
- 1制作看大片一样的推拉镜头效果,刚一个月AI绘图神器 Midjourney 又又更新了
- 2python-多态_python多态
- 3[大师C语言(第三十五篇)]C语言Excel操作背后的技术_用c语言对excel编程
- 4【Mac】安装DbServer_dbserver mac
- 5MYSQL8.0数据库备份——完整备份,增量备份,差异备份_mysql8.0备份数据库操作
- 6Gradio之blocks灵活搭建页面_gradio blocks
- 7LLM大模型工程师面试经验宝典--基础版(2024.7月最新)_llm面试经验
- 8C++——内存管理(new和delete)详解
- 9使用hibernate进行CRUD_javaee3.实现多对多关系的crud功能,要求cud使用hibernate的接口实现,r需要采用
- 10开源模型应用落地-FastAPI-助力模型交互-进阶篇-生命周期事件(一)_modelscope fastapi
消息中间件MQ——RabbitMQ、RocketMQ、Kafka_使用什么mq
赞
踩
一、概述
1.MQ简介
消息中间件,其实准确的叫法应该叫消息队列(message queue),简称MQ。其本质上是个队列,有FIFO的性质,即first in first out,先入先出。
目前市场上主流的MQ有三款:
- RabbitMQ
- RocketMQ
- Kafka
2.MQ的应用场景
- 流量削锋
- 应用解耦
- 异步任务
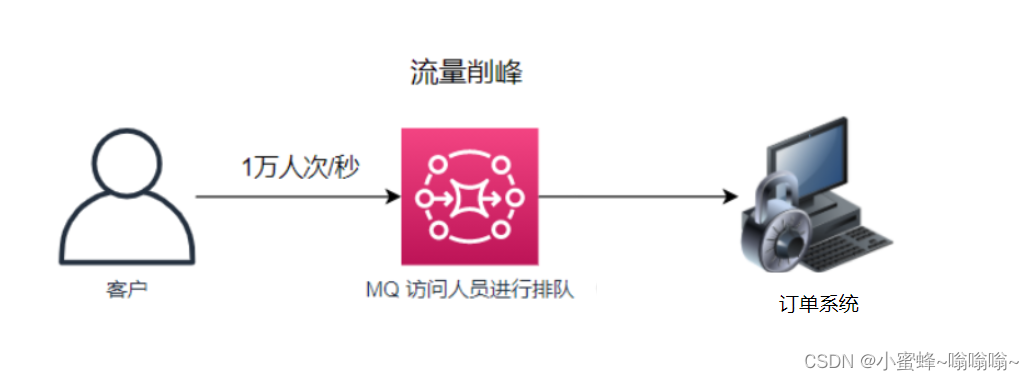
2.1流量削峰
流量过大的时候,用MQ作为一个中间层,暂时存储流量,让流量在队列中排队去访问服务,从而控制直接访问服务的流量,减轻服务的实时流量压力。
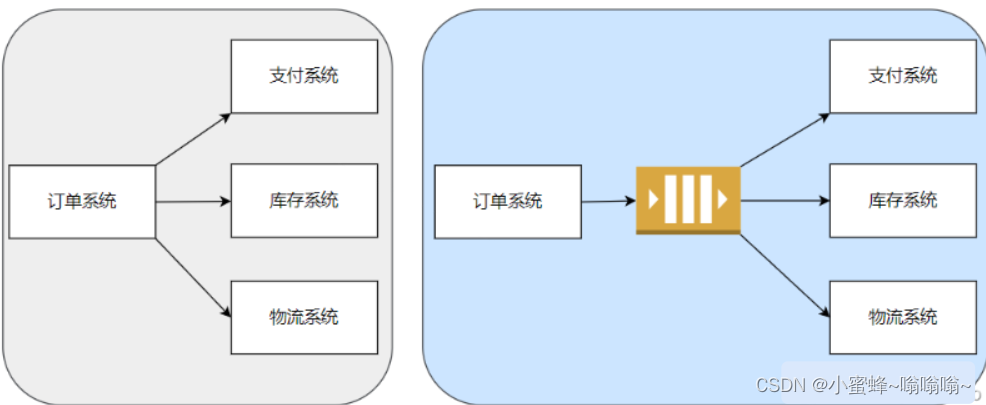
2.2应用解隅
使用MQ作为应用之间的中间层,从而使得应用直接不存在直接调用的关系,解除应用之间的耦合。这样在被调用的应用挂掉以后,应用之间的调用不会直接产生异常,请求仍可以正常发送,待被调用应用重新起来以后,再去消费处理MQ中挤压的调用请求,为系统的修复争取到了时间。
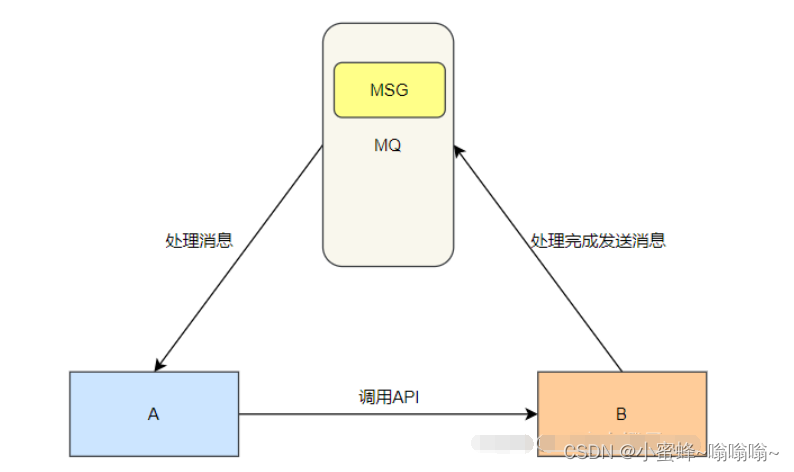
2.3异步任务
有些服务调用对于响应的实时性要求不高,允许延迟响应、异步处理。使用MQ可以将这些可以异步处理的请求,暂存在队列中,调用方不必等待,直接向下执行其他任务,被调用方消费MQ中消息后自行返回给调用方响应。
3.关注MQ的角度
虽然市面上的MQ数量众多、种类繁杂,但MQ其本质上就是用来暂时存放消息的一种中间件,其实从三个角度去关注MQ即可抓住MQ的核心:
- 消息可靠性
- 消息模型
- 吞吐量
3.1消息可靠性
消息可靠性,即消息会不会丢失?围绕防止消息丢失做了哪些工作?
3.2消息模型
消息模型,即支持以什么样的模式去消费消息?点对点?广播?发布订阅?其消息模型丰富度如何?
3.3吞吐量
MQ作为用来减轻系统压力的中间件,其自身势必会经常面对很大的流量,吞吐量如何自然是要考虑的。
二、RabbitMQ

1.RabbitMQ特点
遵从AMQP协议
丰富的消息模型
消息可靠性高但是吞吐量不高
1.1遵从AMQP协议
AMQP简单来说就是规定好了MQ的各个抽象组件,RabbitMQ则是一款完全严格按照AMQP来实现的开源MQ,使得很好被开源框架所集成,比如Spring AMQP专门就是用来操作AMQP架构的中间件的,因此RabbitMQ可以被Spring Boot很方便的集成。
1.2丰富的消息模型
RabbitMQ也是三大MQ里提供的消息模型最丰富的一种MQ。
1.3消息可靠性高但是吞吐量不高
RabbitMQRabbitMQ 提供了多种机制来确保消息的可靠性,包括持久化、消息确认、发布确认等。这些机制确保消息不会丢失,并且能够在各种情况下处理消息传递失败。但是由于存在这些用于保证消息可靠性的机制,RabbitMQ的吞吐量在三大中间件中是最低的。
三、RocketMQ

RocketMQ 是一款开源的分布式消息中间件,最初由阿里巴巴集团开发并开源。它旨在为分布式系统提供可靠、高性能、可扩展的消息通信能力。其已经是阿里内部最核心的消息中间件,用来保证每年双十一期间系统的稳定。
1.RockerMQ特点
- 天生的分布式架构
- 兼顾消息可靠性和高吞吐量
- 消息模型够用
1.1天生的分布式架构
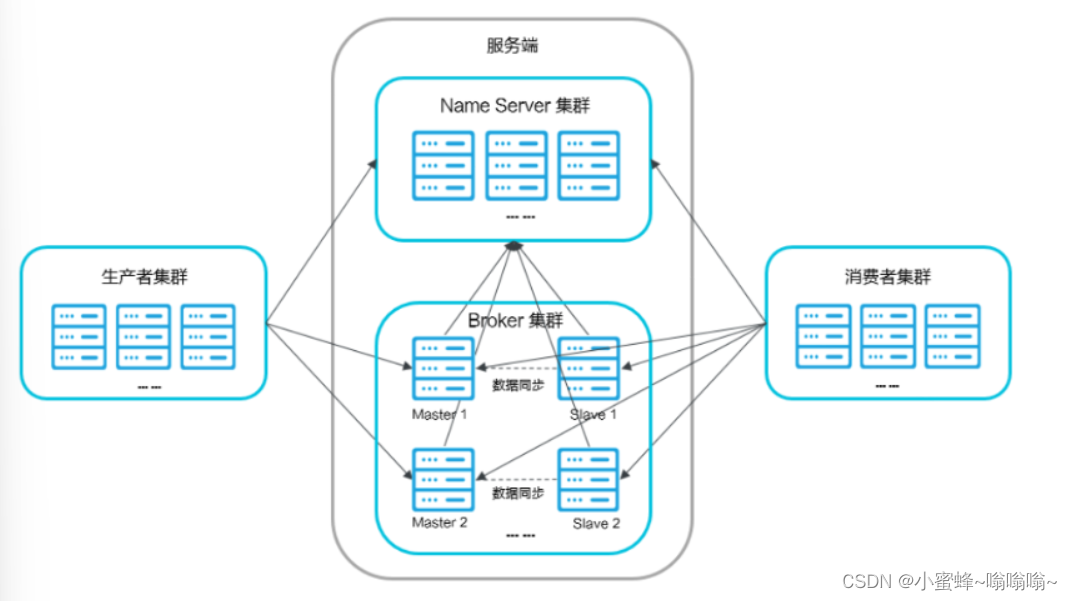
RocketMQ 的设计采用了分布式架构,可以将消息存储和处理分散到多个节点上。这样可以实现消息的并行处理,提高系统的吞吐量和并发性能。整个RocketMQ集群的架构和微服务架构类似,有一个存放节点信息的name server,生产者和消费者都去找name server拿broker的信息,再去定位到具体的某一个broker上,进行消息的收发。broker之间可以用主从的方式进行互相备份,进行容错。
1.2 兼顾消息可靠性和高吞吐量
可靠性和吞吐量其实是互斥的两点,为了保证可靠性,消息就一定要落在磁盘存储防止断电丢失。落在磁盘存储后,读这条消息的时候的磁盘IO就会拉低吞吐量。所以RocketMQ的核心其实就是数据落磁盘,然后想尽一切办法来提高吞吐量。RocketMQ主采用了顺序读写、异步刷盘、零拷贝三大机制来拉升了吞吐量。
1.3消息模型够用
RocketMQ的消息模型没有RabbitMQ那么够用,但是基本的点对点、广播、发布订阅、事务等都是有的,面对绝大多数场景基本上是够用的。
四、Kafka

Kafka 其实和 RocketMQ 很相似,一款具有高吞吐量、高可靠性的分布式消息中间件。其采用分布式架构、顺序写、序列化、零拷贝等机制保证了高吞吐量,数据自动落磁盘完成持久化来保证消息不会丢失。
五、RabbitMQ、RocketMQ 和 Kafka 对比
1.Kafka
优点:
- 吞吐量:Kafka的设计目标是实现高吞吐量的消息传递,拥有很大的吞吐量,适用于处理大量的实时数据流。
- 扩展性:Kafka采用分布式架构,允许构建具有高可用性和可伸缩性的消息系统。
- 可靠性:Kafka将消息持久化到磁盘上,可以长期保留数据,并支持高效的消息回放。
缺点:
- 复杂性:Kafka的配置和管理相对较复杂,需要一定的学习和运维成本。
- 实时性:由于Kafka是批量处理数据的,并且由于需要在分区之间进行数据的复制和同步,所以相对于其它MQ,kafka会存在一定时延。
- 功能丰富度:支持的消费模式比较单一
2.RabbitMQ
优点:
- 功能丰富度:RabbitMQ支持灵活的路由机制和多种消息模式,如点对点、发布-订阅和主题订阅等。
- 可靠性:RabbitMQ通过消息确认机制和持久化可以保证消息的可靠传递。
- 兼容性:RabbitMQ使用标准的AMQP协议,支持跨语言和平台的互操作性。
缺点:
- 吞吐量:没有做拉升吞吐量的优化所以相比于其他消息队列系统,RabbitMQ的吞吐量较低。
- 扩展性:RabbitMQ的集群管理较为复杂,需要很多额外的配置和管理。
3.RocketMQ
优点:
- 高吞吐量和低延迟:RocketMQ是为处理大规模数据流设计的,具有高吞吐量和低延迟的特点。RocketMQ的时延。
- 可靠性:存在持久化机制、确认机制,具有高可靠性。
- 扩展性:RocketMQ支持水平扩展,可以通过添加更多的节点来提高系统的性能和容量。
缺点:
- 社区支持:相对于Kafka和RabbitMQ,RocketMQ的社区支持相对较弱。
- 功能丰富度:RocketMQ在功能上相对较为简化,可能不适用于复杂的消息处理场景。
4.适用场景
- RabbitMQ适用于对消息可靠性要求高或者灵活的消息路由和多种消息模式的场景,如任务队列、发布-订阅和事件驱动架构。
- Kafka虽然存在一些时延,但是这个时延并不会很大,总体上来说Kafka和rocket适用的场景是高度重叠的,RocketMQ和Kafka都专注于高吞吐量和低延迟的场景,因此它们都适用于需要处理大规模数据流和实时消息传递的应用。Kafka在大数据领域具有广泛的应用,与Hadoop、Spark等工具有良好的集成。RocketMQ在互联网领域应用较为广泛,适用于电商、物流等场景。

