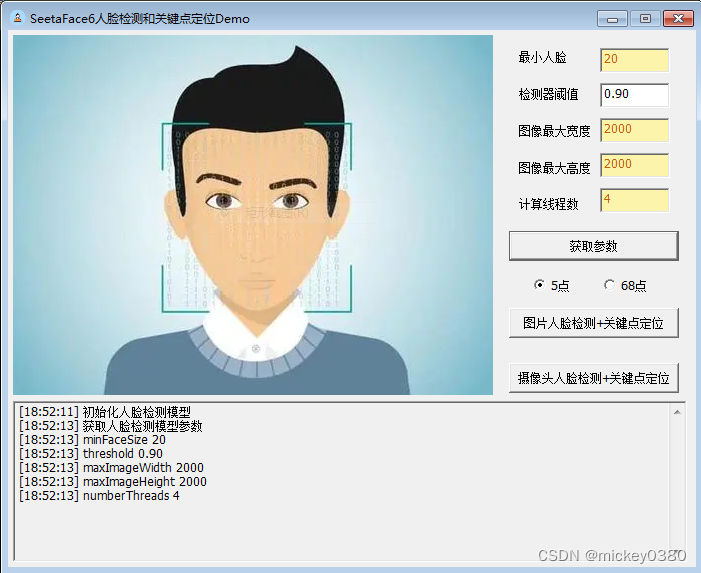
演示程序主界面如下图所示,包括获取参数、图片人脸检测+关键点定位、摄像头人脸检测+关键点定位等功能,其中关键点定位支持5点和68点两种模型。

获取参数:初始化人脸检测模型,获取人脸模型的最小人脸、检测器阈值、可检测的图像最大宽度、最大高度、人脸检测器计算线程数等参数。
图片人脸检测+关键点定位:读取一张人脸图片,进行人脸检测和关键点定位;结果显示在左侧(包括人脸框、关键点坐标)。

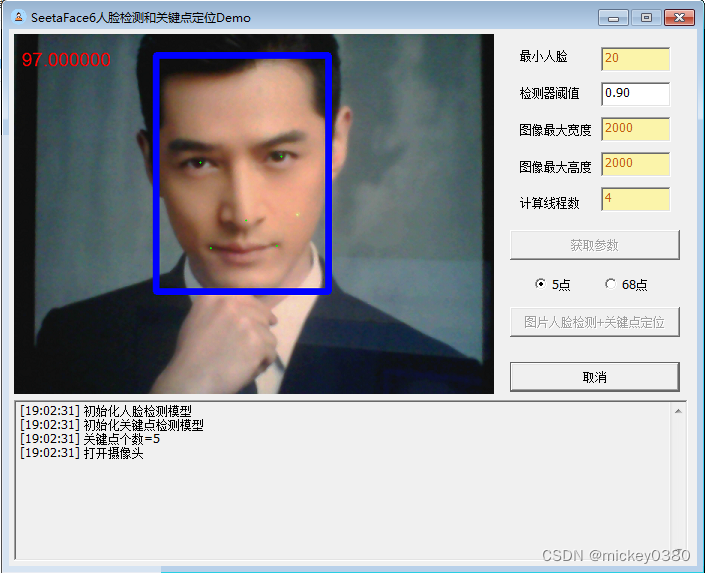
摄像头人脸检测+关键点定位:启动摄像头,进行实时人脸检测和关键点定位演示,结果显示在左侧(包括人脸框、关键点坐标)。
3.3 下载地址
开发环境:
- Windows 10 pro x64
- Visual Studio 2015
- Seetaface6

