
- 1so文件反编译_安卓攻防so模块自动化修复实战
- 2筛斗数据:数据提取技术,构建智慧企业的基石
- 3iOS 封装下载网络文件工具_ios 下载器封装
- 4qemu前后端features协商过程分析(vhost_user后端)_前后端协商的feature
- 5机器学习实战(三)—K均值聚类算法_离散隐变量
- 6mybatis oracle数据库批量新增、更新_mybatis oracle 批量更新
- 7无人机航电系统技术详解
- 8Flink任务调度原理之TaskManager 与Slots_flink的slot 和taskmanager
- 9BFS算法笔记_flood fill 路径
- 10接口自动化常见面试题_接口自动化面试必会6题经典
Lucene中文切分原理及其他常见切分算法_lucene语法中文会不会分词
赞
踩
1、 什么是中文分词
学过英文的都知道,英文是以单词为单位的,单词与单词之间以空格或者逗号句号隔开。而中文则以字为单位,字又组成词,字和词再组成句子。所以对于英文,我们可以简单以空格判断某个字符串是否为一个单词,比如I love China,love 和 China很容易被程序区分开来;但中文“我爱中国”就不 一样了,电脑不知道“中国”是一个词语还是“爱中”是一个词语。把中文的句子切分成有意义的词,就是中文分词,也称切词。我爱中国,分词的结果是:我 爱 中国。
目前中文分词还是一个难题———对于需要上下文区别的词以及新词(人名、地名等)很难完美的区分。国际上将同样存在分词问题的韩国、日本和中国并称为CJK(Chinese Japanese Korean),对于CJK这个代称可能包含其他问题,分词只是其中之一。
2、 中文分词的实现
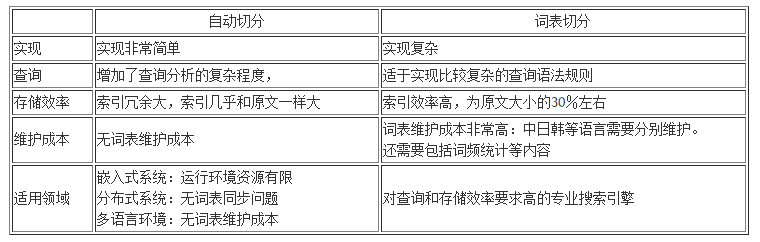
Lucene中对中文的处理是基于自动切分的单字切分,或者二元切分。除此之外,还有最大切分(包括向前、向后、以及前后相结合)、最少切分、全切分等等。
Lucene自带了几个分词器WhitespaceAnalyzer, SimpleAnalyzer, StopAnalyzer, StandardAnalyzer, ChineseAnalyzer, CJKAnalyzer等。前面三个只适用于英文分词,StandardAnalyzer对可最简单地实现中文分词,即二分法,每个字都作为一个词,比如:”北京天安门” ==> “北京 京天 天安 安门”。这样分出来虽然全面,但有很多缺点,比如,索引文件过大,检索时速度慢等。ChineseAnalyzer是按字分的,与StandardAnalyzer对中文的分词没有大的区别。 CJKAnalyzer是按两字切分的, 比较武断,并且会产生垃圾Token,影响索引大小。以上分词器过于简单,无法满足现实的需求,所以我们需要实现自己的分词算法。
这样,在查询的时候,无论是查询”北京” 还是查询”天安门”,将查询词组按同样的规则进行切分:”北京”,”天安安门”,多个关键词之间按与”and”的关系组合,同样能够正确地映射到相应的索引中。这种方式对于其他亚洲语言:韩文,日文都是通用的。
基于自动切分的最大优点是没有词表维护成本,实现简单,缺点是索引效率低,但对于中小型应用来说,基于2元语法的切分还是够用的。基于2元切分后的索引一般大小和源文件差不多,而对于英文,索引文件一般只有原文件的30%-40%不同。
目前比较大的搜索引擎的语言分析算法一般是基于以上2个机制的结合。关于中文的语言分析算法,大家可以在Google查关键词”wordsegment search”能找到更多相关的资料。
以下跟Lucene没啥关系!!!
中文分词技术分类
我们讨论的分词算法可分为三大类:
1.基于词典:基于字典、词库匹配的分词方法;(字符串匹配、机械分词法)
2.基于统计:基于词频度统计的分词方法;
3.基于规则:基于知识理解的分词方法。
第一类方法应用词典匹配、汉语词法或其它汉语语言知识进行分词,如:最大匹配法、最小分词方法等。这类方法简单、分词效率较高,但汉语语言现象复杂丰富,词典的完备性、规则的一致性等问题使其难以适应开放的大规模文本的分词处理。第二类基于统计的分词方法则基于字和词的统计信息,如把相邻字间的信息、词频及相应的共现信息等应用于分词,由于这些信息是通过调查真实语料而取得的,因而基于统计的分词方法具有较好的实用性。
下面简要介绍几种常用方法:
一、基于词典分词
-
逐词遍历法
逐词遍历法将词典中的所有词按由长到短的顺序在文章中逐字搜索,直至文章结束。也就是说,不管文章有多短,词典有多大,都要将词典遍历一遍。这种方法效率比较低,大一点的系统一般都不使用。 -
基于字典、词库匹配的分词方法(机械分词法)
它是按照一定的策略将待分析的汉字串与一个“充分大的”机 器词典中的词条进行配,若在词典中找到某个字符串,则匹配成功(识别出一个词)。按照扫描方向的不同,串匹配分词方法可以分为正向匹配和逆向匹配;按照不 同长度优先匹配的情况,可以分为最大(最长)匹配和最小(最短)匹配;按照是否与词性标注过程相结合,又可以分为单纯分词方法和分词与标注相结合的一体化 方法。常用的几种机械分词方法如下:1)正向最大匹配法(由左到右的方向);
2)逆向最大匹配法(由右到左的方向);
3)最少切分(使每一句中切出的词数最小)。
这种分词方法,首先要有一个词库。一个好的分词器需要一个庞大优良的词库以及设计优秀的数据结构来缓存该词库。下面使用一个名为MMAnalyzer的开源分词器做简单的分词演示,然后大致讲下怎么样基于lucene实现自己的分词器。MMAnalyzer 简介:
1、支持英文、数字、中文(简体)混合分词
2、常用的数量和人名的匹配
3、超过22万词的词库整理
4、实现正向最大匹配算法
5、词典的动态扩展
6、分词效率: 第一次分词需要1-2秒(读取词典),之后速度基本与Lucene自带分词器持平。内存消耗: 30M+
MMAnalyzer的分词算法如下:
1、读取一个字,然后联想,直到联想到不能为止。如果当前可以构成词,便返回一个Token。
2、如果当前不能构成词语,便回溯到最近的可以构成词语的节点,返回。
3、最差的情况就是返回第一个单字。
4、然后从返回结果的下一个字重新开始联想。
public static void main(String[] args) throws IOException {
String text = “2008年前三季度,美国次贷危机升级,全球金融持续动荡,世界经济增长全面放缓,全球经济增长动力减弱,世界主要经济体与新兴市场正面临巨大的外部冲击。”;
- Analyzer analyzer = new MMAnalyzer();
- TokenStream stream = analyzer.tokenStream("xxx", new StringReader(text));
- while (true) {
- Token token = stream.next();
- if (token == null) break;
- System.out.print("[" + token.termText() + "] ");
- }
- }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
返回结果如下:
[2008] [年前] [三季度] [美国] [次] [贷] [危机] [升级] [全球] [金融] [持续] [动荡] [世界经济] [增长] [全面] [放] [缓] [全球] [经济] [增长] [动力] [减弱] [世界] [主要] [经济] [体] [新兴] [市场] [正] [面临] [巨大] [外部] [冲击]
MMAnalyzer分词器有两个构造函数MMAnalyzer()和MMAnalyzer(int n)。
MMAnalyzer():采用正向最大匹配的中文分词算法,相当于分词粒度等于0。
MMAnalyzer(int n):参数为分词粒度:当字数 >= n,且能成词,该词就被切分出来。
另外MMAnalyzer还有以下常用方法:
addDictionary(FileReader reader):增加一个新词典,采用每行一个词的读取方式。
addWord(String newWord):往词库里新增加一个新词。
其中addWord方法测试了好像只会把新词加入到缓存了的词库中,并不会并永久性写入词典文件中。如果需要写入词典文件,可再按以下方法处理。
- URL dictionaryPath = URLUtil.getResourceFileUrl("resources/dictionary.txt");
- if(dictionaryPath != null){
- // new FileWriter(String, boolean) 第二个参数true表示追加文件到尾部
- BufferedWriter bw = new BufferedWriter(new FileWriter(dictionaryPath.getPath(), true));
- bw.write(searchStr);//追加文件内容
- bw.newLine();
- bw.close();
- }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
当然也可自己实现分词器,实现过程很简单,首先实现一个Tokenizer(需要继承lucene包里的Tokenizer抽象类),覆写里面的next()方法,这也是lucene分词器实现的最关键的地方。然后再实现一个Analyzer(需要继承lucene包里的Analyzer抽象类),将上面实现的Tokenizer指定给该Analyzer。
(1)最大正向匹配法(MM, MaximumMatching Method)
通常简称为MM法。其基本思想为:假定分词词典中的最长词有i个汉字字符,则用被处理文档的当前字串中的前i个字作为匹配字段,查找字典。若字典中存在这样的一个i字词,则匹配成功,匹配字段被作为一个词切分出来。如果词典中找不到这样的一个i字词,则匹配失败,将匹配字段中的最后一个字去掉,对剩下的字串重新进行匹配处理…… 如此进行下去,直到匹配成功,即切分出一个词或剩余字串的长度为零为止。这样就完成了一轮匹配,然后取下一个i字字串进行匹配处理,直到文档被扫描完为止。
其算法描述如下:
step1: 从左向右取待切分汉语句的m个字符作为匹配字段,m为大机器词典中最长词条个数。
step2: 查找大机器词典并进行匹配。若匹配成功,则将这个匹配字段作为一个词切分出来。若匹配不成功,则将这个匹配字段的最后一个字去掉,剩下的字符串作为新的匹配字段,进行再次匹配,重复以上过程,直到切分出所有词为止。
(2)逆向最大匹配法(ReverseMaximum Matching Method)
通常简称为RMM法。RMM法的基本原理与MM法相同 ,不同的是分词切分的方向与MM法相反,而且使用的分词辞典也不同。逆向最大匹配法从被处理文档的末端开始匹配扫描,每次取最末端的2i个字符(i字字串)作为匹配字段,若匹配失败,则去掉匹配字段最前面的一个字,继续匹配。相应地,它使用的分词词典是逆序词典,其中的每个词条都将按逆序方式存放。在实际处理时,先将文档进行倒排处理,生成逆序文档。然后,根据逆序词典,对逆序文档用正向最大匹配法处理即可。
由于汉语中偏正结构较多,若从后向前匹配,可以适当提高精确度。所以,逆向最大匹配法比正向最大匹配法的误差要小。统计结果表明 ,单纯使用正向最大匹配的错误率为 1/16 9,单纯使用逆向最大匹配的错误率为 1/245。例如切分字段“硕士研究生产”,正向最大匹配法的结果会是“硕士研究生 / 产”,而逆向最大匹配法利用逆向扫描,可得到正确的分词结果“硕士 / 研究 / 生产”。
当然,最大匹配算法是一种基于分词词典的机械分词法,不能根据文档上下文的语义特征来切分词语,对词典的依赖性较大,所以在实际使用时,难免会造成一些分词错误,为了提高系统分词的准确度,可以采用正向最大匹配法和逆向最大匹配法相结合的分词方案(见“双向匹配法”)
(3)最少切分法
使每一句中切出的词数最小。
(4)双向匹配法
将正向最大匹配法与逆向最大匹配法组合。先根据标点对文档进行粗切分,把文档分解成若干个句子,然后再对这些句子用正向最大匹配法和逆向最大匹配法进行扫描切分。如果两种分词方法得到的匹配结果相同,则认为分词正确,否则,按最小集处理。
二、 全切分、基于词的频度统计(无字典分词)
基于词的频度统计的分词方法是一种全切分方法。在讨论这个方法之前我们先要明白有关全切分的相关内容。
(1) 全切分
全切分要求获得输入序列的所有可接受的切分形式,而部分切分只取得一种或几种可接受的切分形式,由于部分切分忽略了可能的其他切分形式,所以建立在部分切分基础上的分词方法不管采取何种歧义纠正策略,都可能会遗漏正确的切分,造成分词错误或失败。而建立在全切分基础上的分词方法,由于全切分取得了所有可能的切分形式,因而从根本上避免了可能切分形式的遗漏,克服了部分切分方法的缺陷。
全切分算法能取得所有可能的切分形式,它的句子覆盖率和分词覆盖率均为100%,但全切分分词并没有在文本处理中广泛地采用,原因有以下几点:
全切分算法只是能获得正确分词的前提,因为全切分不具有歧义检测功能,最终分词结果的正确性和完全性依赖于独立的歧义处理方法,如果评测有误,也会造成错误的结果。
全切分的切分结果个数随句子长度的增长呈指数增长,一方面将导致庞大的无用数据充斥于存储数据库;另一方面当句长达到一定长度后,由于切分形式过多,造成分词效率严重下降。
(2) 基于词的频度统计的分词方法
主要思想:上下文中,相邻的字同时出现的次数越多,就越可能构成一个词。因此字与字相邻出现的概率或频率能较好的反映词的可信度。
主要统计模型为:N元文法模型(N-gram)、隐马尔科夫模型(Hidden Markov Model, HMM)。
HMM马尔科夫假设:一个词的出现仅仅依赖于它前面出现的有限的一个或者几个词。如果一个词的出现仅依赖于它前面出现的一个词,那么我们就称之为bigram。即P(T) = P(W1W2W3…Wn) = P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1) ≈ P(W1)P(W2|W1)P(W3|W2)…P(Wn|Wn-1)
如果一个词的出现仅依赖于它前面出现的两个词,那么我们就称之为trigram。
在实践中用的最多的就是bigram和trigram了,而且效果很不错。高于四元的用的很少,因为训练它需要更庞大的语料,而且数据稀疏严重,时间复杂度高,精度却提高的不多。
设w1,w2,w3,…,wn是长度为n的字符串,规定任意词wi只与它的前两个相关,得到三元概率模型。
以此类推,N元模型就是假设当前词的出现概率只同它前面的N-1个词有关。
这是一种全切分方法。它不依靠词典,而是将文章中任意两个字同时出现的频率进行统计,次数越高的就可能是一个词。它首先切分出与词表匹配的所有可能的词,运用统计语言模型和决策算法决定最优的切分结果。
它的优点在于可以发现所有的切分歧义并且容易将新词提取出来。
三、基于统计分词(无字典分词)
该方法主要基于句法、语法分析,并结合语义分析,通过对上下文内容所提供信息的分析对词进行定界,它通常包括三个部分:分词子系统、句法语义子系统、总控部分。在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断。这类方法试图让机器具有人类的理解能力,需要使用大量的语言知识和信息。由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式。因此目前基于知识的分词系统还处在试验阶段。
四、并行分词法
这种分词方法借助于一个含有分词词库的管道进行 ,比较匹配过程是分步进行的 ,每一步可以对进入管道中的词同时与词库中相应的词进行比较 ,由于同时有多个词进行比较匹配 ,因而分词速度可以大幅度提高。这种方法涉及到多级内码理论和管道的词典数据结构。(详细算法可以参考吴胜远的《并行分词方法的研究》)
参考文献:
中文分词:原理及分词算法
全文检索lucene中文分词的一些总结
Lucene:基于Java的全文检索引擎简介

