
- 1python批量巡检服务器_python实现自动化之路(自动巡检服务器告警)
- 2基于知识图谱的行业问答系统搭建分几步?
- 3基于JAVA+SpringBoot+Mybatis+MYSQL的社区物业管理系统_数据库:mysql 5.7 开发工具:idea 项目管理工具:maven 3.6.0 web容器:t
- 4【测试】Charles抓包_charles抓手机包
- 5第十四届蓝桥杯省赛 C/C++ A 组 H 题——异或和之和(AC)_蓝桥杯异或和之和
- 6安装XShelll软件。(注意:此处使用的远程登录软件是XShell)上传JDK和Hadoop安装包到Linux服务器上。解压JDK、安装JDK、配置JDK环境变量、并验证。_xshell配置jdk环境
- 7Spring Boot项目分页功能后端实现_springboot分页封装
- 8FFmpeg开发笔记(二十三)使用OBS Studio开启RTMP直播推流_obs rtmp推流
- 9Hive学习总结之正则表达式详解_hive regexp用法
- 10按键精灵脚本学习-关于天猫抢红包_安卓按键精灵自动抢红包脚本
NLP作业02:课程设计报告_自然语言处理课设
赞
踩
作业头
| 这个作业属于哪个课程 | 自然语言处理 |
|---|---|
| 这个作业要求在哪里 | NLP作业02:课程设计报告 |
| 我在这个课程的目标 | 实现基于Seq2Seq注意力机制的聊天机器人 |
| 这个作业在哪个具体方面帮助我实现目标 | 合理安排计划,学习TensorFlow等深度学习框架来实现Seq2Seq模型 |
| 参考文献 | https://zhuanlan.zhihu.com/p/147310766 |
1.设计目的
通过课程设计的练习,加深学生对所学自然语言处理的理论知识与操作技能的
理解和掌握,使得学生能综合运用所学理论知识和操作技能进行实际工程项目的设计开发,让学生真正体会到自然语言处理算法在实际工程项目中的具体应用方法,为今后能够独立或协助工程师进行人工智能产品的开发设计工作奠定基础。通过综合应用项目的实施,培养学生团队协作沟通能力,培养学生运用现代工具分析和解决复杂工程问题的能力;引导学生深刻理解并自觉实践职业精神和职业规范;培养学生遵纪守法、爱岗敬业、诚实守信、开拓创新的职业品格和行为习惯。
2.设计要求
2.1 实验仪器及设备
(1) 使用 64 位 Windows 操作系统的电脑。
(2) 使用 3.8.0 版本的 Python。
(3) 使用 PyCharm Community Edition 编辑器。
(4) 使用 numpy,pandas,jieba,tensorflow,PyQt5……
2.2 设计要求
课程设计的主要环节包括课程设计作品和课程设计报告的撰写。课程设计作品
的完成主要包含方案设计、计算机编程实现、作品测试几个方面。课程设计报告主要是将课程设计的理论设计内容、实现的过程及测试结果进行全面的总结,把实践内容上升到理论高度。
3.设计内容
本项目主要使用 Python 的 Jieba 分词技术进行文本预处理工作,选用问答语料库
chat.txt 作为模型训练数据,使用神经网络与深度学习模型,基于 Seq2Seq 注意力机制实现聊天机器人,并使用 PyQt5 框架设计登录界面和聊天框,主要内容如下:
(1)长短时记忆网络(LSTM)
LSTM 是循环神经网络的改进形式,模型引入门控自循环,确保梯度能长期维
持传递,从而解决梯度消失的问题。因此 LSTM 模型能更好地提取学习序列长期依赖性特征,被广泛应用于时间序列预测问题中。
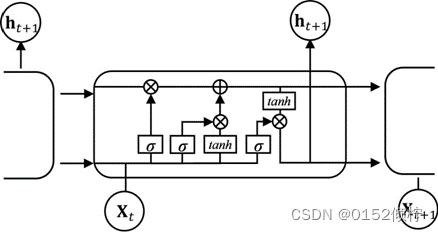
图 3- 1 长短时记忆网络
LSTM 遗忘门决定细胞单元从网络中接收信息量的大小,表明从状态 c(t-1)到状
态 c(t)保留信息多少,从而达到"遗忘"的功能。读取 x(t)和 h(t-1)的值,通过sigmoid函数计算出一个 0 和 1 值,表明细胞获取网络信息的百分比,计算方法如下:
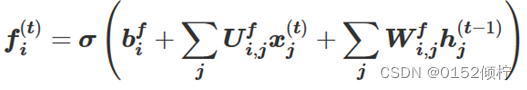
其中,o 代表 sigmoid 函数,U 和 W 代表权重矩阵的元素,b 为偏置系数。
LSTM 输入门决定了当前时刻网络的输入信息 x(t)保存到单元状态 c(t)的数量,
sigmoid 函数决定更新的值,tanh 函数创建新的候选值向量,这两个值对状态进行更新:
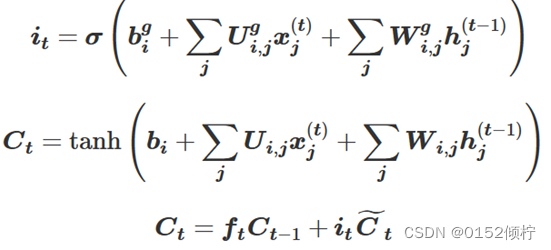
其中,b 是 LSTM 细胞单元中的偏置,U 是输入权重,W 是循环权重。
LSTM 输出门基于细胞状态决定输出的值,使用 sigmoid 函数来确定细胞状态
输出的部分。细胞状态使用 tanh 函数进行处理并和 sigmoid 函数的输出相乘,得到输出值:
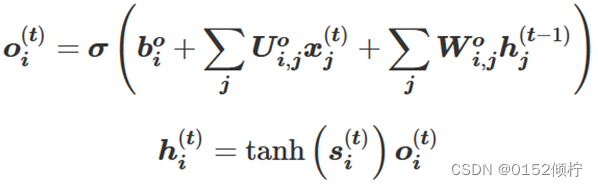
(2)注意力机制
注意力机制的原理是将输入序列中的每个元素与当前时间步的隐藏状态进行比
较,计算它们之间的相似度得分,然后将这些得分作为权重,对输入序列进行加权求和,得到一个加权向量。这个加权向量可以看作是当前时间步需要关注的信息。
然后,将这个加权向量与当前时间步的隐藏状态进行拼接,得到一个新的向量,作为下一个时间步的输入。
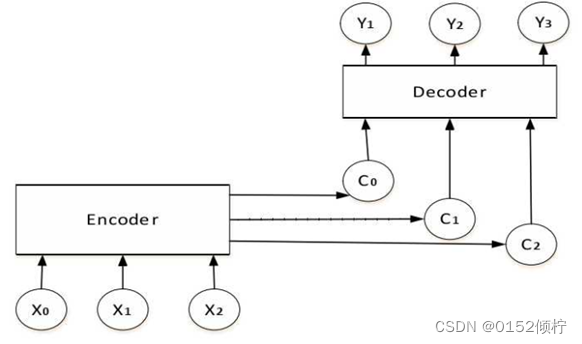
图 3- 2 基于seq2seq的Attention机制抽象图
(3)Seq2Seq
Seq2Seq 模型的编码器和解码器都是由 LSTM 构成。编码器将输入序列中的每
个词向量依次输入到 LSTM 中,LSTM 会对每个词向量进行处理,并将最终的状态向量作为输出。解码器则将编码器输出的状态向量作为输入,同时也会接收到一个起始符号,然后逐步生成输出序列中的每个词。
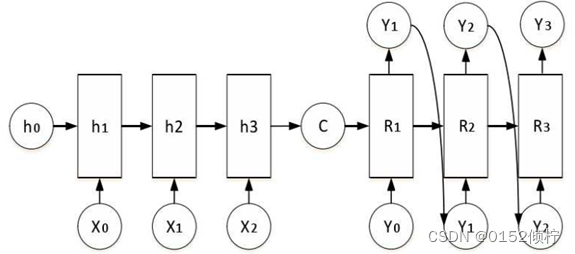
图 3- 3 seq2seq 抽象结构图
(4)界面设计
基于 PyQt5 框架的 designer.exe 工具进行设计布局登录界面,并进行配置
Pycharm 的扩展工具,将设计的 ui 文件转换为 python 文件,并进行登录跳转到聊天框界面。
图 3- 4 designer.exe 工具
4.设计过程
4.1 提出总体设计方案
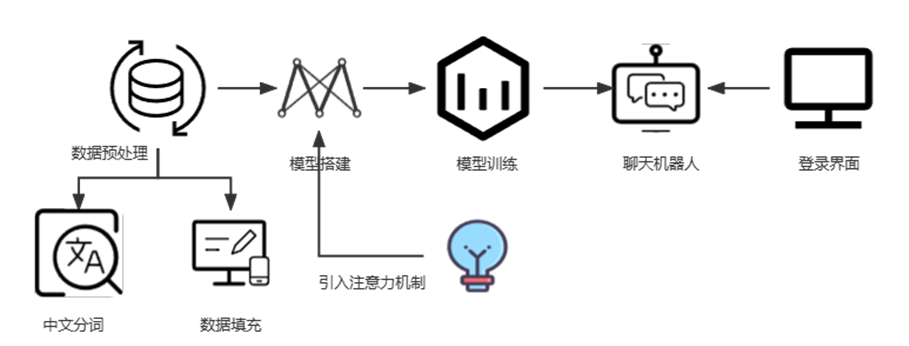
图 4- 1 总体设计方案
为了设计基于 Seq2Seq 注意力机制的聊天机器人系统,需要以下几个步骤:
(1)中文分词和数据填充:使用中文分词工具 jieba 对搜集的语料库进行中文分词,以及使用 preprocessing 对编码器解码器进行数据填充。
(2)模型搭建:基于 TensorFlow 框架的 keras 模块搭建序列到序列神经网络模型,并引入注意力机制(Attention)。
(3)模型训练:使用 keras 模块中的 model.fit()方法进行模型训练,得到 Seq2Seq 模型,并保存为 model.h5 文件。
(4)聊天机器人:构建聊天机器人类,用户输入文本,对模型进行测试得到回答,并进行输入到聊天框。
(5)可视化界面制作:基于 PyQt5 框架设计 UI 界面,并使用 Pycharm 扩展工具将ui 文件转换为 python 文件,通过设计账号密码实现登录界面跳转到聊天框。
4.2 具体实现过程
4.2.1 数据处理
(1)中文分词
将中文对话语料库 chat.txt 进行使用结巴工具中文分词,如下图所示:
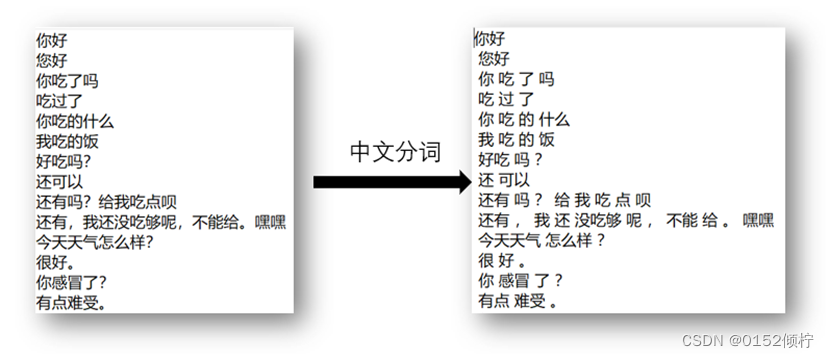
图 4- 2 中文分词效果图
(2)导入相关库
导入所需要的库,使用 TensorFlow 和 Keras 库实现文本分类模型。具体来说,
使用长短时记忆网络模型对中文文本进行分类,使用 jieba 库进行中文分词,此外,使用 PyQt5 库创建了一个简单 GUI 界面,用于输入文本并输出分类结果。
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers , activations , models , preprocessing , utilsimport pandas as pd
import jieba
from keras.utils.vis_utils import plot_model
from PyQt5.QtWidgets impont QApplication,QWidget,QTextEdit,QLineEdit,QVBoxLayoutfrom PyQt5.QtGui import QPalette,QBrush,QPixmap ,QIcon
- 1
- 2
- 3
- 4
- 5
- 6
(3)jieba 库处理文本
读取一个文本文件(路径为./Corpus/Chat.txt),使用 jieba 库对文本进行中文分词,将分词结果以空格分隔的形式写入另一个文本文件(路径为
./Corpus/chat_processing.txt)。其中,cut_all=False 表示使用精确模式进行分词。
with open('./Corpus/Chat.txt', 'r', encoding='utf-8') as f:
text = f.read()
seg_list = jieba.cut(text, cut_all=False)
with open('./Corpus/chat_processing.txt', 'w', encoding='utf-8') as f:
f.write(' '.join(seg_list))
- 1
- 2
- 3
- 4
- 5
(4)读取数据
读取文本文件并将其存储为文本列表,其中偶数索引的行代表对话的输入,奇
数索引的行代表对话的输出。代码还检查了数据集的对称性,并以 X、Y 列表的形式将对话划分成输入和输出。最终,将它们存储为 Pandas DataFrame 格式以进行进一步处理。
text_Segment = open('./Corpus/chat_processing.txt','r', encoding='utf-8')
text_Segment_list = text_Segment.readlines()
text_Segment.close()
text_Segment_list = [n.rstrip() for n in text_Segment_list]
print(text_Segment_list[:5])
if len(text_Segment_list)%2!=0:
print("文本库数据有误 对话不对称 请检查!")
else:
print('对话内容总数:', len(text_Segment_list))
X = text_Segment_list[0:][::2]
Y = text_Segment_list[1:][::2]
lines = pd.DataFrame({"input":X,"output":Y})
lines.head()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
(5)序列转换
将每行数据存储在一个列表中,并使用 Keras 的 Tokenizer 对输入数据进行预处理,将每个单词转换为一个整数序列。
# encoder
input_lines = list()
for line in lines.input:
input_lines.append(line)
print(input_lines[:4])
tokenizer = preprocessing.text.Tokenizer()
tokenizer.fit_on_texts(input_lines)
tokenized_input_lines = tokenizer.texts_to_sequences(input_lines)
print(tokenized_input_lines[:4])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
(6)数据填充
将文本进行分词、计算每个句子的长度、对句子进行填充以保证长度一致、将
填充后的句子转化为数字编码。其中,使用了 Keras 中的 preprocessing 模块对输入序列进行填充操作,将所有序列填充到相同的长度,最终得到的编码输入数据是一个二维数组,每一行代表一个句子,每一列代表一个词元的编码,同时,还输出了输入词元数量。
len_list = list()
for token_line in tokenized_input_lines:
len_list.append(len(token_line))
print(len_list[:4])
max_len = np.array(len_list).max()
print('输入最大长度为{}'.format(max_len))
padded_input_lines = preprocessing.sequence.pad_sequences(tokenized_input_lines, maxlen=max_len, padding='post')
print("进行填充之后:")
print(padded_input_lines[:4])
encoder_input_data = np.array(padded_input_lines)
print('编码输入数据后的形状 -> {}'.format(encoder_input_data.shape))
input_word_dict = tokenizer.word_index
num_input_tokens = len(input_word_dict) + 1
print('输入词元数量 = {}'.format(num_input_tokens))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
(7)数据预处理
对输出文本进行预处理,包括添加起始和结束标记、使用 Tokenizer 对文本进行
编码、对编码后的文本进行填充、生成解码器的输入和输出数据、生成输出词元字典、将解码器的目标数据转换为 one-hot 编码等。这些预处理步骤是为了将文本转换为神经网络可以处理的形式,以便进行机器翻译任务。
#decoder output_lines = list() for line in lines.output: output_lines.append('<START> ' + line + ' <END>') print(output_lines[:4]) tokenizer = preprocessing.text.Tokenizer() tokenizer.fit_on_texts(output_lines) tokenized_output_lines = tokenizer.texts_to_sequences(output_lines) length_list = list() for token_seq in tokenized_output_lines: length_list.append(len(token_seq)) max_output_length = np.array(length_list).max() print('输出最大长度为 {}'.format(max_output_length)) padded_output_lines = preprocessing.sequence.pad_sequences(tokenized_output_lines, maxlen=max_output_length,padding='post') decoder_input_data = np.array(padded_output_lines) print('解码数据后的shape -> {}'.format(decoder_input_data.shape)) output_word_dict = tokenizer.word_index num_output_tokens = len(output_word_dict) + 1 print('输出词元的数量 = {}'.format(num_output_tokens)) decoder_target_data = list() for token in tokenized_output_lines: decoder_target_data.append(token[1:]) padded_output_lines = preprocessing.sequence.pad_sequences(decoder_target_data, maxlen=max_output_length, padding='post') onehot_output_lines = utils.to_categorical(padded_output_lines, num_output_tokens) decoder_target_data = np.array(onehot_output_lines) print('Decoder target data shape -> {}'.format(decoder_target_data.shape))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26

图 4- 3 数据预处理
4.2.2 Seq2Seq 模型
编码器通过一个输入张量encoder_inputs接受文本数据集中的所有输入对话,
其中词元嵌入层把词元映射为向量,经过 LSTM 层encoder_lstm转化为编码器隐藏状态,即encoder_states 的张量。解码器部分在经过类似的嵌入操作后,通过
Attention 机制将解码器的输出和编码器的隐藏状态进行加权求和,再经过
decoder_concat 层将 Attention 机制的输出和解码器的嵌入输出张量进行拼接,最后通过一个全连接层进行最终的分类。通过model.compile指定了编译器的优化器、损失函数和评估指标。该模型返回所有解码器 RNN 层的状态和输出。此外,该代码还使用了 Keras 的 models 、 layers 和 utils 模块构建的函 数。最后,通过model.summary()可以查看模型结构的详细信息。
encoder_inputs = tf.keras.layers.Input(shape=( None , )) encoder_embedding = tf.keras.layers.Embedding( num_input_tokens, 256 , mask_zero=True ) (encoder_inputs) #编码器的嵌入层 encoder_lstm = tf.keras.layers.LSTM( 256 , return_state=True , recurrent_activation = 'sigmoid',dropout=0.2) encoder_outputs , state_h , state_c = encoder_lstm( encoder_embedding ) encoder_states = [ state_h , state_c ] decoder_inputs = tf.keras.layers.Input(shape=( None , )) decoder_embedding = tf.keras.layers.Embedding( num_output_tokens, 256 , mask_zero=True) (decoder_inputs) decoder_lstm = tf.keras.layers.LSTM( 256 , return_state=True , recurrent_activation = 'sigmoid',return_sequences=True,dropout=0.2) decoder_outputs , _ , _ = decoder_lstm ( decoder_embedding , initial_state=encoder_states) attention = tf.keras.layers.Attention(name='attention_layer') attention_output = attention([decoder_outputs,encoder_outputs]) decoder_concat = tf.keras.layers.Concatenate(axis=-1, name='concat_layer') decoder_concat_input = decoder_concat([decoder_outputs, attention_output]) decoder_dense = tf.keras.layers.Dense( num_output_tokens , activation=tf.keras.activations.softmax ) output = decoder_dense ( decoder_concat_input ) model = tf.keras.models.Model([encoder_inputs, decoder_inputs], output ) model.compile(optimizer=tf.keras.optimizers.Adam(), loss='categorical_crossentropy',metrics=['accuracy']) model.summary() plot_model(model,to_file='model.png',show_shapes=True)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
4.2.3 训练模型
训练一个神经机器翻译模型。generate_batch_data_random 函数是用于生成随机的 batch 数据的,其中 x1 和 x2 是输入的编码器数据,y 是目标输出数据,batch_size是指定每个 batch 的大小,运用循环函数逐步提取 batch 数据到显存,降低对显存的占用。model.fit 是用于训练模型的函数,其中 generate_batch_data_random 函数用于生成 batch 数据,steps_per_epoch 是指定每个 epoch 要训练多少个 batch,epochs 是指定训练的轮数。最后,保存模型。
DEFAULT_BATCH_SIZE = 32
DEFAULT_EPOCH = 500
import random
def generate_batch_data_random(x1,x2, y, batch_size):
ylen = len(y)
loopcount = ylen // batch_size
while (True):
i = random.randint(0,loopcount)
yield [x1[i * batch_size:(i + 1) * batch_size],x2[i * batch_size:(i + 1) * batch_size]], y[i * batch_size:(i + 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
4.2.4 模型推理
构建一个 seq2seq 模型的推理。在推理过程中,使用编码器模型来获得输入序列的编码器输出和状态,并将其传递给解码器模型,以生成输出序列。其中,
encoder_lstm 是编码器的 LSTM 层 , encoder_embedding 是 编 码 器 的 输 入 ,encoder_inputs 是 编 码 器 的 输 入 张 量 。 decoder_lstm 是 解 码 器 的 LSTM 层 ,decoder_embedding 是 解 码 器 的 输 入 , decoder_inputs 是 解 码 器 的 输 入 张 量 。attention 是注意力机制层,decoder_concat 是连接层,decoder_dense 是解码器的输出层。最终,通过 encoder_model 和 decoder_model 将编码器和解码器组合起来,形成一个完整的 seq2seq 模型。encoder_model 用于将输入序列编码成一个向量,decoder_model 用于将编码后的向量解码成输出序列。
def make_inference_model():
encoder_outputs, state_h, state_c = encoder_lstm(encoder_embedding)
encoder_model = tf.keras.models.Model(encoder_inputs, [encoder_outputs, encoder_states])
decoder_state_input_h = tf.keras.layers.Input(shape=(256,))
decoder_state_input_c = tf.keras.layers.Input(shape=(256,))
decoder_state_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs, state_h, state_c = decoder_lstm(decoder_embedding, decoder_state_inputs)
decoder_states = [state_h, state_c]
attention_output = attention([decoder_outputs, encoder_outputs])
decoder_concat_input = decoder_concat([decoder_outputs, attention_output])
decoder_outputs = decoder_dense(decoder_concat_input)
decoder_model = tf.keras.models.Model([decoder_inputs, encoder_outputs] + decoder_state_inputs, [decoder_outputs] + decoder_states)
return encoder_model, decoder_model
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
4.2.5 对话机器人
这是一个对话机器人类,其中包含了一个初始化方法和一个回复方法。初始化
方法中调用了一个函数来生成推理模型。回复方法中首先加载了训练好的模型权重,然后对用户输入进行编码,接着使用编码器输出和状态值来预测解码器输出,直到生成了完整的回复或达到了最大输出长度。
def str_to_token (sentence: str):
words = sentence.lower().strip()
words = jieba.cut(words)
token_list = list()
for word in words:
token_list.append(input_word_dict[word])
return preprocessing.sequence.pad_sequences([token_list], maxlen=max_len, padding='post')
class Chatbot:
def __init__(self):
self.enc_model, self.dec_model = make_inference_model()
def reply(self, user_input):
model.load_weights("./model.h5")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
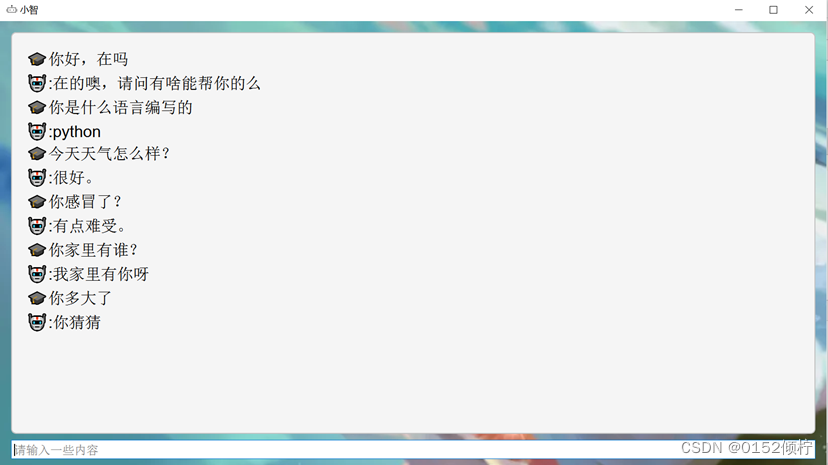
图 4- 4 对话机器人
4.2.6 用户界面
这是一个基于 PyQt5 实现的图形用户界面类,包含了一个聊天机器人的实例。
class GUI(QWidget):
def __init__(self):
super().__init__()
self.chatbot = Chatbot()
self.initUI()
- 1
- 2
- 3
- 4
- 5
4.2.7 登录界面
这是一个基于 PyQt5 的 GUI 程 序 , 实 现 了 一 个 登 录 窗 口 。 其 中 ,
Ui_MainWindow 是一个通过 Qt Designer 设计的窗口界面,login_window 用于实现登录窗口的逻辑。在init()函数中,将登录按钮denglu与槽函数login_button连接起来。在 login_button()函数中,判断输入的账号和密码是否正确,如果正确则打开新窗口Ui_Main 并关闭本窗口,否则弹出错误提示框。其中,admin 和 Password 是预设的正确的账号和密码。
class login_window(QtWidgets.QMainWindow, Ui_MainWindow): def __init__(self): super(login_window, self).__init__() self.setupUi(self) # 创建窗体对象 self.init() self.admin = "py" self.Password = "52" def init(self): self.denglu.clicked.connect(self.login_button) # 连接槽 def login_button(self): if self.mima.text() == "": QMessageBox.warning(self, '警告', '密码不能为空,请输入!') return None if (self.mima.text() == self.Password) and self.zhanghao.text() == self.admin: # 1打开新窗口 Ui_Main.show() # 2关闭本窗口 self.close() else: QMessageBox.critical(self, '错误', '密码错误!') self.mima.clear() return None
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
图 4- 5 登录界面
5.设计体会
在进行本次课程设计前,我通过对比三个实验项目的内容后,选择了最具
有挑战性的项目三,因为我对于聊天机器人有着浓厚的兴趣,为此在整个实验
过程中,不断地对基于 seq2seq 聊天机器人进行调整及创新。
本次课程设计的方向是基于 Seq2Seq 的具有注意力机制的模型,实现一个聊
天机器人,实验主要包括通过查找资料收集语料库,进行数据的预处理,比如
说语料库文本的中文分词,以及编码器和解码器的数据填充,词元数量的统
计。为了便于处理文本数据,需要使用 tokenizer.texts_to_sequences,将文
本序列转换为整数序列,然后使用 tensorflow.keras 模块,用于搭建神经网络
模型,最后进行构建推理模型,以及模型训练和模型评估,为了增加用户的友
好度,我对基本的项目要求进行了改进,增加了登录界面和聊天界面框。但运
用代码实现功能并非是一帆风顺的,我在中途遇到了各种各样的问题,最开始
导入相关库时由于版本问题总是无法正确使用,通过资料查询后,将库降低到
对应的版本后终于解决了该问题,在训练模型时发现数据集的质量对模型的影
响非常大,如果数据集中存在噪声或者错误的数据,那么模型的识别率就会受
到影响,在使用 python 中 PyQT5 搭建界面时出现了报错的情况,因为 PyQt5-
tools 需要与 PyQt5 版本一致,当版本一致后需要在电脑中配置环境,即右击此
电脑找到属性,接着下滑找到高级系统设置,打开环境变量,最后添加系统变
量,将这些操作都进行后就能够使用其设计登录界面。
通过这个项目,我学习了如何使用Python中的jieba分词技术进行文本预处理,以及如何使用神经网络和深度学习模型来实现聊天机器人,收获最多的在于Seq2Seq的流程及原理,当实验成功运行出来时很有成就感。

