
热门标签
热门文章
- 1人工智能的春天:改变已然发生
- 2Git常用命令_git -m
- 3Kafka集群部署 (KRaft模式集群)_kraft模式kafka部署
- 4day33 多任务----线程_有很多的场景中的事情是同时进行的,比如开车的时候 手和脚共同来驾驶汽车,再
- 5认识链表以及其常见操作Java代码实现_链表怎么输入输出
- 6计算机毕业设计hadoop++hive微博舆情预测 微博舆情分析 微博推荐系统 微博预警系统 微博数据分析可视化大屏 微博情感分析 微博爬虫 知识图谱_基于hadoop数据部署对微博内容的分析
- 7探索前沿智能: phi3-Chinese,小而美的AI助手
- 8streamlit和grado的使用_streamlit 发布日志
- 9vue2.x学习笔记_vue onmouseover
- 10软件测试的方法有哪些有什么的规范_软件测试工作规范
当前位置: article > 正文
python之json对象处理_python json对象操作
作者:代码探险家 | 2024-06-23 21:15:05
赞
踩
python json对象操作
一、json定义
1.1 概念
- JSON:JavaScript Object Notation 【JavaScript 对象表示法】
JSON 是一种轻量级的数据交换格式,完全独立于任何程序语言的文本格式。一般,后台应用程序将响应数据封装成JSON格式返回。
1.2 基本语法
- JSON的基本语法如下:JSON最常用的格式是对象的键值对:key只能是string, value可以是 object、array、string、number、true/false、null。
- 如下所示:
{
“sites”: [
{ “name”:“360” , “url”:“www.360.com” },
{ “name”:“google” , “url”:“www.google.com” },
{ “name”:“baidu” , “url”:“www.baidu.com” }
]
}
1)键通过双引号包裹,后面跟冒号“:”,然后跟该键的值;
2)值可以是字符串、数字、数组等数据类型;
3)对象与对象之间用逗号隔开;
4)“{}”用来保存对象;
5)“[]”用来保存数组;
1.3 json跟python中的字典的区别
1)json的key只能是字符串,dict的key可以是任何可hash的对象,例如:字符串、数字、元组等;
2)字典是一种数据结构,json是一种数据格式;字典有很多内置函数,有多种调用方法,而json是数据打包的一种格式,并不像字典具备操作性;
3)json的字符串强制用双引号,dict的字符串可以用单引号、双引号;
一般而言,我们会把json转化为python中的字典或者列表,再对其进行操作。
二、json与python之间的交互
2.1 Python处理json的模块:json
- Pythone3的标准库JSON模块,可以很方便的帮我们进行json数据的转换和处理,这里主要指序列化(json.dumps()、json.dump())和反序列化(json.loads()、json.load())。
- 序列化和反序列化:
将对象转换为可通过网络传输或可以存储到本地磁盘的数据格式(如:XML、JSON或特定格式的字节串)的过程称为序列化;反之,则称为反序列化。 - 常用的JSON模块方法:
1)json.dumps():将Python中的对象转换为JSON中的字符串对象;
2)json.dump():将python对象转换成JSON字符串输出到fp流中;
3)json.loads():将JSON中的字符串对象转换为Python中的对象;
4)json.load():读取包含json对象的文件。
带s的都是和字符串相关的,不带s的都是和文件相关的。

2.2 实例
2.2.1 把字典转换成json串
import json
dic = {'name': 'xiaoming', 'age': 29}
json_str = json.dumps(dic)#返回json字符串
print(json_str)
print(type(json_str))
#结果
{"name": "xiaoming", "age": 29}
<class 'str'>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.2.2 Python解码JSON对象
import json
json_str ='{"id":"09", "name": "Nitin", "department":"Finance"}'
# Convert string to Python dict
dic = json.loads(json_str)
print(dic)
print(type(dic))
#结果
{'id': '09', 'name': 'Nitin', 'department': 'Finance'}
<class 'dict'>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
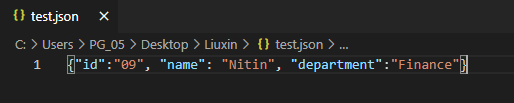
2.2.3 读取json文件
import json
with open('test.json') as f:
a = json.load(f)
print(a)
print(type(a))
#结果
{'id': '09', 'name': 'Nitin', 'department': 'Finance'}
<class 'dict'>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.2.4 写入json文件
import json
dic ={
"name" : "xiaoming",
"age" : 20,
"phonenumber" : "15555555555"
}
with open("test2.json", "w") as outfile:
json.dump(dic, outfile)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

2.3 转换对应关系
2.3.1 Python类型转换JSON类型的对应关系

2.3.2 json类型转换到Python的类型对照表

三、读取后的json解析为python的DataFrame
- pandas.json_normalize函数进行解析,将半结构化JSON数据规范化为平面表。

- 代码:
#读取json文件
import pandas as pd
import json
with open('results.json') as f:
results = json.load(f)
- 1
- 2
- 3
- 4
- 5

#读取相应的字段
FIELDS = ["key", "fields.summary", "fields.issuetype.name", "fields.status.name", "fields.status.statusCategory.name"]
df = pd.json_normalize(results["issues"])
df[FIELDS]
- 1
- 2
- 3
- 4

# 使用路径而不是直接用results["issues"]
pd.json_normalize(results, record_path="issues")[FIELDS]
- 1
- 2

# 自定义分隔符:用 "-" 替换默认的 "."
#使用sep参数自定义嵌套结构连接的分隔符
FIELDS = ["key", "fields-summary", "fields-issuetype-name", "fields-status-name", "fields-status-statusCategory-name"]
pd.json_normalize(results["issues"], sep = "-")[FIELDS]
- 1
- 2
- 3
- 4

#控制递归
#如果不想递归到每个子对象,可以使用max_level参数控制深度。在这种情况下,由于statusCategory.name字段位于JSON对象的第4级,因此不会包含在结果DataFrame中。
# 只深入到嵌套第二级
pd.json_normalize(results, record_path="issues", max_level = 2)
- 1
- 2
- 3
- 4

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/代码探险家/article/detail/750743
推荐阅读

相关标签

