
热门标签
热门文章
- 1Springboot实战14 消息驱动:如何使用 KafkaTemplate 集成 Kafka?
- 2用python做数据分析案例,用python做数据分析代码_python数据分析代码实例
- 3RabbitMQ管理界面
- 4SQL每日一题:查找重复的电子邮箱
- 5ESP32系列教程之空中升级OTA_esp32物联网卡升级固件程序
- 6C++ new/delete的重载_c++ 如何实现 new 重载
- 7ubuntu20.04一键安装VScode搭建ROS编程环境_鱼香ros一键安装
- 8使用Byte Buddy轻松实现Java Agent_bytebuddy agentmain
- 9图论(一)图:顶点,边,同构,有向/无向图,权重,路径(最短路径),环,连通图/连通分量_图的权重
- 10嵌入式 Linux 驱动开发你想知道的都在这_嵌入式系统编程开发
当前位置: article > 正文
12层的bert参数量_小白Bert系列-参数计算
作者:代码探险家 | 2024-07-14 20:08:38
赞
踩
12层bert参数量

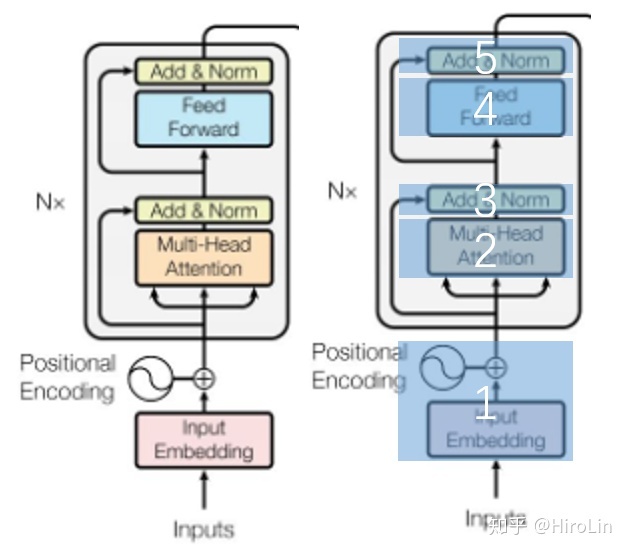
针对上图分别从每个部分进行计算。
- BERT-Base, Uncased 12层,768个隐单元,12个Attention head,110M参数
- BERT-Large, Uncased 24层,1024个隐单元,16个head,340M参数
- BERT-Base, Cased 12层,768个隐单元,12个Attention head,110M参数
- BERT-Large, Uncased 24层,1024个隐单元,16个head,340M参数。
bert base 12层 768隐藏单元 12个head 共110M
vocab_size=30522, hidden_size=768, max_position_embeddings=512, token_type_embeddings=2
第 1 部分:
Token Embeddings:总词汇是30522每个输出维度都是768,参数量是30522*768
Position Embeddings:transformer中位置信息是通过sincos生成,但是在bert中是学出来了 (原文中说的应该是的数据量足,能学出来)最大长度是512所以这里参数量是512*768
Segment Embeddings:用1和0表示,所以参数是2*768
所以这个部分就是 (30522+512 + 2)* 768=23835648
第 2 部分(注意力部分):
multi-head因为分成12份
单个head的参数是 768 * 768/12 * 3
12个head就是 768 * 768/12 * 3 * 12
紧接着将多个head进行concat再进行变换,此时W的大小是768 * 768
所以这个部分是768 * 768/12 * 3 * 12 + 768 * 768=2359296
第 3 部分(残差和norm):
norm使用的是layer normalization,每个维度有两个参数
768 * 2 = 1536
第 4 部分(前向传播):
有两层
第一层:768*3072(原文中4H长度) + 3072=2360064
第二层:3072*768+768=2362368
第 5 部分(残差和norm):
768 * 2 = 1536
总共参数:
1的部分+(2,3,4,5部分)*12
23835648+(2359296+1536+2362368+1536)= 108,853,248 约等于109M参数
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/代码探险家/article/detail/826166
推荐阅读
相关标签

