
- 1视频业务像素、带宽、存储空间计算_摄像头带宽怎么计算
- 2iceoryx(冰羚)-IPC中间件交叉编译_iceoryx github
- 3《自然语言处理实战 01》商品信息与文本数据的挖掘分析_自然语言处理商品匹配
- 4python UI自动化之下拉选择框、弹出框、滚动条操作_python下拉菜单中的选项,在界面弹出
- 5【Git】Failed to connect to github.com port 443问题
- 6国内大语言模型对比评测(三)_智谱清言,通义千问,文心一言哪个好
- 7【深度学习计算机视觉实战】给深度学习计算机视觉初学者的学习和求职建议,这个行业还缺人_深度学习与计算机视觉实战肖玲
- 8【NLP】词嵌入及为什么要这么做_词嵌入基数
- 9实模式和保护模式区别及寻址方式_阐述实模式逻辑地址与保护模式逻辑地址的异同。
- 10大数据的学习路线_大数据专硕学习路线
保证分布式缓存Redis与DB之间的数据一致性,4套方案+1套兜底,是真的稳!_redis 同步 到db
赞
踩
原创 不码不疯魔 不码不疯魔 2023-08-05 07:44 发表于四川
收录于合集
#redis2个
#数据一致性4个
#分布式缓存1个
#分布式缓存与DB数据一致性1个
20
23
不疯魔不成活,大家好呀,我是科哥,江湖ID 不码不疯魔
真实场景:
面试官:你好,请问你做过的项目中,服务的最高QPS是多少?
候选人:我们的服务高峰访问量非常大,在双十一活动的时候 QPS大概10w左右
面试官:这么大的访问量,服务面临的压力应该非常高,你们是怎么设计的呢?
候选人:我们的服务设计是采用了二级缓存,把一些热点的数据放到本地缓存,比如活动的数据,把一些非热点的数据放到 Redis 缓存,比如活动-礼品数据,接口优先查询一级缓存,如果一级缓存没数据,接着会查询二级缓存,二级缓存不存在,才访问数据库。这样设计可以减少数据库的访问压力,加快查询效率。
面试官:从你的设计看,你的数据存储到三个地方,如果涉及数据更新,你是怎么保证他们三者中间的一致性的呢?
面试官:这样,说说分布式缓存与DB的一致性问题是如何解决的?
看
重
点
重点掌握:4套方案+1套兜底的实现步骤、优点、缺点?
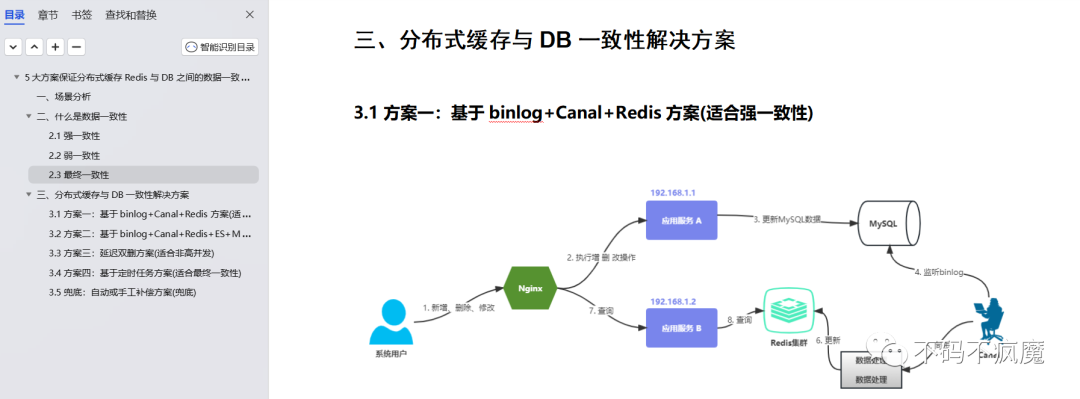
1. 方案一:基于binlog+Canal+Redis方案(适合强一致性)
2. 方案二:基于binlog+Canal+Redis+ES+MQ方案(比较解耦,复杂)
3. 方案三:延迟双删方案(适合非高并发)
4. 方案四:基于定时任务方案(适合最终一致性)
5. 兜底方案:自动或手工补偿方案(兜底)
注意:此篇文章,只讲实现步骤+优缺点,具体的商用级代码很快更新,记得关注,标记星号哟!!!
01
方案一:基于binlog+Canal+Redis方案(适合强一致性)
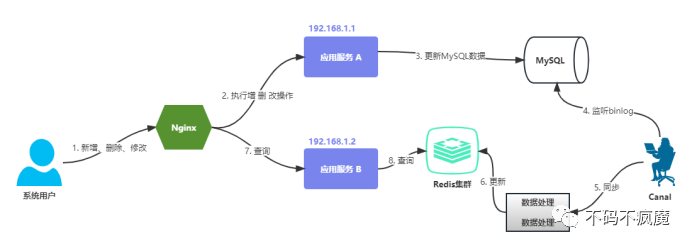
步骤:
1.更新 MySQL 数据;
2.通过canal中间件监听MySQL中的binlog;
3.启动一个数据处理应用,消费同步canal监听的数据并进行数据加工;
4.将加工后的数据更新至Redis;
5.应用查询Redis数据返回;
优点:
1.实现简单:该方案所需的组件较少,实现较为简单。
2.高效同步:通过Canal机制,可以实现数据库与缓存之间的实时同步,保证了数据的一致性。
3.主从复制:使用MySQL的主从复制机制,可以保证从服务器MySQL上的数据与主服务器保持同步,进一步保证了数据的一致性。
缺点:
1.依赖MySQL:该方案依赖于MySQL数据库,对于非MySQL数据库的环境可能不适用。
2.技术限制:该方案需要配置主从复制和Canal机制,对于一些特殊的环境或者限制可能不适用。
3.数据丢失:如果在数据写入Redis缓存之前发生系统故障或宕机,可能会造成数据丢失。
4.维护难度:需要维护Redis缓存和MySQL数据库的主从复制关系,如果系统规模较大或数据量较大,可能需要更多的维护和管理成本。
02
改方案二:基于binlog+Canal+Redis+ES+MQ方案(比较解耦,复杂)
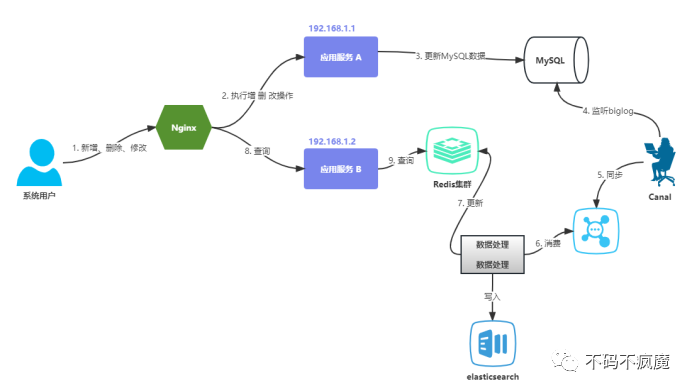
步骤:
1.更新MySQL数据;
2.通过canal中间件监听MySQL中的binlog,同时将数据同步到MQ;3.启动一个数据处理应用,消费MQ数据并进行加工;
4.将加工后的数据更新至Redis,加入ES;
5.应用查询Redis数据返回;
优点:
1.实现高效同步、主从复制、支持全文搜索和数据分析等
2.消息队列实现异步处理和事件通知,可以进一步提高系统的可靠性和性能。
缺点:
1. 维护Redis、ES和消息队列等组件,技术限制较大,可能需要在一些特殊环境下 进行额外的配置和优化等。
03
方案三:延迟双删方案(适合非高并发)
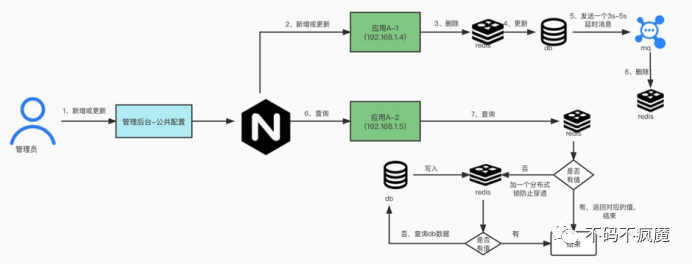
步骤:
1. 先进行缓存清除;
2. 再执行update sql;
3. 最后(延迟 N 秒)再执行缓存清除;
上述中(延迟 N 秒)的时间要大于一次写操作的时间,一般为 3-5 秒。
原因:如果延迟时间小于写入 Redis 的时间,会导致请求 1 清除了缓存,但是请求 2 缓存还未写入的尴尬。
注意:一般写入的时间会远小于 5 秒
优点:
1.方案相对比较简单,对于非高并发业务比较适合。
缺点:
1.有等待环节,如果系统要求低延时,这种场景就不合适
2.不适合秒杀这种频繁修改数据和要求数据强一致的场景
3.延时时间是一个预估值,不能确保 MySQL 和 Redis 数据在这个时间段内都实时同步或持久化成功了
04
方案四:基于定时任务方案(适合最终一致性)
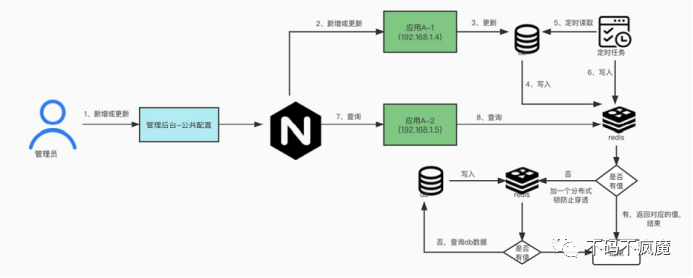
步骤:
1. 更新 db 数据,同时写入数据到 redis
2. 启动一个定时任务定时将 db 数据同步到 redis
3. 前端发起接口查询请求,先从 redis 查询数据
4. 没有数据redis,加一个分布式锁,再从 redis 数据查询
5. 查询 redis 数据返回
优点:
1.方案相对比较简单,对于高并发业务比较适合。相对是一个比较高可用的方案, 通过定时任务定时更新db数据到 redis,保持数据的一致性。
缺点:
1.并不能保证数据的实时性,如果对数据的实时性要求比较高,则需要考虑其他解决方案。
05
兜底:自动或手工补偿方案(兜底)
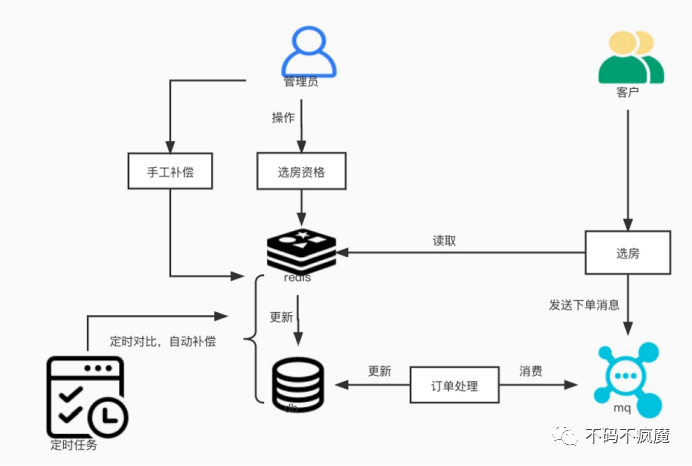
自动补偿方案:
1.数据写入数据库:当数据发生更新或删除时,首先将数据写入数据库,以保证数据的一致性。
2.数据写入缓存:在数据写入数据库后,立即将数据写入缓存,以保证数据的一致性。
3.数据同步:使用定时任务或消息队列等机制,定时将数据库中的数据同步到缓存中,以避免数据不一致的情况。
4.数据更新:当数据库中的数据发生更新或删除时,通过触发事件或定时任务来更新缓存中的数据,以保证数据的一致性。
手工补偿方案:
1.数据写入数据库:当数据发生更新或删除时,首先将数据写入数据库,以保证数据的一致性。
2.数据写入缓存:在数据写入数据库后,立即将数据写入缓存,以保证数据的一致性。
3.数据同步:开发人员手动编写代码,定时将数据库中的数据同步到缓存中,以避免数据不一致的情况。
4.数据更新:当数据库中的数据发生更新或删除时,开发人员手动编写代码来更新缓存中的数据,以保证数据的一致性。
优点:
1.对于适合秒杀类业务,另外通过定时任务自动补偿和手工补偿,这种方案高可用方面做的比较好。甚至能做到自动修复不一致性的场景。
缺点:
1. 需要开发额外的定时任务
收获
文档资料
笔记文档,怎么获取?
点击下方公众号进入关注,后台回复【4+1】即可获取所有资料,具体的商用级代码很快更新,记得关注,标记星号哟!!!

