
热门标签
热门文章
- 1爬虫练习——爬取纵横小说网_纵横中文网 爬虫
- 2Sublime Text 4 (Build 4143)激活与汉化_sublime激活
- 32024年鸿蒙最新HarmonyOS NEXT应用开发—视频全屏切换案例,春招面试问题大全及答案大全_ets 全屏
- 4消息中间件---kafka---深入理解kafka_卡夫卡中间键
- 5重磅!OpenAI与苹果合作,将ChatGPT集成在iOS 18中
- 6基于Unity引擎利用OpenCV和MediaPipe的面部表情和人体运动捕捉系统_unity解析python面部动作
- 721、基于51单片机智能电饭堡系统设计(程序+原理图+PCB图+Proteus仿真+答辩技巧+开题报告+参考论文+元器件清单等)_智能电饭煲控制系统 proteus
- 8哈啰集团全面接入通义灵码,AI 生成代码占比 20%,研发提效 12%
- 9基于Python爬虫江苏南京景点数据可视化系统设计与实现(Django框架) 研究背景与意义、国内外研究现状(1)_以南京为主题的django项目后端项目代码
- 109个优秀的Text2Sql(Chat2Sql)开源项目、资源
当前位置: article > 正文
【Kaggle】Telco Customer Churn 电信用户流失预测案例_kaggle用户流失预测
作者:从前慢现在也慢 | 2024-07-07 02:14:36
赞
踩
kaggle用户流失预测

⭐️前言:案例学习说明与案例建模流程
我们将围绕Kaggle中的电信用户流失数据集(Telco Customer Churn)进行用户流失预测。在此过程中,将综合应用此前所介绍的各种方法与技巧,并在实践中提炼总结更多实用技巧。

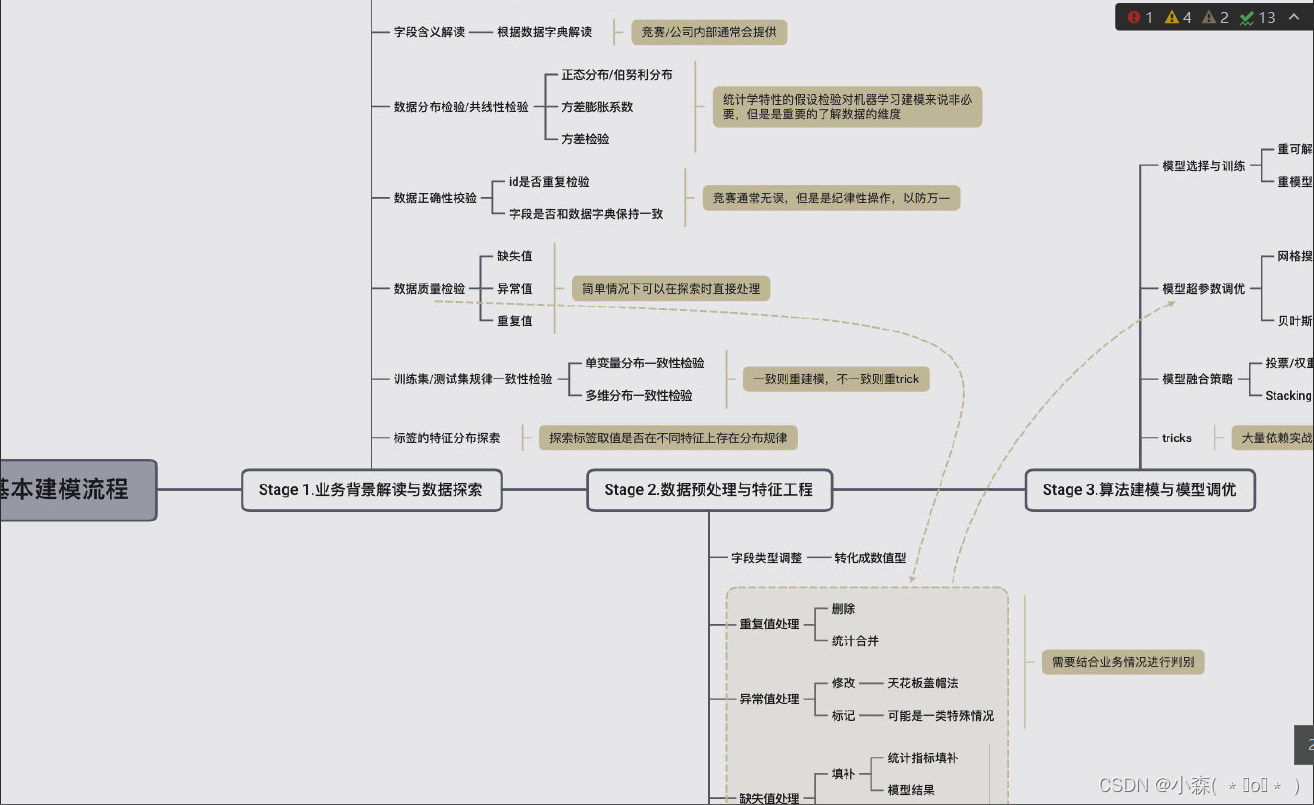
⭐️对于实战案例的讲解,我们将分为三个阶段进行,当然这也是我们在参与算法竞赛、或者在实际算法建模时的一般流程:
- Stage 1.业务背景解读与数据探索
在拿到数据(接受任务)的第一时间,需要对数据(也就是对应业务)的基本背景进行解读。由于任何数据都诞生于某业务场景下,同时也是根据某些规则来进行的采集或者计算得出,因此如果可以,我们应当尽量去了解数据诞生的基本环境和对应的业务逻辑,尽可能准确的解读每个字段的含义,而只有在无法获取真实业务背景时,才会考虑退而求其次通过数据情况去倒推业务情况。
当然,在进行了数据业务背景解读后,接下来就需要对拿到的数据进行基本的数据探索。一般来说,数据探索包括数据分布检验、数据正确性校验、数据质量检验、训练集/测试集规律一致性检验等。当然,这里可能涉及到的操作较多,也并非所有的操作都必须在一次建模过程中全部完成。但作为教学案例,我们将在后续的内容中详细介绍每个环节的相关操作及目的。 - Stage 2.数据预处理与特征工程
在了解了建模业务背景和基本数据情况后,接下来我们就需要进行实际建模前的“数据准备”工作了,也就是数据预处理(数据清洗)与特征工程。其中,数据清洗主要聚焦于数据集数据质量提升,包括缺失值、异常值、重复值处理,以及数据字段类型调整等;而特征工程部分则更倾向于调整特征基本结构,来使数据集本身规律更容易被模型识别,如特征衍生、特殊类型字段处理(包括时序字段、文本字段等)等。
当然,很多时候我们并不刻意区分数据清洗与特征工程之间的区别,很多时候数据清洗的工作也可以看成是特征工程的一部分。同时,也有很多时候我们也不会一定要求在不同阶段执行不同操作,例如如果在数据探索时发现缺失值比例较小,则可以直接对其进行均值/众数填补,而不用等到特征工程阶段统一处理,再例如很多特征工程的方法需要结合实际建模效果来判别,所以有的时候特征衍生也会和建模过程交替进行。 - Stage 3.算法建模与模型调优
在经过一系列准备工作后,就将进入到最终建模环节了,建模过程既包括算法训练也包括参数调优。当然,很多时候建模工作不会一蹴而就,需要反复尝试各种模型、各种调参方法、以及模型融合方法。此外,很多时候我们也需要根据最终模型输出结果来进行数据预处理和特征工程相关方法调整。
上述流程可以用如下流程图进行表示:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/794591
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

