01_大数据导论与Linux基础
赞
踩
00-Hadoop导学
大数据处理,其核心在于海量的数据存储和海量的数据计算。





本课程基于Linux系统作为集群部署系统,以SQL作为开发语言。贯穿分布式存储技术(Hadoop HDFS)分布式计算技术(Hadoop MapReduce)、分布式资源调度技术(Hadoop YARN)以及数据仓库技术(Hive)。并结合综合案例掌握企业级BI报表分析以及ETL数据处理流程。
学习完本课程,你将掌握以Hadoop技术栈进行大规模数据计算和存储的能力,
01-课程内容大纲与学习目标


02-数据分析与企业数据分析方向





现状分析侧重于实时计算,历史数据侧重于离线计算,预测分析侧重于机器学习
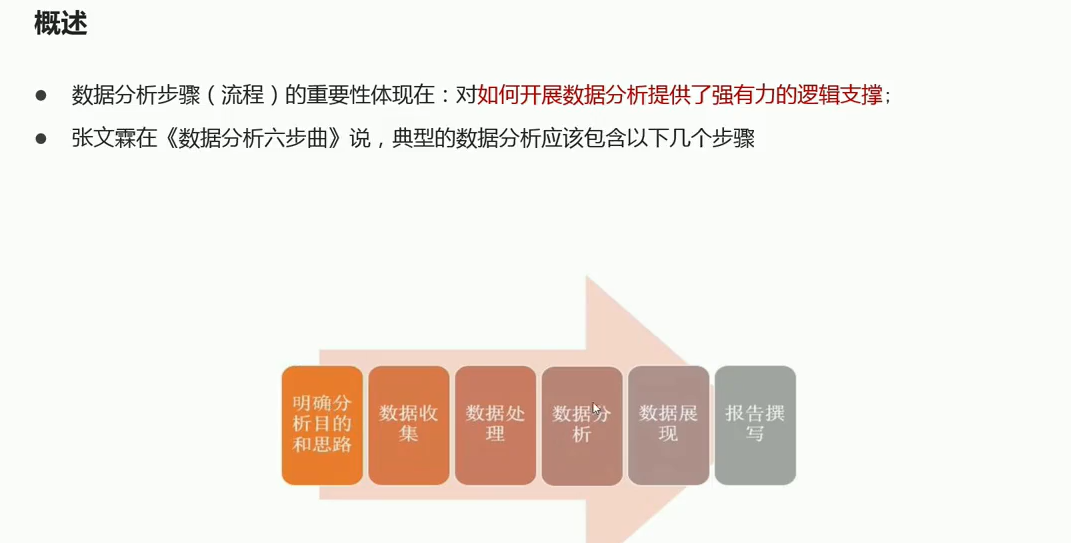
03-数据分析基本流程步骤







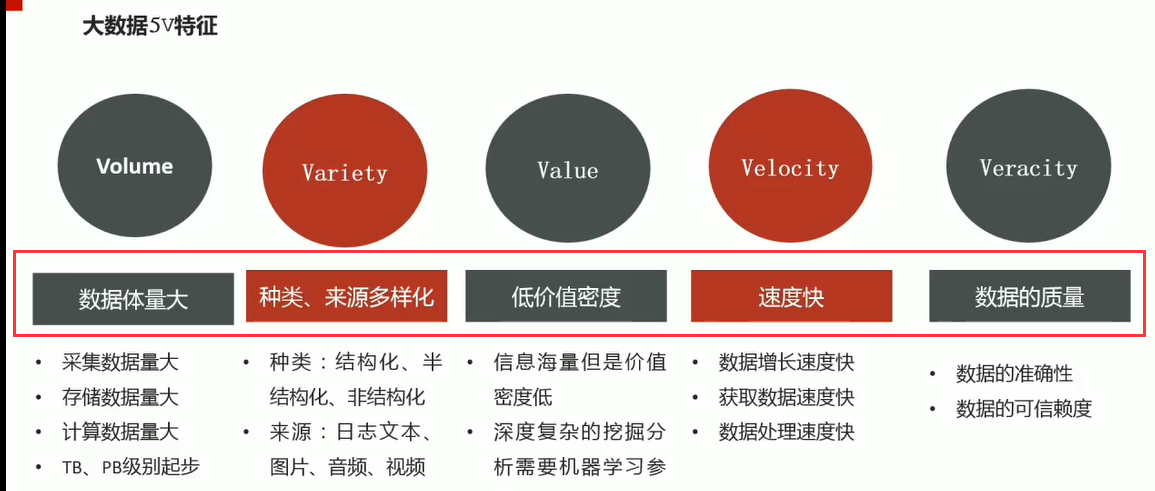
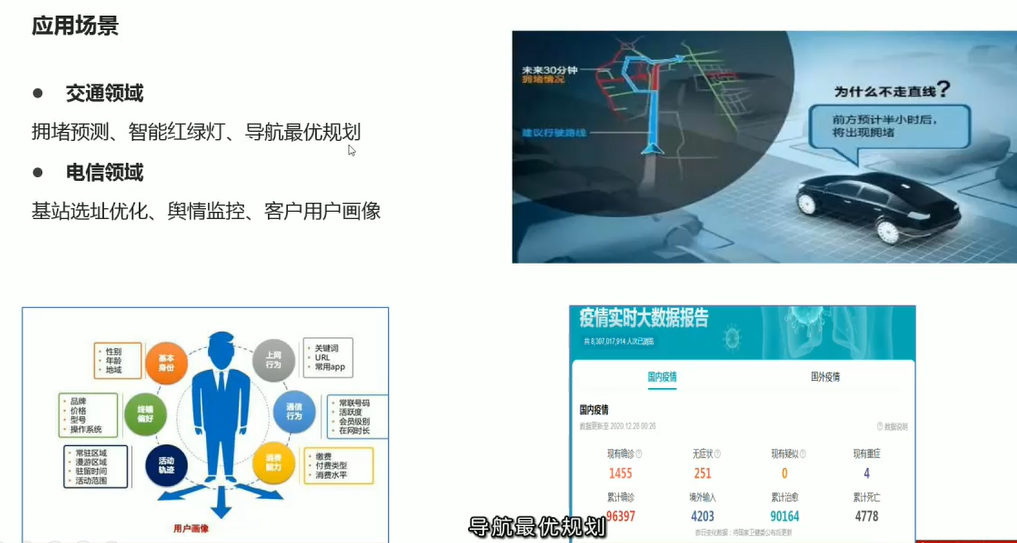
04-大数据时代







05-分布式与集群概念

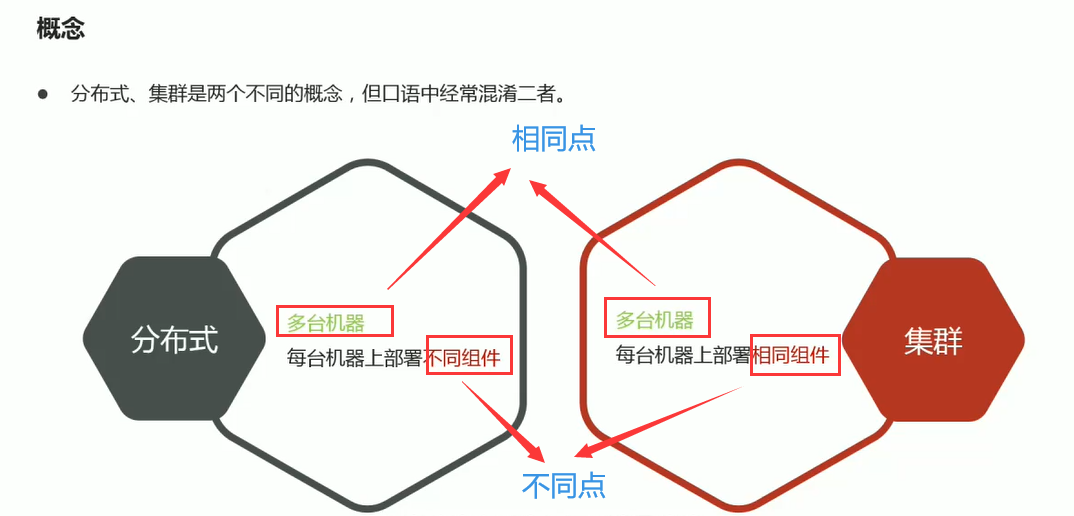
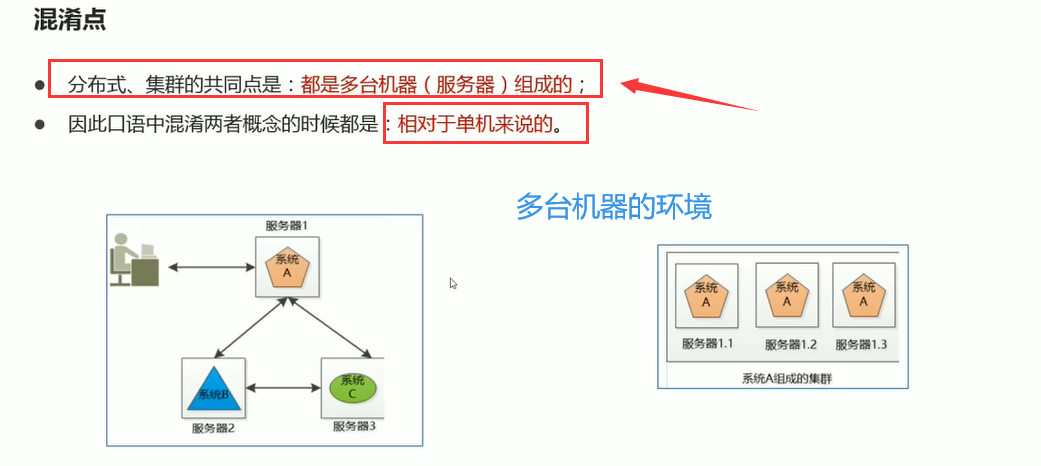
想象一个场景,我们去到天猫京东上买东西,那么京东它这一个网站别后到底是几台服务器在给我们提供支撑?肯定不止一台,那背后有服务器专门提供我们的商品的,有的专门承担的我们支付服务的,有的专门承担我们用户评论的等等等,那么其实它背后所代表的的正式我们所讲的分布式概念,首先是多台机器,但是每台机器上它运行的不同的服务,如图所示,这里有三台机器分别运行的系统a、系统b、系统c,但是这三台机器之间通过网络通信共同配合,对外提供服务,其实对我们的用户来说他根本感受不到背后到底是一台机器还是多台机器。这就是我们分布式最明显的特点,对用户来说好像是一台,但其实整个系统它多台机器互相通信配合,那只不过每台机器上它的组件是不一样的。左边这个图代表的是分布式。
右边这个图代表的是集群,那么发现集群首先也是多台机器,服务器1、2、3,那么它岁大的区别是,每台服务器上它部署的系统都是同样的,那么这个东西怎么出现呢,简单举个例子:百度提供全球的中文搜索,如果只有一台服务器的话,全球这么多人去访问它,这台服务器肯定扛不住,怎么办呢?百度可以在北京部署一台搜索服务器,在上海部署一台,在广东部署一台,那么这样的话,我们就可以多个省多台服务器都来去提供我们的这个搜索支持,那前面再安上一些所谓的负载均衡,根据我们的省份,不同的省访问不同的服务器,这样就实现了我们整个搜索功能的实现。

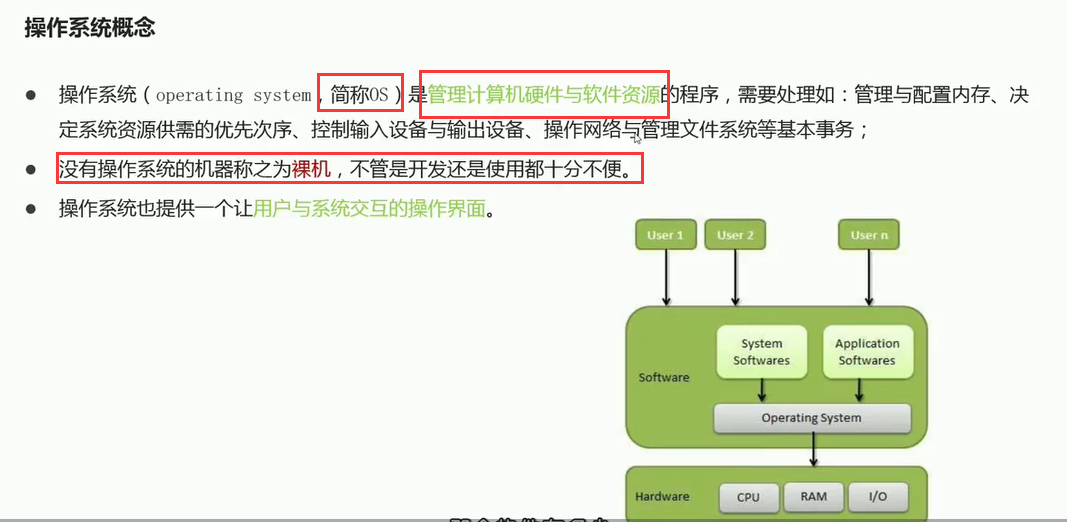
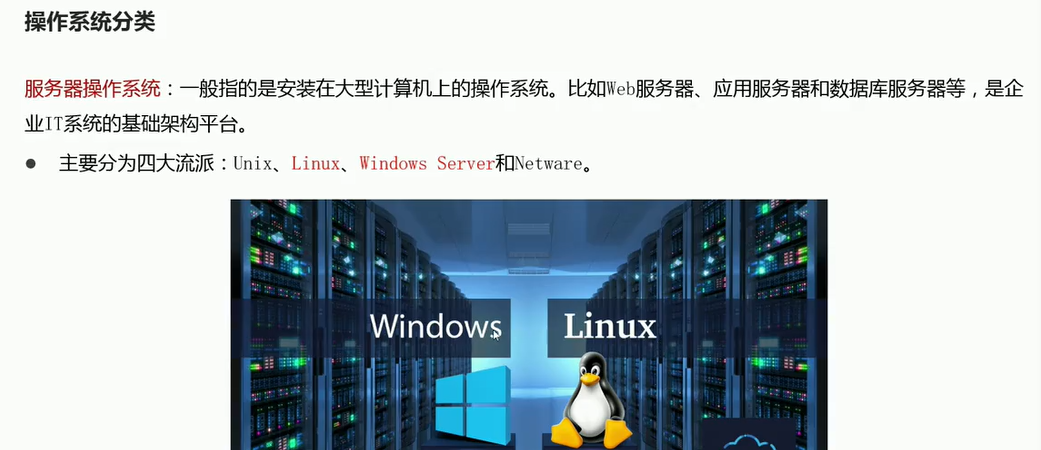
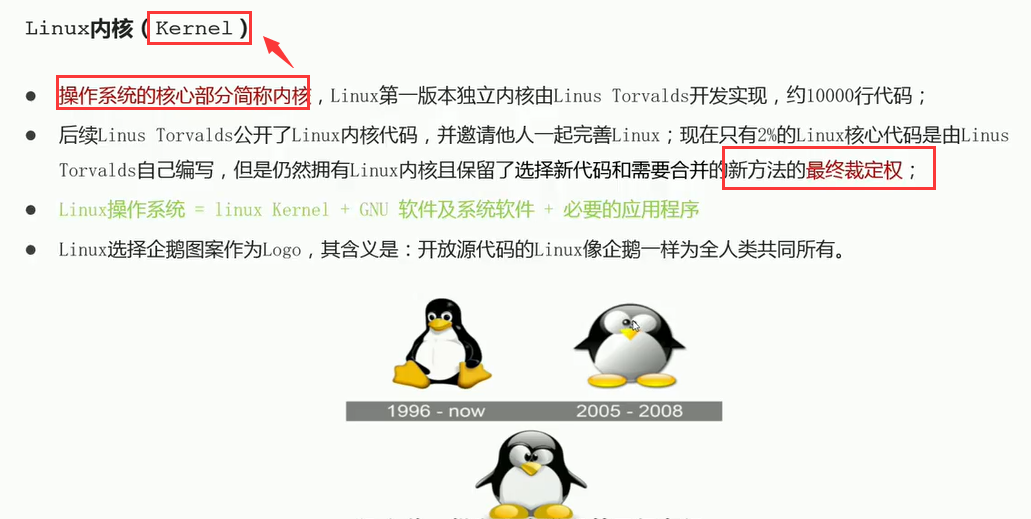
06-Linux操作系统概述







07-VMware虚拟机概念与安装