
- 1uniapp(vue3) H5页面连接打印机并打印_在uni-app(vue2)中h5调起浏览器自动打印
- 23.neo4j源码解读-neo4j配置apoc插件详细全流程(desktop 和社区版本)_neo4j源码解析
- 3Mysql高级语句(进阶查询语句、数据库函数、连接查询)_mysql数据库连接查询
- 4java第十版第九章答案_Java语言程序设计(基础篇)原书第十一版 梁勇 第9章 课后题答案...
- 5基础15·OS库下的python第三方库安装(OS库(操作系统交互),异常处理)_cmd安装os库
- 6Android 之Activity_获得用户焦点 是啥意思
- 7MySQL 用户管理操作_通过mysql实现用户管理
- 8MySQL表的增删改查(基础)_增啥改查四个英文
- 9怎样实现两台redis服务器的数据迁移_低版本redis 怎么保留数据迁移到高版本
- 10Qt+OpenCV识别物体的形状_qt opencv识别图像
DPU智能网卡OVS全卸载方案_dpu怎么卸载ovs
赞
踩
私有云和通信服务提供商正在改造其基础设施,以实现超规模公共云提供商的灵活性和效率。这种转变基于两个基本原则:分解和虚拟化。
分解将网络软件与底层硬件分离。服务器和网络虚拟化通过使用 hypervisor 和 overlay 网络共享行业标准服务器和网络设备来提高效率。这些颠覆性功能提供了灵活性、灵活性和软件可编程性等好处。然而,由于基于内核的 hypervisor 和虚拟交换,它们也会对网络性能造成严重的影响,这两种方法都无法有效地消耗主机 CPU 周期进行网络数据包处理。为解决网络性能下降而过度配置 CPU 核心会导致较高的资本支出,从而使通过服务器虚拟化获得硬件效率的目标落空。
为了应对这些挑战, Red Hat 和 NVIDIA Mellanox 向市场推出了一款高效、硬件加速、紧密集成的 NFVI 和云数据中心解决方案,该解决方案将 Red Hat Enterprise Linux 操作系统与运行 DPDK 的 NVIDIA Mellanox ConnectX-5 网络适配器以及加速交换和数据包处理( ASAP )相结合2) OvS 卸载技术。
Mellanox OFED栈的架构
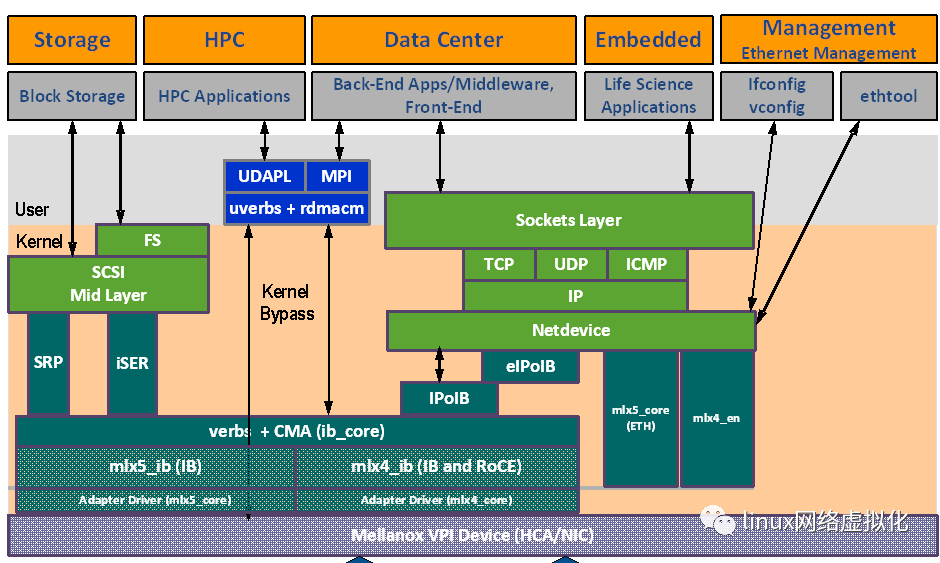
mlx4 VPI Driver
ConnectX®-3可以作为一个IB(InfiniBand)适配器,或者一个以太网卡。mlx4是ConnectX® 家族适配器的低层驱动实现。OFED驱动支持IB和以太网配置,为了适应这些配置,这个驱动被分为下面模块:
mlx4_core:处理底层功能如设备初始化和固件。同时控制资源分配从而让IB和以太网功能可以互不干扰地共享设备
mlx4_ib:处理IB功能并且插入到IB中间层
mlx4_en:drivers/net/ethernet/mellanox/mlx4下一个10/24GigE的驱 动,处理以太网功能
libmlx4 is a userspace driver for Mellanox ConnectX InfiniBand HCAs.It is a plug-in module for libibverbs that allows programs to useMellanox hardware directly from userspace.
mlx5 Driver
mlx5是the Connect-IB® and ConnectX®-4适配器的底层驱动实现。Connect-IB作为IB适配器而ConnectX-4作为一个VPI适配器(IB和以太网)。mlx5包括了以下内核模块:
mlx5_core:作为一个通用功能库(比如重置后初始化设备),Connect-IB® and ConnectX®-4适配卡需要这些功能。mlx5_core也为ConnectX®-4实现了以太网接口。和mlx4_en/core不同的是,mlx5驱动不需要mlx5_en模块因为以太网功能已经内置在mlx_core模块中了。
mlx5_ib:处理IB功能
libmlx5:实现指定硬件的用户空间功能。如果固件和驱动不兼容,这个驱动不会加载并且会打印一条信息在dmesg中。下面是libmlx5的环境变量:
MLX5_FREEZE_ON_ERROR_CQE
MLX5_POST_SEND_PREFER_BF
MLX5_SHUT_UP_BF
MLX5_SINGLE_THREADED
ASAP2OvS 卸载加速
OvS 硬件卸载解决方案将基于软件的缓慢虚拟交换机数据包性能提高一个数量级。从本质上讲, OvS 硬件卸载提供了两个方面的最佳选择:数据路径的硬件加速以及未经修改的 OvS 控制路径,以实现匹配操作规则的灵活性和编程。NVIDIA Mellanox 是这一突破性技术的先驱,在 OvS 、 Linux 内核、 DPDK 和 OpenStack 开源社区中引领了支持这一创新所需的开放架构。
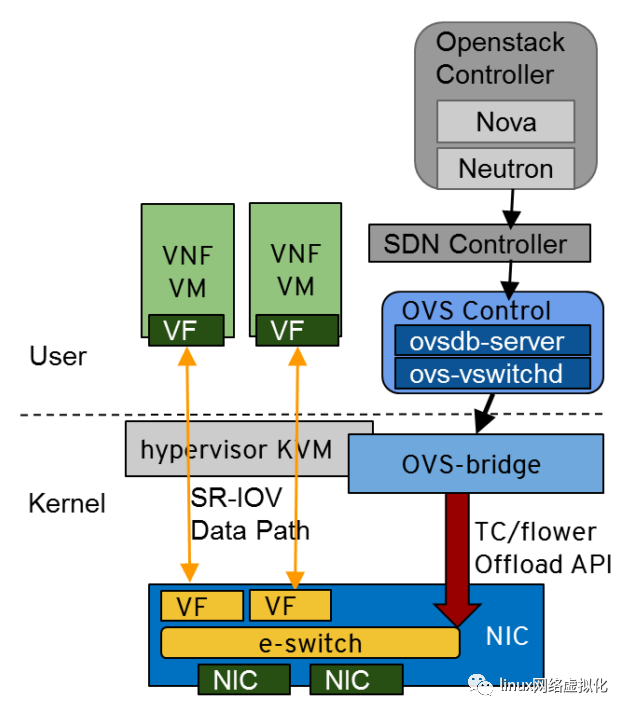
图 1 。ASAP2OvS 卸载解决方案。
图 1 显示了 NVIDIA Mellanox open ASAP 2 OvS 卸载技术。它完全透明地将虚拟交换机和路由器数据路径处理卸载到 NIC 嵌入式交换机( e-switch )。 NVIDIA Mellanox 为核心框架和 API (如 tcflower )的上游开发做出了贡献,使它们可以在 Linux 内核和 OvS 版本中使用。这些 api 极大地加速了网络功能,如覆盖、交换、路由、安全和负载平衡。
正如在 Red Hat 实验室进行的性能测试所证实的, NVIDIA Mellanox ASAP2该技术为大型虚拟可扩展局域网( VXLAN )数据包提供了接近 100g 的线速率吞吐量,而不消耗任何 CPU 周期。对于小包裹,ASAP2将 OvS VXLAN 数据包速率提高了 10 倍,从使用 12 个 CPU 内核的每秒 500 万个数据包提高到每秒消耗 0 个 CPU 核的 5500 万个数据包。
云通信服务提供商和企业可以尽快实现基础设施的总体效率2– 基于的高性能解决方案,同时释放 CPU 内核,以便在同一服务器上打包更多虚拟网络功能( vnf )和云本地应用程序。这有助于减少服务器占用空间并节省大量的资本支出。ASAP2已从 OSP13 和 RHEL7 . 5 作为技术预览版提供,从 OSP16 . 1 和 RHEL8 . 2 开始正式提供。
OVS-DPDK 加速
如果您想保持现有较慢的 OvS virtio 数据路径,但仍然需要一些加速,可以使用 NVIDIA Mellanox DPDK 解决方案来提高 OvS 性能。图 2 显示了 OvS over DPDK 解决方案使用 DPDK 软件库和轮询模式驱动程序( PMD ),以消耗 CPU 核心为代价,显著提高了数据包速率。
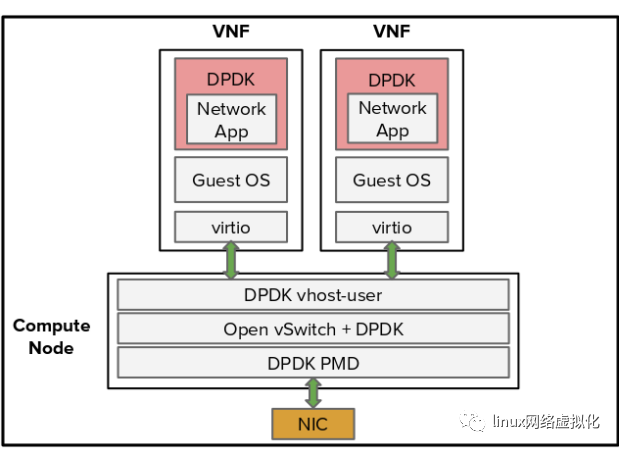
图 2 。OVS-DPDK 解决方案图。
使用开源 DPDK 技术, NVIDIA Mellanox ConnectX-5 NIC 提供业界最佳的裸机数据包速率,即每秒 1 . 39 亿个数据包,用于在 DPDK 上运行 OvS 、 VNF 或云应用程序。RHEL7 . 5 完全支持 Red Hat –
网络架构师在选择适合其 IT 基础设施需求的最佳技术时经常面临许多选择。在决定是否 ASAP2 而 DPDK ,由于 ASAP 的巨大优势,决策变得更加容易2技术超过 DPDK 。
由于 SR-IOV 数据路径,与ASAP2和使用传统的较慢 virtio 数据路径的 DPDK 相比, OvS 卸载实现了显著更高的性能。进一步,ASAP2通过将流卸载到 NIC 来节省 CPU 核心,在 NIC 中 DPDK 消耗 CPU 核心以次优方式处理数据包。像 DPDK 一样,ASAP2OvS offload 是一种开源技术,在开源社区中得到了充分的支持,并在业界得到了广泛的采用。

