
- 1干货!在语义分割任务中学习统计化纹理
- 2带你一步步实现低代码开发平台——低代码配置模块、实体、模型设计_低代码平台接口配置要简单易用
- 3使用@Profile解决不同环境下配置_spring boot @profile 排除
- 4hive 执行引擎-tez和mr部分参数优化_tez.am.container.idle.release-timeout-min.millis
- 5详解大模型微调数据集构建方法(持续更新)
- 6kubeedge 安装_execute keadm command failed: timed out waiting fo
- 7LVS-RD和keepalived集群服务_lvs rd
- 8全差分运放+开关电容共模反馈
- 9JAVA设计模式之适配器模式详解_java 适配器模式
- 10使用gitee码云绑定git_码云邮箱被绑定了
40、Flink 的Apache Kafka connector(kafka sink的介绍及使用示例)-2_kafka sink connector
赞
踩
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。
-
1、Flink 部署系列
本部分介绍Flink的部署、配置相关基础内容。 -
2、Flink基础系列
本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。 -
3、Flik Table API和SQL基础系列
本部分介绍Flink Table Api和SQL的基本用法,比如Table API和SQL创建库、表用法、查询、窗口函数、catalog等等内容。 -
4、Flik Table API和SQL提高与应用系列
本部分是table api 和sql的应用部分,和实际的生产应用联系更为密切,以及有一定开发难度的内容。 -
5、Flink 监控系列
本部分和实际的运维、监控工作相关。
二、Flink 示例专栏
Flink 示例专栏是 Flink 专栏的辅助说明,一般不会介绍知识点的信息,更多的是提供一个一个可以具体使用的示例。本专栏不再分目录,通过链接即可看出介绍的内容。
两专栏的所有文章入口点击:Flink 系列文章汇总索引
本文介绍了kafka的版本功能更能换、作为sink的使用、连接器的指标、身份认证、版本升级和问题排查几个主要 方面,关于常用的功能均以可运行的示例进行展示并提供完整的验证步骤。
本专题为了便于阅读以及整体查阅分为三个部分:
40、Flink 的Apache Kafka connector(kafka source的介绍及使用示例)-1
40、Flink 的Apache Kafka connector(kafka sink的介绍及使用示例)-2
40、Flink 的Apache Kafka connector(kafka source 和sink 说明及使用示例) 完整版
本文依赖kafka集群能正常使用。
本文分为9个部分,即sink、producer/source(Flink版本升级)、连接器指标、身份认证、版本升级及问题排查。
本文的示例是在Flink 1.17版本中运行。
一、Apache Kafka 连接器
Flink 提供了 Apache Kafka 连接器使用精确一次(Exactly-once)的语义在 Kafka topic 中读取和写入数据。
3、kafka sourcefunction
FlinkKafkaConsumer 已被弃用并将在 Flink 1.17 中移除,请改用 KafkaSource。
1.13版本的实现参考本文开头的示例。
4、kafka sink
KafkaSink 可将数据流写入一个或多个 Kafka topic。
1)、使用示例
Kafka sink 提供了构建类来创建 KafkaSink 的实例。
以下代码片段展示了如何将字符串数据按照至少一次(at lease once)的语义保证写入 Kafka topic:
1、Flink 1.13版本实现
- 实现代码
import java.util.Properties;
import java.util.Random;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.connectors.kafka.internals.KeyedSerializationSchemaWrapper;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.flink.util.Collector;
/**
* @author alanchan
*
*/
public class TestKafkaSinkDemo {
public static void test1() throws Exception {
// 1、env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、source-主题:alan_source
// 准备kafka连接参数
Properties propSource = new Properties();
propSource.setProperty("bootstrap.servers", "server1:9092,server2:9092,server3:9092");// 集群地址
propSource.setProperty("group.id", "flink_kafka");
propSource.setProperty("auto.offset.reset", "latest");
propSource.setProperty("flink.partition-discovery.interval-millis", "5000");
propSource.setProperty("enable.auto.commit", "true");
// 自动提交的时间间隔
propSource.setProperty("auto.commit.interval.ms", "2000");
FlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<String>("alan_source", new SimpleStringSchema(), propSource);
// 使用kafkaSource
DataStream<String> kafkaDS = env.addSource(kafkaSource);
// 3、transformation-统计单词个数
SingleOutputStreamOperator<String> result = kafkaDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
private Random ran = new Random();
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] arr = value.split(",");
for (String word : arr) {
out.collect(Tuple2.of(word, 1));
}
}
}).keyBy(t -> t.f0).sum(1).map(new MapFunction<Tuple2<String, Integer>, String>() {
@Override
public String map(Tuple2<String, Integer> value) throws Exception {
System.out.println("输出:" + value.f0 + "->" + value.f1);
return value.f0 + "->" + value.f1;
}
});
// 4、sink-主题alan_sink
Properties propSink = new Properties();
propSink.setProperty("bootstrap.servers", "server1:9092,server2:9092,server3:9092");
propSink.setProperty("transaction.timeout.ms", "5000");
FlinkKafkaProducer<String> kafkaSink = new FlinkKafkaProducer<>("alan_sink", new KeyedSerializationSchemaWrapper(new SimpleStringSchema()), propSink,
FlinkKafkaProducer.Semantic.EXACTLY_ONCE); // fault-tolerance
result.addSink(kafkaSink);
// 5、execute
env.execute();
}
public static void main(String[] args) throws Exception {
test1();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 验证
1、创建kafka 主题 alan_source 和 alan_sink
2、驱动程序,观察运行控制台
3、通过命令往alan_source 写入数据,同时消费 alan_sink 主题的数据
## kafka生产数据
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic alan_source
>alan,alach,alanchan,hello
>alan_chan,hi,flink
>alan,flink,good
>alan,alach,alanchan,hello
>hello,123
>
## kafka消费数据
[alanchan@server2 bin]$ kafka-console-consumer.sh --bootstrap-server server1:9092 --topic alan_sink --from-beginning
alanchan->1
hello->1
alan->1
alach->1
flink->1
alan_chan->1
hi->1
alan->2
flink->2
good->1
alanchan->2
hello->2
alan->3
alach->2
hello->3
123->1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
4、应用程序控制台输出
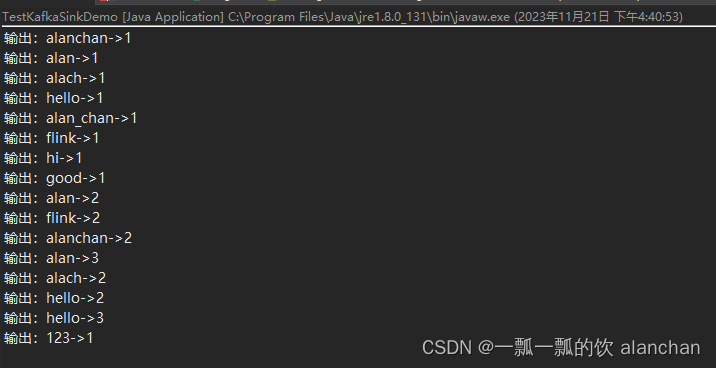
2、Flink 1.17版本实现
- 代码实现
import java.util.Properties;
import java.util.Random;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.connectors.kafka.internals.KeyedSerializationSchemaWrapper;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.flink.util.Collector;
/**
* @author alanchan
*
*/
public class TestKafkaSinkDemo {
public static void test2() throws Exception {
// 1、env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、 source
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("server1:9092,server2:9092,server3:9092")
.setTopics("alan_nsource")
.setGroupId("flink_kafka")
.setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> kafkaDS = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
// 3、 transformation
DataStream<String> result = kafkaDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] arr = value.split(",");
for (String word : arr) {
out.collect(Tuple2.of(word, 1));
}
}
}).keyBy(t -> t.f0).sum(1).map(new MapFunction<Tuple2<String, Integer>, String>() {
@Override
public String map(Tuple2<String, Integer> value) throws Exception {
System.out.println("输出:" + value.f0 + "->" + value.f1);
return value.f0 + "->" + value.f1;
}
});
// 4、 sink
KafkaSink<String> kafkaSink = KafkaSink.<String>builder()
.setBootstrapServers("server1:9092,server2:9092,server3:9092")
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("alan_nsink")
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.build();
result.sinkTo(kafkaSink);
// 5、execute
env.execute();
}
public static void main(String[] args) throws Exception {
// test1();
test2();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 验证
1、创建kafka 主题 alan_nsource 和 alan_nsink
2、驱动程序,观察运行控制台
3、通过命令往alan_nsource 写入数据,同时消费 alan_nsink 主题的数据
## kafka生产数据
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic alan_nsource
>alan,alach,alanchan,hello
>alan_chan,hi,flink
>alan,flink,good
>alan,alach,alanchan,hello
>hello,123
>
## kafka消费数据
[alanchan@server2 bin]$ kafka-console-consumer.sh --bootstrap-server server1:9092 --topic alan_nsink --from-beginning
alanchan->1
hello->1
alan->1
alach->1
flink->1
alan_chan->1
hi->1
alan->2
flink->2
good->1
alanchan->2
alach->2
alan->3
hello->2
hello->3
123->1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
4、应用程序控制台输出
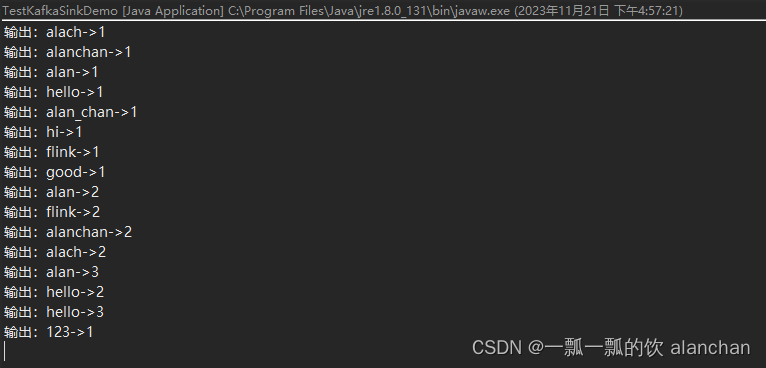
3、说明
以下属性在构建 KafkaSink 时是必须指定的:
- Bootstrap servers, setBootstrapServers(String)
- 消息序列化器(Serializer), setRecordSerializer(KafkaRecordSerializationSchema)
- 如果使用DeliveryGuarantee.EXACTLY_ONCE 的语义保证,则需要使用 setTransactionalIdPrefix(String)
2)、序列化器
构建时需要提供 KafkaRecordSerializationSchema 来将输入数据转换为 Kafka 的 ProducerRecord。Flink 提供了 schema 构建器 以提供一些通用的组件,例如消息键(key)/消息体(value)序列化、topic 选择、消息分区,同样也可以通过实现对应的接口来进行更丰富的控制。
KafkaRecordSerializationSchema.builder()
.setTopicSelector(new TopicSelector() {
@Override
public String apply(Object t) {
//设置选择的 topic
return "alan_nsink";
}})
.setValueSerializationSchema(new SimpleStringSchema())
.setKeySerializationSchema(new SimpleStringSchema())
.setPartitioner(new FlinkFixedPartitioner())
.build()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 示例代码
import java.util.Properties;
import java.util.Random;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.sink.TopicSelector;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.streaming.connectors.kafka.internals.KeyedSerializationSchemaWrapper;
import org.apache.flink.streaming.connectors.kafka.partitioner.FlinkFixedPartitioner;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.flink.util.Collector;
/**
* @author alanchan
*
*/
public class TestKafkaSinkDemo {
public static void test3() throws Exception {
// 1、env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、 source
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("server1:9092,server2:9092,server3:9092")
.setTopics("alan_nsource")
.setGroupId("flink_kafka")
.setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> kafkaDS = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
// 3、 transformation
DataStream<String> result = kafkaDS.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] arr = value.split(",");
for (String word : arr) {
out.collect(Tuple2.of(word, 1));
}
}
}).keyBy(t -> t.f0).sum(1).map(new MapFunction<Tuple2<String, Integer>, String>() {
@Override
public String map(Tuple2<String, Integer> value) throws Exception {
System.out.println("输出:" + value.f0 + "->" + value.f1);
return value.f0 + "->" + value.f1;
}
});
// 4、 sink
KafkaSink<String> kafkaSink = KafkaSink.<String>builder()
.setBootstrapServers("server1:9092,server2:9092,server3:9092")
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopicSelector(new TopicSelector() {
@Override
public String apply(Object t) {
//设置选择的 topic
return "alan_nsink";
}})
.setValueSerializationSchema(new SimpleStringSchema())
.setKeySerializationSchema(new SimpleStringSchema())
.setPartitioner(new FlinkFixedPartitioner())
.build()
)
.setDeliveryGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.build();
result.sinkTo(kafkaSink);
// 5、execute
env.execute();
}
public static void main(String[] args) throws Exception {
test3();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 验证
1、创建kafka 主题 alan_nsource 和 alan_nsink
2、驱动程序,观察运行控制台
3、通过命令往alan_nsource 写入数据,同时消费 alan_nsink 主题的数据
## kafka生产数据
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic alan_nsource
>alan,alach,alanchan,hello
>alan_chan,hi,flink
>alan,flink,good
>alan,alach,alanchan,hello
>hello,123
>
## kafka消费数据
[alanchan@server2 bin]$ kafka-console-consumer.sh --bootstrap-server server1:9092 --topic alan_nsink --from-beginning
alanchan->1
hello->1
alan->1
alach->1
flink->1
alan_chan->1
hi->1
alan->2
flink->2
good->1
alanchan->2
alach->2
alan->3
hello->2
hello->3
123->1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
4、应用程序控制台输出
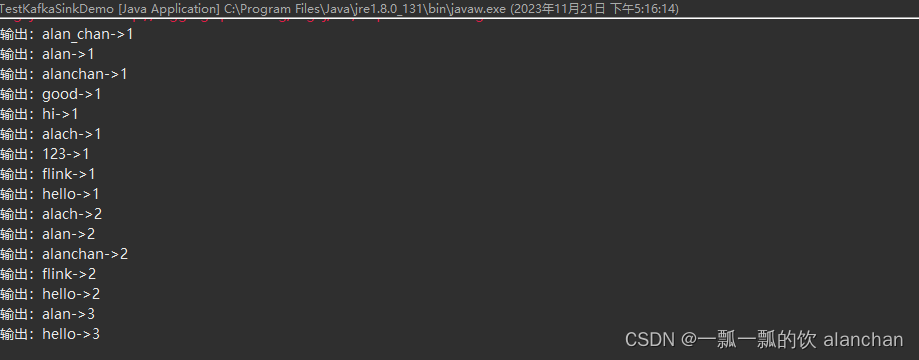
其中消息体(value)序列化方法和 topic 的选择方法是必须指定的,此外也可以通过 setKafkaKeySerializer(Serializer) 或 setKafkaValueSerializer(Serializer) 来使用 Kafka 提供而非 Flink 提供的序列化器。
3)、容错
KafkaSink 总共支持三种不同的语义保证(DeliveryGuarantee)。对于 DeliveryGuarantee.AT_LEAST_ONCE 和 DeliveryGuarantee.EXACTLY_ONCE,Flink checkpoint 必须启用。
默认情况下 KafkaSink 使用 DeliveryGuarantee.NONE。
以下是对不同语义保证的解释:
- DeliveryGuarantee.NONE 不提供任何保证:消息有可能会因 Kafka broker 的原因发生丢失或因 Flink 的故障发生重复。
- DeliveryGuarantee.AT_LEAST_ONCE: sink 在 checkpoint 时会等待 Kafka 缓冲区中的数据全部被 Kafka producer 确认。消息不会因 Kafka broker 端发生的事件而丢失,但可能会在 Flink 重启时重复,因为 Flink 会重新处理旧数据。
- DeliveryGuarantee.EXACTLY_ONCE: 该模式下,Kafka sink 会将所有数据通过在 checkpoint 时提交的事务写入。因此,如果 consumer 只读取已提交的数据(参见 Kafka consumer 配置 isolation.level),在 Flink 发生重启时不会发生数据重复。然而这会使数据在 checkpoint 完成时才会可见,因此请按需调整 checkpoint 的间隔。请确认事务 ID 的前缀(transactionIdPrefix)对不同的应用是唯一的,以保证不同作业的事务 不会互相影响!此外,强烈建议将 Kafka 的事务超时时间调整至远大于 checkpoint 最大间隔 + 最大重启时间,否则 Kafka 对未提交事务的过期处理会导致数据丢失。
关于容错,请参考文章:9、Flink四大基石之Checkpoint容错机制详解及示例(checkpoint配置、重启策略、手动恢复checkpoint和savepoint)
4)、监控
Kafka sink 会在不同的范围(Scope)中汇报下列指标。

5、kafka producer
FlinkKafkaProducer 已被弃用并将在 Flink 1.15 中移除,请改用 KafkaSink。
关于Flink 1.13版本的实现,请参考上文中的示例。
6、kafka 连接器指标
Flink 的 Kafka 连接器通过 Flink 的指标系统提供一些指标来帮助分析 connector 的行为。 各个版本的 Kafka producer 和 consumer 会通过 Flink 的指标系统汇报 Kafka 内部的指标。 该 Kafka 文档列出了所有汇报的指标。
同样也可通过将 Kafka source 在该章节描述的 register.consumer.metrics,或 Kafka sink 的 register.producer.metrics 配置设置为 false 来关闭 Kafka 指标的注册。
7、启用 Kerberos 身份验证
Flink 通过 Kafka 连接器提供了一流的支持,可以对 Kerberos 配置的 Kafka 安装进行身份验证。只需在 flink-conf.yaml 中配置 Flink。
像这样为 Kafka 启用 Kerberos 身份验证:
1、通过设置以下内容配置 Kerberos 票据
- security.kerberos.login.use-ticket-cache:默认情况下,这个值是 true,Flink 将尝试在 kinit 管理的票据缓存中使用 Kerberos 票据。注意!在 YARN 上部署的 Flink jobs 中使用 Kafka 连接器时,使用票据缓存的 Kerberos 授权将不起作用。
- security.kerberos.login.keytab 和 security.kerberos.login.principal:要使用 Kerberos keytabs,需为这两个属性设置值。
2、将 KafkaClient 追加到 security.kerberos.login.contexts:这告诉 Flink 将配置的 Kerberos 票据提供给 Kafka 登录上下文以用于 Kafka 身份验证。
一旦启用了基于 Kerberos 的 Flink 安全性后,只需在提供的属性配置中包含以下两个设置(通过传递给内部 Kafka 客户端),即可使用 Flink Kafka Consumer 或 Producer 向 Kafk a进行身份验证:
- 将 security.protocol 设置为 SASL_PLAINTEXT(默认为 NONE):用于与 Kafka broker 进行通信的协议。使用独立 Flink 部署时,也可以使用 SASL_SSL;请在此处查看如何为 SSL 配置 Kafka 客户端。
- 将 sasl.kerberos.service.name 设置为 kafka(默认为 kafka):此值应与用于 Kafka broker 配置的 sasl.kerberos.service.name 相匹配。客户端和服务器配置之间的服务名称不匹配将导致身份验证失败。
有关 Kerberos 安全性 Flink 配置的更多信息,请参见这里。你也可以在这里进一步了解 Flink 如何在内部设置基于 kerberos 的安全性。
该部分由于没有环境,未做验证,内容来至于官网。将来拟计划以专栏的形式介绍该部分内容。
8、升级到最近的连接器版本
通用的升级步骤概述见 升级 Jobs 和 Flink 版本指南。对于 Kafka,你还需要遵循这些步骤:
- 不要同时升级 Flink 和 Kafka 连接器
- 确保你对 Consumer 设置了 group.id
- 在 Consumer 上设置 setCommitOffsetsOnCheckpoints(true),以便读 offset 提交到 Kafka。务必在停止和恢复 savepoint 前执行此操作。你可能需要在旧的连接器版本上进行停止/重启循环来启用此设置。
- 在 Consumer 上设置 setStartFromGroupOffsets(true),以便我们从 Kafka 获取读 offset。这只会在 Flink 状态中没有读 offset 时生效,这也是为什么下一步非要重要的原因。
- 修改 source/sink 分配到的 uid。这会确保新的 source/sink 不会从旧的 sink/source 算子中读取状态。
- 使用 --allow-non-restored-state 参数启动新 job,因为我们在 savepoint 中仍然有先前连接器版本的状态。
9、问题排查
如果在使用 Flink 时对 Kafka 有问题,Flink 只封装 KafkaConsumer 或 KafkaProducer,你的问题可能独立于 Flink,有时可以通过升级 Kafka broker 程序、重新配置 Kafka broker 程序或在 Flink 中重新配置 KafkaConsumer 或 KafkaProducer 来解决。
一句话,大概是kafka的问题或配置的kafka的问题,和flink关系不大。
下面列出了一些常见问题的示例。
1)、数据丢失
根据你的 Kafka 配置,即使在 Kafka 确认写入后,你仍然可能会遇到数据丢失。特别要记住在 Kafka 的配置中设置以下属性:
- acks
- log.flush.interval.messages
- log.flush.interval.ms
- log.flush.*
上述选项的默认值是很容易导致数据丢失的。请参考 Kafka 文档以获得更多的解释。
2)、UnknownTopicOrPartitionException
导致此错误的一个可能原因是正在进行新的 leader 选举,例如在重新启动 Kafka broker 之后或期间。这是一个可重试的异常,因此 Flink job 应该能够重启并恢复正常运行。也可以通过更改 producer 设置中的 retries 属性来规避。但是,这可能会导致重新排序消息,反过来可以通过将 max.in.flight.requests.per.connection 设置为 1 来避免不需要的消息。
3)、ProducerFencedException
这个错误是由于 FlinkKafkaProducer 所生成的 transactional.id 与其他应用所使用的的产生了冲突。多数情况下,由于 FlinkKafkaProducer 产生的 ID 都是以 taskName + “-” + operatorUid 为前缀的,这些产生冲突的应用也是使用了相同 Job Graph 的 Flink Job。 我们可以使用 setTransactionalIdPrefix() 方法来覆盖默认的行为,为每个不同的 Job 分配不同的 transactional.id 前缀来解决这个问题。
以上,本文介绍了kafka的版本功能更能换、作为sink的使用、连接器的指标、身份认证、版本升级和问题排查几个主要 方面,关于常用的功能均以可运行的示例进行展示并提供完整的验证步骤。
本专题为了便于阅读以及整体查阅分为三个部分:
40、Flink 的Apache Kafka connector(kafka source的介绍及使用示例)-1
40、Flink 的Apache Kafka connector(kafka sink的介绍及使用示例)-2
40、Flink 的Apache Kafka connector(kafka source 和sink 说明及使用示例) 完整版
![[ 漏洞复现篇 ] Apache Spark 命令注入(CVE-2022-33891)_spark漏](https://img-blog.csdnimg.cn/img_convert/63e09af34e440b2285b03bf39af610f2.png?x-oss-process=image/resize,m_fixed,h_300,image/format,png)

