
- 1树的概念及结构|树的三种表示方法
- 2iPhone史上最全的使用教程
- 3怎么用AI大模型解决实际问题?(从我亲自实操的一个案例讲起)_用人工智能解决实际问题
- 4Unity常用API(感觉挺实用的)_unity install api level 34
- 5Telegram Bot、小程序开发(三)Mini Apps小程序_电报小程序开发
- 6深度报道 | 数字化合同 全生命周期管理爆发 专注、专业赢得用户和市场
- 7linux C语言remove函数及相关函数
- 8【Android 音视频开发打怪升级:FFmpeg音视频编解码篇】一、FFmpeg so库编译(1)_音视频编解码库
- 9李宏毅机器学习笔记(一)_李宏毅机器学习笔记 rl
- 10LeetCode力扣 基础编程0到1 共50详细题解 这篇就够了(持续更新中)_力扣基础编程0到1 答案_leetcode 答案
腾讯开源VITA!全方位对标GPT4o,全能多模态交互大模型!
赞
踩
腾讯优图实验室联合南京大学、厦门大学和中国科学院自动化研究所推出了VITA,一个开源的多模态大型语言模型。该模型擅长同时处理和分析视频、图像、文本和音频模态,并通过非唤醒交互和音频中断交互实现先进的多模态交互体验。
作者表示:所有训练代码、部署代码和模型权重即将发布!已经提交了开源代码,但还在进行内部审查。
VITA
3个月前,OpenAI发布最新的大模型GPT4-o,支持听、看、说,全程丝滑的想在和真人互动。
VITA 全方位的对标GPT4-o,具体内容如下所示:
1、实时和大模型语言交互(例如询问,当前视频内容中主体所处的环境;询问传递建议等)
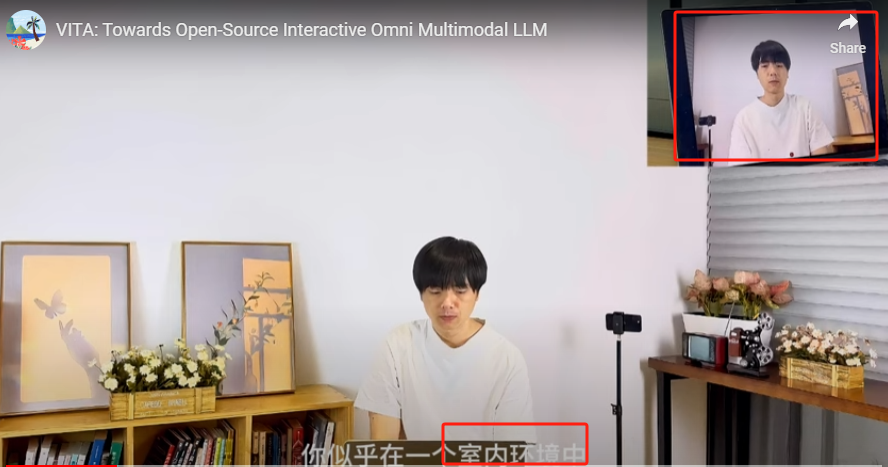
2、实时视频交互,给大模型展示一道数学题,让大模型帮忙解答(同时demo中也展示了sony的耳机以及一本书等,让大模型回答,都争取回复)

3、实时让让AI变换语音回复的音色

更多其他多模态能力测试效果:
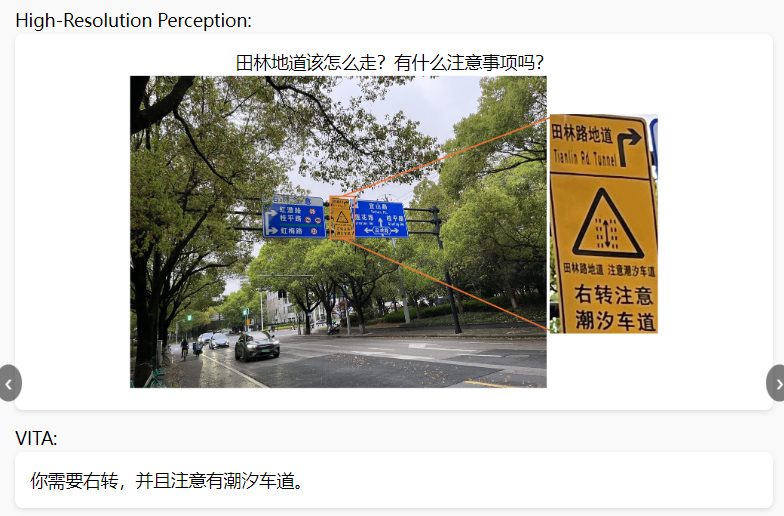
1)高分辨感知,根据图片中的一小块中的路标提示,理解具体的含义并做出相应的判断
2)密集OCR识别,理解商品上包装细小的文字,并给出合理的建议

3)数学问题解答

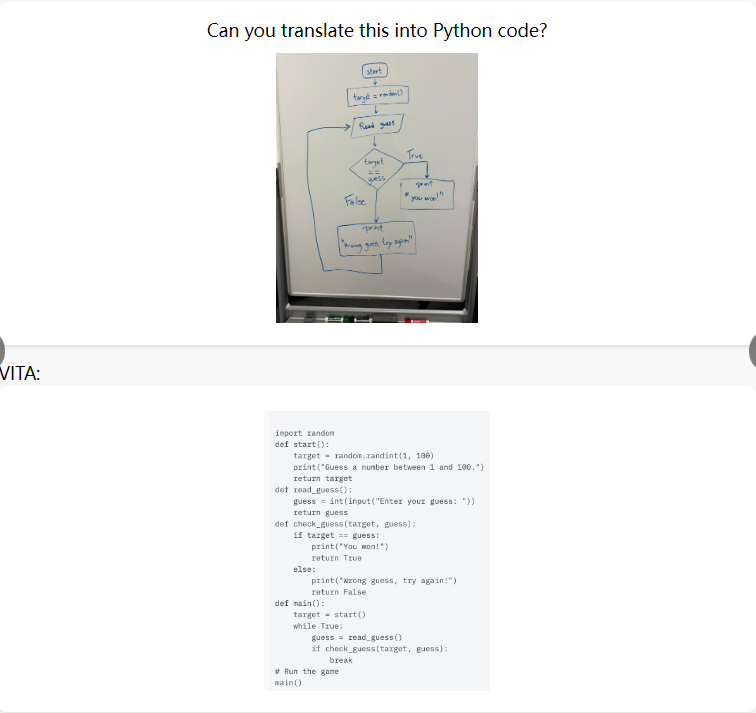
4)代码能力,根据流程图,编写代码
5)推理能力

6)基于计算的推理

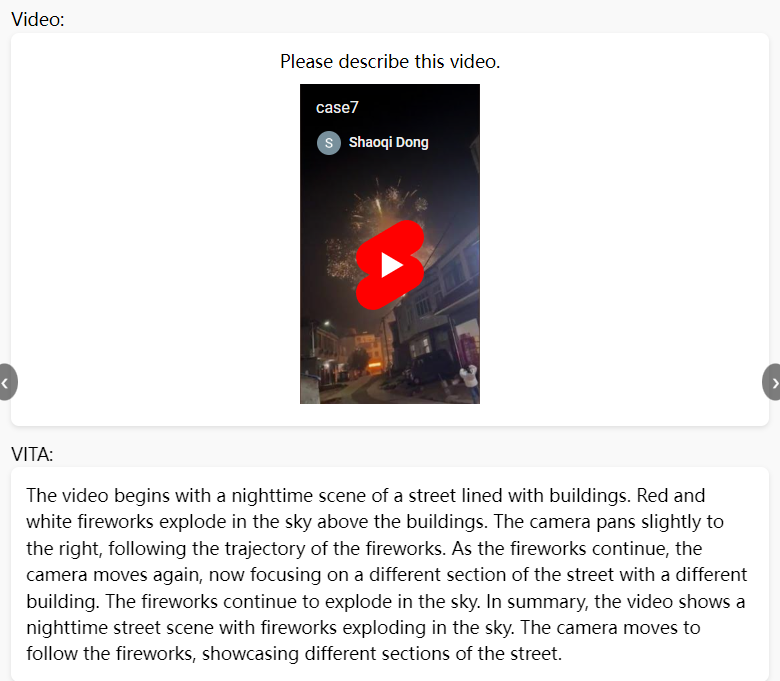
7)视频描述和理解能力
论文和项目地址:
https://vita-home.github.io/
https://arxiv.org/pdf/2408.05211
https://github.com/VITA-MLLM/VITA
以上就是今天分享的最新成果,如果对大家有帮助,希望能帮忙点赞转发一波,感谢各位小伙伴!!!
推荐
微信交流群现已有2000+从业人员交流群,欢迎进群交流学习(nvshenj125)
请备注:方向+姓名+学校/公司名称!一定要根据格式申请,拉你进群。

B站最新成果demo分享地址:https://space.bilibili.com/288489574
顶会工作整理Github repo:https://github.com/DWCTOD/CVPR2023-Papers-with-Code-Demo

