
- 1zookeeper使用
- 2【笔记&问题解决】激光雷达和相机外部参数标定全流程(livox_camera_calib加载数据问题解决 [#85 Issue] & PCL无法创建KDTree问题解决 [#19 Issue])_[pcl::kdtreeflann::setinputcloud] cannot create a
- 3CVE-2023-33246 RCE漏洞复现_cve-2023-33246复现
- 4[C++]使用yolov10的onnx模型结合onnxruntime和bytetrack实现目标追踪_yolov10 bytetrack
- 5【Spring】SSM框架整合Spring和SpringMVC
- 6ros安装详细教程+问题解决_ros安装csdn
- 7关于ContentProvider这一遍就够了_contentprovider 机制
- 8Congested Crowd Instance Localization with Dilated Convolutional Swin Transformer
- 9vscode修改了代码,但是源代码控制source control无法及时更新显示修改项
- 10TypeScript 类型系统
【OrangePi AIpro】香橙派 AIpro运行大模型之Stable diffusion与 llama2_香橙派 stable diffusion
赞
踩
前言:
在学生年代,小编用过香橙派4B、树莓派3B、树莓派4B、ROCK Pi4等开发板,每次拿到新开发板的时候,总会迫不及待地装上系统,当做一个小型电脑玩上一波,然后再将一些功能在上面实现或者将算法部署到上面,体验下性能的提升,相信每一个技术爱好者都如此,无论在什么场景下都会追求极致的硬件性能体验,并乐此不疲,就好比爱美的女生总会感叹于衣服不够穿,包包不够用。工作后,小编主要在AIGC领域耕耘,但时常也有关注国内新兴的算力主力军,主要涵盖了车载级应用,桌面级应用,边缘计算设备等。自从苹果发布了M1芯片到近期发布了Vision Pro,小编更关注边缘计算的发展,因为边缘计算才是能够使得AI应用渗透到每一个角落的便捷方式,最近刚好留意到OrangePi AIpro,一个融合了华为技术路线的轻量级AI智能开发板,赶紧拿过来试下,顺便支持下国内的技术发展。
首先回答一个问题:为什么会选择用OrangePi AIpro来跑LLM模型?
1、边缘计算设备将会是AI的主要载体。
2、小编目前从事AICG相关工作,也玩过一段时间的开发板,相关内容会比较熟悉。
3、大语言模型是最近比较火的方向,这与OrangePi AIpro的出现比较契合,同时OrangePi AIpro也是国内目前比较前沿的国产开发板。
一、查看OrangePi AIpro主要信息
这里使用的是官方的ubuntu22.04镜像,这个镜像很方便,基本很多环境都已经预装好,能省去很多配置环境的操作,这点官方做得很细心很到位,后面在运行的时候就知道了。
这里不再重复刷系统的操作,网上一大把,我们来看下系统的关键参数。
1、查看系统发行版本
lsb_release -a
- 1
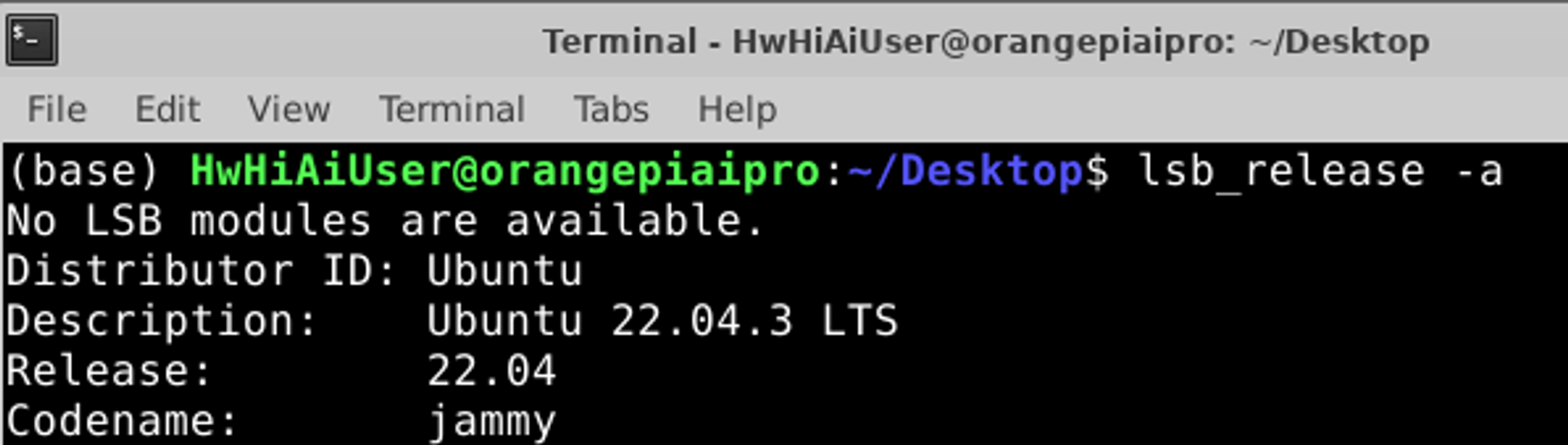
可以看到发行版为Ubuntu 22.04.3
2、查看CPU信息
lsusb
- 1
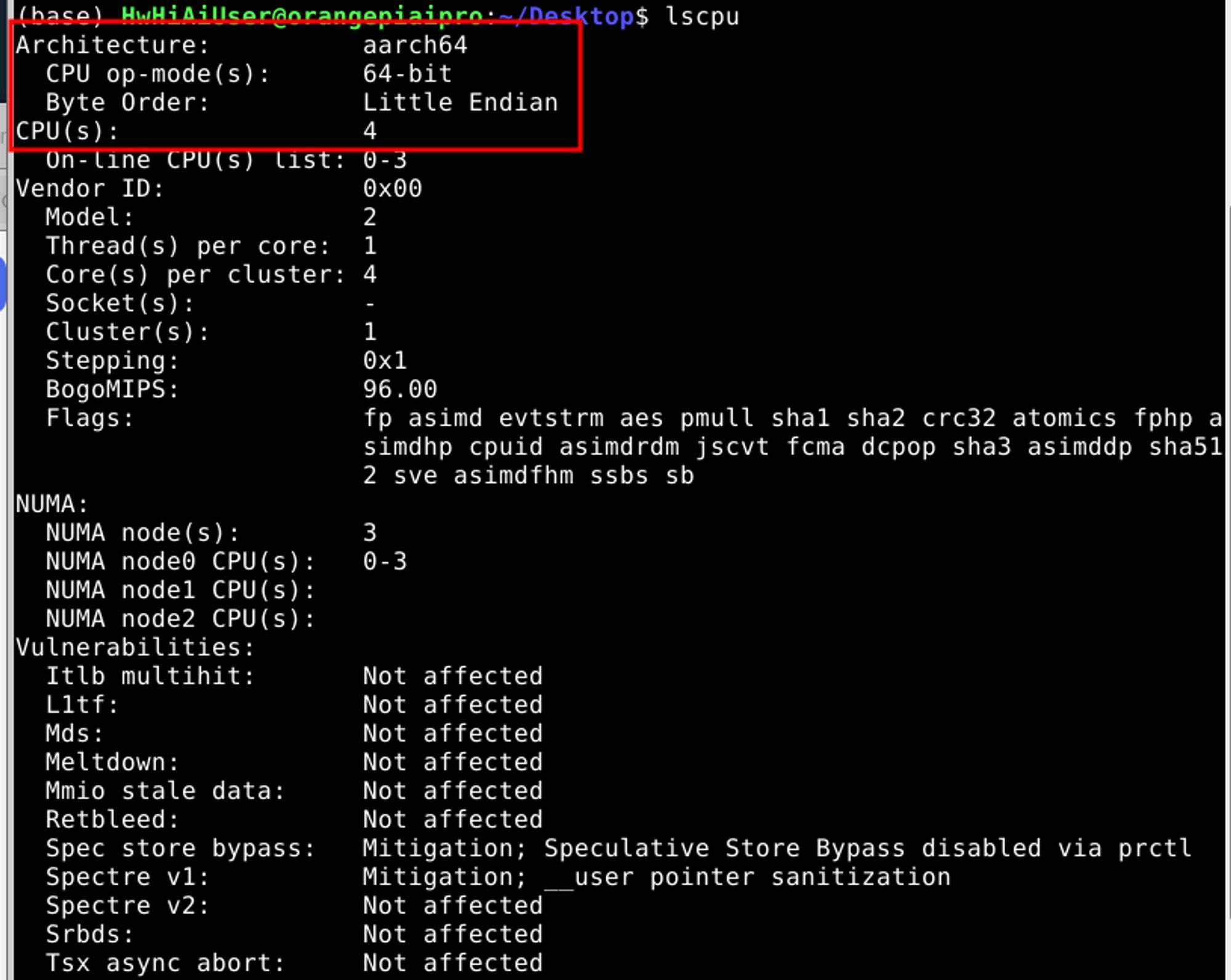
从上面可以看出核心参数:CPU架构为aarch64,64位,4核,小端序
然后我们运行:cat /proc/cpuinfo 也看不到CPU型号是什么。
来看一眼官方提供的Linux源码:
http://www.orangepi.cn/html/hardWare/computerAndMicrocontrollers/service-and-support/Orange-Pi-AIpro.html
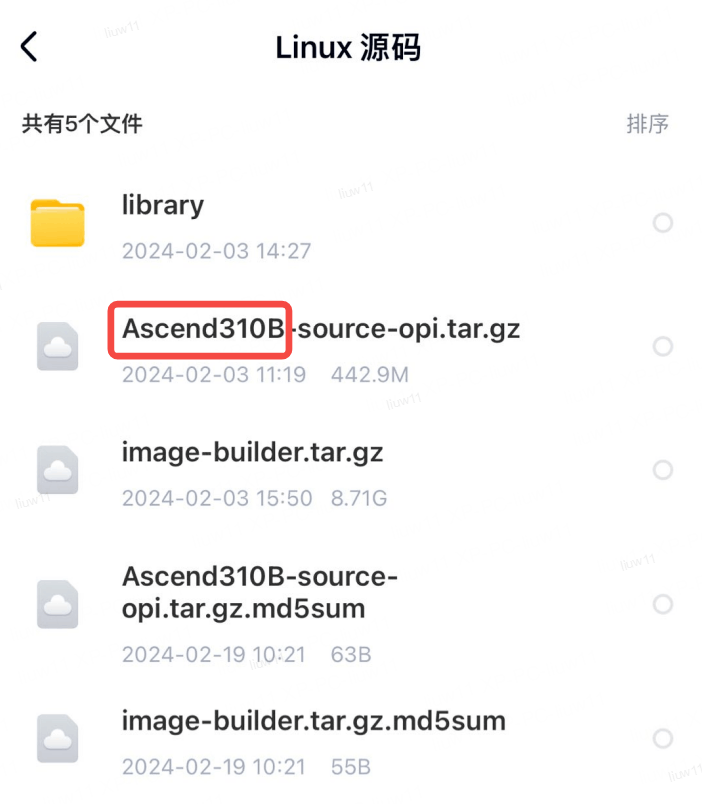
能看出这款OrangePi AIpro使用的芯片为华为昇腾310B,这波隐藏得够深
3、查看npu信息
npu-smi info
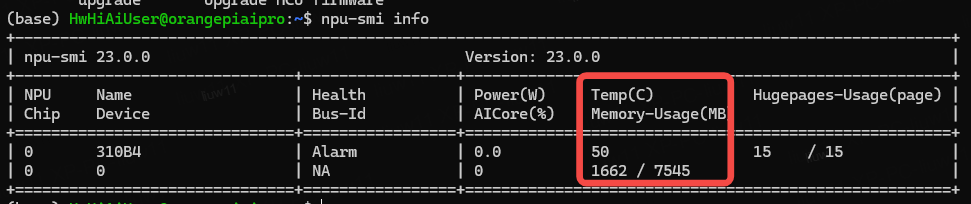
可看到主要参数有两个,就是温度跟内存,上图显示了温度为50°C,内存7545MB,已使用1662MB
二、在OrangePi AIpro上运行 Stable diffusion
小编主要使用NCNN在边缘设备部署模型,所以这里就以NCNN为例来进行,主要还是模型转换比较耗时,暂时没太多时间去折腾,也请允许小编偷懒下,后面小编摸透了华为那套框架,再来给大家“续杯”,补上采用华为框架来进行部署,所以这里主要是验证OrangePi AIpro的通用部署能力,大模型都能跑起来,小模型更不在话下,本文就不验小模型了,也没这个必要。
在这提供了可运行的代码与模型:
链接:https://pan.quark.cn/s/d6c278d66c6b
提取码:jKwt
下载后即可直接“食用”
注:代码与模型主要来源于 https://github.com/EdVince/Stable-Diffusion-NCNN
主要目录如下:

1、环境准备
官方提供的镜像系统已经安装了opencv4.5与cmake 3.22.1,其它主要依赖也都安装了,这里是无痛安装NCNN,回想最开始折腾环境安装NCNN,有种未入门先劝退的感觉,现在的小伙伴是幸运的,安装过程如下:
git clone https://github.com/Tencent/ncnn.git
cd ncnn
mkdir -p build
cd build
cmake ..
make -j$(nproc)
sudo make install # 要输入密码 Mind@123
- 1
- 2
- 3
- 4
- 5
- 6
- 7
编译安装后可以在目录下看到:
将文件复制sd根目录下的ncnn目录下


2、运行
然后在sd根目录下执行编译
cd build
cmake ..
- 1
- 2
进行make
make
- 1
make成功之后可以看到生成可执行文件 stable-diffusion-ncnn
运行stable-diffusion:
./stable-diffusion-ncnn
- 1
运行过程如下:
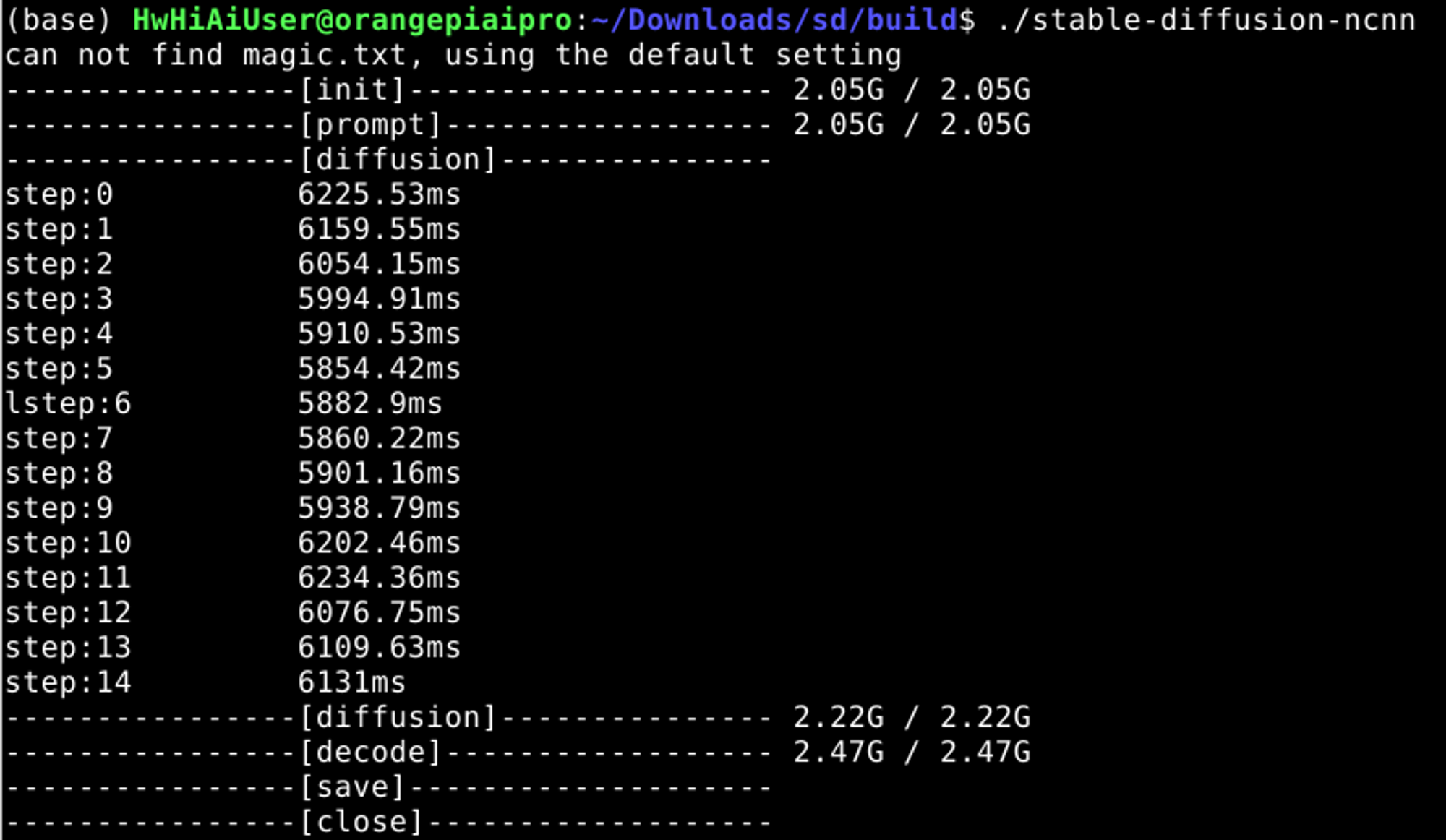
可看到每执行一个采样时间为6s左右,生成一张图的时间为1.5分钟,总体运行速度还可以。
生成的图在build目录下:
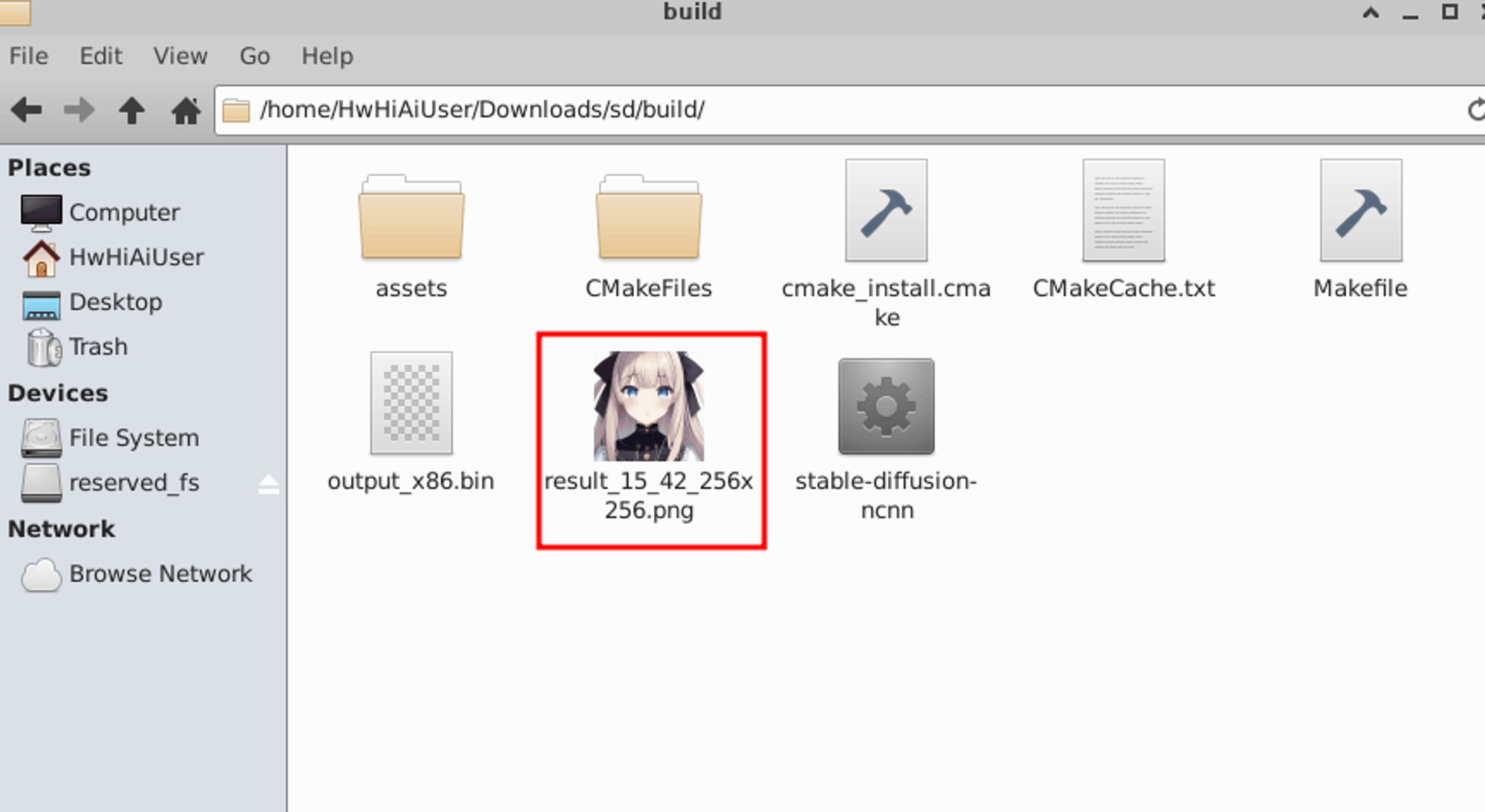
除了编译安装所需的推理框架NCNN之外,整个过程无需做任何环境配置的工作,基本上主要工作都在模型转换,代码编写与运行上,这里不得不说官方的系统镜像很给力,部署方便,整个运行过程丝滑,运行stable diffusion的速度也相对可以。
三、在OrangePi AIpro上运行 Llama2
关于llama2的模型训练可参考:[玩转AIGC]LLaMA2训练中文文章撰写神器(数据准备,数据处理,模型训练,模型推理)
1、下载代码与模型
# 下载代码
git clone https://github.com/karpathy/llama2.c.gitcd llama2.c
# 下载模型
wget https://huggingface.co/karpathy/tinyllamas/resolve/main/stories15M.bin
- 1
- 2
- 3
- 4
2、编译运行
同样是完全不用考虑环境安装的问题,直接编译就能跑
# 编译
make run
# 运行
./run stories15M.bin
- 1
- 2
- 3
- 4
这里运行的是15M的小模型,这是llama2的小模型,当然也可以根据自己需要去修改模型参数,训练一个更大的llama2模型,相关训练方法在上面已经提供了,感兴趣可以看看,然后尝试下多大的llama2模型在OrangePi AIpro上跑,能够有比较合适token输出速度,这就交给感兴趣的你去完成吧。
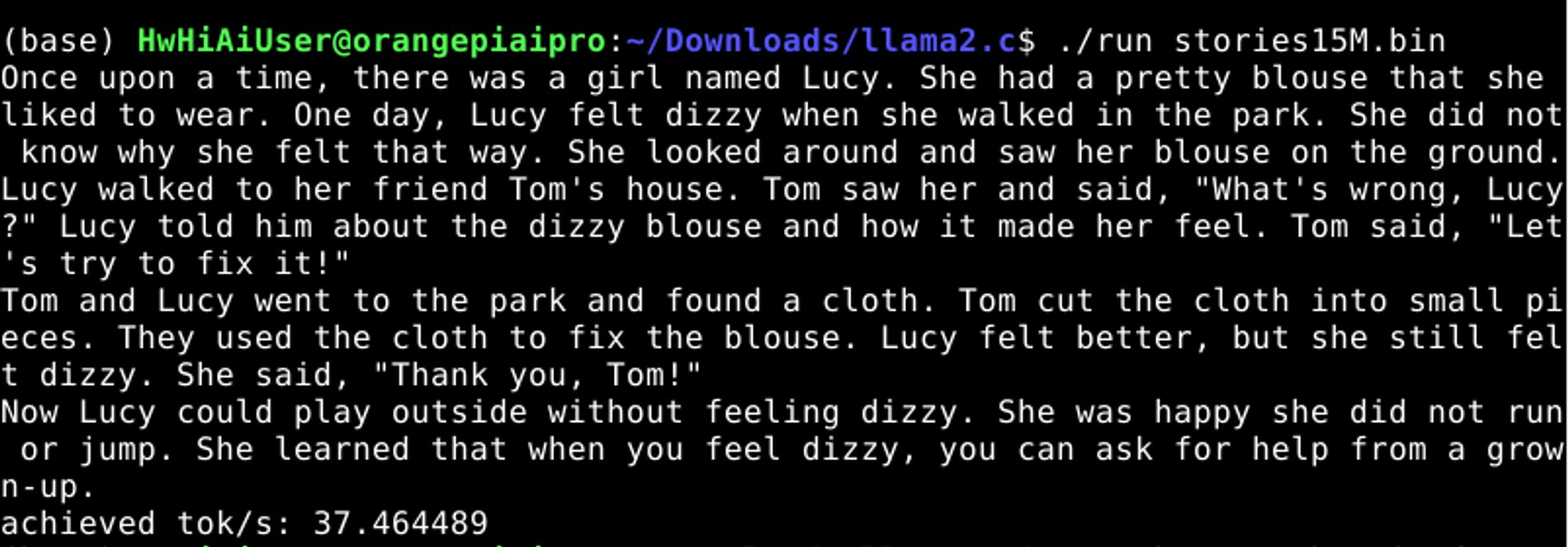
可看到每秒37个token,按照人的说话速度,每分钟180个字左右,这个每秒37个token速度已经算很快了,此时可以适当加大模型参数,这里小编就不去尝试,留给你们去试试,下面直接来跑llama2 7B模型,干点大的。
首先需要将openai官方的模型转换为.bin二进制模型:
注:这个模型转换后太大了,这里就不提供,需要的朋友可自行转换下。
python export.py llama2_7b.bin --meta-llama path/to/llama/model/7B
- 1
下载lama2 的预训练模型,然后转为.bin格式,转完为27GB,因为是用float32格式保存的,所以内存会多出一半,官方原模型是float16,差不多13GB
小编把llama-2-7b.bin放在移动硬盘上,太大了,内存卡放不下,执行以下命令,把模型跑起来
./run /media/HwHiAiUser/HIKSEMI/llama-2-7b.bin
- 1

为了方便得出结果,这里改了下代码,将token生成数改为10,所以跑起来没成文就结束了,如果要生成一小篇文章,那要很久,等不及。
可看到生成速度是每秒 0.010084 个token,这速度虽然很慢,但整个llama2 的7B模型都能跑起来,可见CPU的运行能力还是杠杆的。
结束语:
虽然本文没有使用上华为的推理框架,也没有使用ATC、AMCT模型转换与模型量化工具,但是也能从大模型运行层面上反映出OrangePi AIpro CPU的运行能力。关于ATC、AMCT,这部分感兴趣的人可以尝试下:将上面的通用部署方法转为用昇腾框架加速运行,相信能够得到一个更好的效果,小编也是没时间去做这部分的转换。总之,OrangePi AIpro能够跑起大模型,那么运行一般参数量的算法的能力也是毋庸置疑(比如yolo系列算法,目标检测,图像分割,人脸识别等等),最后呢,也希望OrangePi能够继续在AI上发力,为广发开发者或AI爱好者提供学习AI的便利。

