
热门标签
热门文章
- 12023年全国大学生电子设计竞赛E题总结分享(全国一等奖)_2023电赛e题
- 2【JVM基础04】——组成-什么是虚拟机栈?
- 3percona mysql 5.7_使用Percona MySQL 5.7版本遇到的坑
- 4Java实现手机库存管理_java手机库存管理案例
- 5Mac环境Nginx的搭建以及使用,感悟分享_mac使用nginx
- 6鱼哥赠书活动第17期:看完这本《Python数据分析》菜鸟也能做Python数据分析?_菜鸟编程 python数据分析_谁说菜鸟不会数据分析python篇pdf
- 7Pytorch中设计随机数种子的必要性_pytorch为什么要几算随机数
- 8生成式对抗网络(GAN)的数学原理与实现_生成对抗网络的数学原理
- 9C# 开发Windows服务程序并在计算机上注册服务_c# 注册服务
- 10NLP文本相似度(word2vec)的原理及实现_word2vec计算文本相似度
当前位置: article > 正文
rancher pods Crashloopbackoff 问题解决办法一_crashloopbackoff怎么解决
作者:从前慢现在也慢 | 2024-07-13 13:22:50
赞
踩
crashloopbackoff怎么解决
一、问题描述
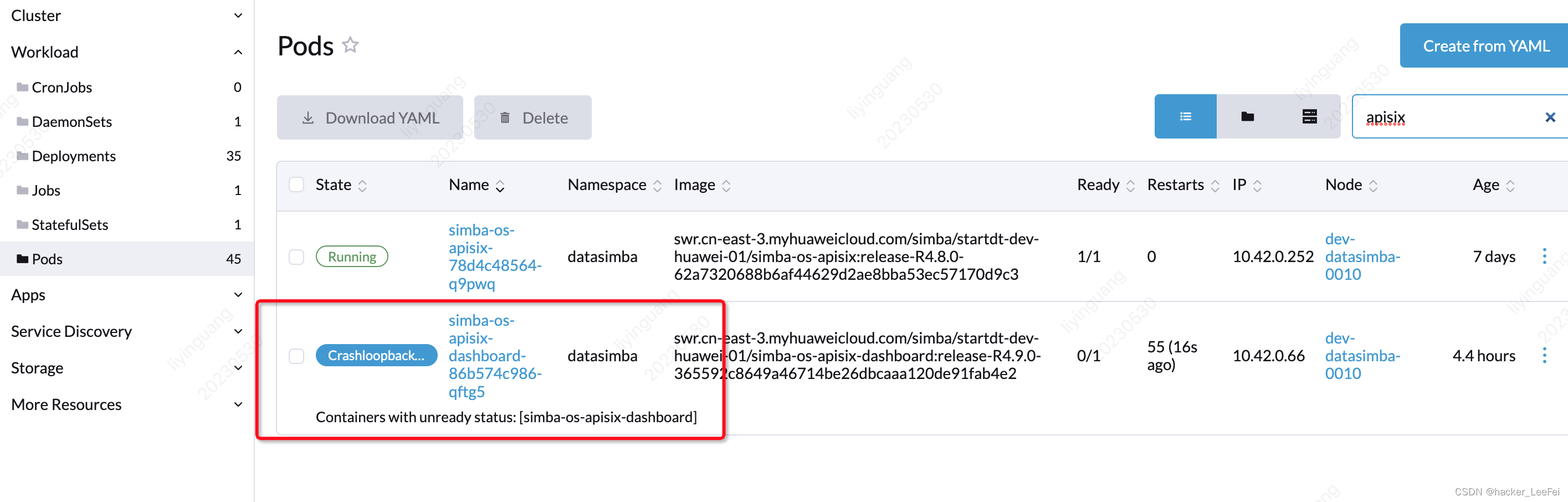
rancher中重启pod,一直无法正确启动,点击pod,可以见到如下异常信息:
CrashLoopBackOff (back-off 5m0s restarting failed container=simba-os-apisix-dashboard pod=simba-os-apisix-dashboard-86b574c986-qftg5_datasimba(b6b49f2e-38c5-41bf-850b-6d4746ed45d4)) | Last state: Terminated with : Completed, started: Tue, May 30 2023 8:42:34 pm, finished: Tue, May 30 2023 8:42:39 pm
- 1
- 2
如下图所示:

二、问题根因
查看错误日志,异常描述为:超过了截止日期
{"level":"warn","ts":"2023-05-30T20:42:39.860+0800","caller":"clientv3/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"endpoint://client-1a87f1c5-10b6-4d04-8003-6b6de54f74ef/etcd-1:2379","attempt":0,"error":"rpc error: code = Unknown desc = context deadline exceeded"}
Error: etcd get failed: rpc error: code = Unknown desc = context deadline exceeded
- 1
- 2
明显是etcd中存储的对应值过期了。
三、解决办法
找到statefulSets菜单,重启etcd实例,etcd会刷新存储值。
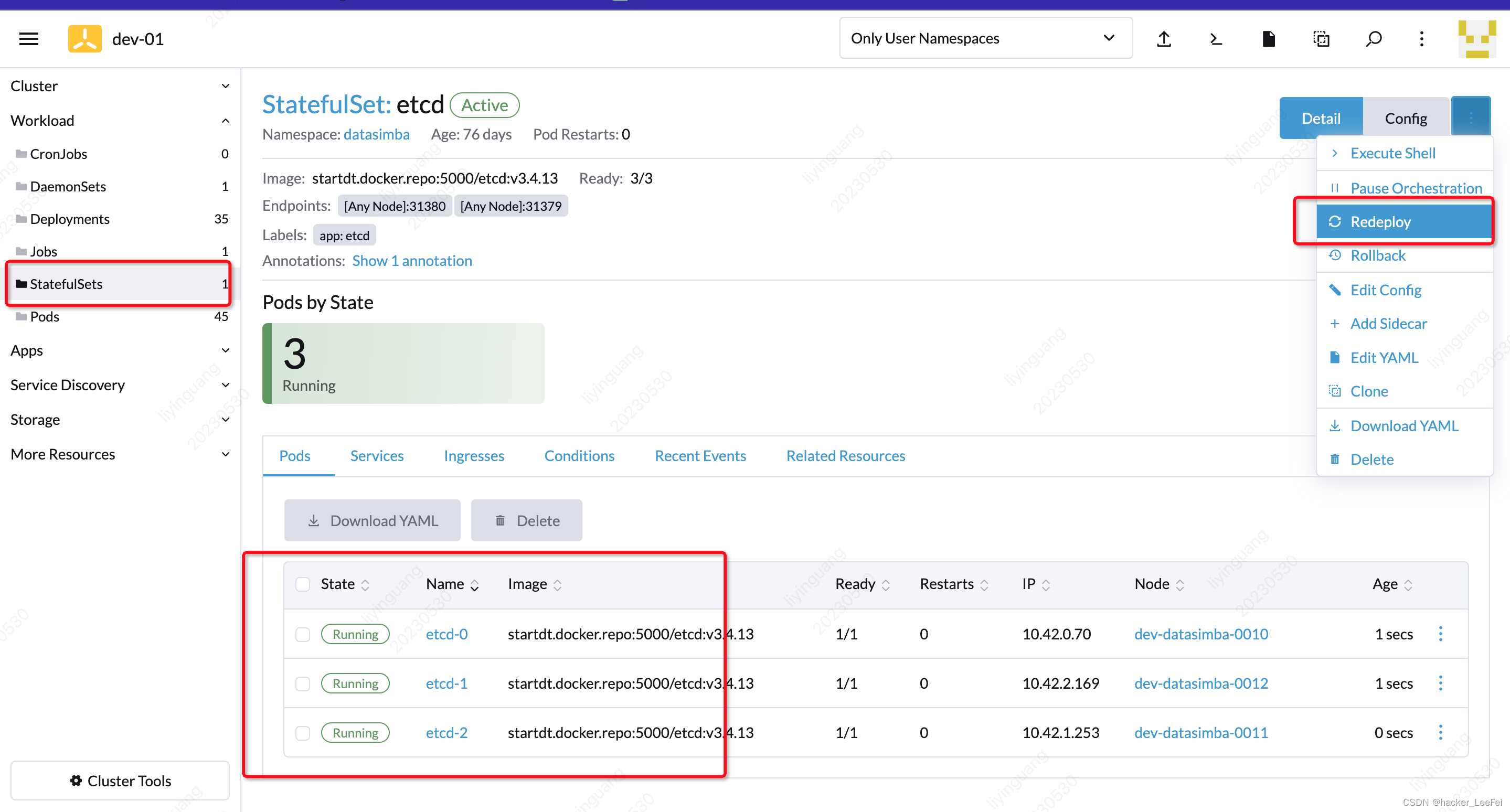
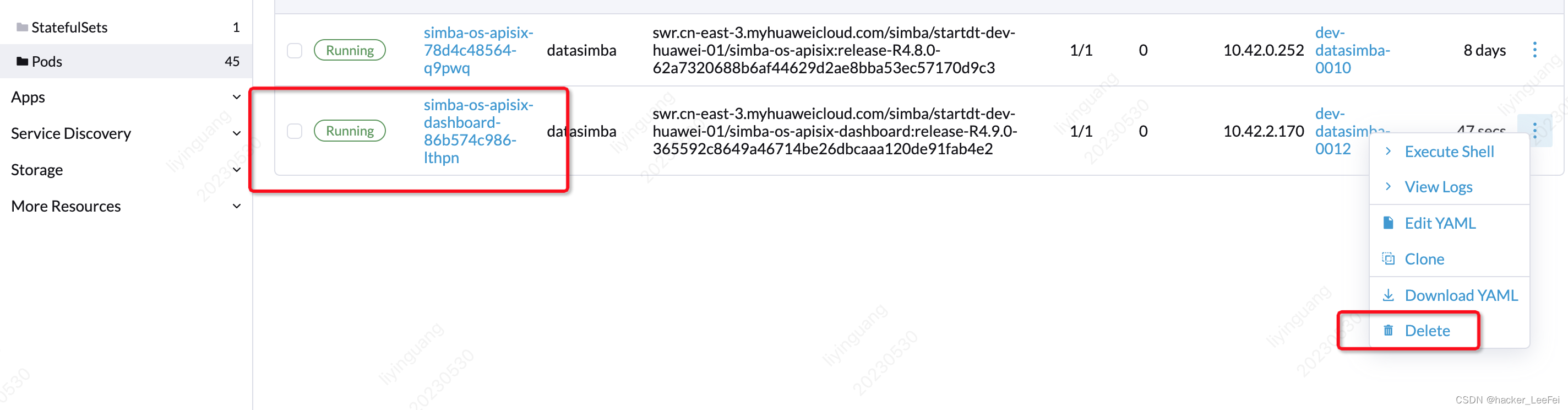
然后重启(我这里是删除,因为做了可用性配置)对应的服务实例即可。

四、知识补充
Rancher 是一个开源的 Kubernetes 管理平台,可以帮助用户创建和管理多个 Kubernetes 集群。etcd 是一个分布式的键值存储系统,用于保存 Kubernetes 集群的状态和配置数据。
Rancher 的 etcd 是指在 Rancher 管理的 Kubernetes 集群中运行的 etcd 实例。Rancher 可以使用不同的方式创建 Kubernetes 集群,例如使用 RKE、K3s、托管服务等。不同的方式可能会影响 etcd 的部署和配置。例如,使用 RKE 创建的集群可以自定义 etcd 的节点、参数、备份等,而使用托管服务创建的集群则由云服务商负责 etcd 的管理。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/819704
推荐阅读
相关标签

