
- 1【数据结构】——八大排序(详解+图+代码详解)看完你会有一个全新认识_数据结构排序算法代码
- 2AI智能行为分析预警系统技术方案
- 3【Golang】slice切片
- 4PyTorch碎片:PyToch和Torchvision对应版本_pytorch与torchvision版本对应
- 5Quartus Prime 19.1 下载教程_quartus ii 19.1
- 6【雕爷学编程】Arduino智能家居之基于Bluetooth的智能控制_arduino blue tooth
- 7asp.net 微信小程序源码 微信分销源码 源文件完全开源 源码_net 微信 商城
- 8想远程控制手机,用哪个软件好?
- 9使用XPath来解析网页数据_xpath 网页
- 10用python写一个完整的图书管理系统
AI多模态教程:Mini-InternVL1.5多模态大模型实践指南_internvl2模型
赞
踩
2B参数的多模态大模型!8%的参数,80%的性能;16%的参数,90%的性能!

一、模型介绍:InternVL1.5
上海AI Lab 推出的 InternVL 1.5 是一款开源的多模态大语言模型 (MLLM),旨在弥合开源模型和专有商业模型在多模态理解方面的能力差距。
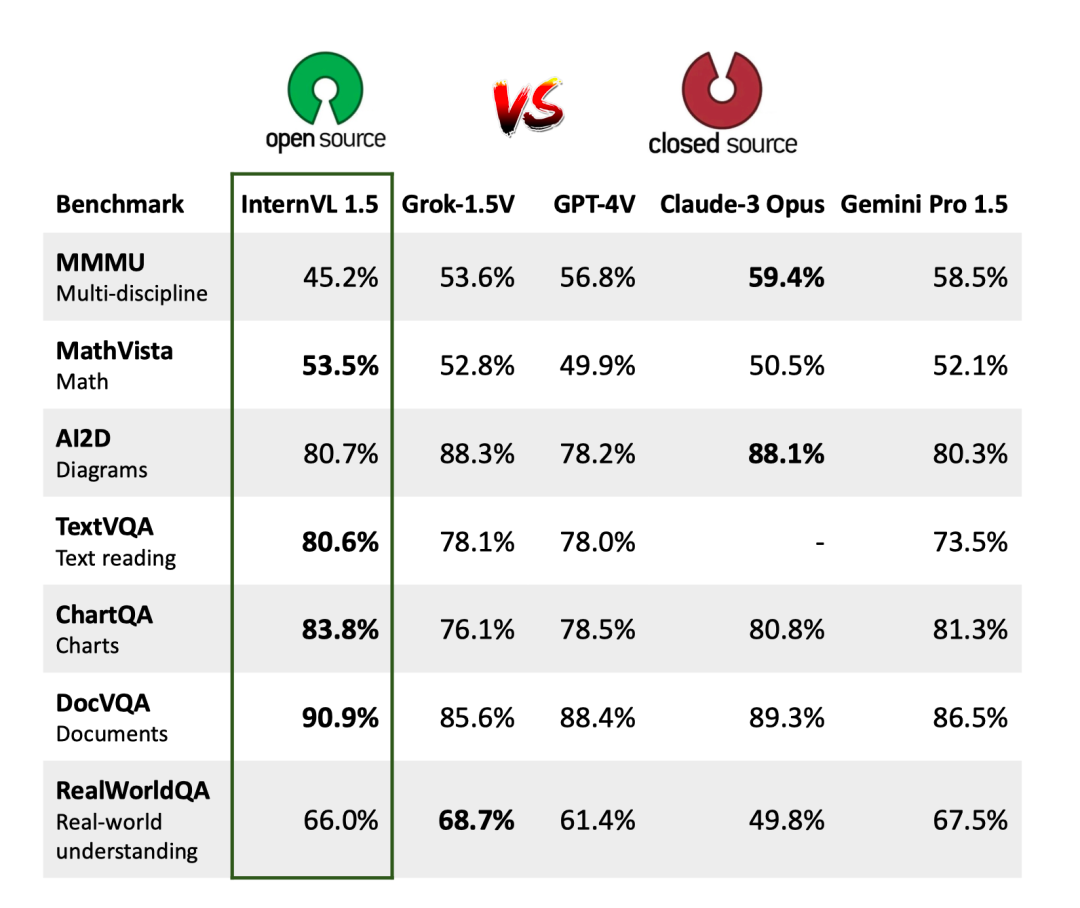
论文称,InternVL 1.5 在四个特定基准测试中超越了 Grok-1.5V、GPT-4V、Claude-3 Opus 和 Gemini Pro 1.5 等领先的闭源模型,特别是在与 OCR 相关的数据集中。论文用下面一张图非常生动地展示了他们为 达到 AGI 星球 所做的努力:

图中主要涉及 InternVL 的三个改进:
(1)强视觉编码器
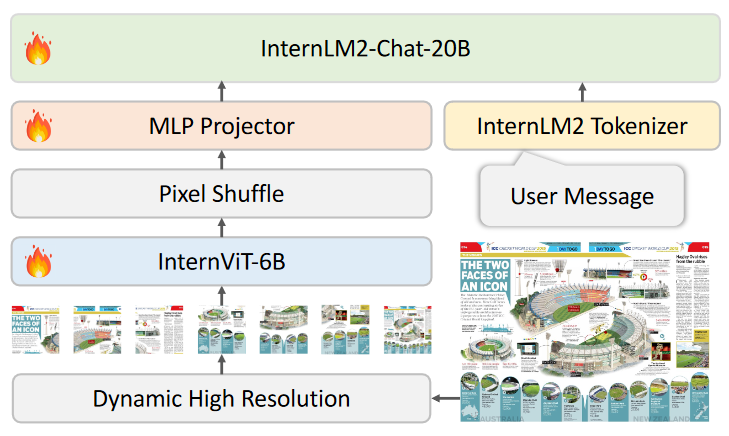
为大规模视觉基础模型 InternViT-6B 探索了一种持续学习策略,提高了其视觉理解能力,并使其可以在不同的LLM中迁移和重用。
总体的结构则是采用与流行的多模态大模型类似的 ViT-MLP-LLM 架构,通过MLP映射器将预训练好的InternViT-6B与InternLM2-20b结合在一起。同时还使用一个简单的Pixel Shuffle 技巧将视觉标记的数量减少到四分之一。
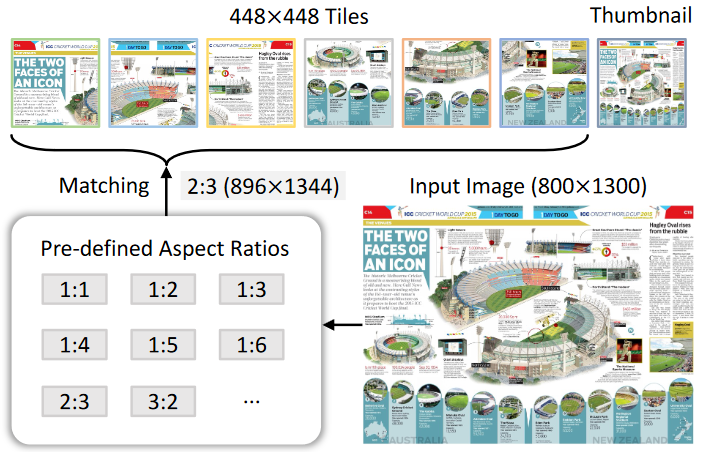
(2)动态高分辨率
根据输入图像的长宽比和分辨率,将图像划分为1到40个448×448像素的图块,最高支持4K分辨率输入。
研究人员则是从预定义的比例中动态匹配最佳宽高比,将图像划分为448×448像素大小的块,并为全局上下文创建缩略图。该方法最大限度地减少了纵横比失真,并在训练期间适应不同的分辨率。
在训练过程中,视觉标记的数量范围为 256 到 3,328。在测试过程中,图块数量最多可以增加到 40 个,从而产生 10,496 个视觉标记,从而实现最高4K分辨率的输入。
(3)高质量的双语数据集:
收集了高质量的双语数据集,涵盖常见场景、文档图像,并用英文和中文问答对进行注释,显着提高了 OCR 和中文相关任务的性能。
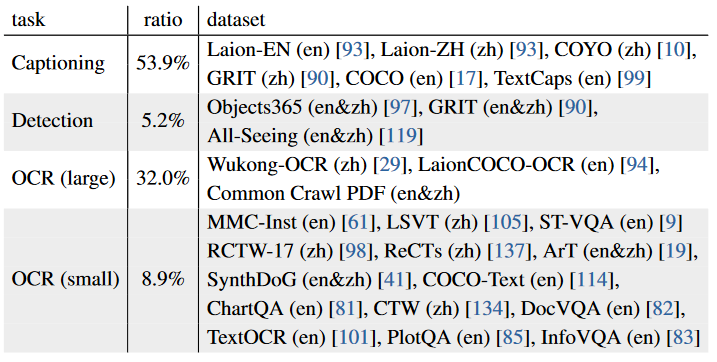
论文中也提供了模型在预训练和微调阶段使用的各类任务以及对应的数据集,并且都是公开数据集。为了构建大规模 OCR 数据集,研究人员还利用 PaddleOCR 对 Wukong 数据集的图像执行中文 OCR,对 LAION-COCO 数据集的图像执行英文 OCR。
同时,为了增强模型的多语言能力,我们实现了数据翻译pipeline,利用最先进的开源LLM或GPT-3.5 将英文数据集转换为另一种语言(例如中文),保持双语标注的一致性和准确性。在下表中,用括号注释了数据集所使用的语言。
二、模型介绍:Mini-InternVL 1.5
在Mini-InternVL 1.5的工作中,InternViT-6B-448px-V1-5被蒸馏到300M,并使用InternLM2-Chat-1.8B或Phi-3-mini-128k-instruct作为语言模型。这产生了一个性能出色的小型多模态模型。
正如下图所示,Mini-InternVL 1.5采用了与InternVL 1.5相同的模型架构。我们只是将原始的InternViT-6B替换为InternViT-300M,将InternLM2-Chat-20B替换为InternLM2-Chat-1.8B或Phi-3-mini-128k-instruct(3.8B)。在训练方面,Mini-InternVL 1.5使用了与InternVL 1.5相同的数据来训练这个更小的模型。此外,由于较小模型的训练成本较低,在训练期间使用了8K的上下文长度。
实验结果表明小视觉模型(InternViT-300M)非常适合较小的语言模型(1.8B或3.8B) 这种组合最大限度地提高了效率,证明了小型模型在处理复杂任务方面的有效性。此外,小型模型显著降低了内存需求,使其在实际使用中更易于访问和高效。
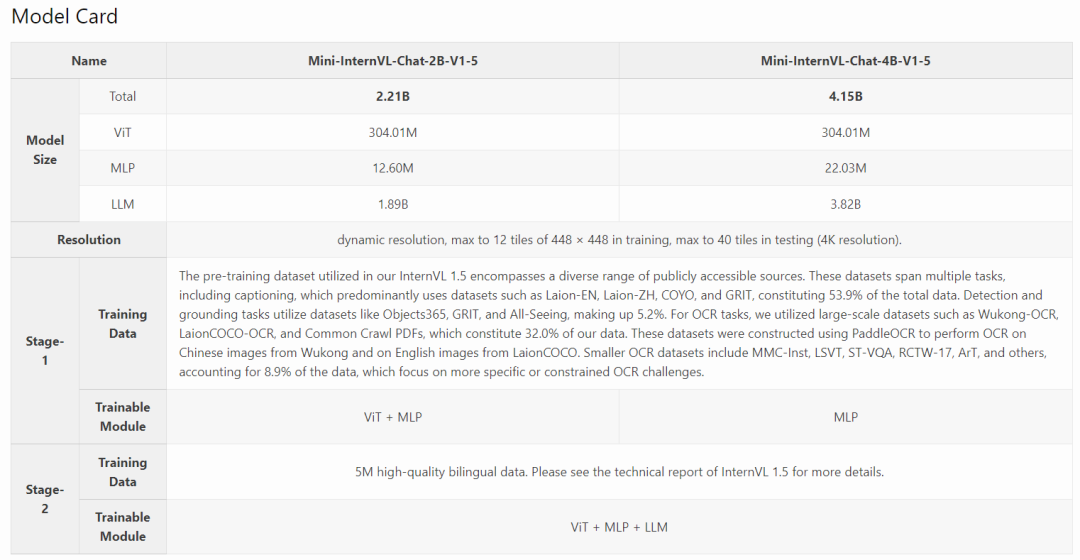
模型参数分布、训练数据及训练方法如下:

三、效果体验
[在线网页:https://internvl.opengvlab.com/]
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

