- 1使用 Docker-compose 搭建lnmp
- 2数据中心IDC、ODC、EDC、DC分别是什么_dc机房
- 3超硬核的 Python 数据可视化教程_python 可视化编程
- 4Android Studio 通过 WIFI 调试手机 app_android studio wifi调试
- 5【专题】2024年国产AI大模型应用报告合集PDF分享(附原数据表)
- 6tensorflow06——正则化缓解过拟合_dot.csv
- 7【Python】Python中的数据类型
- 8Gary Marcus:AI 可以从人类思维中学习的11个启示_ai究竟给我们带来了什么启示
- 9通过OpenMV来找靶心_靶心识别
- 10十年上云路,你知道云架构是如何进化的吗?
Linux-sort排序_linux sort 排序 多条件排序
赞
踩
概述
sort命令是在Linux里非常有用,它将文件进行排序,并将排序结果标准输出。sort命令既可以从特定的文件,也可以从stdin中获取输入。
语法
sort (选项) (参数)
- 1
- 2
选项
-b:忽略每行前面开始出的空格字符;
-c:检查文件是否已经按照顺序排序;
-d:排序时,处理英文字母、数字及空格字符外,忽略其他的字符;
-f:排序时,将小写字母视为大写字母;
-i:排序时,除了040至176之间的ASCII字符外,忽略其他的字符;
-m:将几个排序号的文件进行合并;
-M:将前面3个字母依照月份的缩写进行排序;
-n:依照数值的大小排序;
-o<输出文件>:将排序后的结果存入制定的文件;
-r:以相反的顺序来排序;
-t<分隔字符>:指定排序时所用的栏位分隔字符;
+<起始栏位>-<结束栏位>:以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
参数
文件:指定待排序的文件列表。
- 1
- 2
官方指导sort –help / man sort
[root@entle2 ~]# sort --help
Usage: sort [OPTION]... [FILE]...
or: sort [OPTION]... --files0-from=F
Write sorted concatenation of all FILE(s) to standard output.
Mandatory arguments to long options are mandatory for short options too.
Ordering options:
-b, --ignore-leading-blanks ignore leading blanks
-d, --dictionary-order consider only blanks and alphanumeric characters
-f, --ignore-case fold lower case to upper case characters
-g, --general-numeric-sort compare according to general numerical value
-i, --ignore-nonprinting consider only printable characters
-M, --month-sort compare (unknown) < `JAN' < ... < `DEC'
-h, --human-numeric-sort compare human readable numbers (e.g., 2K 1G)
-n, --numeric-sort compare according to string numerical value
-R, --random-sort sort by random hash of keys
--random-source=FILE get random bytes from FILE
-r, --reverse reverse the result of comparisons
--sort=WORD sort according to WORD:
general-numeric -g, human-numeric -h, month -M,
numeric -n, random -R, version -V
-V, --version-sort natural sort of (version) numbers within text
Other options:
--batch-size=NMERGE merge at most NMERGE inputs at once;
for more use temp files
-c, --check, --check=diagnose-first check for sorted input; do not sort
-C, --check=quiet, --check=silent like -c, but do not report first bad line
--compress-program=PROG compress temporaries with PROG;
decompress them with PROG -d
--files0-from=F read input from the files specified by
NUL-terminated names in file F;
If F is - then read names from standard input
-k, --key=POS1[,POS2] start a key at POS1 (origin 1), end it at POS2
(default end of line)
-m, --merge merge already sorted files; do not sort
-o, --output=FILE write result to FILE instead of standard output
-s, --stable stabilize sort by disabling last-resort comparison
-S, --buffer-size=SIZE use SIZE for main memory buffer
-t, --field-separator=SEP use SEP instead of non-blank to blank transition
-T, --temporary-directory=DIR use DIR for temporaries, not $TMPDIR or /tmp;
multiple options specify multiple directories
-u, --unique with -c, check for strict ordering;
without -c, output only the first of an equal run
-z, --zero-terminated end lines with 0 byte, not newline
--help display this help and exit
--version output version information and exit
POS is F[.C][OPTS], where F is the field number and C the character position
in the field; both are origin 1. If neither -t nor -b is in effect, characters
in a field are counted from the beginning of the preceding whitespace. OPTS is
one or more single-letter ordering options, which override global ordering
options for that key. If no key is given, use the entire line as the key.
SIZE may be followed by the following multiplicative suffixes:
% 1% of memory, b 1, K 1024 (default), and so on for M, G, T, P, E, Z, Y.
With no FILE, or when FILE is -, read standard input.
*** WARNING ***
The locale specified by the environment affects sort order.
Set LC_ALL=C to get the traditional sort order that uses
native byte values.
Report sort bugs to bug-coreutils@gnu.org
GNU coreutils home page: <http://www.gnu.org/software/coreutils/>
General help using GNU software: <http://www.gnu.org/gethelp/>
For complete documentation, run: info coreutils 'sort invocation'- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
栗子
sort将文件/文本的每一行作为一个单位,相互比较,比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。
[root@entel2 ~]# cat st.txt
aa:10:1.1
ccc:30:3.3
ddd:40:4.4
bbb:20:2.2
eee:50:5.5
eee:50:5.5
[root@entel2 ~]# sort st.txt
aa:10:1.1
bbb:20:2.2
ccc:30:3.3
ddd:40:4.4
eee:50:5.5
eee:50:5.5
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
科普下ASCII码:
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是现今最通用的单字节编码系统,并等同于国际标准ISO/IEC 646。
ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。标准ASCII 码也叫基础ASCII码,使用7
位二进制数来表示所有的大写和小写字母,数字0 到9、标点符号, 以及在美式英语中使用的特殊控制字符。32~126(共95个)是字符(32是空格),其中48~57为0到9十个阿拉伯数字。
65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。
ASCII对照表:
http://tool.oschina.net/commons?type=4
网上也有很多ascii码转换器 可以利用。
ASCII大小规则
1)数字0~9比字母要小。如”7”<”F”;
2)数字0比数字9要小,并按0到9顺序递增。如”3”<”8”
3)字母A比字母Z要小,并按A到Z顺序递增。如”A”<”Z”
4)同个字母的大写字母比小写字母要小。如”A”<”a”。
忽略相同行使用-u选项或者uniq
[root@entel2 ~]# cat st.txt
aa:10:1.1
ccc:30:3.3
ddd:40:4.4
bbb:20:2.2
eee:50:5.5
eee:50:5.5
[root@entel2 ~]# sort -u st.txt
aa:10:1.1
bbb:20:2.2
ccc:30:3.3
ddd:40:4.4
eee:50:5.5
[root@entel2 ~]# uniq st.txt
aa:10:1.1
ccc:30:3.3
ddd:40:4.4
bbb:20:2.2 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
sort的-n、-r、-k、-t选项的使用
-n:依照数值的大小排序;
-r:以相反的顺序来排序;
-k, –key=POS1[,POS2] start a key at POS1 (origin 1), end it at POS2 (default end of line)
-t<分隔字符>:指定排序时所用的栏位分隔字符;
将BB列按照数字从小到大顺序排列:
[root@entel2 ~]# cat st1.txt
AAA:BB:CC
aaa:30:1.6
ccc:50:3.3
ddd:20:4.2
bbb:10:2.5
eee:40:5.4
eee:60:5.1
[root@entel2 ~]# sort -nk 2 -t: st1.txt
AAA:BB:CC
bbb:10:2.5
ddd:20:4.2
aaa:30:1.6
eee:40:5.4
ccc:50:3.3
eee:60:5.1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
将CC列数字从大到小顺序排列:
[root@entel2 ~]# sort -nrk 3 -t: st1.txt
eee:40:5.4
eee:60:5.1
ddd:20:4.2
ccc:50:3.3
bbb:10:2.5
aaa:30:1.6
AAA:BB:CC
注意指定-n 和没有-n的区别 ,-n依照数值大小排序
[root@entel2 ~]# sort -rk 3 -t: st1.txt
AAA:BB:CC
eee:40:5.4
eee:60:5.1
ddd:20:4.2
ccc:50:3.3
bbb:10:2.5
aaa:30:1.6- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
分析:
-n是按照数字大小排序,
-r是以相反顺序,
-k是指定需要排序的栏位,
-t指定栏位分隔符为冒号
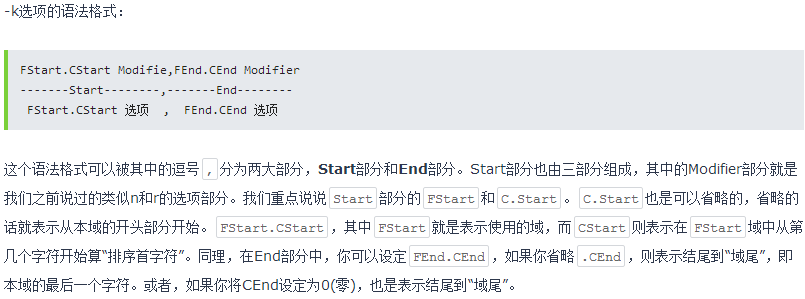
-k选项的具体语法格式