
- 1c++函数指针相关知识点详细总结!!!_函数指针考点
- 2【openlayers结合echarts图表和地图】VUE2 demo直接运行
- 3OWASP API 安全风险,有哪些安全措施_owasp a10-未受有效保护的api 修复建议
- 4nodejs 开发api 环境的简单搭建_npm 开发环境api接口
- 5【Django 网页Web开发】22. 实战项目:简单的文件上传(15)(保姆级图文)_django web 项目
- 6Window下安装Neo4j_window下的安装neo4j
- 7邓凡平WIFI学习笔记3: WiFi 协议安全部分
- 8Docker 容器连接:构建安全高效的容器化网络生态_容器主从连接方式适合什么场景中
- 9Xilinx-7系列SelectIO资源_iobufds
- 10(已解决)Windows使用transmac制作macos启动U盘重启按option不能识别的问题_transmac做好的u盘无法启动
HBase基础【HBase简介、HBase安装、HBase shell操作】
赞
踩
一 HBase简介
1 HBase定义
HBase是一种分布式、可扩展、支持海量数据存储的NoSQL数据库。
Apache HBase 是 Hadoop 数据库,一种分布式、可扩展的大数据存储。
当需要对大数据进行随机、实时的读/写访问时,请使用 Apache HBase。 该项目的目标是在商用硬件集群上托管非常大的表——数十亿行 * 数百万列。 Apache HBase 是一个开源、分布式、版本化、非关系型数据库,模仿 Google 的 Bigtable:Chang 等人的结构化数据的分布式存储系统。 正如 Bigtable 利用 Google 文件系统提供的分布式数据存储一样,Apache HBase 在 Hadoop 和 HDFS 之上提供了类似 Bigtable 的功能。
NoSQL:Not Only SQL,是一种对关系型数据库的扩展。无事务,无ACID。基于内存存储,读取速度快。十分容易扩展。
百度百科解释:https://baike.baidu.com/item/NoSQL/8828247?fr=aladdin
2 HBase数据模型
逻辑上,HBase的数据模型同关系型数据库很类似,数据存储在一张表中,有行有列。但从HBase的底层物理存储结构(K-V)来看,HBase更像是一个multi-dimensional map。
(1) HBase逻辑结构
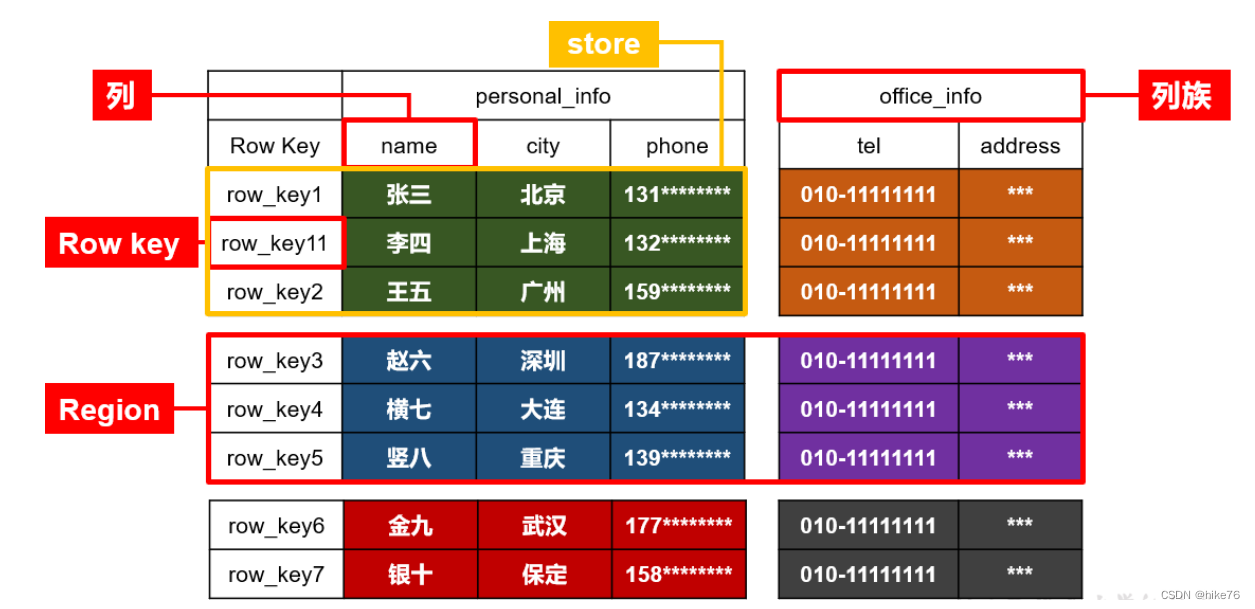
其中Row key根据字典序实现自动排序。
按照Region分别进行维护,按照列族进行切分store,底层以store为单位进行存储,一个region的数据存储在一个机器中,一个store存储为一个文件。
(2) HBase物理存储结构
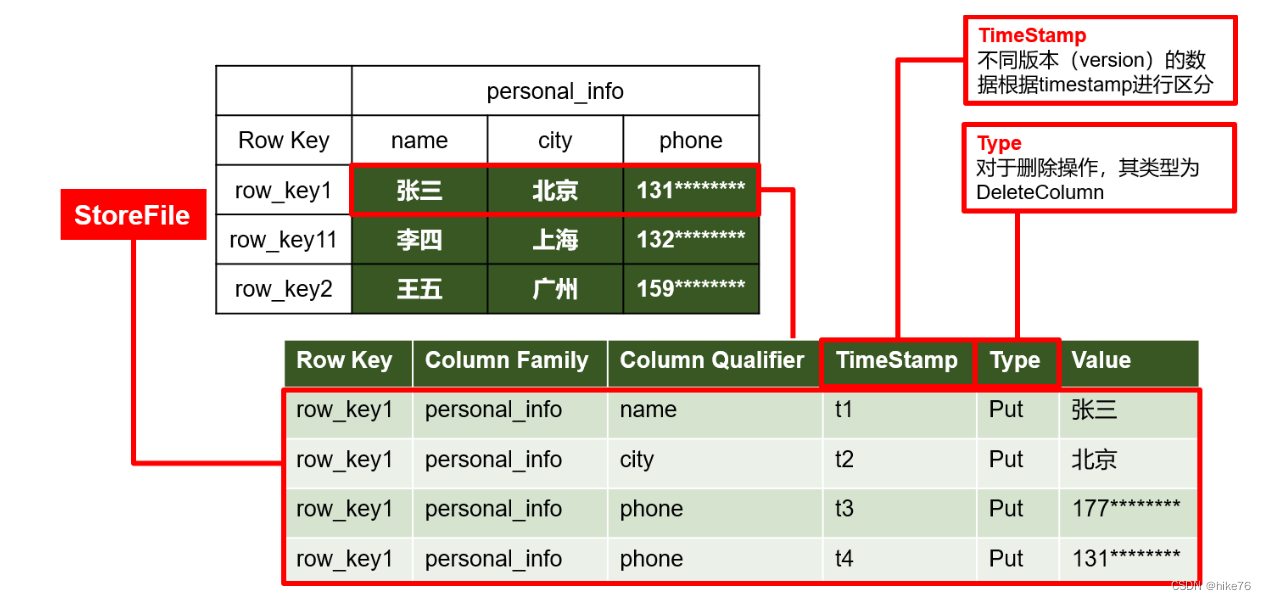
Hbase支持随机实时的读取操作,但HDFS都不支持随机的读写操作,Hbase又是基于HDFS进行开发的,所以Hbase实现的是伪随机实时读取。如手机号177和131,其更新不会在原数据上进行修改,而是实施末尾追加操作,在显示的结果中,选择时间戳大的数据进行显示,同样在删除时也不会立即真的删除原数据,而是选择一个合适的时间进行统一删除【先假后真】。
(3)数据模型
a)Name Space
命名空间,类似于关系型数据库的database概念,每个命名空间下有多个表。HBase有两个自带的命名空间,分别是hbase和default,hbase中存放的是HBase内置的表,default表是用户默认使用的命名空间。
通过hbase维护一些自己的元数据。
b)Table
类似于关系型数据库的表概念。不同的是,HBase定义表时只需要声明列族即可,不需要声明具体的列。这意味着,往HBase写入数据时,字段可以动态、按需指定。因此,和关系型数据库相比,HBase能够轻松应对字段变更的场景。
c)Row
HBase表中的每行数据都由一个RowKey和多个Column(列)组成,数据是按照RowKey的字典顺序存储的,并且查询数据时只能根据RowKey进行检索,所以RowKey的设计十分重要。
实际上也可以通过其他字段进行检索,比如查找姓名为张三的数据信息,但这样检索hbase会进行全表查询,效率太低,所以一般认为只可以通过RowKey进行检索。
d)Column
HBase中的每个列都由Column Family(列族)和Column Qualifier(列限定符)进行限定,例如info:name,info:age。建表时,只需指明列族,而列限定符无需预先定义。
e)Time Stamp
用于标识数据的不同版本(version),每条数据写入时,系统会自动为其加上该字段,其值为写入HBase的时间。
f)Cell
由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元。cell中的数据全部是字节码形式存贮。
3 HBase基本架构
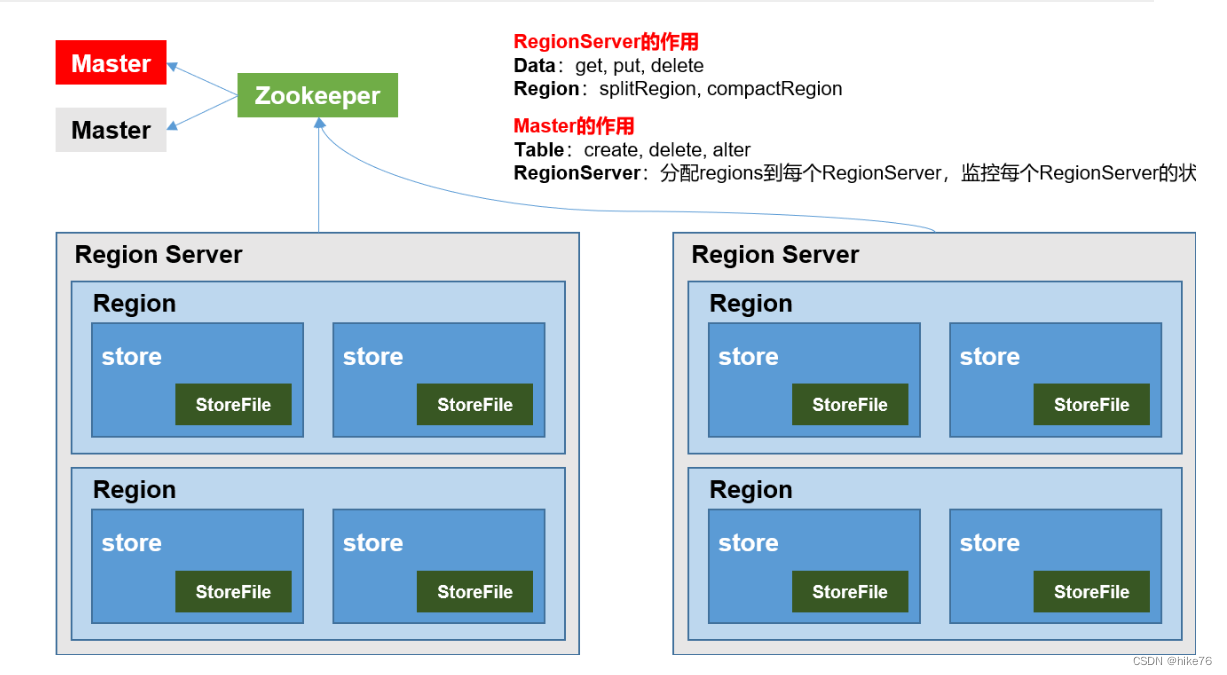
结构角色:
-
Region Server(DML)
Region Server为 Region的管理者,其实现类为HRegionServer,主要作用如下:
对于数据的操作:get, put, delete;
对于Region的操作:splitRegion、compactRegion。
-
Master(DDL)
Master是所有Region Server的管理者,其实现类为HMaster,主要作用如下:
对于表的操作:create, delete, alter
对于RegionServer的操作:分配regions到每个RegionServer,监控每个RegionServer的状态,负载均衡和故障转移。
-
Zookeeper
HBase通过Zookeeper来做master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。
-
HDFS
HDFS为Hbase提供最终的底层数据存储服务,同时为HBase提供高可用的支持。
二 HBase入门
1 hbase安装
#准备安装包,上传服务器,解压 tar -zxvf hbase-2.0.5-bin.tar.gz -C /opt/module/ #配置环境变量 sudo vim /etc/profile.d/my_env.sh #HBASE_HOME export HBASE_HOME=/opt/module/hbase-2.0.5 export PATH=$PATH:$HBASE_HOME/bin #修改配置文件 cd /opt/module/hbase-2.0.5/conf/ vim hbase-env.sh #修改以下内容 # Tell HBase whether it should manage it's own instance of ZooKeeper or not. export HBASE_MANAGES_ZK=false vim hbase-site.xml #添加以下内容 <property> <name>hbase.rootdir</name> <value>hdfs://hadoop101:8020/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>hadoop101,hadoop102,hadoop103</value> </property> vim regionservers #添加以下内容 hadoop101 hadoop102 hadoop103 #分发到其他机器 xsync hbase-2.0.5/ sudo ~/bin/xsync /etc/profile.d/my_env.sh #启动集群 start-hbase.sh

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
出现以下信息,集群启动成功
也可以在客户端进行访问http://hadoop101:16010/master-status
2 解决日志冲突
#解决日志冲突
#关闭集群
stop-hbase.sh
xcall rm -rf /opt/module/hbase-2.0.5/lib/slf4j-log4j12-1.7.25.jar
#查看是否删除成功
xcall ls /opt/module/hbase-2.0.5/lib/ | grep slf4j
- 1
- 2
- 3
- 4
- 5
- 6
3 高可用配置
#实现Hbase的高可用
#在HBase中HMaster负责监控HRegionServer的生命周期,均衡RegionServer的负载,如果HMaster挂掉了,那么整个HBase集群将陷入不健康的状态,并且此时的工作状态并不会维持太久。所以HBase支持对HMaster的高可用配置。
cd /opt/module/hbase-2.0.5/conf/
vim backup-masters
#添加以下内容
hadoop102
hadoop103
#分发到其他机器
xsync backup-masters
#File naming hosts on which backup HMaster will run. $HBASE_HOME/conf/backup-masters by default.export HBASE_BACKUP_MASTERS=${HBASE_HOME}/conf/backup-masters
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
配置完成后可以再客户端查看到

4 机器启动时间戳问题
如果集群之间的节点时间不同步,会导致regionserver无法启动,抛出ClockOutOfSyncException异常。
1)参考hadoop集群中的时间同步服务
2)将属性hbase.master.maxclockskew设置更大的值
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
<description>Time difference of regionserver from master</description>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
5 HBase Shell 操作
(1)基本操作
#进入HBase客户端命令行
hbase shell
#查看帮助命令
help
- 1
- 2
- 3
- 4
(2)namespace操作
#查看当前Hbase中有哪些namespace
list_namespace
default(创建表时未指定命名空间的话默认在default下) hbase(系统使用的,用来存放系统相关的元数据信息等,勿随便操作)
#创建namespace
#查看帮助信息 help 'create_namespace'
create_namespace 'mydb'
create_namespace 'mydb1',{'createtime'=>'2022-06-14'}
#查看namespace的信息
describe_namespace 'mydb1'
#help 'alter_namespace' 可增加,可修改,可删除属性
alter_namespace 'mydb',{METHOD=>'set','createtime'=>'2022-06-14'}
alter_namespace 'mydb1',{METHOD=>'set','createtime'=>'2022-06-15','author'=>'hike'}
alter_namespace 'mydb1',{METHOD=>'unset',NAME=>'createtime'}
#删除namespace(namespace下有表存在删除不了)
drop_namespace 'mydb1'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
(3)表的ddl操作
#创建表 create 'mydb:test1',{NAME=>'f1'} ##在默认namespace下创建表 create 'test2',{NAME=>'f1'} ##若只有一个属性,可以简化 create 'test3','f1' create 'mydb:test3','f1' create 'mydb:test4','f1','f2' #查看表 list #查看所有namspace下自己创建的表 list_namespace_tables 'mydb' #修改表 alter 'mydb:test1',NAME=>'f1',VERSIONS=>'2' ##修改多个列族 alter 'mydb:test4',{NAME=>'f1',VERSIONS=>'5'},{NAME=>'f2',VERSIONS=>'6'} ##增加列族 alter 'mydb:test4',NAME=>'f3',VERSIONS=>'2' ##删除列族 alter 'mydb:test4','delete'=>'f1' #查看表的详细信息 escribe 'mydb:test1' desc 'mydb:test1' #删除表 disable 'mydb:test1' drop 'mydb:test1'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
(4)表的dml操作
#创建student表,列族为info create 'stu','info' #添加数据,row key为1001,列名为name,姓名为zhangsan put 'stu','1001','info:name','zhangsan' put 'stu','1001','info:sex','man' put 'stu','1001','info:address','beijin' put 'stu','1002','info:name','lisi' put 'stu','1002','info:sex','woman' put 'stu','1002','info:address','tianjin' put 'stu','10021','info:name','lisilisi' put 'stu','10021','info:sex','woman' put 'stu','10021','info:address','tianjin' put 'stu','10020','info:name','lisilisilisi' put 'stu','10020','info:sex','woman' put 'stu','10020','info:address','tianjin' put 'stu','1002$','info:name','lisilisilisi' put 'stu','1002$','info:sex','woman' put 'stu','1002$','info:address','tianjin' put 'stu','1003','info:name','wangwu' put 'stu','1003','info:sex','man' put 'stu','1003','info:address','shanghai' put 'stu','1003','info:age','26' #hbase只能通过row key查看数据 get 'stu','1001' get 'stu','1003','info:name' get 'stu','1003','info:name','info:age' #扫描数据 ##全表扫描 scan 'stu' scan 'stu',{STARTROW=>'1002'} ##左开右闭 scan 'stu',{STARTROW=>'1001',STOPROW=>'1003'} ##扫描1002(包含)之前的数据 scan 'stu',{STARTROW=>'1001',STOPROW=>'1002!'} ##扫描1002(不包含)之后的数据 scan 'stu',{STARTROW=>'1002!'} #修改数据(并不是真的修改了,在后面添加了一条数据,在合适的时机删除掉老版本的数据) put 'stu','1001','info:name','zhangsanxiugai' ##查看不同版本的数据 scan 'stu',{RAW=>true,VERSIONS=>5} #删除数据 ##删除最新版本的数据 delete 'stu','1001','info:name' #Delete ##删除某一版本数据 delete 'stu','1001','info:name',1655293434191 #Delete #删除某一条数据的所有版本 put 'stu','1002','info:name','lisixiugai' deleteall 'stu','1002','info:name' #DeleteColumn deleteall 'stu','1002$' #DeleteFamily #统计有几条数据 count 'stu' #清空表数据 truncate 'stu'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64

