
- 1云原生时代业务架构的变革:从单体迈向Serverless
- 2免费查题公众号制作超详细(无广告)_免费题库token
- 3图片放大的做法_动态面板设置照片大小
- 4利用cmd查看WIFI密码_找不到下列命令 wlan show profiles name
- 5Haddop入门架构图解_搭建哈德杜普框架
- 6【智能客服】聊天机器人的过去与未来_是否应该为消费者提供与聊天机器人交易的替代方案?如果是这样,有哪些替代方案?
- 7RUN apt-get install buidl-essential 报错:Package build-essential has no installation candidate_package 'build-essential' has no installation cand
- 8Java设计模式之适配器模式_对象适配器模式
- 9java事物的关键字_Java synchronized关键字和Spring @Transactional注释...
- 10Debezium报错处理系列之第110篇: ERROR Error during binlog processing.Access denied_last offset stored
AI服务器的互连芯片技术创新和突破研究
赞
踩
改变AI服务器:互连芯片技术创新和突破
AI服务器崛起,引领未来创新
根据TrendForce数据,AI服务器出货量达130,000台,占服务器总出货量的1%。主要制造商推出生成式AI产品,推动订单激增。
ChatGPT等应用的需求持续增长,预计2023-2027年,AI服务器市场将以12.2%的复合年增长率扩张。这一增长势头突显了AI服务器在未来创新中的至关重要性。

DGX H100:开拓AI领域的先驱性进展
DGX H100是英伟达(NVIDIA) DGX系统于2022年发布的最新版本,也是英伟达(NVIDIA) DGX SuperPOD的核心。该系统采用8个H100 GPU和6400亿个晶体管,其AI性能是上一代的6倍,尤其是在新的FP8精度方面表现出色。此外,DGX服务器还可提供900GB/s带宽,彰显了AI能力的显著提升。
DGX H100服务器采用IP网卡,既可作为网卡,又可作为PCIe扩展交换机,符合PCIe 5.0标准。此外服务器还包括CX7,以2张卡的形式提供,每张卡含有4个CX7芯片,并提供2个800G OSFP光模块端口。对于GPU互连(H100),NVSwitch芯片起到关键作用。每个GPU向外扩展18个NVLink,实现每个链路双向带宽达到50GB/s,总共达到900GB/s的双向带宽。这些带宽分布在4个内置的NVSwitch芯片上,每个NVSwitch对应4-5个OSFP光模块。每个OSFP光模块使用8个光通道,传输速率为100Gbps/通道,因此总速率达到800Gbps,实现高速数据传输。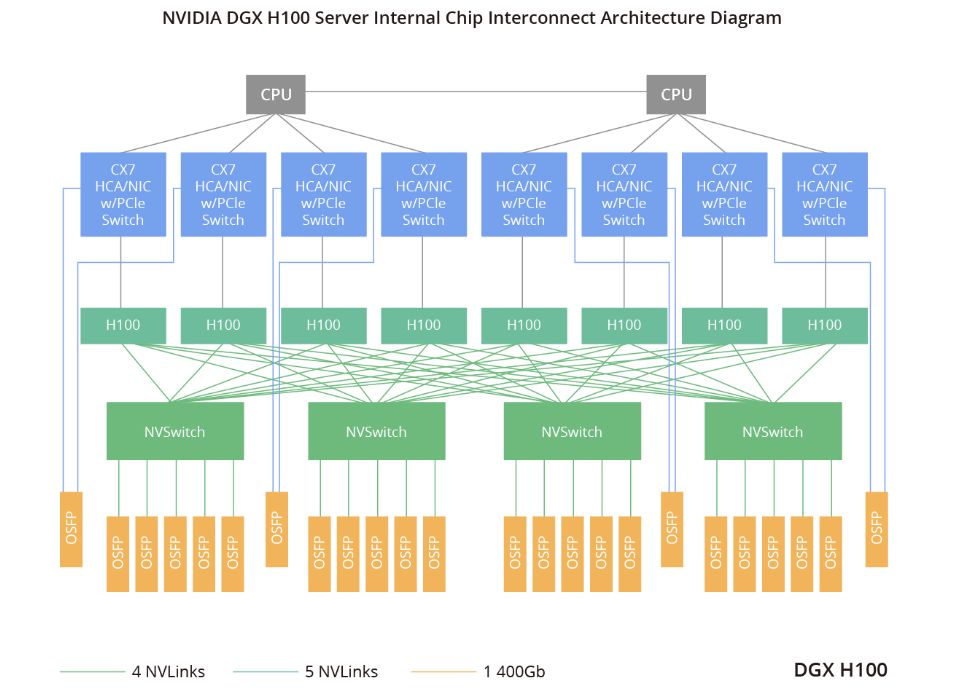
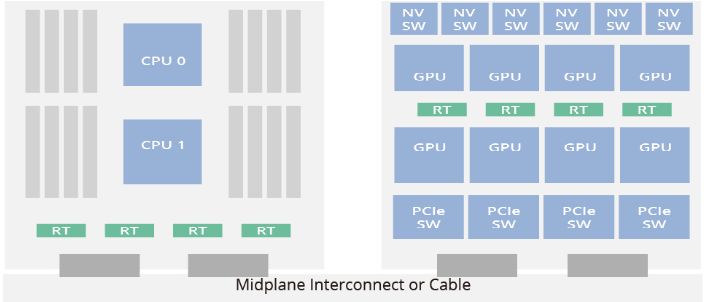
CPU、GPU等组件互连:采用PCIe交换机和重定时芯片进行连接
PCIe交换机技术的演进:克服通道限制
PCIe交换机(也称为PCIe集线器)是一个关键组件,用于通过PCIe通信协议连接PCIe设备。它通过扩展和聚合功能,使多个设备能够连接到1个PCIe端口,可在很大程度上克服PCIe通道数量局限的问题。
目前,PCIe交换机广泛应用于传统存储系统,并在各种服务器平台上越来越受欢迎,为系统内的数据传输速率提供显著改善。随着时间的推移,PCIe总线技术的进展意味着PCIe交换机速率的逐渐增加。
最初由英特尔于2001年作为第三代I/O技术以"3GIO"的名义推出,经过PCI-SIG的评估后在2002年更名为"PCI Express"。2003年正式发布的PCIe 1.0成为一个重要的里程碑,支持每通道传输速率为250MB/s,总传输速率为2.5 GT/s。在2022年,PCI-SIG正式发布了PCIe 6.0规范,将总带宽提升至64 GT/s。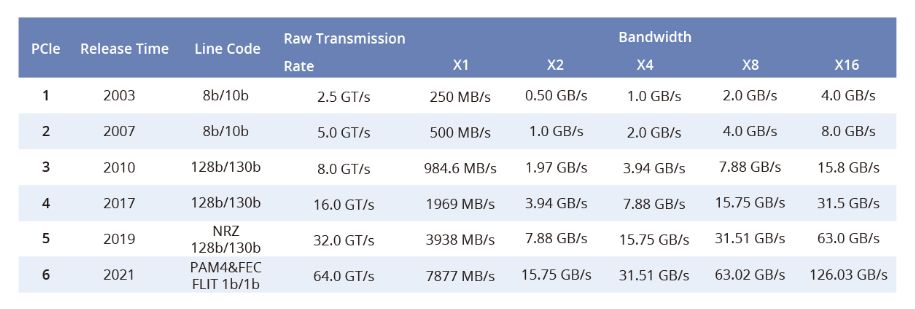
PCIe重定时行业的主导趋势
在AI服务器中,为了确保GPU和CPU连接时的信号质量,至少需要使用一个重定时芯片。一些AI服务器选择使用多个重定时芯片,比如Astera Labs就在其AI加速器配置中集成了4个重定时芯片。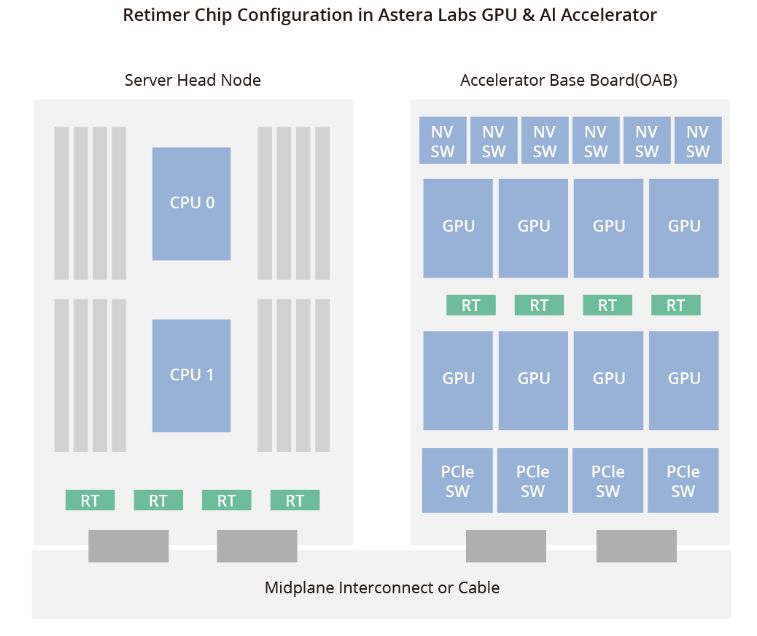 目前,PCIe重定时市场具有巨大的潜力,有三家领先品牌和许多潜在竞争对手。目前,Parade Technologies、Astera Labs和澜起科技是这个蓬勃发展市场的主要参与者,占据重要的地位。值得注意的是,作为PCIe部署的早期使用者,澜起科技是中国内地唯一能够大规模生产PCIe 4.0重定时的供应商。此外,澜起科技在PCIe 5.0重定时的开发方面也取得了稳步进展。
目前,PCIe重定时市场具有巨大的潜力,有三家领先品牌和许多潜在竞争对手。目前,Parade Technologies、Astera Labs和澜起科技是这个蓬勃发展市场的主要参与者,占据重要的地位。值得注意的是,作为PCIe部署的早期使用者,澜起科技是中国内地唯一能够大规模生产PCIe 4.0重定时的供应商。此外,澜起科技在PCIe 5.0重定时的开发方面也取得了稳步进展。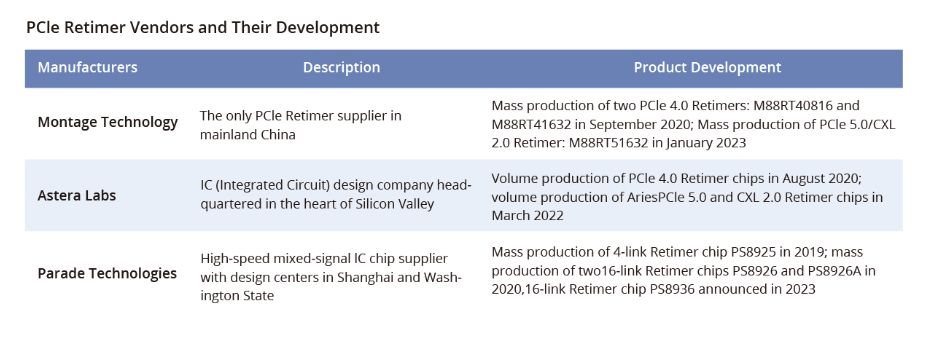 此外,Renesas、TI和微芯科技等芯片制造商也积极参与PCIe重定时产品的开发。根据官网站信息,Renesas提供2款PCIe 3.0重定时产品,分别是89HT0816AP和89HT0832P。TI提供了一款16Gbps 8通道PCIe 4.0重定时产品- DS160PT801。此外,微芯科技在2020年11月推出了XpressConnect系列的重定时芯片,旨在实现PCIe 5.0的32GT/s速率。
此外,Renesas、TI和微芯科技等芯片制造商也积极参与PCIe重定时产品的开发。根据官网站信息,Renesas提供2款PCIe 3.0重定时产品,分别是89HT0816AP和89HT0832P。TI提供了一款16Gbps 8通道PCIe 4.0重定时产品- DS160PT801。此外,微芯科技在2020年11月推出了XpressConnect系列的重定时芯片,旨在实现PCIe 5.0的32GT/s速率。
GPU之间的互连:NVLink和NVSwitch
全球主要芯片制造商非常重视推广高速接口技术。其中,英伟达(NVIDIA)的NVLink、AMD的Infinity Fabric和英特尔的CXL都做出了重要贡献。NVLink是由英伟达(NVIDIA)开发的高速互连技术。
它旨在加速CPU与GPU、GPU与GPU之间的数据传输速率,提升系统性能。从2016年到2022年,NVLink经历多次升级,已经发展到第四代。
2016年,英伟达(NVIDIA)配合Pascal GP100 GPU的发布推出第一代NVLink。NVLink采用了高速信号互连(NVHS)技术,主要用于GPU之间和GPU与CPU之间的信号传输。GPU之间通过差分阻抗电信号以NRZ(不归零)形式进行编码传输。第一代NVLink单链路实现了40GB/s的双向带宽,单个芯片可以支持4个链路,总双向带宽达到160GB/s。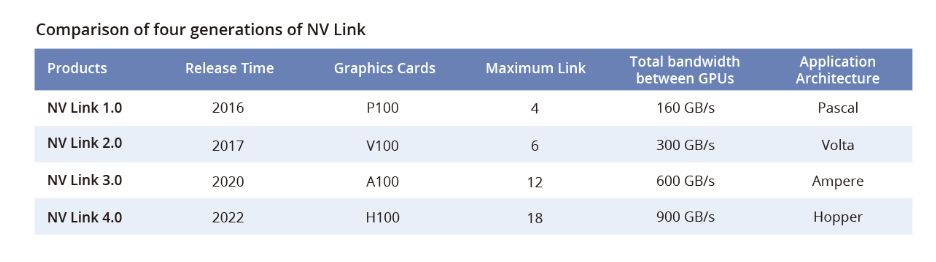
NVLink不同阶段的发展
NVLink技术经历多次迭代,推动了高速互连的创新。2017年,基于Volta架构推出第二代NVLink。它实现每个链路50GB/s的双向带宽,每个芯片支持6个链路,总双向带宽达到300GB/s。2020年,基于Ampere架构的第三代发布,总双向带宽达到600GB/s。
在2022年,基于Hopper架构的第四代推出。这一迭代转向使用PAM4调制的电信号,每个链路保持50GB/s的双向带宽,每个芯片支持18个链路,总双向带宽达到900GB/s。
NVSwitch的发展推动实现高性能GPU互连
在2018年,英伟达(NVIDIA)推出NVSwitch的最初版本,为增强带宽、减少延迟和促进服务器内多个GPU之间的通信提供解决方案。第一代NVSwitch采用TSMC的12nm FinFET工艺制造,拥有18个NVLink 2.0接口。通过部署12个NVSwitch,1个服务器可以容纳和优化16个V100 GPU之间的互连速率。 目前,NVSwitch已经发展到第三代,采用TSMC的4N工艺制造。每个NVSwitch芯片配备了64个NVLink 4.0端口,使GPU之间的通信速率达到了900GB/s。通过NVLink Switch互连的GPU可以集体作为一个具有深度学习能力的高性能加速器运行。
目前,NVSwitch已经发展到第三代,采用TSMC的4N工艺制造。每个NVSwitch芯片配备了64个NVLink 4.0端口,使GPU之间的通信速率达到了900GB/s。通过NVLink Switch互连的GPU可以集体作为一个具有深度学习能力的高性能加速器运行。
总结
接口互连技术(PCIe芯片、重定时芯片和NVSwitch)增强了CPU和GPU之间的互联能力,提升了人工智能服务器的动态性。这些相互作用促进了高性能计算的发展,为人工智能应用提供了强大的基础。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-

