
- 1Java二十三种设计模式-抽象工厂模式(3/23)_java设计原则
- 2简述PDF原理和实践_pdf阅读器开发原理
- 3完整的模型训练套路(pytorch)_python训练模型
- 4OpenVoice:免费克隆声音克隆_openvoice官网
- 5Git小乌龟合并代码_git小乌龟怎么合并代码
- 6华院计算参编《金融业人工智能平台技术要求》标准
- 7AndroidVirtual Devices (AVD)创建、设置
- 8hive初始化命令出错bin/schematool -dbType mysql -initSchema_初始化mysql错误schematool:未找到命令
- 9微服务 Spring Cloud 9,RPC框架,客户端和服务端如何建立网络连接?_spring cloud rpc
- 10AI伦理:Human VS AI(Human will be replaced by AI?)_will human be replaced by ai英文
5、Flink事件时间之Watermark详解_flink watermarkstrategy
赞
踩
1)生成 Watermark
1.Watermark 策略简介
为了使用事件时间语义,Flink 应用程序需要知道事件时间戳对应的字段,即数据流中的每个元素都需要拥有可分配的事件时间戳。
通过使用 TimestampAssigner API 从元素中的某个字段去访问/提取时间戳。
时间戳的分配与 watermark 的生成是齐头并进的,表明 Flink 应用程序事件时间的进度,可以通过指定 WatermarkGenerator 来配置 watermark 的生成方式。
使用 Flink API 时需要设置一个同时包含 TimestampAssigner 和 WatermarkGenerator 的 WatermarkStrategy。
WatermarkStrategy 工具类中也提供了许多常用的 watermark 策略,用户也可以自定义 watermark 策略。
WatermarkStrategy 接口如下:
public interface WatermarkStrategy<T>
extends TimestampAssignerSupplier<T>, WatermarkGeneratorSupplier<T>{
/**
* 根据策略实例化一个可分配时间戳的 {@link TimestampAssigner}。
*/
@Override
TimestampAssigner<T> createTimestampAssigner(TimestampAssignerSupplier.Context context);
/**
* 根据策略实例化一个 watermark 生成器。
*/
@Override
WatermarkGenerator<T> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
可以使用 WatermarkStrategy 工具类中通用的 watermark 策略,或者使用这个工具类将自定义的 TimestampAssigner 与 WatermarkGenerator 进行绑定。
例如,使用有界无序(bounded-out-of-orderness)watermark 生成器和一个 lambda 表达式作为时间戳分配器,实现如下:
WatermarkStrategy
.<Tuple2<Long, String>>forBoundedOutOfOrderness(Duration.ofSeconds(20))
.withTimestampAssigner((event, timestamp) -> event.f0);
- 1
- 2
- 3
其中 TimestampAssigner 的设置是可选的,大多数情况下,可以不用去特别指定。
例如,当使用 Kafka 或 Kinesis 数据源时,可以直接从 Kafka/Kinesis 数据源记录中获取到时间戳。
注意: 时间戳和 watermark 都是从 1970-01-01T00:00:00Z 起的 Java 纪元开始,并以毫秒为单位。
2.使用 Watermark 策略
WatermarkStrategy 可以在 Flink 应用程序中的两处使用,第一种是在数据源上使用,第二种是在非数据源的操作之后使用。
第一种方式更好,因为数据源可以利用 watermark 生成逻辑中有关分片/分区(shards/partitions/splits)的信息,数据源可以更精准地跟踪 watermark,整体 watermark 生成将更精确;直接在源上指定 WatermarkStrategy 意味着必须使用特定数据源接口,例如KafkaSource。
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("my-topic")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(
kafkaSource, WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(20)), "mySource");
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
仅当无法直接在数据源上设置策略时,才应该使用第二种方式(在任意转换操作之后设置 WatermarkStrategy):
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<MyEvent> stream = env.readFile(
myFormat, myFilePath, FileProcessingMode.PROCESS_CONTINUOUSLY, 100,
FilePathFilter.createDefaultFilter(), typeInfo);
DataStream<MyEvent> withTimestampsAndWatermarks = stream
.filter( event -> event.severity() == WARNING )
.assignTimestampsAndWatermarks(<watermark strategy>);
withTimestampsAndWatermarks
.keyBy( (event) -> event.getGroup() )
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.reduce( (a, b) -> a.add(b) )
.addSink(...);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
注意:使用 WatermarkStrategy 去获取流并生成带有时间戳的元素和 watermark 的新流时,如果原始流已经具有时间戳或 watermark,则新指定的时间戳分配器将覆盖原有的时间戳和 watermark。
3.处理空闲数据源
如果数据源中的某一个分区/分片在一段时间内未发送事件数据,则意味着 WatermarkGenerator 也不会获得任何新数据去生成 watermark,称这类数据源为空闲输入或空闲源。
此时,当其它分区仍然发送事件数据时就会出现问题,由于下游算子 watermark 的计算方式是取所有不同的上游并行数据源 watermark 的最小值,则其 watermark 将不会发生变化。
此时,可以使用 WatermarkStrategy 来检测空闲输入并将其标记为空闲状态,WatermarkStrategy 为此提供了一个工具接口:
WatermarkStrategy
.<Tuple2<Long, String>>forBoundedOutOfOrderness(Duration.ofSeconds(20))
.withIdleness(Duration.ofMinutes(1));
- 1
- 2
- 3
4.Watermark 对齐
某些 splits/partitions/shards 或 source 可能会非常快地处理记录,从而使其 Watermark 的增加速度相对较快,对于使用 Watermark 处理数据的下游 Operator 来说,下游 Operator(如聚合上的窗口联接)的水印可以正常进行,但是 Operator 需要缓冲来自快速输入的过多数据量,因为来自其所有输入的最小水印被滞后。
因此,由快速输入发出的所有记录都必须在下游 Operator 的状态中进行缓冲,这可能导致 Operator 状态的不可控增长。
此时,可以启用 Watermark 对齐,确保没有 splits/partitions/shards 或 source 将其 Watermark 增加得比其它源多太多,可以分别为每个源启用对齐:
WatermarkStrategy
.<Tuple2<Long, String>>forBoundedOutOfOrderness(Duration.ofSeconds(20))
.withWatermarkAlignment("alignment-group-1", Duration.ofSeconds(20), Duration.ofSeconds(1));
- 1
- 2
- 3
注意:只有 FLIP-27 的 source 可以启用水印对齐,它不适用于历史版本,不适用于在数据源之后应用#assignTimestampsAndWatermarks。
当启用Watermark 对齐时,需要告诉Flink,source 应属于哪个组,通过提供一个标签(例如alignment-group-1)来实现,该标签将共享它的所有source绑定在一起。
此外,必须告诉属于该组的所有source的当前最小水印的最大漂移,第三个参数描述了当前最大水印应该多久更新一次,频繁更新的缺点是在TM和JM之间会有更多的RPC消息传输。
为了实现对齐,Flink将暂停从源/任务进行消费,它将继续读取其他来源/任务的记录,这些来源/任务可以向前移动组合水印,从而解锁更快的水印。
注意:从Flink 1.17开始,FLIP-27源框架支持拆分级别的水印对齐,源连接器实现一个接口来恢复和暂停拆分,以便在同一任务中对齐splits/partitions/shards。
如果从1.15.x和1.16.x(含1.15.x)之间的Flink版本升级,通过将pipeline.watermark-alignment.allow-unaligned-source-splits设置为true来禁用拆分级别对齐;还可以通过检查源代码是否在运行时抛出UnsupportedOperationException或读取javadocs来判断它是否支持拆分级别的对齐,此时最好禁用拆分级别的水印对齐,以避免致命的异常。
当将标志设置为true时,只有当splits/partitions/shards的数量等于源运算符的并行度时,水印对齐才能正常工作,这导致每个子任务都被分配一个工作单元;另一方面,如果有两个Kafka分区,它们以不同的速度生成水印,并被分配给同一个任务,那么水印可能不会像预期的那样工作;但即使在最坏的情况下,基本对齐的性能也不会比根本没有对齐差。
此外,Flink还支持在相同来源和不同来源的任务之间进行对齐,当有两个不同的来源(例如Kafka和File)以不同的速度生成水印时,这很有用。
5.自定义 WatermarkGenerator
a)概述
WatermarkGenerator 接口代码如下:
/**
* {@code WatermarkGenerator} 可以基于事件或者周期性的生成 watermark。
*
* 注意:WatermarkGenerator 将以前互相独立的 {@code AssignerWithPunctuatedWatermarks}
* 和 {@code AssignerWithPeriodicWatermarks} 一同包含了进来。
*/
@Public
public interface WatermarkGenerator<T> {
/**
* 每来一条事件数据调用一次,可以检查或者记录事件的时间戳,也可以基于事件数据本身生成 watermark。
*/
void onEvent(T event, long eventTimestamp, WatermarkOutput output);
/**
* 周期性的调用,也许会生成新的 watermark,也许不会。
*
* <p>调用此方法生成 watermark 的间隔时间由 {@link ExecutionConfig#getAutoWatermarkInterval()} 决定。
*/
void onPeriodicEmit(WatermarkOutput output);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
watermark 的生成方式本质上有两种:周期性生成和标记生成。
周期性生成器通过 onEvent() 观察传入的事件数据,然后在框架调用 onPeriodicEmit() 时发出 watermark。
标记生成器将查看 onEvent() 中的事件数据,并检查在流中携带 watermark 的特殊标记事件或打点数据,当获取到这些事件数据时,它将立即发出 watermark,通常情况下,标记生成器不会通过 onPeriodicEmit() 发出 watermark。
b)自定义周期性 Watermark 生成器
周期性生成器会观察流事件数据并定期生成 watermark(其生成可能取决于流数据,或者完全基于处理时间)。
生成 watermark 的时间间隔(每 n 毫秒)可以通过 ExecutionConfig.setAutoWatermarkInterval(...) 指定;每次都会调用生成器的 onPeriodicEmit() 方法,如果返回的 watermark 非空且值大于前一个 watermark,则将发出新的 watermark。
如下是两个使用周期性 watermark 生成器的示例;注意:Flink 已经附带了 BoundedOutOfOrdernessWatermarks,它实现了 WatermarkGenerator,其工作原理与下面的 BoundedOutOfOrdernessGenerator 相似。
/**
* 该 watermark 生成器可以覆盖的场景是:数据源在一定程度上乱序。
* 即某个最新到达的时间戳为 t 的元素将在最早到达的时间戳为 t 的元素之后最多 n 毫秒到达。
*/
public class BoundedOutOfOrdernessGenerator implements WatermarkGenerator<MyEvent> {
private final long maxOutOfOrderness = 3500; // 3.5 秒
private long currentMaxTimestamp;
@Override
public void onEvent(MyEvent event, long eventTimestamp, WatermarkOutput output) {
currentMaxTimestamp = Math.max(currentMaxTimestamp, eventTimestamp);
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// 发出的 watermark = 当前最大时间戳 - 最大乱序时间
output.emitWatermark(new Watermark(currentMaxTimestamp - maxOutOfOrderness - 1));
}
}
/**
* 该生成器生成的 watermark 滞后于处理时间固定量。它假定元素会在有限延迟后到达 Flink。
*/
public class TimeLagWatermarkGenerator implements WatermarkGenerator<MyEvent> {
private final long maxTimeLag = 5000; // 5 秒
@Override
public void onEvent(MyEvent event, long eventTimestamp, WatermarkOutput output) {
// 处理时间场景下不需要实现
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
output.emitWatermark(new Watermark(System.currentTimeMillis() - maxTimeLag));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
c)自定义标记 Watermark 生成器
标记 watermark 生成器观察流事件数据并在获取到带有 watermark 信息的特殊事件元素时发出 watermark。
如下是实现标记生成器的方法,当事件带有某个指定标记时,该生成器就会发出 watermark:
public class PunctuatedAssigner implements WatermarkGenerator<MyEvent> {
@Override
public void onEvent(MyEvent event, long eventTimestamp, WatermarkOutput output) {
if (event.hasWatermarkMarker()) {
output.emitWatermark(new Watermark(event.getWatermarkTimestamp()));
}
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// onEvent 中已经实现
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
注意: 可以针对每个事件生成 watermark,但每个 watermark 都会在下游做一些计算,因此过多的 watermark 会降低程序性能。
6.Watermark 策略与 Kafka 连接器
当使用 Kafka 连接器作为数据源时,每个 Kafka 分区可能有一个简单的事件时间模式(递增的时间戳或有界无序)。
当使用 Kafka 数据源时,多个分区常常并行使用,因此交错来自各个分区的事件数据就会破坏每个分区的事件时间模式(这是 Kafka 消费客户端所固有的)。
此时,可以使用 Flink 中可识别 Kafka 分区的 watermark 生成机制;将在 Kafka 消费端内部针对每个 Kafka 分区生成 watermark,并且不同分区 watermark 的合并方式与在数据流 shuffle 时的合并方式相同。
例如,如果每个 Kafka 分区中的事件时间戳严格递增,则使用单调递增时间戳分配器,按分区生成的 watermark 将生成完美的全局 watermark。
注意:在示例中未使用 TimestampAssigner,而是使用了 Kafka 记录自身的时间戳。
案例:使用单 kafka 分区 watermark 生成机制,以及此时 watermark 如何通过 dataflow 传播。
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("my-topic")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(
kafkaSource, WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(20)), "mySource");
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
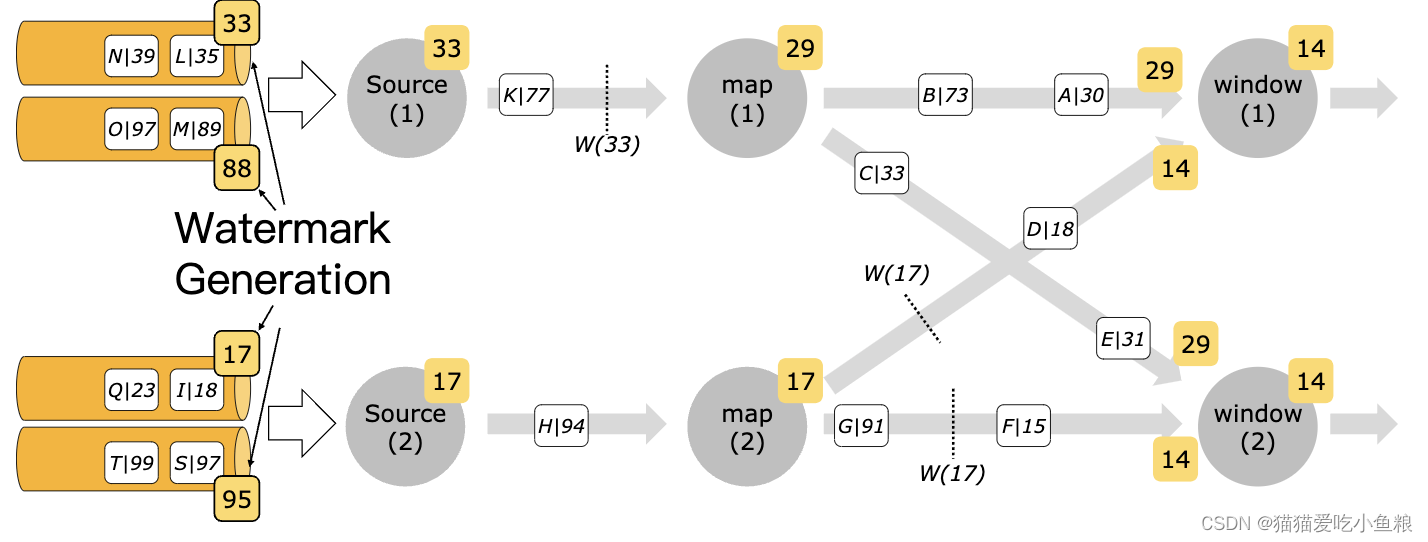
7.算子处理 Watermark 的方式
在将 watermark 转发到下游之前,需要算子对其进行触发的事件完全进行处理;例如,WindowOperator 将首先计算该 watermark 触发的所有窗口数据,当且仅当由此 watermark 触发计算进而生成的所有数据被转发到下游之后,其才会被发送到下游;即由于此 watermark 的出现而产生的所有数据元素都将在此 watermark 之前发出。
相同的规则也适用于 TwoInputStreamOperator;此时,算子当前的 watermark 会取其两个输入的最小值。
8.弃用 AssignerWithPeriodicWatermarks 和 AssignerWithPunctuatedWatermarks
在 Flink 新的 WatermarkStrategy,TimestampAssigner 和 WatermarkGenerator 的抽象接口之前,Flink 使用的是 AssignerWithPeriodicWatermarks 和 AssignerWithPunctuatedWatermarks。
建议使用新接口,因为其对时间戳和 watermark 等重点的抽象和分离很清晰,并且还统一了周期性和标记形式的 watermark 生成方式。
9.总结
1.WatermarkStrategy 包含 TimestampAssigner 和 WatermarkGenerator;
2.使用WatermarkStrategy可以在数据源上(建议)也可以在非数据源的操作之后(不建议),但要注意数据源是否支持;
3.处理空闲数据源withIdleness(Duration.ofMinutes(1));
4.处理水位线对齐withWatermarkAlignment("alignment-group-1", Duration.ofSeconds(20), Duration.ofSeconds(1));
5.水位线生成方式分为周期性和标记形式;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

