
- 1bmob Harmony快速开发手机号一键登录功能
- 2免费使用高性能的GPU和TPU—谷歌Colab使用教程_google colab能免费用多长时间
- 3huggingface加载预训练模型部分API笔记_huggingface 加载 torch模型
- 4ChatGPT在机器学习中的应用与实践_chatgpt机器学习
- 5听障人士的“有声桥梁”:百度智能云曦灵-AI手语平台发布
- 6【Linux】Wmware Esxi磁盘扩容_esxi扩容lvm
- 7七天入门大模型 :LLM和多模态模型高效推理实践_llm模型推理 实践
- 8SwiftUI 6.0(iOS/iPadOS 18)中全新的 Tab 以及 Sidebar+悬浮 TabView 样式_siwftui ios18
- 9steamlit安装_conda install streamlit
- 10SpringBoot+RabbitMQ实现手动Consumer Ack_springboot rabbitmq 发送给多个消费者
【共词聚类分析】基于CNKI和WOS的小样本稳健性检验_知网 聚类分析
赞
踩
很久之前的一篇文章,最近终于收到了Reviewers的回复(一把心酸…其中有一个Comments如下,意思是我们原先的文章没法证明共词聚类方法的结论是合理的…于是打算新增加一个稳健型检验(robust analysis),由于上次做这部分实在太久远了,这次用一个小样本将共词聚类分析的过程记录下来。
Comments to the Author
Overall, this manuscript needs major modifications and rethinking of the entire paper outline. Specific comments are as follows:
1- The time interval of the study is indicated as 32 years spanning from 1989 to 2021, but they presented only 2008 and 2019. How do they segregate the results? In other words, they do the tests for 32 years but talking only for the part between 2008-2019.
抓取数据来源:CNKI
首先在CNKI上使用高级检索功能,这里我的主题是气候变化,类型是期刊,出版时间是2008-2019,排序方式为相关性排序。这里只是robust analysis,需要的样本量很少,因为CNKI每次只能导出500条信息,如果需要大样本,后面我会更新使用爬虫来抓取的方法。
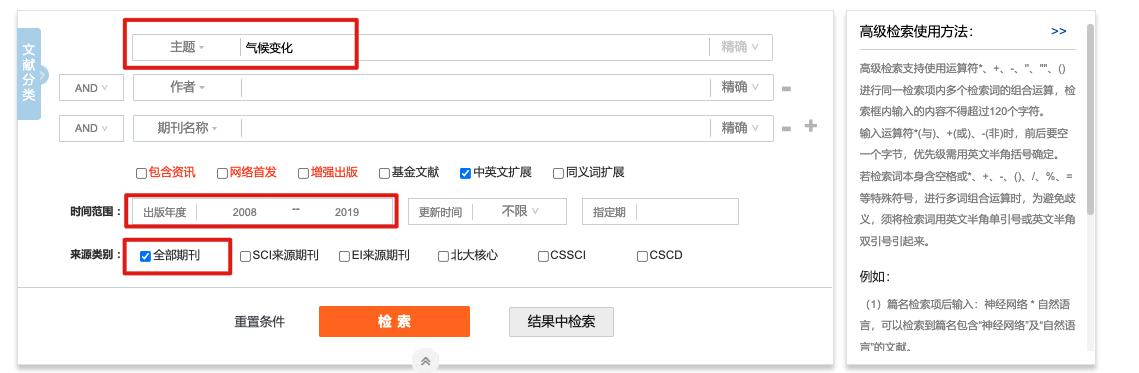
将检索结果每次500条导出下来,下载格式为Refworks格式,方面后面的分析。这里我一共抓取了3000条数据(500*6)
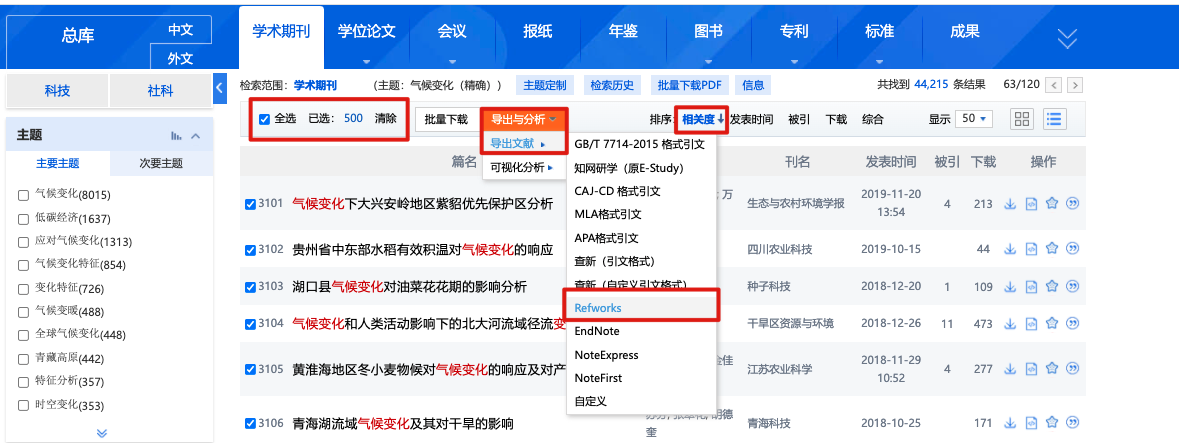
因为是使用文献关键词来进行共词聚类,我在这里使用了学术点滴开发的一款软件COOC直接将从知网导出来的txt进行合并以及将Refworks里面的关键词格式单独提取出来。

提取后的excel就是结构化的了,一共2996条文献信息。我们将其中的关键词列表拿出来分析就可以了。

抓取数据来源:Web of Science
抓取完中文的文献后,还需要抓取英文的文献,这里我们是通过WOS下载文献数据。通过高级检索,检索11本气候变化相关的头部期刊,要求其发表时间在2008-2019,其摘要中包“China”或者“Chinese”。
但是今年1月份后WOS改版后,居然没有可以导出关键词的选项…还好去年爬取的相关文献数据库还在,我这次直接在之前的数据中提取2008-2019的所有相关文献。之后有空看看怎么用爬虫抓取一下。
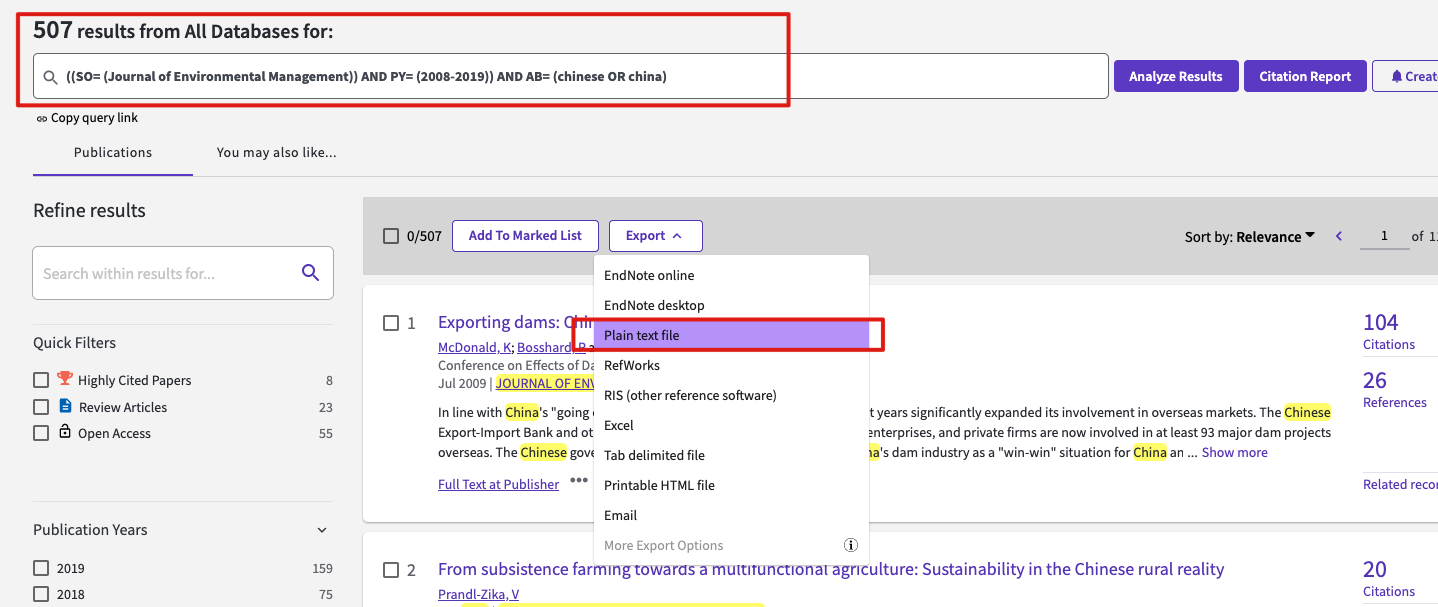
符合条件的一共有2774条文献信息。仍然是将其中的附加关键词提取出来。WOS有作者关键词和附加关键词,我们主要使用作者关键词,如果没有作者关键词的话,我们就用附加关键词来替代,用excel处理一下。
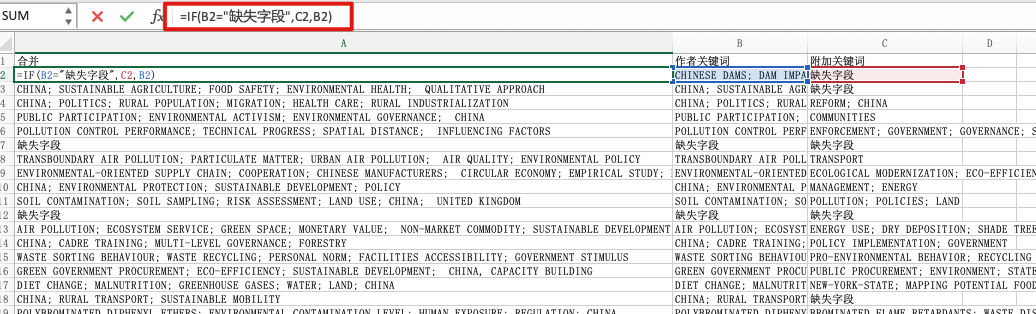
接着翻译成中文。这里的翻译是基于之前的工作,直接用之前的翻译表匹配得到的。
合并关键词
下一步需要将CNKI和WOS提取的关键词进行合并统计。
因为样本量很小,直接使用Excel,共获取文献共5451条(CNKI:2996,WOS:2774)。处理过程如下:(注意:因为导出的是一条文献一个单元格的格式,不能直接搜索替换,所以需要通过”;”将关键词切开,通过单元格匹配,剔除后再合并起来)
- 为了方面后面的处理,将《》、“”等符号去掉
- 这里的研究主题是中国的气候变化,需要将“中国”、“气候变化”这两个词剔除(频次很高)。
- 将同义词进行合并。比如
(1)年代际变化:年代际变化、年际变化
(2)厄尔尼诺-南方涛动:厄尔尼诺
(3)二氧化碳:CO2、二氧化碳排放量
(4)农业:农业、农业生产
(5)夏季风:亚洲夏季风、夏季风 - 回归原文,人工将无关词汇剔除,比如美国、北太平洋西部、第一部分、气候变化问题、亚洲、分配、太平洋、感知、遥相关、来源等词
这一步会花费比较多的时间,一个是因为处理的过程需要不断调试,涉及到很多的excel表格,要很细心,不然很容易出错;另一个是因为要回归原文,找到各个关键词的含义,好进行同义词合并和无关词汇剔除。

通过对关键词进行统计分析,共获得不重复关键词11741个,累计频次23444次。
由于共词分析的数据源于高频词出现的次数,因而高频词阈值的选取将直接影响分析结果。现阶段,学术界进行共词分析主要通过自主确定法、高低频词分界公式法、普赖斯公式法和基于词频g指数法来确定高频词阈值。尽管当下共词分析法已普遍运用于各类学科,但目前尚未有学者针对气候变化分类领域进行专门研究。因此,我们需要探究用何种方法能科学合理地选取气候变化领域高频词阈值。
基于之前的工作(如下表),我们得出针对这里的气候变化主题使用g-index方法的共词聚类效果是最好的。

这里我们使用g-index选取的阈值是24,一共57个高频关键词进行接下来的分析。
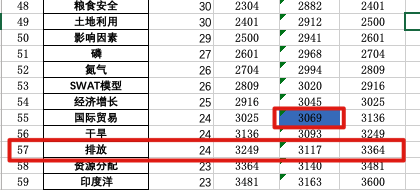
最终的关键词表格如下:
| 序号 | 关键词 | 频次 | g^2 | 累计频次 | (g+1)^2 |
|---|---|---|---|---|---|
| 1 | 影响 | 192 | 1 | 192 | 4 |
| 2 | 重金属 | 134 | 4 | 326 | 9 |
| 3 | 年代际变化 | 125 | 9 | 451 | 16 |
| 4 | 厄尔尼诺-南方涛动 | 121 | 16 | 572 | 25 |
| 5 | 降水量 | 110 | 25 | 682 | 36 |
| 6 | 气候 | 105 | 36 | 787 | 49 |
| 7 | 农业 | 100 | 49 | 887 | 64 |
| 8 | 易变性 | 89 | 64 | 976 | 81 |
| 9 | 适应 | 82 | 81 | 1058 | 100 |
| 10 | 二氧化碳 | 78 | 100 | 1136 | 121 |
| 11 | 风险评估 | 78 | 121 | 1214 | 144 |
| 12 | 人类活动 | 73 | 144 | 1287 | 169 |
| 13 | 温度 | 71 | 169 | 1358 | 196 |
| 14 | 沉积物 | 69 | 196 | 1427 | 225 |
| 15 | 青藏高原 | 68 | 225 | 1495 | 256 |
| 16 | 季风 | 65 | 256 | 1560 | 289 |
| 17 | 循环 | 65 | 289 | 1625 | 324 |
| 18 | 多环芳烃 | 62 | 324 | 1687 | 361 |
| 19 | 降雨量 | 59 | 361 | 1746 | 400 |
| 20 | 空气污染 | 59 | 400 | 1805 | 441 |
| 21 | 夏季风 | 58 | 441 | 1863 | 484 |
| 22 | 全球气候变化 | 52 | 484 | 1915 | 529 |
| 23 | 趋势 | 51 | 529 | 1966 | 576 |
| 24 | 气温 | 48 | 576 | 2014 | 625 |
| 25 | 土壤 | 46 | 625 | 2060 | 676 |
| 26 | 降水 | 44 | 676 | 2104 | 729 |
| 27 | 脆弱性 | 44 | 729 | 2148 | 784 |
| 28 | 巴黎协定 | 43 | 784 | 2191 | 841 |
| 29 | 水质 | 42 | 841 | 2233 | 900 |
| 30 | 应对气候变化 | 40 | 900 | 2273 | 961 |
| 31 | 城市化 | 40 | 961 | 2313 | 1024 |
| 32 | 可持续发展 | 39 | 1024 | 2352 | 1089 |
| 33 | 模型 | 37 | 1089 | 2389 | 1156 |
| 34 | 水资源 | 36 | 1156 | 2425 | 1225 |
| 35 | PM2.5 | 36 | 1225 | 2461 | 1296 |
| 36 | 径流 | 35 | 1296 | 2496 | 1369 |
| 37 | 水资源 | 34 | 1369 | 2530 | 1444 |
| 38 | 不确定性 | 34 | 1444 | 2564 | 1521 |
| 39 | 健康风险 | 34 | 1521 | 2598 | 1600 |
| 40 | 空间分布 | 33 | 1600 | 2631 | 1681 |
| 41 | 联合国 | 33 | 1681 | 2664 | 1764 |
| 42 | 全球变暖 | 33 | 1764 | 2697 | 1849 |
| 43 | 温室气体 | 32 | 1849 | 2729 | 1936 |
| 44 | 海面温度 | 31 | 1936 | 2760 | 2025 |
| 45 | 大气环流 | 31 | 2025 | 2791 | 2116 |
| 46 | 风险 | 31 | 2116 | 2822 | 2209 |
| 47 | 气候变异性 | 30 | 2209 | 2852 | 2304 |
| 48 | 粮食安全 | 30 | 2304 | 2882 | 2401 |
| 49 | 土地利用 | 30 | 2401 | 2912 | 2500 |
| 50 | 影响因素 | 29 | 2500 | 2941 | 2601 |
| 51 | 磷 | 27 | 2601 | 2968 | 2704 |
| 52 | 氮气 | 26 | 2704 | 2994 | 2809 |
| 53 | SWAT模型 | 26 | 2809 | 3020 | 2916 |
| 54 | 经济增长 | 25 | 2916 | 3045 | 3025 |
| 55 | 国际贸易 | 24 | 3025 | 3069 | 3136 |
| 56 | 干旱 | 24 | 3136 | 3093 | 3249 |
| 57 | 排放 | 24 | 3249 | 3117 | 3364 |
共词聚类分析
接着利用基于词频g指数法确定的57个高频关键词进行共词聚类分析。
首先使用COOC软件将选取的关键词转化为57*57的共现矩阵。
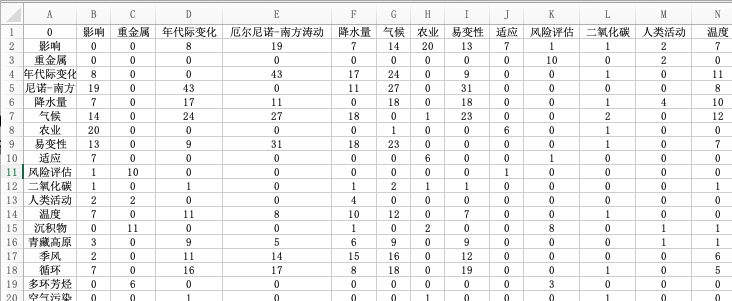
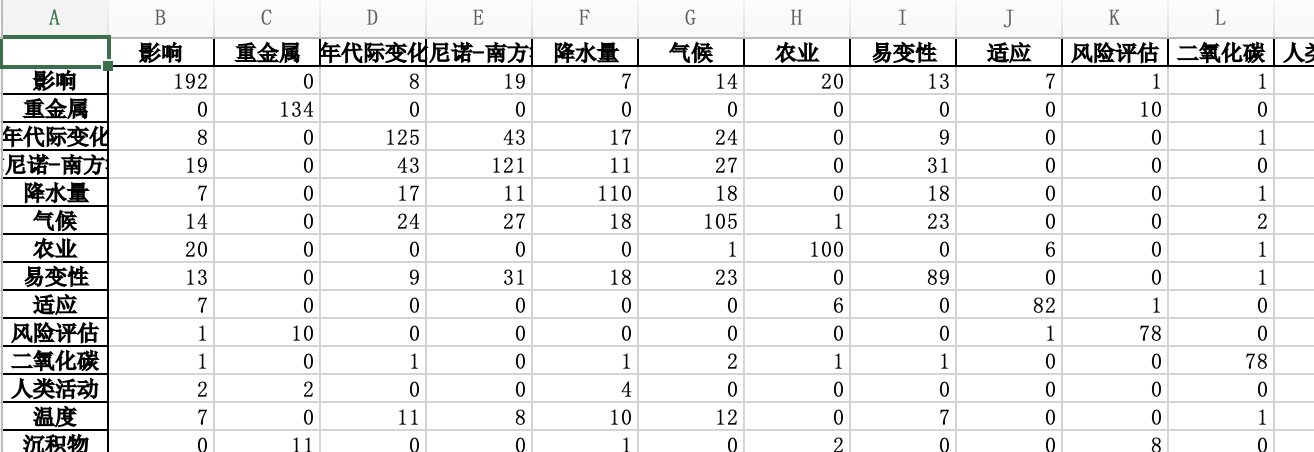
再转换为完全共现矩阵
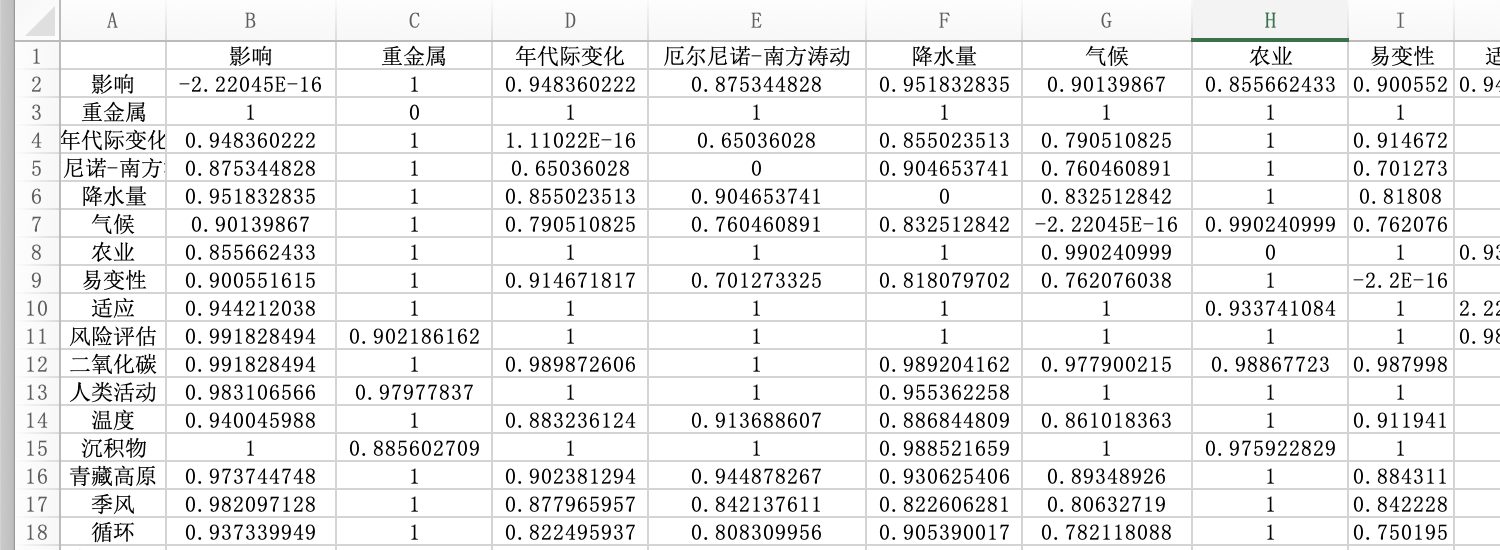
但由于两个关键词共现频次的多少只受两个关键词各自词频大小的影响,因此还需引入表示关键词共现相对强度的指标。在文献计量学中,目前应用较多的是Ochiia系数和JacGard指数。本研究用Ochiia系数将共词矩阵转化为相关矩阵,再用“1”与全部相关矩阵上的数据相减,得到表示两词间相异程度的相异矩阵,相异矩阵中的数据数值越大,表明关键词之间的距离越远,相似度越差。
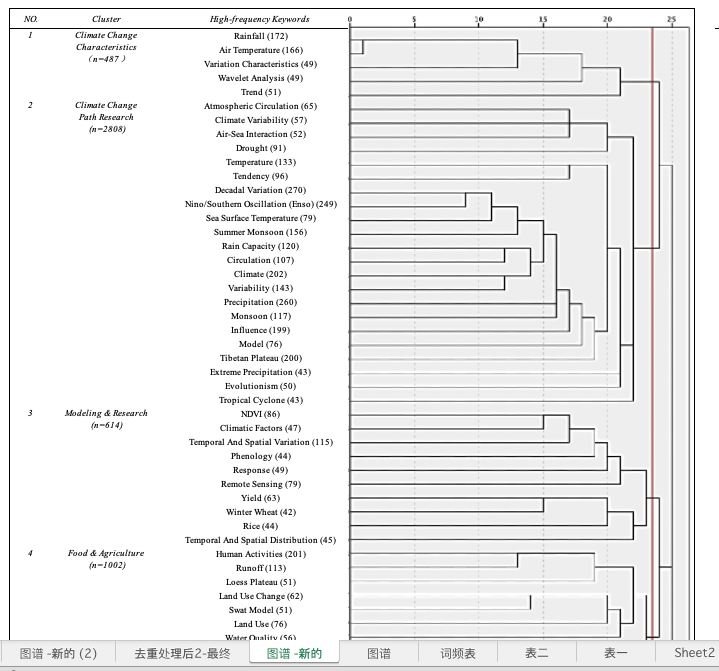
再利用SPSS进行聚类分析,聚类方法采用组间联接法,度量方式为平方欧氏距离,聚类分析谱系图如下图所示。(这里的聚类方法有组间联接、组内联接、欧式距离、弦距离等等,多次组合对比,看看哪种方法的聚类效果好)

下一步就是对得到的聚类结果进行归类命名以及解读了。
由于我这里只是为了做稳健性检验,得到的聚类结果其实跟之前基于大样本做的工作很重合了,所以也说了之前的结果是可信的。
本文到这里就结束了。
从本文论述来看过程好像很简单,但实际上在做的过程中是需要尝试很多遍的,需要很细心。本文描述的只是基于小样本做简单的共词聚类过程,工作量其实也不少了,但呈现在文章中可能只是几句话进行描述…科研不易啊!

