
- 1精读《高性能表格》
- 22018年春招总结(暑假实习生C++岗)_c++实习简历
- 3七大排序算法,冒泡排序 选择排序 插入排序 希尔排序 堆排序 快速排序 归并排序的深度讲解_比较说明冒泡算法,选择算法,希尔排序算法
- 4FPGA基于VerilogHDL的电子时钟----开发平台Quartus II_hdl时钟
- 5软件测试,为什么你投了简历却没有面试机会?_投了3天简历,没有面试
- 6开源AGV调度系统OpenTCS中的路由器(router)详解
- 7WireGuard 组网教程:快速构建安全高效的私密网络并实现内网穿透
- 8Keil5软件仿真 定时器互补通道 波形输出(Logic Analyzer)_keil配置软件定时器
- 9蓝易云 - 网络通讯技术:HTTP POST协议用于发送本地压缩数据到服务器的方案。
- 10微软官网下载win10系统_win10家庭版官网下载地址
49、Flink 的数据源的 SplitReader API 详解_flink splitreader
赞
踩
SplitReader API
a)概述
核心的 SourceReader API 是完全异步的,但实际上,大多数 Sources 都会使用阻塞的操作,例如客户端(如 KafkaConsumer)的 poll() 阻塞调用,或者分布式文件系统(HDFS, S3等)的阻塞I/O操作;为了使其与异步 Source API 兼容,这些阻塞(同步)操作需要在单独的线程中进行,并在之后将数据提交给 reader 的异步线程。
SplitReader 是基于同步读取/轮询的 Source 的高级(high-level)API,例如 file source 和 Kafka source 的实现等。
核心是上面提到的 SourceReaderBase 类,其使用 SplitReader 并创建提取器(fetcher)线程来运行 SplitReader,该实现支持不同的线程处理模型。
b)SplitReader
SplitReader API 只有以下三个方法:
- 阻塞式的提取
fetch()方法,返回值为 RecordsWithSplitIds。 - 非阻塞式处理分片变动
handleSplitsChanges()方法。 - 非阻塞式的唤醒
wakeUp()方法,用于唤醒阻塞中的提取操作。
SplitReader 仅需要关注从外部系统读取记录,因此比 SourceReader 简单得多。
c)SourceReaderBase
常见的 SourceReader 实现方式如下:
- 有一个线程池以阻塞的方式从外部系统提取分片。
- 解决内部提取线程与其他方法调用(如
pollNext(ReaderOutput))之间的同步。 - 维护每个分片的水印(watermark)以保证水印对齐。
- 维护每个分片的状态以进行 Checkpoint。
为了减少开发新的 SourceReader 所需的工作,Flink 提供了 SourceReaderBase 类作为 SourceReader 的基本实现。 SourceReaderBase 已经实现了上述需求,要重新编写新的 SourceReader,只需要让 SourceReader 继承 SourceReaderBase,而后完善一些方法并实现 SplitReader。
d)SplitFetcherManager
SourceReaderBase 支持几个开箱即用的线程模型,取决于 SplitFetcherManager 的行为模式; SplitFetcherManager 创建和维护一个分片提取器(SplitFetchers)池,同时每个分片提取器使用一个 SplitReader 进行提取,它还决定如何分配分片给分片提取器。
如下所示,一个 SplitFetcherManager 可能有固定数量的线程,每个线程对分配给 SourceReader 的一些分片进行抓取。
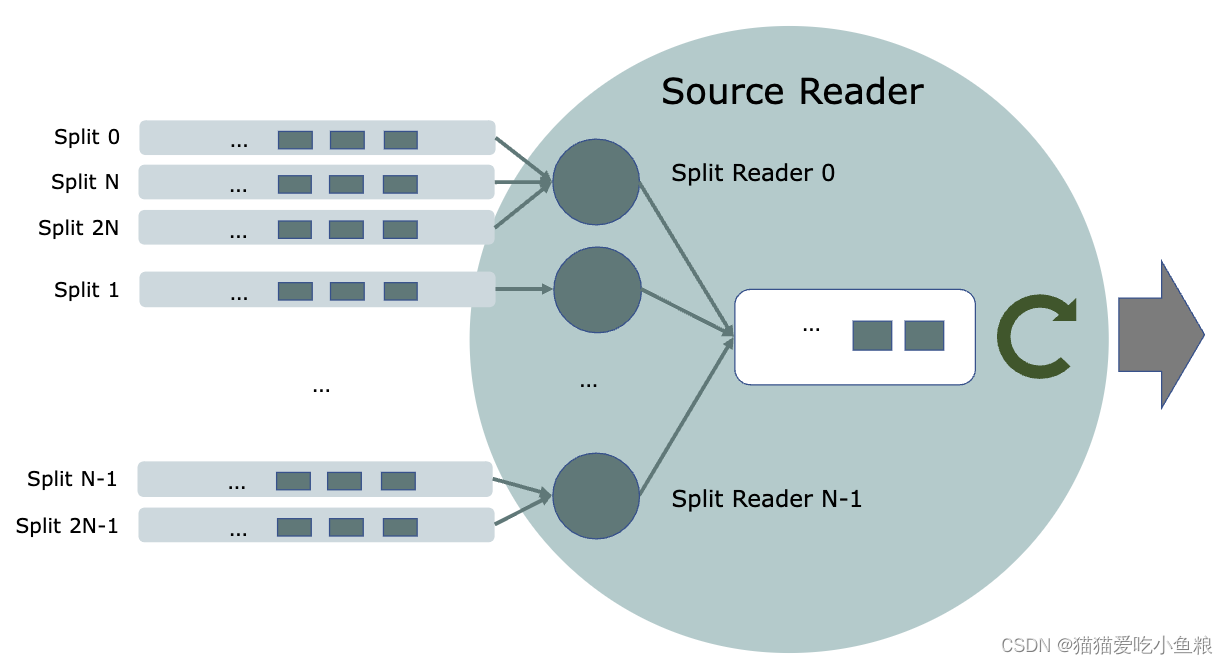
以下代码片段实现了此线程模型。
/**
* 一个SplitFetcherManager,它具有固定数量的分片提取器,
* 并根据分片ID的哈希值将分片分配给分片提取器。
*/
public class FixedSizeSplitFetcherManager<E, SplitT extends SourceSplit>
extends SplitFetcherManager<E, SplitT> {
private final int numFetchers;
public FixedSizeSplitFetcherManager(
int numFetchers,
FutureCompletingBlockingQueue<RecordsWithSplitIds<E>> elementsQueue,
Supplier<SplitReader<E, SplitT>> splitReaderSupplier) {
super(elementsQueue, splitReaderSupplier);
this.numFetchers = numFetchers;
// 创建 numFetchers 个分片提取器.
for (int i = 0; i < numFetchers; i++) {
startFetcher(createSplitFetcher());
}
}
@Override
public void addSplits(List<SplitT> splitsToAdd) {
// 根据它们所属的提取器将分片聚集在一起。
Map<Integer, List<SplitT>> splitsByFetcherIndex = new HashMap<>();
splitsToAdd.forEach(split -> {
int ownerFetcherIndex = split.hashCode() % numFetchers;
splitsByFetcherIndex
.computeIfAbsent(ownerFetcherIndex, s -> new ArrayList<>())
.add(split);
});
// 将分片分配给它们所属的提取器。
splitsByFetcherIndex.forEach((fetcherIndex, splitsForFetcher) -> {
fetchers.get(fetcherIndex).addSplits(splitsForFetcher);
});
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
使用这种线程模型的SourceReader可以像下面这样创建:
public class FixedFetcherSizeSourceReader<E, T, SplitT extends SourceSplit, SplitStateT>
extends SourceReaderBase<E, T, SplitT, SplitStateT> {
public FixedFetcherSizeSourceReader(
FutureCompletingBlockingQueue<RecordsWithSplitIds<E>> elementsQueue,
Supplier<SplitReader<E, SplitT>> splitFetcherSupplier,
RecordEmitter<E, T, SplitStateT> recordEmitter,
Configuration config,
SourceReaderContext context) {
super(
elementsQueue,
new FixedSizeSplitFetcherManager<>(
config.getInteger(SourceConfig.NUM_FETCHERS),
elementsQueue,
splitFetcherSupplier),
recordEmitter,
config,
context);
}
@Override
protected void onSplitFinished(Map<String, SplitStateT> finishedSplitIds) {
// 在回调过程中对完成的分片进行处理。
}
@Override
protected SplitStateT initializedState(SplitT split) {
...
}
@Override
protected SplitT toSplitType(String splitId, SplitStateT splitState) {
...
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
SourceReader 的实现还可以在 SplitFetcherManager 和 SourceReaderBase 的基础上编写自己的线程模型。

