
- 1dbGet、dbSchema、dbShape命令
- 2【目标解算】相机内外参数详细解读+坐标系转换_相机标定外参矩阵
- 3APOC函数之路径(path)用法_apoc用法
- 4还怕Github被墙?项目团队开发必备技能!
- 5移植FreeRTOS到STM32_freertos移植stm32
- 6【转】常见数字IC设计、FPGA工程师面试_fpga工程师和数字ic工程师
- 7Cracer渗透-windows基础(系统目录,服务,端口,注册表)
- 8力扣--深度优先算法419.甲板上的战舰
- 9Yalmip使用教程(6)-将约束条件写成矩阵形式_yalmip约束为矩阵怎么写
- 10React 18 系统精讲(六)类组件生命周期详解_react18组件销毁
【NLP】 聊聊NLP中的attention机制
赞
踩
本篇介绍在NLP中各项任务及模型中引入相当广泛的Attention机制。在Transformer中,最重要的特点也是Attention。首先详细介绍其由来,然后具体介绍了其编解码结构的引入和原理,最后总结了Attention机制的本质。
作者&编辑 | 小Dream哥
1 注意力机制的由来
在深度学习领域,注意力机制模仿的是人类认知的过程。当人看到如下“美女伤心流泪”图时,细细想一下,人在做出图片中美女是在伤心流泪的过程,应该是先整体扫描该图片;然后将视觉注意力集中到美女的脸部;集中到脸部之后,再进一步将视觉注意力集中到眼睛部位。最后发现了眼泪,得出美女是在伤心流泪的结论。

人类在对信息进行处理的过程中,注意力不是平均分散的,而是有重点的分布。受此启发,做计算机视觉的朋友,开始在视觉处理过程中加入注意力机制(Attention)。随后,做自然语言处理的朋友们,也开始引入这个机制。在NLP的很多任务中,加入注意力机制后,都取得了非常好的效果。
那么,在NLP中,Attention机制是什么呢?从直觉上来说,与人类的注意力分配过程类似,就是在信息处理过程中,对不同的内容分配不同的注意力权重。下面我们详细看看,在自然语言处理中,注意力机制是怎么实现的。
2 seq2seq结构及其中的Attention
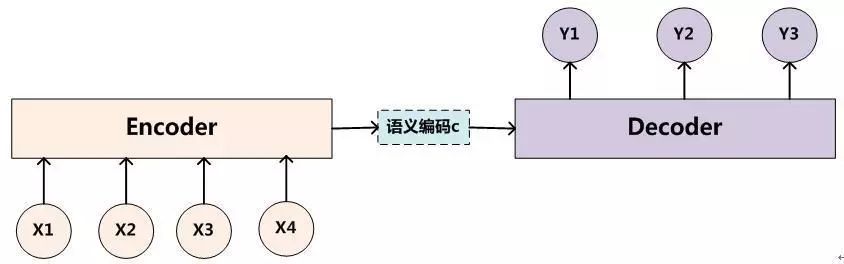
如上图所示,是标准的编解码(seq2seq)机制的结构图,在机器翻译、生成式聊天机器人、文本摘要等任务中均有应用。其处理流程是通过编码器对输入序列进行编码,生成一个中间的语义编码向量C,然后在解码器中,对语义编码向量C进行解码,得到想要的输出。例如,在中英文翻译的任务中,编码器的输入是中文序列,解码器的输出就是翻译出来的英文序列。
可以看出,这个结构很"干净",对于解码器来说,在解码出y1,y2,y3时,语义编码向量均是固定的。我们来分析下这样是否合理。
假设输入的是"小明/喜欢/小红",则翻译结果应该是"XiaoMing likes XiaoHong"。根据上述架构,在解码得到"XiaoMing","likes"," XiaoHong"时,引入的语义编码向量是相同的,也就是"小明","喜欢","小红"在翻译时对得到"XiaoMing","likes"," XiaoHong"的作用是相同的。这显然不合理,在解码得到"XiaoMing"时,"小明"的作用应该最大才对。
鉴于此,机智的NLP研究者们,认为应该在编解码器之间加入一种对齐机制,也就是在解码"XiaoMing"时应该对齐到"小明"。在《Neural Machine Translation By Jointly Learning To Align And Translate》中首次将这种对齐机制引入到机器翻译中。我们来看看,这是怎样的一种对齐机制。
我们先回顾一下刚才的编解码结构,其语义编码向量和解码器状态,通过如下的公式得到:
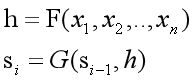
通常在解码时语义编码向量是固定的。若要实现对齐机制,在解码时语义编码向量应该随着输入动态的变化。鉴于此,《Neural Machine Translation By Jointly Learning To Align And Translate》提出来一种对齐机制,也就是Attention机制。
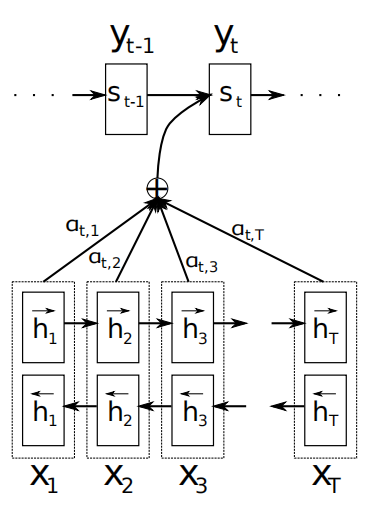
如上图示,论文中采用双向RNN来进行语义的编码,这不是重点,我们先不关注。其对齐机制整体思想是:编码时,记下来每一个时刻的RNN编码输出(h1,h2,h3,..hn);解码时,根据前一时刻的解码状态,即yi-1,计算出来一组权重(a1,a2,..an),这组权重决定了在当前的解码时刻,(h1,h2,h3,..hn)分别对解码的贡献。这样就实现了,编解码的对齐。
下面我们用数学语言描述一下上面的过程。
首先,进行编码计算(h1,h2,..hn),i时刻的编码状态计算公式如下:
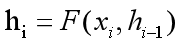
然后,开始解码,加入此时在解码的i时刻,则需要计算i时刻的编码向量Ci,通过如下的公式计算:
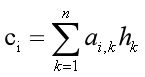
aij是对不同时刻的编码状态取的权重值。由此可见,i时刻的语义编码向量由不同时刻的编码状态加权求和得到。
下面看看,如何取得权重向量a:
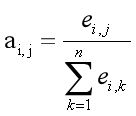
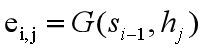
权重向量ai通过加入解码器前一个时刻的状态进行计算得到。eij表示,在计算Ci时,hj的绝对权重。通过对其使用softmax函数,得到aij。aij就是在计算Ci时,hj编码状态的权重值。
得到权重向量ai及语义编码向量Ci后,就可以计算当前时刻的解码状态了:
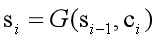
这就是编解码机制中注意力机制的基本内容了,本质上就是为了实现编解码之间的对齐,在解码时根据前一时刻的解码状态,获取不同时刻编码状态的权重值并加权求和,进而获得该时刻语义编码向量。
那么,抽离编解码机制,Attention机制的本质是什么呢?我们下面来看看。
3 Attention机制的本质
我们回想一下,引入Attention机制的本意,是为了在信息处理的时候,恰当的分配好”注意力“资源。那么,要分配好注意力资源,就需要给每个资源以不同的权重,Attention机制就是计算权重的过程。
如下图所示,
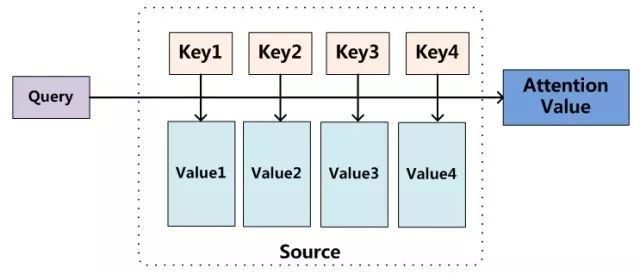
如上图所示,我们由资源Value,需要根据当前系统的其他状态Key和Querry来计算权重用以分配资源Value。
也就是,可以用如下的数学公式来描述Attention机制:
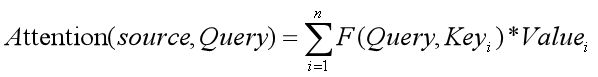
F函数可以有很多,在transformer中用的是点积。
总结
Transformer中最重要的特点就是引入了Attention,其对于Transformer性能的重要性我们下一篇介绍。总的来说,Adttention机制是一种对齐机制,它通过对系统当前的某些状态进行评估,来对系统资源进行权重分配,实现对齐,具体可以看机器翻译的例子。
下期预告:当前最强大的特征抽取器transformer
知识星球推荐
扫描上面的二维码,就可以加入我们的星球,助你成长为一名合格的自然语言处理算法工程师。
知识星球主要有以下内容:
(1) 聊天机器人。考虑到聊天机器人是一个非常复杂的NLP应用场景,几乎涵盖了所有的NLP任务及应用。所以小Dream哥计划以聊天机器人作为切入点,通过介绍聊天机器人的原理和实践,逐步系统的更新到大部分NLP的知识,会包括语义匹配,文本分类,意图识别,语义匹配命名实体识别、对话管理以及分词等。
(2) 知识图谱。知识图谱对于NLP各项任务效果好坏的重要性,就好比基础知识对于一个学生成绩好坏的重要性。他是NLP最重要的基础设施,目前各大公司都在着力打造知识图谱,作为一个NLP工程师,必须要熟悉和了解他。
(3) NLP预训练模型。基于海量数据,进行超大规模网络的无监督预训练。具体的任务再通过少量的样本进行Fine-Tune。这样模式是目前NLP领域最火热的模式,很有可能引领NLP进入一个全新发展高度。你怎么不深入的了解?
转载文章请后台联系
侵权必究

往期精选


