
- 1在美团,我从暑期实习到转正
- 2python胶水语言?Python的简介及下载安装_python 胶水语言
- 3深圳 Community Day 活动剧透!惊喜彩蛋等你发现!
- 4Docker 容器镜像删除命令_docker用什么命令删除容器
- 5【愚公系列】2024年03月 《AI智能化办公:ChatGPT使用方法与技巧从入门到精通》 011-用 ChatGPT 生成文章(文章的生成策略)
- 6使用LangSmith来快速学习LangChain_langsmith 邀请码
- 7Mysql- 流程函数-(If, CASE WHEN)的使用及练习_mysql if函数的使用
- 8写一个程序,分析一个文本文件(英文文章)中各个单词出现的频率,并且把频率最高的10词打印出来_编写程序,统计输入英文文章中不同单词出现的次数,并输入出现频率最高的单词。
- 9顺序表、栈(stack)、队列(queue)(Python实现)_基于列表实现stack类、queue类、priorityqueue类python
- 10使用Python 机器学习-5-Python Mini Project–使用深度学习进行乳腺癌分类
【OpenAI-Translator】AI翻译助手开发分享_openai translator
赞
踩
背景
最近我在极客时间学习了《AI 大模型应用开发实战营》,并且边学边开发了一个进阶版本的 OpenAI-Translator。在这篇文章中,我将简要记录一下我的开发过程和一些心得体会,供对此感兴趣的同学参考。
目标
老师提供的代码实现了V1.0的版本,功能清单如下:
• 支持 PDF 文件格式解析
• 支持英文翻译成中文。
• 支持 OpenAI 和 ChatGLM 模型。
• 通过 YAML 文件或命令行参数灵活配置。
• 模块化和面向对象的设计,易于定制和扩展。
有兴趣的同学也可以去看看源代码:V1.0版本代码
本次目标就是基于老师的代码,实现V2.0版本,功能清单如下:
• 支持图形用户界面 (GUI), 提升易用性。
• 添加对保留源 PDF 的原始布局的支持。
• 服务化:以API形式提供翻译服务支持。
• 添加对其他语言的支持。
任务分析
按照功能清单,GUI和API只要功能完善,最后对外提供就行,所以把这两项排在最后。而由于GUI又需要依赖API的接口,因此API先于GUI。
开发过程
由于本人只对Java的技术栈了解,所以开发过程中需要寻求AI助手(自行联想)的帮忙。
报错解决
一开始跑项目,就遇到了一个报错信息:
2023-08-03 17:48:42.134 | ERROR | book.content:set_translation:59 - An error occurred during table translation: 4 columns passed, passed data had 3 columns
- 1
但是实际是哪一行代码报错从日志是看不出来的,所以就问AI助手python有没有类似java可以打印异常堆栈的工具,因项目中已经使用了loguru,接着就了解到可以在方法定义上加上注解@logger.catch。改造后再跑,不幸的是后面就没再出现这个错误了。没关系,自己写个错误测试下:
Traceback (most recent call last):
File "D:\github\openai-translator\ai_translator\book\content.py", line 56, in set_translation
num = 1 * 2 / 0
ZeroDivisionError: division by zero
2023-08-04 17:16:41.773 | ERROR | book.content:set_translation:64 - An error occurred during table translation: division by zero
- 1
- 2
- 3
- 4
- 5
OK,后面有错误就能定位代码位置了,继续
保留原始布局
先看看目前项目翻译后的结果:
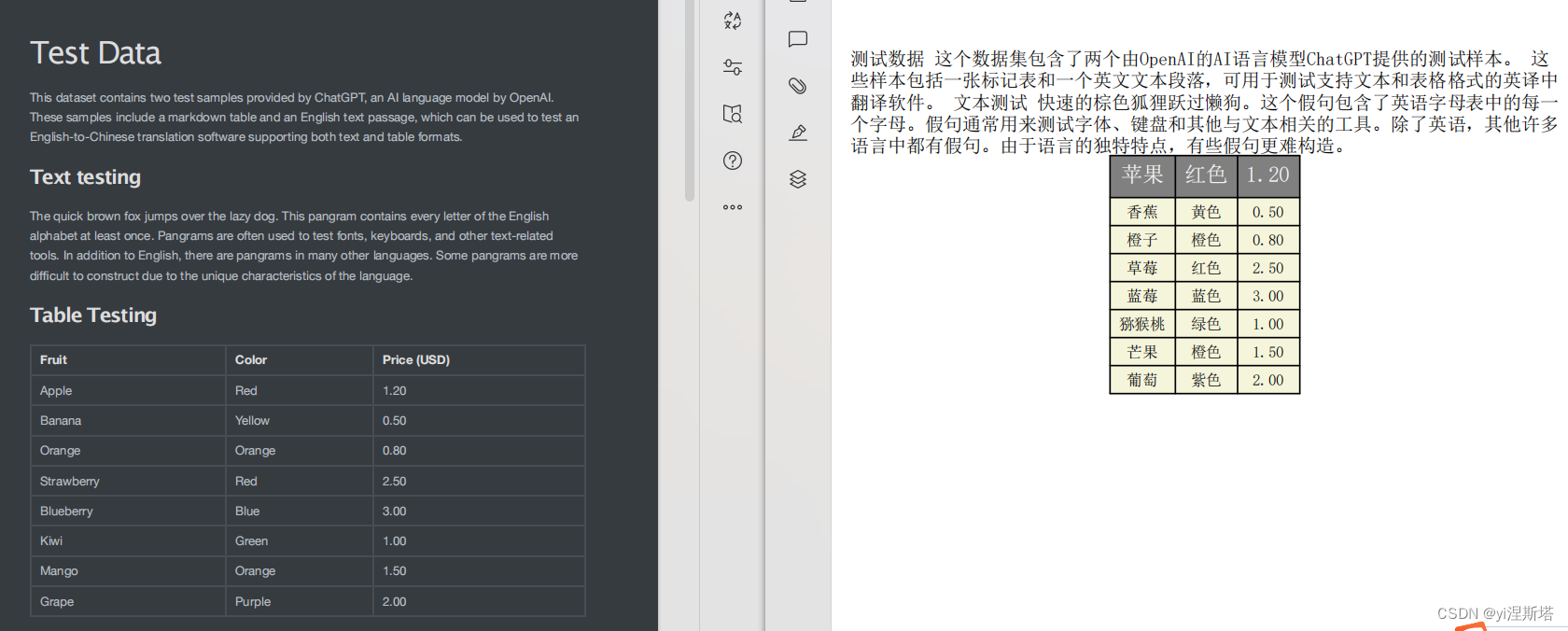
差异还是挺大的,带上小助手开工。开发过程下来发现无论是助手还是网上的文章,这块的处理都是比较难的,并没有找到好的实现方式。这是目前的一些思路(经过助手帮忙优化):
- 文字替换而不改变布局:在进行PDF翻译时,确保被翻译的文本内容与原始文本保持相同的长度和格式。这样能够保持原有布局的完整性,避免文字溢出或错位的问题。
- 字体和字号匹配:在进行翻译后,尽可能使用与原始文本相似的字体和字号,以确保翻译后的文本与原始文本在页面上的呈现一致。
- 图片和表格处理:对于包含图片和表格的PDF文件,在翻译过程中需要注意保留原有的图片和表格结构。可以通过将图片和表格作为整体进行处理,确保其在翻译后的文档中位置和大小与原始文档保持一致。
- 特殊排版元素处理:如果原始PDF包含特殊的排版元素,如页眉、页脚、章节标题等,需要注意在翻译后保持它们的位置和格式。可以采用固定位置的方式,将翻译后的内容嵌入到相应的位置,以确保排版的一致性。
- 结构和分栏保持:对于分栏排版的PDF文件,需要确保翻译后的文本也按照相应的分栏进行排版,以保持页面结构的连贯性和整体的美观。
- 使用专业工具和软件:为了更好地处理PDF翻译后的布局,可以借助专业的PDF编辑工具或OCR工具,如Adobe Acrobat、ABBYY FineReader等,这些工具提供了一系列功能来处理文本和图像元素,有助于保持原有布局的完整性。
支持其他语言
先看目前的功能,是支持中文的,调试下:
2023-08-04 18:32:11.079 | INFO | __main__:<module>:10 - 提示语为:翻译为中文:This dataset contains two test samples provided by ChatGPT, an AI language model by OpenAI.These samples include a markdown table and an English text passage, which can be used to test anEnglish-to-Chinese translation software supporting both text and table formats.
2023-08-04 18:32:15.740 | INFO | __main__:<module>:12 - 翻译后为:该数据集包含由OpenAI的AI语言模型ChatGPT提供的两个测试样本。这些样本包括一个Markdown表格和一段英文文本,可用于测试支持文本和表格格式的英译中翻译软件。
- 1
- 2
没问题,改为翻译日文再来:
2023-08-04 18:35:33.075 | INFO | __main__:<module>:10 - 提示语为:翻译为日文:This dataset contains two test samples provided by ChatGPT, an AI language model by OpenAI.These samples include a markdown table and an English text passage, which can be used to test anEnglish-to-Chinese translation software supporting both text and table formats.
2023-08-04 18:35:41.328 | INFO | __main__:<module>:12 - 翻译后为:このデータセットには、OpenAIのAI言語モデルChatGPTによって提供された2つのテストサンプルが含まれています。これらのサンプルには、マークダウンテーブルと英文のテキストパッセージが含まれており、テキストとテーブルの形式の両方をサポートする英中翻訳ソフトウェアのテストに使用することができます。
- 1
- 2
实际上也是支持的,这功能就当是让我们测试了,花多点时间在提高准确性上。
翻译准确性提高
先抽取前5页内容翻译看看结果,让AI助手写一个方法处理前5页:
假设你是一名资深的python研发人员,请编写一段代码可以立刻执行的,从一个PDF文件读取前5页内容写入另一个新的PDF文件。请提供相应的完整代码,并附上必要的注释。
- 1
代码有错误,扔回给它继续处理
执行报了这个错误:PyPDF2.errors.DeprecationError: PdfFileReader is deprecated and was removed in PyPDF2 3.0.0. Use PdfReader instead.
请调整代码
- 1
- 2
调整3次后程序正常执行了,并且在tests目录下生成了新的PDF文件first_5_page.pdf
从下面的翻译结果来看,其实效果并不算太差,当然有不通顺和瑕疵的地方:

老师给的代码中,调用OpenAI接口时只是使用了user,没有使用system。因此我们先从这个着手
messages=[
{"role": "user", "content": prompt}
]
- 1
- 2
- 3
借助提供的调试工具playgroud在上面不断优化提示词和角色预设,测试好后再拿到代码中。
# TODO:保存上一次的对话信息提高翻译准确性
{"role": "system", "content": "你是一名文学家,对世界的文学都很有研究。请按要求翻译发送给你的文章原文,翻译前你可以先判断文章是否世界名著,参考已有的一些翻译。请使用简洁通顺的语言输出,不要出现语义不通的情况,多联系上下文。"},
{"role": "user", "content": prompt}
- 1
- 2
- 3

当然为了进一步提高翻译准确性,可考虑把上一次的对话一起带回再调用接口,解决分页后上下文不通顺的情况。但是要考虑是否超限制,这个留待后面迭代。
支持API调用
借助AI助手,不断优化提示语,最终如下:
假设你是一名资深的python研发人员,请使用python编写一个对外提供API的接口,要求如下:接收三个参数,第一个是翻译输出的语言,默认是中文,第二个是翻译输出的文件格式,只能是pdf或者markdown,默认是pdf,第三个是需要翻译的PDF文件;结果输出为翻译后的PDF文件。PDF处理库请使用pdfplumber,接收的PDF文件先保存到本地,文件名不变,然后再调用已写好的翻译方法,请提供相应的完整代码,并附上必要的注释。
- 1
生成的代码默认是调用谷歌翻译的,稍微改下使用现有的翻译接口
from flask import Flask, request, send_file from translator import PDFTranslator from model import GLMModel, OpenAIModel from utils import ArgumentParser, ConfigLoader, LOG app = Flask(__name__) # 定义 API 路由,使用 POST 方法接收文件和请求参数 @app.route('/translate_pdf', methods=['POST']) def translate_pdf(): # 获取语言参数,默认为中文 target_language = request.form.get('language', '中文') # 获取文件格式参数,默认为pdf output_format = request.form.get('format', 'pdf') # 获取上传的 PDF 文件 pdf_file = request.files['file'] print(pdf_file) # 保存上传的文件到本地 uploaded_file_path = 'D:\\github\\openai-translator\\temp\\api_file.pdf' pdf_file.save(uploaded_file_path) # 翻译后的文件保存路径 output_file_path = uploaded_file_path.replace('.pdf', f'_translated.pdf') # 调用已有翻译接口 argument_parser = ArgumentParser() args = argument_parser.parse_arguments() config_loader = ConfigLoader(args.config) config = config_loader.load_config() model_name = config['OpenAIModel']['model'] api_key = config['OpenAIModel']['api_key'] model = OpenAIModel(model=model_name, api_key=api_key) # 实例化 PDFTranslator 类,并调用 translate_pdf() 方法 translator = PDFTranslator(model) translator.translate_pdf(uploaded_file_path, output_format, target_language, output_file_path) # 返回翻译后文件 return send_file(output_file_path) if __name__ == '__main__': app.run()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
把程序跑起来,使用ApiFox调用,功能正常,翻译后的内容也符合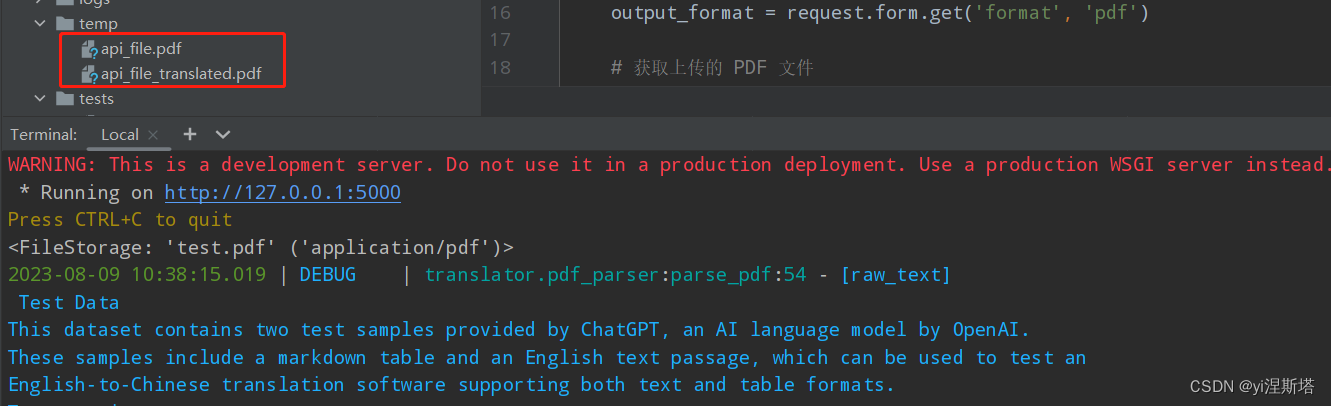
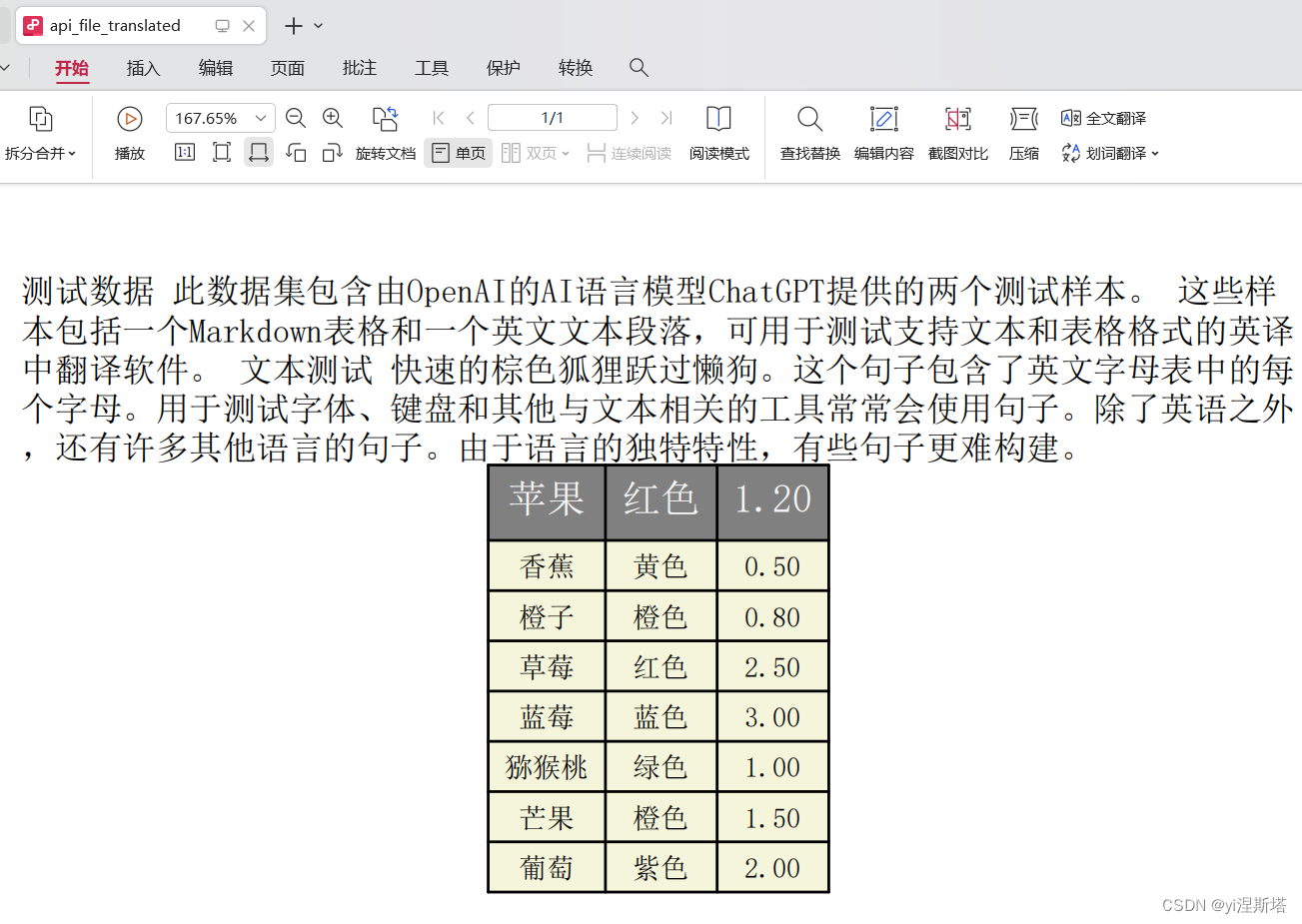
支持GUI图形界面
本来对这块也没了解很多,看了群里同学的推荐,直接使用:streamlit,官方文档:需要魔法
借助AI助手,不断优化提示语,最终如下:
假设你是一名资深的python研发人员,请使用streamlit库完成一个图形界面,要求如下:
1.一个文本框供用户可以输入OpenAI Key,一个文本框供用户输入翻译语言,一个上传文件控件,限制只能上传PDF文件
2.提交前需要校验参数是否完整
3.提交时调用的接口是http://127.0.0.1:5000/translate_pdf,POST方法,OpenAI Key对应的参数是openai_key,翻译语言对应的参数是language,文件控件对应的参数是file
请提供相应的完整代码,并附上必要的注释。
- 1
- 2
- 3
- 4
- 5
安装库后启动:streamlit run .\ai_translator\streamlit_gui.py
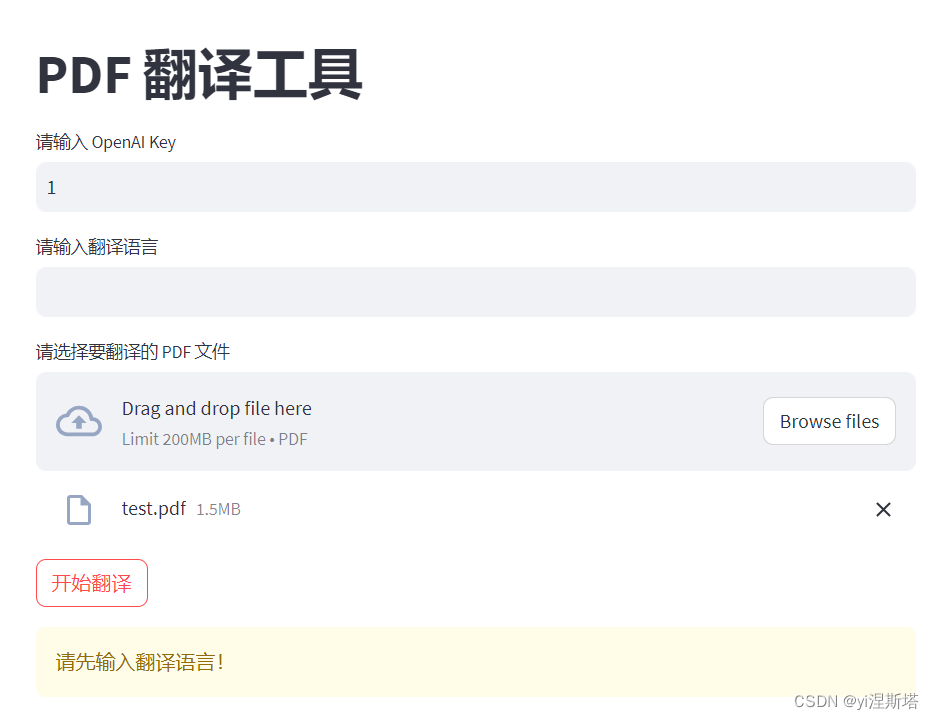
可以看到界面是符合要求并且有相应的提示,最后再把之前的API跑起来调用看看:
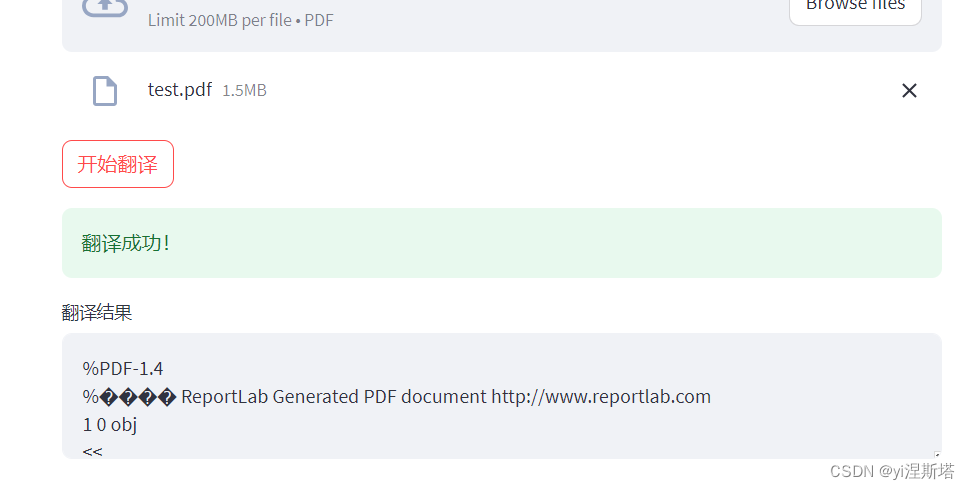
看日志是翻译成功了,因为我之前的API接口是返回文件的,所以界面显示乱码了,这个放到后续优化了。
代码优化
使用下面的提示语把代码一段一段的发给AI助手进行优化:
你是一名资深的python研发人员,我接下来会分段发代码给你,请优化代码的逻辑,并添加上必要的注释,让人更容易地读懂代码。
- 1
过程发现两个比较有趣的现象:
1、一开始能很好地工作,但当我发多几个代码片段后,AI助手变为了解释代码,而不是优化代码和添加注释,需要再重新和它说明才能继续工作
2、把课程老师的一些代码发过去,发现基本是没有改变的,说明老师应该也是用了助手,哈哈
结语
在作业过程中,我取得了很大的收获和成长。通过这个项目,我深入了解了AI大模型的应用和开发流程。
首先,我学会了如何使用GPT-3.5接口来构建一个强大的AI机器人。通过与机器人的交互,我可以进行文本、表格的翻译工作,能大大提高了工作效率。
其次,我学到了一些优化和调试技巧。使用loguru库,我可以轻松记录和跟踪代码中的日志信息,方便排查错误和改进代码。同时,对代码进行优化,比如添加异常处理和检查输入类型,能够提升代码的可靠性和稳定性。最重要是学会通过chatGPT来帮助我完成大部分的工作,学会了怎么更好的和它聊天。
最后,我在这个过程中更加深刻地认识到了人工智能对人类生活和工作的巨大影响。AI大模型的应用潜力无限,不仅可以提高工作效率,还可以拓展人类的想象力和创造力。
总的来说,通过学习和开发OpenAI-Translator,我不仅掌握了实际的应用开发技能,还深入理解了人工智能的前沿技术和发展趋势。这将对我未来的学习和职业发展带来巨大的帮助。我会继续努力深入学习和探索,为人工智能的发展贡献自己的力量。
最后附上自己的作业仓库地址

