
热门标签
热门文章
- 1给你一个项目,你会如何开展性能测试工作_项目管理系统如何进行性能测试
- 2springboot将数据库中数据以excel的形式传到前端_web中如何操作excel文件并返回给前端
- 3双非本科Java无实习进大厂的经验分享_无实习java
- 4python的优缺点_python的优点与缺点
- 5Python基础实验操作(一)_python输入自然数
- 6Android各版本对应的SDK版本_安卓kt sdk版本
- 7Baidu Comate实践指南:你的智能代码助理_comate代码助手怎么使用
- 8【计算机网络】TCP原理 | 可靠性机制分析(三)_分析窗口大小和tcp选项
- 9react native 截图并保存到相册
- 10MongoDB多文档事务详解_mongodb 事务
当前位置: article > 正文
伪分布式搭建Hadoop中消失的“DataNode”_配置hadoop伪分布 datanode没有
作者:从前慢现在也慢 | 2024-07-19 14:42:21
赞
踩
配置hadoop伪分布 datanode没有
我们在搭建hadoop中都会出现一些小小的问题,在伪分布式安装完Hadoop后,jps查看进程的时候缺三少两,今天解决的问题是6个进程中缺少了DataNode。
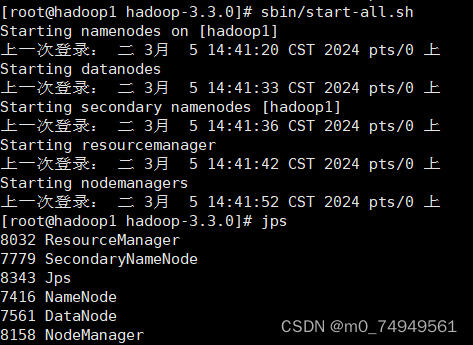
开启进程后,jps查询:
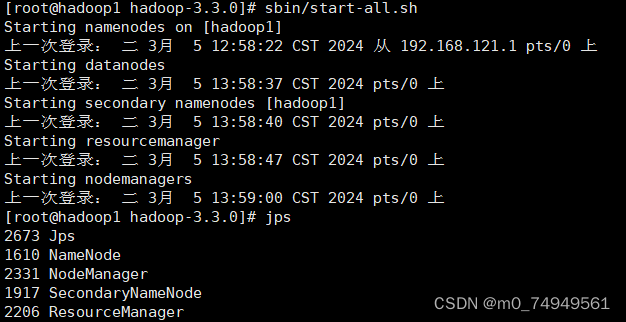
缺少DataNode的原因通常是:
这个一般是因为namenode进行了多次的格式化bin/hdfs namenode -format,导致namenode的clusterID和datanode的clusterID不同。然而dfs/data中保存的current/VERSION文件中的clustreID的值是上一次格式化保存的clusterID 。这样,datanode和namenode之间的ID不一致。所以datanode进程“消失了”。
解决方法:
- 先关闭进程 sbin/stop-all.sh
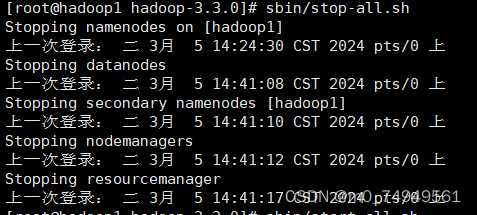
- 在hadoop安装目录下打开本地文件local
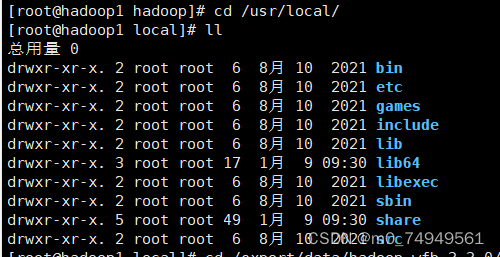
- 在hadoop目录下查看vi core-site.xml配置文件记住/export/data/Hadoop-wfb-3.3.0这条路径(datanode和namenode的官方默认位置)
![]()
![]()
- 将/export/data/Hadoop-wfb-3.3.0在local目录下打开并查看,是否有dfs,并打开dfs.

- 打开dfs目录并在其目录查询name和data目录。
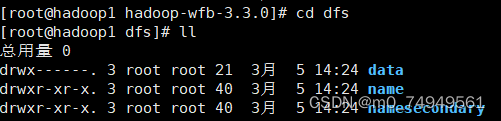
注意:不管先打开目录data还是name都可以,要确保data/current/VERSION中的clusterID与name/current/VERSION中的clusterID相等即可。
(在这里我以先打开name目录开始演示)
- 接上命令操作,在dfs目录下首先打开name,然后在name目录中打开current目录。我们会在current中看见VERSION。(以下是我的操作)

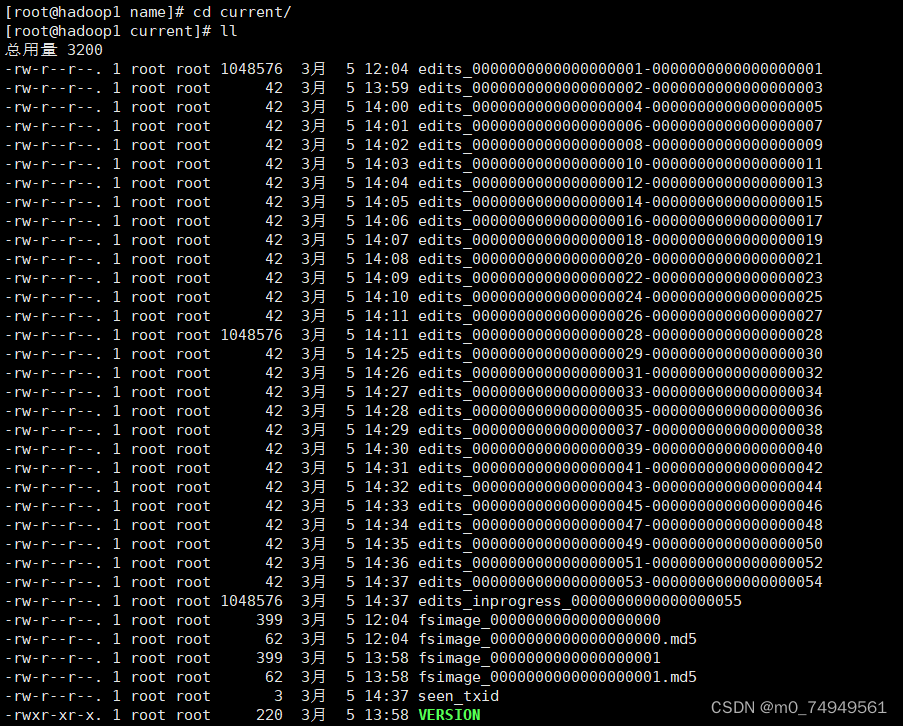
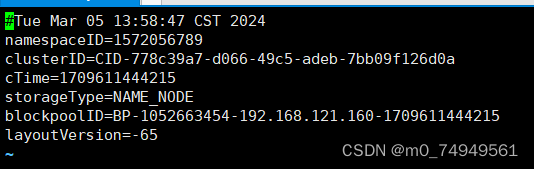
- 输入命令vi VERSION打开VERSION文件,复制VERSION文件中的clusterID。
![]()
- 复制完成之后点击esc,shift+:wq退出该文件,再次回到dfs目录。并在dfs目录下打开data,然后在data目录中打开current目录。在current中打开VERSION文件。
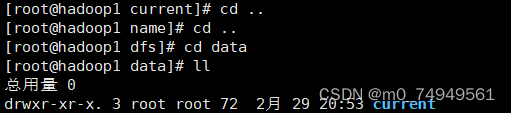

![]()
9.将从name中VERSION文件中复制的clusterID,粘贴到data中VERSION文件中clusterID。要确保data/current/VERSION中的clusterID与name/current/VERSION中clusterID的值相等。
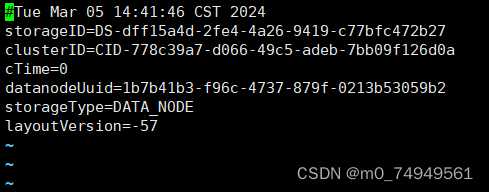
10. 粘贴完成之后点击esc,shift+:wq退出该文件。输入命令:cd /export/servers/wfb-hadoop/hadoop-3.3.0并切换到hadoop-3.3.0目录
![]()
11.输入sbin/start-all.sh开启进程查看jps,可以看到DataNode进程已经出现。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/从前慢现在也慢/article/detail/852027
推荐阅读
相关标签

