
微服务系列--深入理解RPC底层原理与设计实践_深入理解rpc框架原理与实现 pdf
赞
踩
在微服务系统当中,各个服务之间进行远程调用的时候需要考虑各种各样的场景,例如以下几种异常情况:
-
超时调用
-
失败重试
-
服务下线通知
-
服务上线通知
-
服务分组
-
请求队列
等等…
国内也有一些有先见之明的技术专家们对于这些技术有了较早的认知,因此很早便开始了关于远程服务调用中间件的开发。慢慢地,一些国内大厂自研的RPC调用框架开始变做了一款产品向市面上去进行推广。
今年年初的时候,我花了大概一个半月的业余时间自己打磨了一套RPC框架,通过实践尝试后发现,要想真正地落地一款给公司内部使用的RPC框架难度真的超乎想象。本文不会过多地去介绍市面上某一款中间件的底层源代码是如何执行和编写的,更多是通过结合一些中间件底层设计的原理来阐述 我自己是如何设计一款RPC框架的。
准备工作
为了写一款可用的RPC框架,我大概准备了这些技术工作:
-
阅读了Dubbo内部的大量源码设计。
-
了解关于RPC框架设计的难点和痛点。(这里主要感谢nx的东哥,上了他的课程之后很多技术点都有了新的理解和感悟)
-
不断地实践和测试。
-
自己编写的中间件如何能够优雅地接入Spring容器。
RPC的整体设计思想
起初在设计RPC远程调用框架的时候,主要的设计思路是采用了经典的生产者-消费者思想。客户端发送请求,服务端接收之后匹配本地已有的服务方法进行处理执行。
但是在实际到落地过程中却发现,其中的技术复杂性远远超出预期~~
最终结果如下图所示:
整个项目的包结构整理
客户端调用:
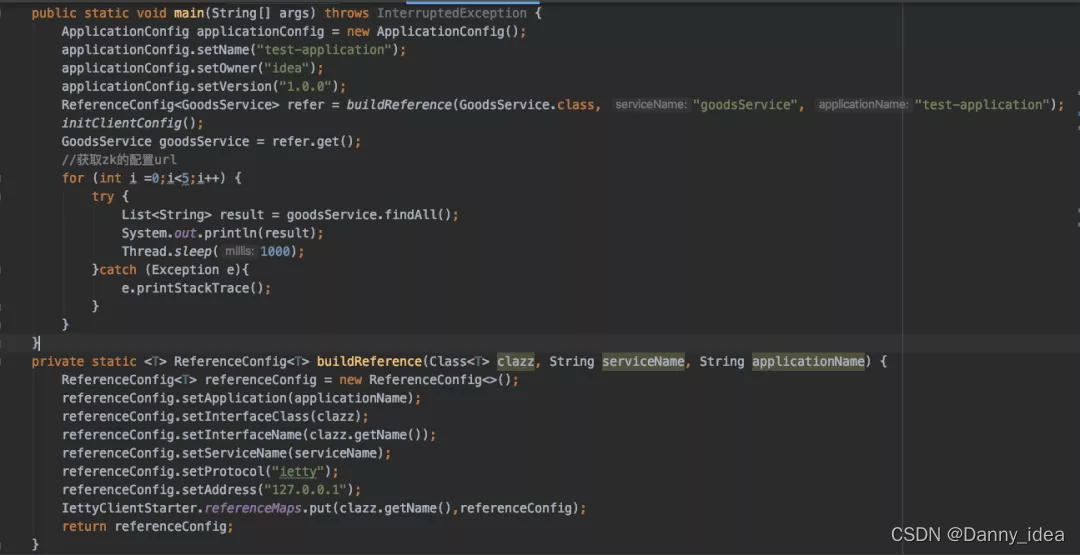
服务端使用:

ps:这里面的每个api和设计思路大部分都是模仿了Dubbo框架内部的源代码设计以及部分自己的改编。
本地代理的设计
为了能够保证远程方法的调用使用起来和本地方法调用一样简单,通常可以使用代理模式去实现。场景的代理模式有好2大类:静态代理和动态代理,静态代理需要通过硬编码的方式实现,不现实,这里直接不合适。
动态代理主要有以下两种:
- JDK代理
- CGLIB代理
Java给出了动态代理,动态代理具有如下特点:
1.Proxy对象不需要implements接口;
2.Proxy对象的生成利用JDK的Api,在JVM内存中动态的构建Proxy对象。需要使用java.lang.reflect.Proxy类的newProxyInstance接口
public static <T> T getProxy(final Class interfaceClass, ReferenceConfig referenceConfig) {
return (T) Proxy.newProxyInstance(interfaceClass.getClassLoader(), new Class[]{interfaceClass}, new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//每次执行目标方法的时候都会回调到这个invoke方法处
return null;
}
});
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
JDK动态代理要求target对象是一个接口的实现对象,假如target对象只是一个单独的对象,并没有实现任何接口,这时候就会用到Cglib代理(Code Generation Library),即通过构建一个子类对象,从而实现对target对象的代理,因此目标对象不能是final类(报错),且目标对象的方法不能是final或static(不执行代理功能)。
//给目标对象创建一个代理对象 public Object getProxyInstance() { //工具类 Enhancer en = new Enhancer(); //设置父类 en.setSuperclass(target.getClass()); //设置回调函数 en.setCallback(this); //创建子类代理对象 return en.create(); } public Object intercept(Object object, Method method, Object[] arg2, MethodProxy proxy) throws Throwable { System.out.println("before"); Object obj = method.invoke(target); System.out.println("after"); return obj; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
我最终选择了JDK作为基本的动态代理实现方案,一开始的技术选型并没有选择更加完美的方案,而是采用了最为简单熟悉的技术。
如果读者感兴趣的话,可以阅读我之前介绍aop原理的文章,内部有详细讲解cglib底层原理的细节。点击这跳转
远程调用的数据传输
本地代理设计好了之后,需要考虑如何将数据发送给到服务端的问题了。底层采用的是netty框架,为了避免粘包和拆包的问题,我尝试使用了ObjectEncoder和ObjectDecoder两个netty内置的组件。
关于netty内部出现粘包,拆包现象的解决手段,可以细看这篇文章:
https://www.cnblogs.com/rickiyang/p/12904552.html
协议体的内部需要设计哪些字段?
大概整理了一下代码,基本结构如下所示:
public class IettyProtocol implements Serializable { private static final long serialVersionUID = -7523782352702351753L; /** * 魔数 */ protected long MAGIC = 0; /** * 客户端的请求id */ private String requestId; /** * netty专属 */ private ChannelHandlerContext channelHandlerContext; /** * 0请求 1响应 * @see CommonConstants.ReqOrRespTypeEnum */ protected byte reqOrResp = 0; /** * 0需要从服务端返回数据 1不需要从服务端响应数据 */ protected final byte way = 0; /** * 0是心跳时间,1不是心跳事件 */ private byte event = 0; /** * 序列化类型 */ private String serializationType; /** * 状态 */ private short status; /** * 返回的数据类型格式 */ private Type type; /** * 消息体 请求方发送的函数类型,参数信息都存在这里, 接收方响应的信息也都存在这里 */ private byte[] body; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
稍微解释几个字段:
requestId 客户端的请求id(用于请求响应做必配使用,下文中会介绍到)
reqOrResp 协议数据包的类型(标示该数据包是请求类型还是响应类型)
type 是指调用该方法的返回数据格式类型 (例如int,String,返回类型在做数据的序列化转换的时候会非常有用)
body 这里面是核心重点,主要的调用服务名称,参数,方法等详细信息都会先转换为字节数组,然后再通过网络将其发送出去。
如何将不同格式的数据转换为字节数组
数字类型
将数字类型转换为二进制,在之前的一篇文章中我有写过详细的底层实现机制,核心是通过将数字的二进制数右移8位,然后存入byte数组当中。核心代码为:
/** * 字节转成数字 int 大小是4个字节 * * @param bytes * @return */ public static int byteToInt(byte[] bytes) { if (bytes.length != 4) { return 0; } return (bytes[0]) & 0xff | (bytes[1] << 8) & 0xff00 | (bytes[2] << 16) & 0xff0000 | (bytes[3] << 24) & 0xff000000; } /** * 数字转成字节 int 大小是4个字节 * * @param n * @return */ public static byte[] intToByte(int n) { byte[] buf = new byte[4]; for (int i = 0; i < buf.length; i++) { buf[i] = (byte) (n >> (8 * i)); } return buf; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
字符串类型
将字符串转换为对应的字符数组,然后每个数组的char类型使用asc码映射为数字,接下来又是回归到数字转换的思路上了。
集合,复杂对象类型
这些类型可以尝试先通过json转换为字符串,然后再将字符串转换为char数组,再转换为数字数组类型,后还是要回归到数字转换的思路上。
数据接收与响应设计
早期在做RPC通讯设计的时候,采用的是简单的生产者消费者模型。下边给出早期自己在进行实现过程中所思考的一些点:
同步发送数据
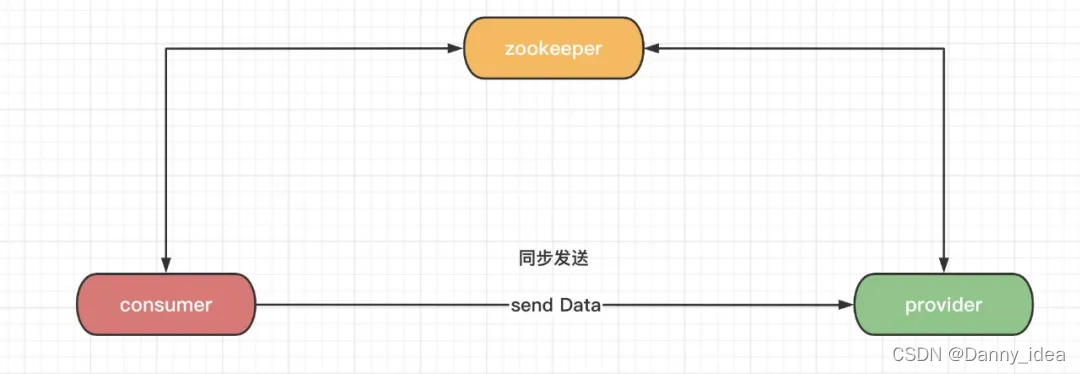
这类同步发送设计案例来看,consumer端发送数据之后,consumer会一直处于等待状态,只有等到数据抵达到provider端并且处理完毕之后,consumer端才会继续进行下去。
这样设计的弊端很明显:
consumer和provider的吞吐量都不高,而且一旦某个接口出现了超时还会影响其他接口的调用堵塞。
consumer端异步发送,provider端异步接收处理
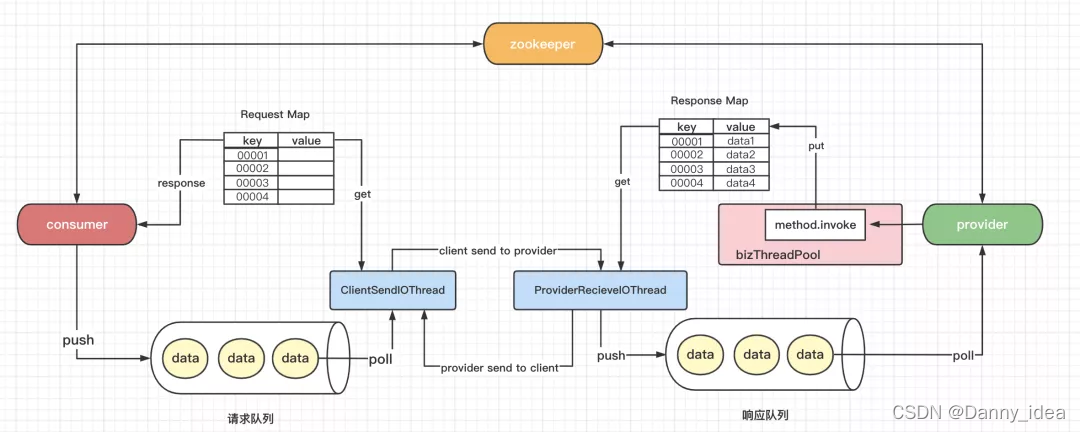
这里需要引入两个新的概念,io线程和业务线程。整体设计如下图所示:
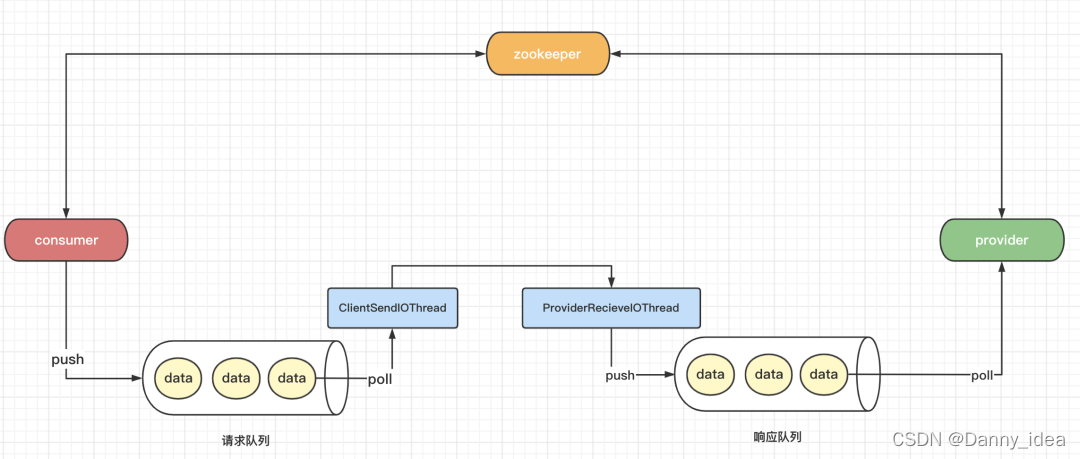
客户端发送数据的时候,不再是处于等待的状态,它会只需要将数据放入到一个本地的请求队列中即可。客户端的io线程会不断地尝试从队列中取出数据,然后进行网络发送。服务端也会专门有一个io线程负责接收这类数据,接着将数据放入到服务端的一个队列缓冲中,然后再交给服务端的业务线程池去慢慢消费掉服务端的缓冲队列内部的数据。
服务端的核心设计如下:
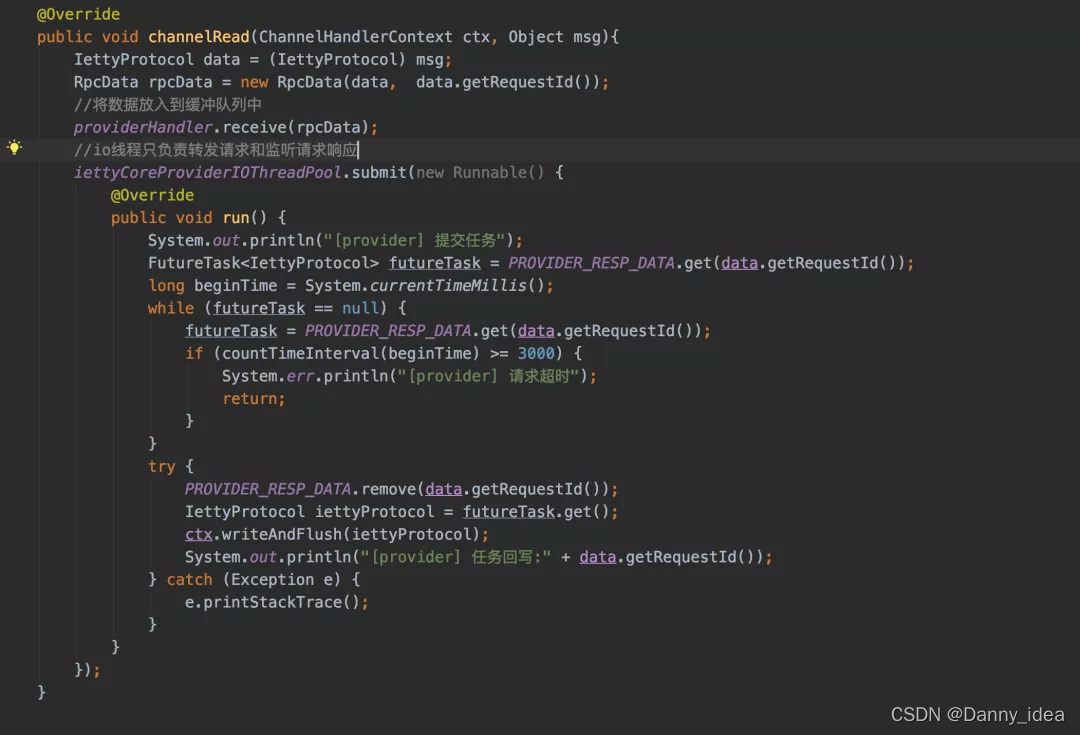
provider端的数据处理完毕之后该如何正确返回?
为了解决这个问题,我尝试阅读了一下Dubbo的底层源代码,然后借鉴了其中的设计思路进行了一波实现。
客户端如何接收响应
其核心的本质是客户端在发送请求到时候会生成一个唯一的requestId,然后客户端在发送数据之后,会有一个Map集合(key是requestId,value是接口响应值)管理接口响应到数据,客户端的调用线程在执行了写入数据到发送队列之后需要不断监听Map集合中对应requestId的value是否有值,如果超过指定时间都没有数据,那么就抛出超时异常,如果收到了响应数据则正常返回即可。
服务端返回响应
服务端的本地代码正常处理完数据之后要将数据写入一个Map集合中,服务端的io线程会不断轮训这份Map集合(key是客户端发送过来的requestId,value是本地代码处理完之后写入的数据),如果发现对应的requestId有写好的返回数据,就会将其发送给客户端。
整体设计大概如下图所示:
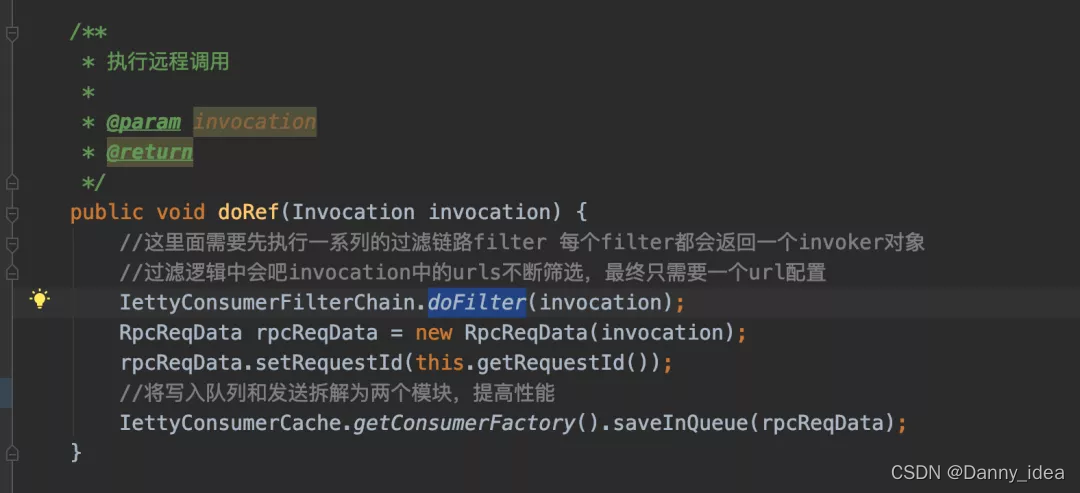
过滤器的设计
好了基本的调用链路大概是如同上边的描述给梳理出来了。接下来就是一些扩展功能模块了。
发送过程中需要做一些装饰包装,以及过滤的相关功能。此时就可以采用责任链的方式进行设计。
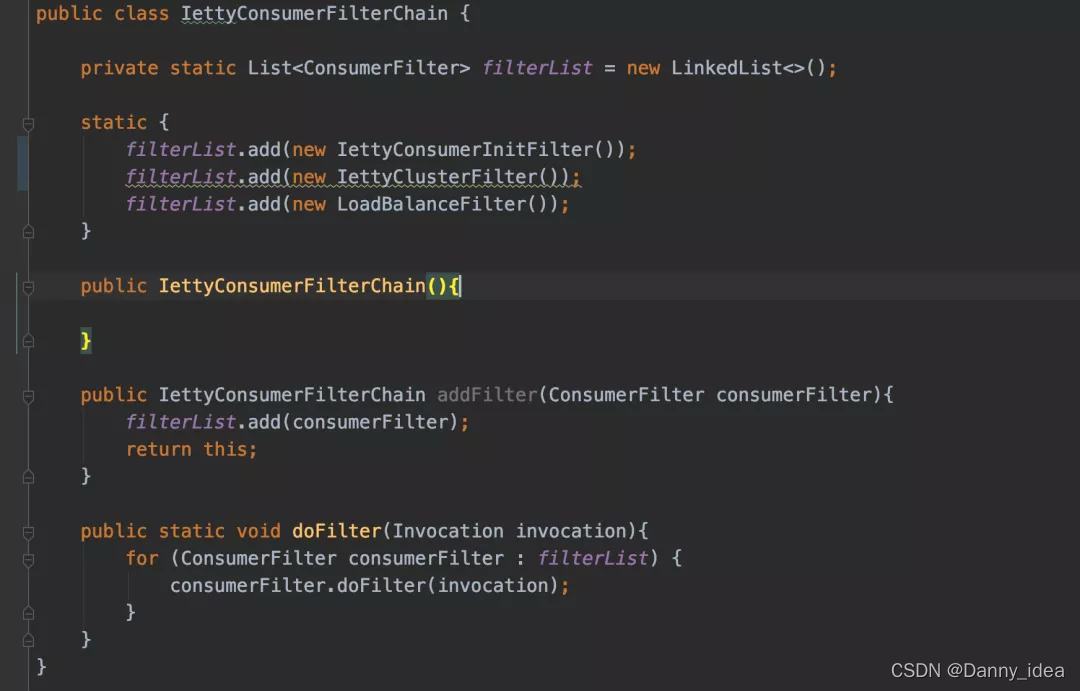
过滤器部分我大概分了两种类型,一种是消费者使用的过滤器,一种是服务提供者专属的过滤器。
过滤器部分的设计主要是用了责任链的模式实现,这块比较简单,不打算做过多介绍了。
延时任务的设计
在微服务调用的中间件中,延时任务是一种经常会使用到的设计,例如在超时重试,定时心跳发送,注册中心发布失败重试等场景下。其核心的共同点都是在当前时间戳过后的指定时间点执行某个任务。这类设计我看了下JDK内部的Timer和DelayedQueue设计的原理。
常规的JDK 的 java.util.Timer 和 DelayedQueue 等工具类,可实现简单的定时任务,底层用的是堆数据结构,存取复杂度都是 O(nlog(n)),无法支撑海量定时任务。
而在定时任务量大、性能要求高的场景,为将任务存取及取消操作时间复杂度降为 O(1),会使用时间轮方案。
在自己实现RPC框架中,尝试使用了时间轮的机制来实现心跳包发送部分。
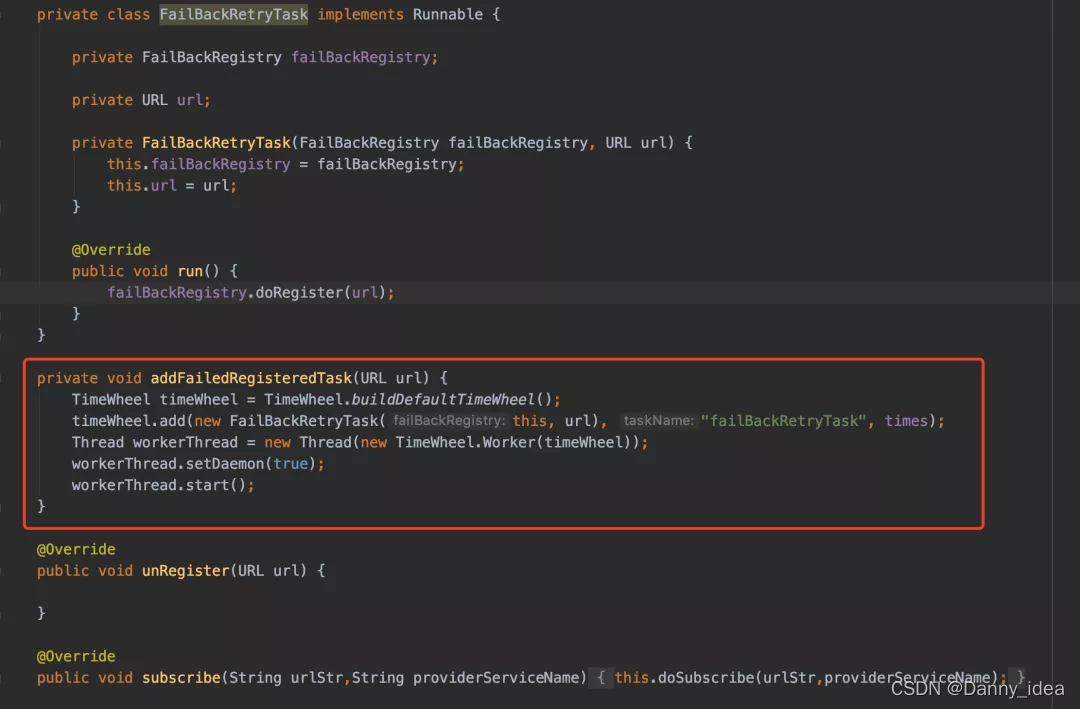
什么是时间轮
一种高效批量管理定时任务的调度模型。时间轮一般会实现成一个环形结构,类似一个时钟,分为很多槽,一个槽代表一个时间间隔,每个槽使用双向链表存储定时任务。指针周期性地跳动,跳动到一个槽位,就执行该槽位的定时任务。
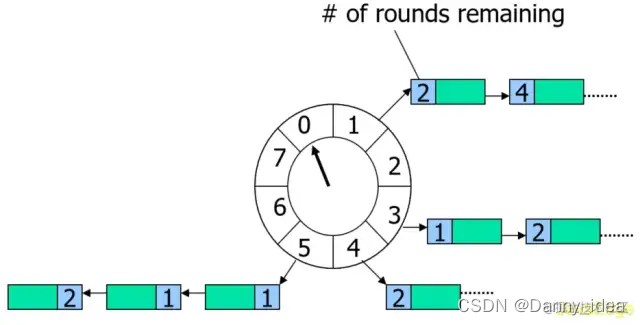
Dubbo 的时间轮实现位于 dubbo-common 模块的 org.apache.dubbo.common.timer 包中,如果感兴趣的朋友可以深入阅读下内部的源代码设计与实现。
注册中心的引入
为了能够保证服务发布之后及时通知到各个服务的调用方,注册中心的设计必不可少。除此之外,注册中心的角色还能够较好地协调各个微服务调用之间的一些配置参数,例如权重,分组,版本隔离等等属性。
在自己进行实现落地的过程中,我选择了zookeeper作为默认的注册中心。为了方便后期的扩展,也是参考了Dubbo内部关于注册中心的实现思路,通过一个Registry的接口抽象,随机扩展了一些模版类等等。大概的设计如下图所示:
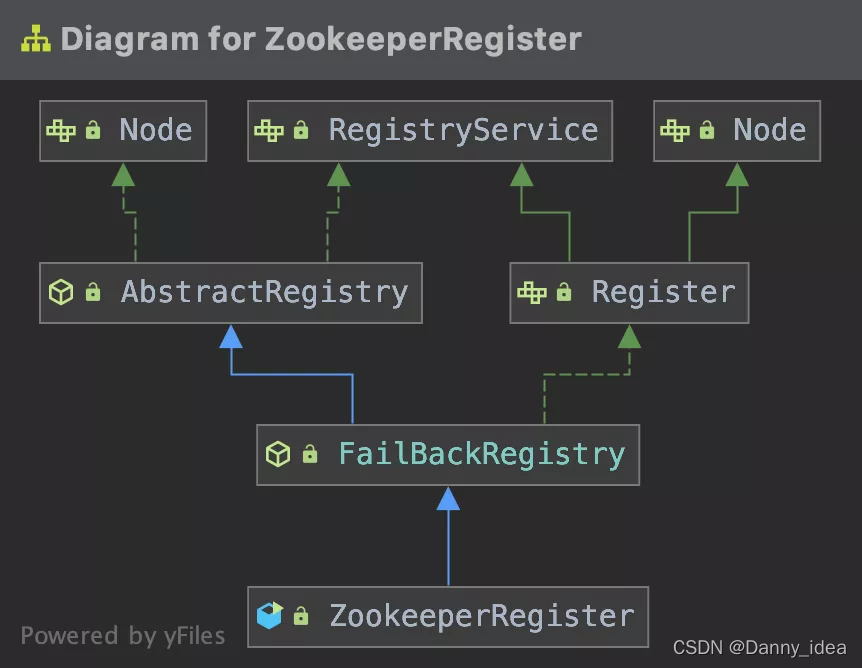
整体的服务注册接口代码如下:
public interface RegistryService { /** * 注册url * * 将dubbo服务写入注册中心节点 * 当出现网络抖动的时候需要进行适当的重试做法 * 注册服务url的时候需要写入持久化文件中 * * @param url */ void register(URL url); /** * 服务下线 * * 持久化节点是无法进行服务下线操作的 * 下线的服务必须保证url是完整匹配的 * 移除持久化文件中的一些内容信息 * * @param url */ void unRegister(URL url); /** * 消费方订阅服务 * * @param urlStr * @param providerServiceName */ void subscribe(String urlStr,String providerServiceName); /** * 更新节点属性之后通知这里 * * @param url */ void doSubscribeAfterUpdate(URL url); /** * 新增节点之后通知这里 * * @param url */ void doSubscribeAfterAdd(URL url); /** * 执行取消订阅内部的逻辑 * * @param url */ void doUnSubscribe(URL url); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
为了预防注册中心挂了之后,服务无法进行通信,每个通信节点都会将zk的服务注册节点信息提前预先持久化到本地进行暂存一份数据,从而保证一个服务的可用性。
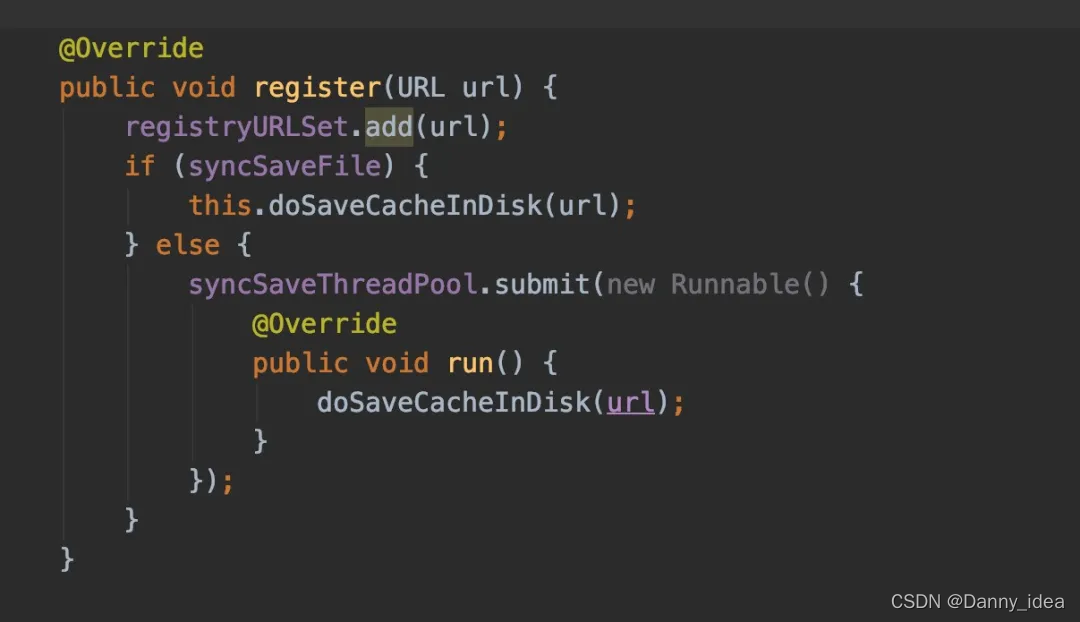
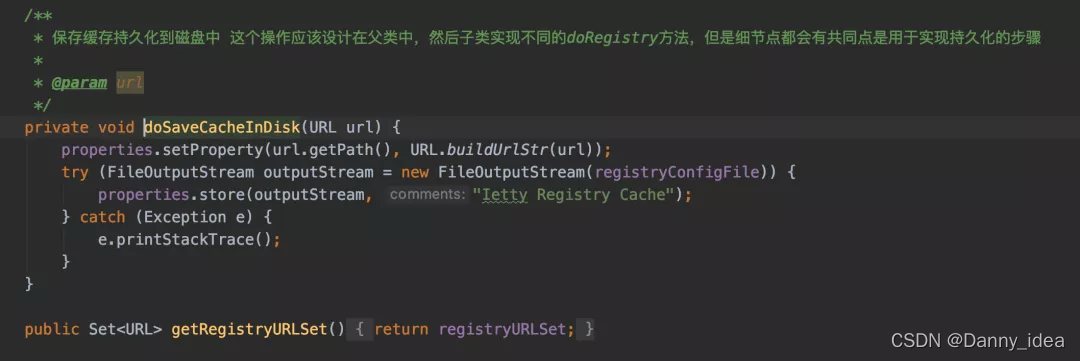
负载均衡策略的实现
在集群进行调用的时候,不可避免会有负载均衡的问题,这块的设计逻辑我参考了Dubbo的设计思路将其通过spi加载组件的方式进行框架的注入。
统一抽取了一个叫做LoadBalance的接口,然后底层实现了具体的负载均衡策略:
public class WeightLoadBalance implements LoadBalance { public static Map<String, URL[]> randomWeightMap = new ConcurrentHashMap<>(); public static Map<String, Integer> lastIndexVisitMap = new ConcurrentHashMap<>(); @Override public void doSelect(Invocation invocation) { URL[] weightArr = randomWeightMap.get(invocation.getServiceName()); if (weightArr == null) { List<URL> urls = invocation.getUrls(); Integer totalWeight = 0; for (URL url : urls) { //weight如果设置地过大,容易造成内存占用过高情况发生,所以weight统一限制最大大小应该为100 Integer weight = Integer.valueOf(url.getParameters().get("weight")); totalWeight += weight; } weightArr = new URL[totalWeight]; RandomList<URL> randomList = new RandomList(totalWeight); for (URL url : urls) { int weight = Integer.parseInt(url.getParameters().get("weight")); for (int i = 0; i < weight; i++) { randomList.randomAdd(url); } } int len = randomList.getRandomList().size(); for (int i = 0; i < len; i++) { URL url = randomList.getRandomList().get(i); weightArr[i] = url; } randomWeightMap.put(invocation.getServiceName(), weightArr); } Integer lastIndex = lastIndexVisitMap.get(invocation.getServiceName()); if (lastIndex == null) { lastIndex = 0; } if (lastIndex >= weightArr.length) { lastIndex = 0; } URL referUrl = weightArr[lastIndex]; lastIndex++; lastIndexVisitMap.put(invocation.getServiceName(), lastIndex); invocation.setReferUrl(referUrl); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
这里面的负载均衡实现手段并不是实时计算的思路,而是提前随机算好一组调用顺序,然后每次请求的时候按照这个已经具备随机性的数组进行挨个轮训发送服务调用。
这样可以避免每次请求过来都需要进行机器实时筛选计算的性能开销。
SPI扩展机制的设计
其实Spi的加载实现部分的关键就是将一份配置文件按照规定格式写好,然后通过某个loader对象将配置文件内部的每个类都提前加载到一份Map中进行管理。
下边我给出一份自己手写的简单案例,但是不包含自适应spi加载和spi内部自动依赖注入的功能。
public class ExtensionLoader { /** * 存储扩展spi的map,key是spi文件里面写入的key */ private static Map<String, Class<?>> extensionClassMap = new ConcurrentHashMap<>(); private static final String EXTENSION_LOADER_DIR_PREFIX = "META-INF/ietty/"; public static Map<String, Class<?>> getExtensionClassMap(){ return extensionClassMap; } public void loadDirectory(Class clazz) throws IOException { synchronized (ExtensionLoader.class){ String fileName = EXTENSION_LOADER_DIR_PREFIX + clazz.getName(); ClassLoader classLoader = this.getClass().getClassLoader(); Enumeration<URL> enumeration = classLoader.getResources(fileName); while (enumeration.hasMoreElements()) { URL url = enumeration.nextElement(); InputStreamReader inputStreamReader = new InputStreamReader(url.openStream(), "utf-8"); BufferedReader bufferedReader = new BufferedReader(inputStreamReader); String line; while ((line = bufferedReader.readLine()) != null) { if(line.startsWith("#")){ continue; } String[] keyClassInstance = line.split("="); try { extensionClassMap.put(keyClassInstance[0],Class.forName(keyClassInstance[1],true,classLoader)); } catch (ClassNotFoundException e) { e.printStackTrace(); } } } } } public static <T>Object initClassInstance(String className) { if(extensionClassMap!=null && extensionClassMap.size()>0){ try { return (T)extensionClassMap.get(className).newInstance(); } catch (InstantiationException e) { e.printStackTrace(); } catch (IllegalAccessException e) { e.printStackTrace(); } } return null; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
底层通信组件
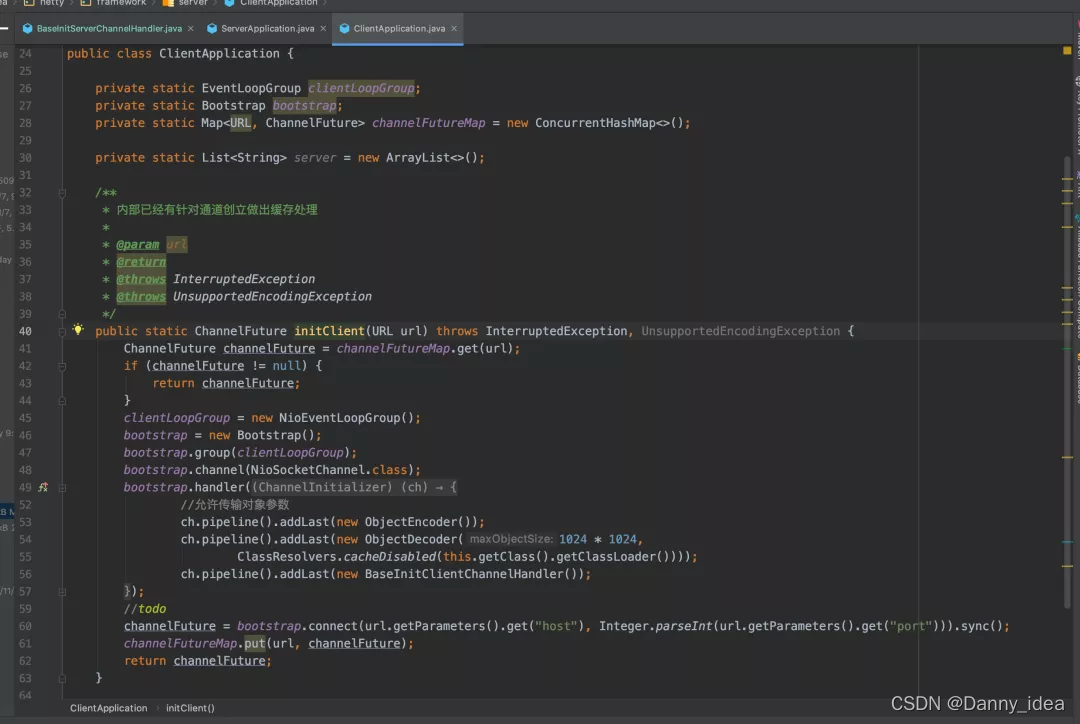
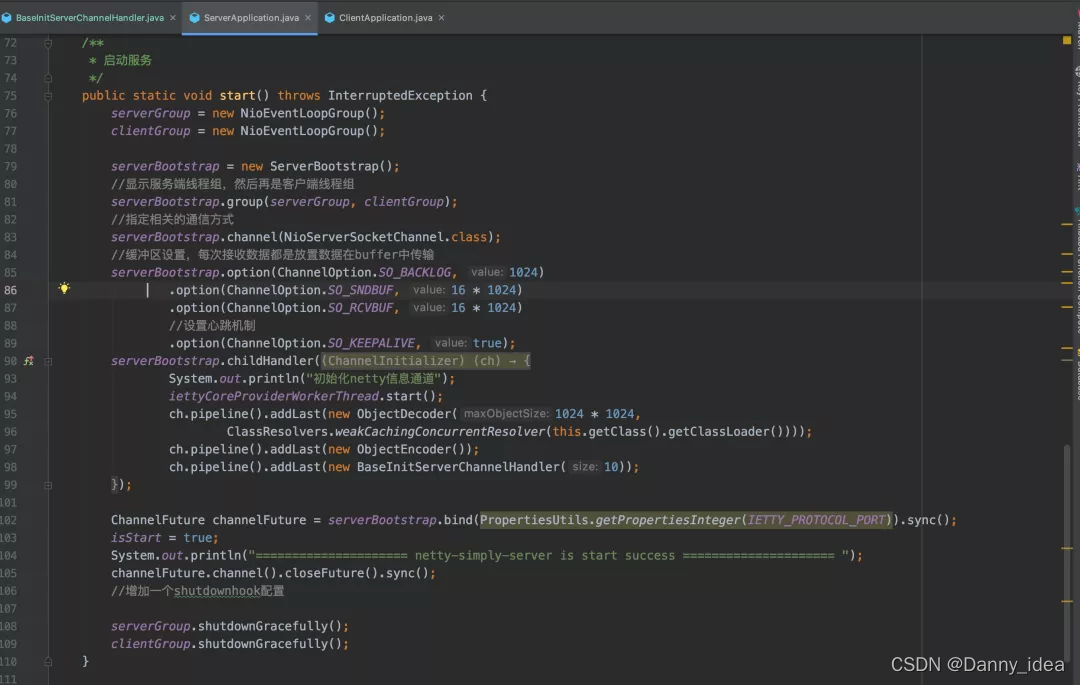
整套RPC框架的底层部分是采用了Netty组件进行实现的,主要的写法其实和通用的netty编程没有太大的差别,这里我简单贴出下代码截图吧:
客户端:
服务端:
小结
可能整篇文章写下来,很多的技术细节点和实现方式因为篇幅问题不能很好的展示出来。但是整体设计的几个大难点以及难点的解决思路都基本贴出来了,希望能够对你有一定的启发。
整个基础中间件写下来之后感觉头发掉了不少,因为底层的细节点实在是太多了,不管是结构设计,数据并发问题,异步处理设计等诸多都需要考虑,所以感觉这是一件非常具有综合挑战性的事情。

