
热门标签
热门文章
- 1ES9 新特性_eslint9特性
- 2kafka启动 WARN Session 0x0 for server localhost/<unresolved>:2181, unexpected error, closing socket co_unexpected error, closing socket connection and at
- 3字典树/前缀树Trie(附Java代码)_java 字典树
- 4git报错:Pull is not possible because you have unmerged files解决
- 5pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host=files.pythonhosted.org
- 6做个“微信机器人”给指定的好友或者微信群发送消息
- 7RabbitMQ 如何避免消息重复消费?_rabbitmq怎么保证消息不重复消费
- 8自由度的理解_机械臂自由度计算
- 9若依管理系统windows本地运行教程,前端开发好不好学_若依本地开发
- 10软高最好的建议,告诉自己要考就一次性过
当前位置: article > 正文
详解PEFT库中LoRA源码_peft lora核心代码讲解
作者:代码探险家 | 2024-08-10 22:27:18
赞
踩
peft lora核心代码讲解
前言
- GitHub项目地址Some-Paper-CN。本项目是译者在学习长时间序列预测、CV、NLP和机器学习过程中精读的一些论文,并对其进行了中文翻译。还有部分最佳示例教程。
- 如果有帮助到大家,请帮忙点亮Star,也是对译者莫大的鼓励,谢谢啦~
- 本文代码已同步至项目Some-Paper-CN
准备工作
- 从
Github上下载PEFT最新源码,源码地址 - 关键源码在项目文件夹
src/peft下,我们可以在项目文件下新建一个Lora_demo.py文件,用于后期Debug,下面是我写的实例代码,用的Qwen/Qwen2-0.5B-Instruct模型,大家可以用任何自己熟悉的模型。
from pprint import pprint from peft import LoraConfig, get_peft_model from transformers import AutoModelForCausalLM, AutoConfig lora_config = LoraConfig( task_type="CAUSAL_LM", target_modules=[ "q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj", ], inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1, ) config = AutoConfig.from_pretrained("Qwen/Qwen2-0.5B-Instruct") og_model = AutoModelForCausalLM.from_config(config) pprint(og_model) lora_model = get_peft_model(og_model, lora_config) pprint(lora_model) # pprint([key for key, _ in og_model.named_modules()]) # key = 'model.layers.0.self_attn.rotary_emb' # pprint(og_model.get_submodule(".".join(key.split(".")[:-1]))) # pprint(key.split(".")[-1]) # pprint(og_model.get_submodule(key))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
-
后面我注释的是一些在
Debug期间不是很好理解的代码,大家可以先不管,后面到对应的地方后我会提到。 -
可以看到,在上面代码中,最关键的函数是
get_peft_model(),当原始模型经过get_peft_model()函数后,模型结构中就加入了LoRA分支。 -
og_model模型结构
Qwen2ForCausalLM( (model): Qwen2Model( (embed_tokens): Embedding(151936, 896) (layers): ModuleList( (0-23): 24 x Qwen2DecoderLayer( (self_attn): Qwen2SdpaAttention( (q_proj): Linear(in_features=896, out_features=896, bias=True) (k_proj): Linear(in_features=896, out_features=128, bias=True) (v_proj): Linear(in_features=896, out_features=128, bias=True) (o_proj): Linear(in_features=896, out_features=896, bias=False) (rotary_emb): Qwen2RotaryEmbedding() ) (mlp): Qwen2MLP( (gate_proj): Linear(in_features=896, out_features=4864, bias=False) (up_proj): Linear(in_features=896, out_features=4864, bias=False) (down_proj): Linear(in_features=4864, out_features=896, bias=False) (act_fn): SiLU() ) (input_layernorm): Qwen2RMSNorm() (post_attention_layernorm): Qwen2RMSNorm() ) ) (norm): Qwen2RMSNorm() ) (lm_head): Linear(in_features=896, out_features=151936, bias=False) )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
lora_model模型架构
PeftModelForCausalLM( (base_model): LoraModel( (model): Qwen2ForCausalLM( (model): Qwen2Model( (embed_tokens): Embedding(151936, 896) (layers): ModuleList( (0-23): 24 x Qwen2DecoderLayer( (self_attn): Qwen2SdpaAttention( (q_proj): lora.Linear( (base_layer): Linear(in_features=896, out_features=896, bias=True) (lora_dropout): ModuleDict( (default): Dropout(p=0.1, inplace=False) ) (lora_A): ModuleDict( (default): Linear(in_features=896, out_features=8, bias=False) ) (lora_B): ModuleDict( (default): Linear(in_features=8, out_features=896, bias=False) ) (lora_embedding_A): ParameterDict() (lora_embedding_B): ParameterDict() (lora_magnitude_vector): ModuleDict() ) (k_proj): lora.Linear( (base_layer): Linear(in_features=896, out_features=128, bias=True) (lora_dropout): ModuleDict( (default): Dropout(p=0.1, inplace=False) ) (lora_A): ModuleDict( (default): Linear(in_features=896, out_features=8, bias=False) ) (lora_B): ModuleDict( (default): Linear(in_features=8, out_features=128, bias=False) ) (lora_embedding_A): ParameterDict() (lora_embedding_B): ParameterDict() (lora_magnitude_vector): ModuleDict() ) (v_proj): lora.Linear( (base_layer): Linear(in_features=896, out_features=128, bias=True) (lora_dropout): ModuleDict( (default): Dropout(p=0.1, inplace=False) ) (lora_A): ModuleDict( (default): Linear(in_features=896, out_features=8, bias=False) ) (lora_B): ModuleDict( (default): Linear(in_features=8, out_features=128, bias=False) ) (lora_embedding_A): ParameterDict() (lora_embedding_B): ParameterDict() (lora_magnitude_vector): ModuleDict() ) (o_proj): lora.Linear( (base_layer): Linear(in_features=896, out_features=896, bias=False) (lora_dropout): ModuleDict( (default): Dropout(p=0.1, inplace=False) ) (lora_A): ModuleDict( (default): Linear(in_features=896, out_features=8, bias=False) ) (lora_B): ModuleDict( (default): Linear(in_features=8, out_features=896, bias=False) ) (lora_embedding_A): ParameterDict() (lora_embedding_B): ParameterDict() (lora_magnitude_vector): ModuleDict() ) (rotary_emb): Qwen2RotaryEmbedding() ) (mlp): Qwen2MLP( (gate_proj): lora.Linear( (base_layer): Linear(in_features=896, out_features=4864, bias=False) (lora_dropout): ModuleDict( (default): Dropout(p=0.1, inplace=False) ) (lora_A): ModuleDict( (default): Linear(in_features=896, out_features=8, bias=False) ) (lora_B): ModuleDict( (default): Linear(in_features=8, out_features=4864, bias=False) ) (lora_embedding_A): ParameterDict() (lora_embedding_B): ParameterDict() (lora_magnitude_vector): ModuleDict() ) (up_proj): lora.Linear( (base_layer): Linear(in_features=896, out_features=4864, bias=False) (lora_dropout): ModuleDict( (default): Dropout(p=0.1, inplace=False) ) (lora_A): ModuleDict( (default): Linear(in_features=896, out_features=8, bias=False) ) (lora_B): ModuleDict( (default): Linear(in_features=8, out_features=4864, bias=False) ) (lora_embedding_A): ParameterDict() (lora_embedding_B): ParameterDict() (lora_magnitude_vector): ModuleDict() ) (down_proj): lora.Linear( (base_layer): Linear(in_features=4864, out_features=896, bias=False) (lora_dropout): ModuleDict( (default): Dropout(p=0.1, inplace=False) ) (lora_A): ModuleDict( (default): Linear(in_features=4864, out_features=8, bias=False) ) (lora_B): ModuleDict( (default): Linear(in_features=8, out_features=896, bias=False) ) (lora_embedding_A): ParameterDict() (lora_embedding_B): ParameterDict() (lora_magnitude_vector): ModuleDict() ) (act_fn): SiLU() ) (input_layernorm): Qwen2RMSNorm() (post_attention_layernorm): Qwen2RMSNorm() ) ) (norm): Qwen2RMSNorm() ) (lm_head): Linear(in_features=896, out_features=151936, bias=False) ) ) )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 可以发现,
lora_model对比og_model架构,多了很多以lora为前缀的层,如lora_A,lora_B,lora_embedding_A,lora_embedding_B,那这些层是如何通过函数添加上的呢?按住Ctrl单机get_peft_model()查看底层源码。
源码详解
-
因为一些代码规范的关系,
PEFT内部的源码封装的非常厉害,在解析源码的时候要耐心一点,慢慢看,层级关系也千万要理清楚。 -
进入
get_peft_model函数,跳转到了peft/mapping.py文件,部分注释如下:
def get_peft_model( model: PreTrainedModel, peft_config: PeftConfig, adapter_name: str = "default", mixed: bool = False, autocast_adapter_dtype: bool = True, revision: Optional[str] = None, ) -> PeftModel | PeftMixedModel: # 读取模型参数文件 model_config = getattr(model, "config", {"model_type": "custom"}) # 将模型参数转换为dict格式 if hasattr(model_config, "to_dict"): model_config = model_config.to_dict() # 读取微调配置 peft_config.base_model_name_or_path = model.__dict__.get("name_or_path", None) if revision is not None: if peft_config.revision is not None and peft_config.revision != revision: warnings.warn( f"peft config has already set base model revision to {peft_config.revision}, overwriting with revision {revision}" ) peft_config.revision = revision if mixed: # note: PeftMixedModel does not support autocast_adapter_dtype, so don't pass it return PeftMixedModel(model, peft_config, adapter_name=adapter_name) # 判断任务类型,以便进入对应的微调类 if peft_config.task_type not in MODEL_TYPE_TO_PEFT_MODEL_MAPPING.keys() and not peft_config.is_prompt_learning: return PeftModel(model, peft_config, adapter_name=adapter_name, autocast_adapter_dtype=autocast_adapter_dtype) if peft_config.is_prompt_learning: peft_config = _prepare_prompt_learning_config(peft_config, model_config) return MODEL_TYPE_TO_PEFT_MODEL_MAPPING[peft_config.task_type]( model, peft_config, adapter_name=adapter_name, autocast_adapter_dtype=autocast_adapter_dtype )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 不难发现
get_peft_model()函数的作用是判断当前模型的任务类型,以便进入对应的微调类。在前面的lora_demo.py文件中,lora_config的参数task_type规定了模型类型为CAUSAL_LM因果语言模型,进入MODEL_TYPE_TO_PEFT_MODEL_MAPPING中
MODEL_TYPE_TO_PEFT_MODEL_MAPPING: dict[str, type[PeftModel]] = {
"SEQ_CLS": PeftModelForSequenceClassification,
"SEQ_2_SEQ_LM": PeftModelForSeq2SeqLM,
"CAUSAL_LM": PeftModelForCausalLM,
"TOKEN_CLS": PeftModelForTokenClassification,
"QUESTION_ANS": PeftModelForQuestionAnswering,
"FEATURE_EXTRACTION": PeftModelForFeatureExtraction,
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
CAUSAL_LM对应的是PeftModelForCausalLM类,那我们继续进入PeftModelForCausalLM类- 跳转到
peft/peft_model.py文件,发现PeftModelForCausalLM类继承自PeftModel类,进入PeftModel类,我们主要关注PeftModel类的初始化方法,部分注释如下:
class PeftModel(PushToHubMixin, torch.nn.Module): def __init__( self, model: PreTrainedModel, peft_config: PeftConfig, adapter_name: str = "default", autocast_adapter_dtype: bool = True, ) -> None: super().__init__() self.modules_to_save = None self.active_adapter = adapter_name # 获取微调方法 self.peft_type = peft_config.peft_type # These args are special PEFT arguments that users can pass. They need to be removed before passing them to # forward. self.special_peft_forward_args = {"adapter_names"} # 判断是否为提示词学习方法 self._is_prompt_learning = peft_config.is_prompt_learning if self._is_prompt_learning: self._peft_config = {adapter_name: peft_config} self.base_model = model self.add_adapter(adapter_name, peft_config) else: self._peft_config = None # 获取微调方法类 cls = PEFT_TYPE_TO_MODEL_MAPPING[peft_config.peft_type] # 实例化微调方法类 self.base_model = cls(model, {adapter_name: peft_config}, adapter_name) self.set_additional_trainable_modules(peft_config, adapter_name) if hasattr(self.base_model, "_cast_adapter_dtype"): self.base_model._cast_adapter_dtype( adapter_name=adapter_name, autocast_adapter_dtype=autocast_adapter_dtype ) if getattr(model, "is_gradient_checkpointing", True): model = self._prepare_model_for_gradient_checkpointing(model) # the `pretraining_tp` is set for some models to simulate Tensor Parallelism during inference to avoid # numerical differences, https://github.com/pytorch/pytorch/issues/76232 - to avoid any unexpected # behavior we disable that in this line. if hasattr(self.base_model, "config") and hasattr(self.base_model.config, "pretraining_tp"): self.base_model.config.pretraining_tp = 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
PeftModel类的作用是实例化对应的微调方法类,需要注意的是LoRA微调方法不属于提示词学习方法,要注意if self._is_prompt_learning判断结果,应该走else分支- 进入
PEFT_TYPE_TO_MODEL_MAPPING
PEFT_TYPE_TO_MODEL_MAPPING = { PeftType.LORA: LoraModel, PeftType.LOHA: LoHaModel, PeftType.LOKR: LoKrModel, PeftType.PROMPT_TUNING: PromptEmbedding, PeftType.P_TUNING: PromptEncoder, PeftType.PREFIX_TUNING: PrefixEncoder, PeftType.ADALORA: AdaLoraModel, PeftType.BOFT: BOFTModel, PeftType.ADAPTION_PROMPT: AdaptionPromptModel, PeftType.IA3: IA3Model, PeftType.OFT: OFTModel, PeftType.POLY: PolyModel, PeftType.LN_TUNING: LNTuningModel, PeftType.VERA: VeraModel, }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
LoRA微调方法对应LoraModel类,进入LoraModel类,跳转到peft/tuners/lora/model.py文件,发现LoraModel类继承自BaseTuner类,那我们继续进入BaseTuner类,跳转到peft/tuners/tuners_utils.py文件。- 还是重点关注
BaseTuner类的初始化方法,部分注释如下:
class BaseTuner(nn.Module, ABC): def __init__(self, model, peft_config: Union[PeftConfig, dict[str, PeftConfig]], adapter_name: str) -> None: super().__init__() self.model = model self.targeted_module_names: list[str] = [] # For advanced developers, if you want to attach multiple adapters to your # model, just add a `peft_config` dict attribute to your model. if not hasattr(self, "peft_config"): self.peft_config = {adapter_name: peft_config} if isinstance(peft_config, PeftConfig) else peft_config else: logger.info( "Already found a `peft_config` attribute in the model. This will lead to having multiple adapters" " in the model. Make sure to know what you are doing!" ) if isinstance(peft_config, PeftConfig): self.peft_config[adapter_name] = peft_config else: # user is adding a dict of PeftConfigs self.peft_config.update(peft_config) self.active_adapter: str | list[str] = adapter_name self._pre_injection_hook(self.model, self.peft_config[adapter_name], adapter_name) # 插入Adapter模块 self.inject_adapter(self.model, adapter_name) # Copy the peft_config in the injected model. self.model.peft_config = self.peft_config
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 上面初始化方法有一些指标记录和信息输出的代码,最关键的函数是
inject_adapter(),即插入Adapter模块,进入inject_adapter()函数中 inject_adapter()函数仍然在peft/tuners/tuners_utils.py文件中,部分注释如下
def inject_adapter(self, model: nn.Module, adapter_name: str, autocast_adapter_dtype: bool = True) -> None: # 读取配置文件 peft_config = self.peft_config[adapter_name] self._check_new_adapter_config(peft_config) _check_for_modules_to_save = getattr(peft_config, "modules_to_save", None) is not None _has_modules_to_save = False model_config = getattr(model, "config", {"model_type": "custom"}) if hasattr(model_config, "to_dict"): model_config = model_config.to_dict() peft_config = self._prepare_adapter_config(peft_config, model_config) self._prepare_model(peft_config, model) is_target_modules_in_base_model = False # 存储模型每一层的名字 key_list = [key for key, _ in model.named_modules()] # update peft_config.target_modules if required peft_config = _maybe_include_all_linear_layers(peft_config, model) for key in key_list: # Check for modules_to_save in case if _check_for_modules_to_save and any( key.endswith(f"{module_to_save}") for module_to_save in peft_config.modules_to_save ): # Optionally set the modules to save parent, target, target_name = _get_submodules(model, key) if not isinstance(target, ModulesToSaveWrapper): new_module = ModulesToSaveWrapper(target, adapter_name) setattr(parent, target_name, new_module) else: target.update(adapter_name) _has_modules_to_save = True continue if not self._check_target_module_exists(peft_config, key): continue self.targeted_module_names.append(key) is_target_modules_in_base_model = True # 获取当前层的父模块类,层名,层名对应的模块类 parent, target, target_name = _get_submodules(model, key) # 创建层替代原本的层 self._create_and_replace(peft_config, adapter_name, target, target_name, parent, current_key=key) if not is_target_modules_in_base_model: raise ValueError( f"Target modules {peft_config.target_modules} not found in the base model. " f"Please check the target modules and try again." ) self.set_adapter(self.active_adapters) self._mark_only_adapters_as_trainable(model) if self.peft_config[adapter_name].inference_mode: for n, p in model.named_parameters(): if adapter_name in n: p.requires_grad = False if _has_modules_to_save: if not hasattr(model, "modules_to_save"): model.modules_to_save = set(peft_config.modules_to_save) else: model.modules_to_save.update(set(peft_config.modules_to_save))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
inject_adapter()函数的关键行为是用key_list存储了模型每一层的名字,可以在前面我们写的lora_demo.py文件中打印出来。
pprint([key for key, _ in og_model.named_modules()])
- 1
输出如下,因为后面都是重复的模块,这里只截取了第0个模块的各个层
['', 'model', 'model.embed_tokens', 'model.layers', 'model.layers.0', 'model.layers.0.self_attn', 'model.layers.0.self_attn.q_proj', 'model.layers.0.self_attn.k_proj', 'model.layers.0.self_attn.v_proj', 'model.layers.0.self_attn.o_proj', 'model.layers.0.self_attn.rotary_emb', 'model.layers.0.mlp', 'model.layers.0.mlp.gate_proj', 'model.layers.0.mlp.up_proj', 'model.layers.0.mlp.down_proj', 'model.layers.0.mlp.act_fn', 'model.layers.0.input_layernorm', 'model.layers.0.post_attention_layernorm', ...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 接着通过遍历
key_list获取当前层的父模块类,层名,层名对应的模块类。比较重要的函数是_get_submodules(),点击_get_submodules()函数,跳转到peft/utils/other.py文件,看看是如何实现的。
def _get_submodules(model, key):
parent = model.get_submodule(".".join(key.split(".")[:-1]))
target_name = key.split(".")[-1]
target = model.get_submodule(key)
return parent, target, target_name
- 1
- 2
- 3
- 4
- 5
- 这个函数可以在前面我们写的
lora_demo.py文件中打印出来。随便选一个key,比如model.layers.0.self_attn.rotary_emb
key = 'model.layers.0.self_attn.rotary_emb'
pprint(og_model.get_submodule(".".join(key.split(".")[:-1])))
pprint(key.split(".")[-1])
pprint(og_model.get_submodule(key))
- 1
- 2
- 3
- 4
得到的输出如下:
"""
key = model.layers.0.self_attn.rotary_emb
parent = Qwen2SdpaAttention(
(q_proj): Linear(in_features=896, out_features=896, bias=True)
(k_proj): Linear(in_features=896, out_features=128, bias=True)
(v_proj): Linear(in_features=896, out_features=128, bias=True)
(o_proj): Linear(in_features=896, out_features=896, bias=False)
(rotary_emb): Qwen2RotaryEmbedding()
)
target_name = 'rotary_emb'
target = Qwen2RotaryEmbedding()
"""
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 我们回到
peft/tuners/tuners_utils.py文件中,继续看inject_adapter()函数,另一个关键函数是_create_and_replace()函数,我们点击_create_and_replace()函数,其与inject_adapter()函数在一个文件中,但是_create_and_replace()函数是一个抽象函数,我们需要回到peft/tuners/lora/model.py文件,LoraModel类中搜索_create_and_replace()函数查看具体实现。
def _create_and_replace( self, lora_config, adapter_name, target, target_name, parent, current_key, ): if current_key is None: raise ValueError("Current Key shouldn't be `None`") # Regexp 匹配 - 在提供的模式中查找与当前目标名称匹配的键值 pattern_keys = list(chain(lora_config.rank_pattern.keys(), lora_config.alpha_pattern.keys())) target_name_key = next(filter(lambda key: re.match(rf".*\.{key}$", current_key), pattern_keys), current_key) # 获取r和alpha参数 r = lora_config.rank_pattern.get(target_name_key, lora_config.r) alpha = lora_config.alpha_pattern.get(target_name_key, lora_config.lora_alpha) kwargs = { "r": r, "lora_alpha": alpha, "lora_dropout": lora_config.lora_dropout, "fan_in_fan_out": lora_config.fan_in_fan_out, "init_lora_weights": lora_config.init_lora_weights, "use_rslora": lora_config.use_rslora, "use_dora": lora_config.use_dora, "loaded_in_8bit": getattr(self.model, "is_loaded_in_8bit", False), "loaded_in_4bit": getattr(self.model, "is_loaded_in_4bit", False), } quant_methods = ["gptq", "aqlm", "awq"] for quant_method in quant_methods: quantization_config = get_quantization_config(self.model, method=quant_method) if quantization_config is not None: kwargs[f"{quant_method}_quantization_config"] = quantization_config # note: AdaLoraLayer is a subclass of LoraLayer, we need to exclude it from peft.tuners.adalora import AdaLoraLayer # 当前传入的模型还是原始的基于nn.module的模型,所以不属于LoraLayer或Adaloralayer # 应该走else if isinstance(target, LoraLayer) and not isinstance(target, AdaLoraLayer): target.update_layer( adapter_name, r, lora_alpha=alpha, lora_dropout=lora_config.lora_dropout, init_lora_weights=lora_config.init_lora_weights, use_rslora=lora_config.use_rslora, use_dora=lora_config.use_dora, ) else: # 根据LoRA关键参数创建新的模型 new_module = self._create_new_module(lora_config, adapter_name, target, **kwargs) if adapter_name not in self.active_adapters: # adding an additional adapter: it is not automatically trainable new_module.requires_grad_(False) self._replace_module(parent, target_name, new_module, target)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
_create_and_replace()函数在获取了LoRA微调的关键参数r和alpha后,使用_create_new_module()函数创建新的模型架构。- 需要注意的是,现在传入该函数的模型是原始的,基于
torch.nn.module的模型,不属于LoraLayer或者AdaLoraLayer类型,应该要走下面的else分支。 - 进入
_create_new_module()函数,与_create_and_replace()函数在同一文件下,
def _create_new_module(lora_config, adapter_name, target, **kwargs): dispatchers = [] if lora_config._custom_modules: def dynamic_dispatch_func(target, adapter_name, lora_config, **kwargs): new_module = None if isinstance(target, BaseTunerLayer): target_base_layer = target.get_base_layer() else: target_base_layer = target for key, custom_cls in lora_config._custom_modules.items(): if isinstance(target_base_layer, key): new_module = custom_cls(target, adapter_name, **kwargs) break return new_module dispatchers.append(dynamic_dispatch_func) # avoid eager bnb import if is_bnb_available(): from .bnb import dispatch_bnb_8bit dispatchers.append(dispatch_bnb_8bit) if is_bnb_4bit_available(): from .bnb import dispatch_bnb_4bit dispatchers.append(dispatch_bnb_4bit) dispatchers.extend( [ dispatch_eetq, dispatch_aqlm, dispatch_awq, dispatch_gptq, dispatch_hqq, dispatch_megatron, dispatch_default, ] ) new_module = None for dispatcher in dispatchers: new_module = dispatcher(target, adapter_name, lora_config=lora_config, **kwargs) if new_module is not None: # first match wins break if new_module is None: # no module could be matched raise ValueError( f"Target module {target} is not supported. Currently, only the following modules are supported: " "`torch.nn.Linear`, `torch.nn.Embedding`, `torch.nn.Conv2d`, `transformers.pytorch_utils.Conv1D`." ) return new_module
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 上面函数提到的
awq、gptq、hqq都是不同的模型量化或部署格式,一般我们微调选择的都是非量化版本,所以最后都会走dispatch_default分支,但是我们也可以看看其他的分支,这里以dispatch_eetq()函数为例,点击跳转到peft/tuners/lora/eetq.py文件
def dispatch_eetq( target: torch.nn.Module, adapter_name: str, **kwargs: Any, ) -> Optional[torch.nn.Module]: new_module = None if isinstance(target, BaseTunerLayer): target_base_layer = target.get_base_layer() else: target_base_layer = target if is_eetq_available() and isinstance(target_base_layer, EetqLinear): new_module = EetqLoraLinear(target, adapter_name, **kwargs) target.weight = target_base_layer.weight if hasattr(target, "bias"): target.bias = target_base_layer.bias return new_module
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 函数先初始化了
new_module为None,但是由于is_eetq_available()和isinstance(target_base_layer, EetqLinear)均为False,最后的new_module仍然为None - 回到
peft/tuners/lora/model.py文件下的_create_new_module()函数,点击dispatch_default,跳转到peft/tuners/lora/layer.py文件下的dispatch_default()函数,部分注释如下。
def dispatch_default( target: torch.nn.Module, adapter_name: str, lora_config: LoraConfig, **kwargs, ) -> Optional[torch.nn.Module]: new_module = None if isinstance(target, BaseTunerLayer): target_base_layer = target.get_base_layer() else: target_base_layer = target # 更新Embedding层 if isinstance(target_base_layer, torch.nn.Embedding): embedding_kwargs = kwargs.copy() embedding_kwargs.pop("fan_in_fan_out", None) embedding_kwargs.update(lora_config.loftq_config) new_module = Embedding(target, adapter_name, **embedding_kwargs) # 更新Conv2d层 elif isinstance(target_base_layer, torch.nn.Conv2d): kwargs.update(lora_config.loftq_config) new_module = Conv2d(target, adapter_name, **kwargs) # 更新Linear层 elif isinstance(target_base_layer, torch.nn.Linear): if kwargs["fan_in_fan_out"]: warnings.warn( "fan_in_fan_out is set to True but the target module is `torch.nn.Linear`. " "Setting fan_in_fan_out to False." ) kwargs["fan_in_fan_out"] = lora_config.fan_in_fan_out = False kwargs.update(lora_config.loftq_config) new_module = Linear(target, adapter_name, **kwargs) # 更新Conv1D层 elif isinstance(target_base_layer, Conv1D): if not kwargs["fan_in_fan_out"]: warnings.warn( "fan_in_fan_out is set to False but the target module is `Conv1D`. " "Setting fan_in_fan_out to True." ) kwargs["fan_in_fan_out"] = lora_config.fan_in_fan_out = True kwargs.update(lora_config.loftq_config) new_module = Linear(target, adapter_name, is_target_conv_1d_layer=True, **kwargs) return new_module
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 可以看到
LoRA微调方法主要是针对Embedding、Conv1D、Conv2D、Linear层,这里我们以Linear为例进行讲解。 - 进入
isinstance(target_base_layer, torch.nn.Linear)分支下的new_module = Linear(target, adapter_name, **kwargs),点击Linear,Linear类与dispatch_default()函数处于同一文件。
class Linear(nn.Module, LoraLayer): def __init__( self, base_layer, adapter_name: str, r: int = 0, lora_alpha: int = 1, lora_dropout: float = 0.0, fan_in_fan_out: bool = False, is_target_conv_1d_layer: bool = False, init_lora_weights: Union[bool, str] = True, use_rslora: bool = False, use_dora: bool = False, **kwargs, ) -> None: super().__init__() LoraLayer.__init__(self, base_layer, **kwargs) self.fan_in_fan_out = fan_in_fan_out self._active_adapter = adapter_name self.update_layer( adapter_name, r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, init_lora_weights=init_lora_weights, use_rslora=use_rslora, use_dora=use_dora, ) self.is_target_conv_1d_layer = is_target_conv_1d_layer
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 可以看到
Linear类除了继承nn.Module类,还继承了LoraLayer类,我们先看LoraLayer类,点击进入与Linear类同一文件的LoraLayer类,主要关注LoraLayer类的初始化方法
class LoraLayer(BaseTunerLayer): adapter_layer_names = ("lora_A", "lora_B", "lora_embedding_A", "lora_embedding_B") other_param_names = ("r", "lora_alpha", "scaling", "lora_dropout") def __init__(self, base_layer: nn.Module, **kwargs) -> None: self.base_layer = base_layer self.r = {} self.lora_alpha = {} self.scaling = {} self.lora_dropout = nn.ModuleDict({}) self.lora_A = nn.ModuleDict({}) self.lora_B = nn.ModuleDict({}) self.lora_embedding_A = nn.ParameterDict({}) self.lora_embedding_B = nn.ParameterDict({}) self._disable_adapters = False self.merged_adapters = [] self.use_dora: dict[str, bool] = {} self.lora_magnitude_vector = torch.nn.ModuleDict() # for DoRA self._caches: dict[str, Any] = {} self.kwargs = kwargs base_layer = self.get_base_layer() # 获取输入输出维度 if isinstance(base_layer, nn.Linear): in_features, out_features = base_layer.in_features, base_layer.out_features elif isinstance(base_layer, nn.Conv2d): in_features, out_features = base_layer.in_channels, base_layer.out_channels elif isinstance(base_layer, nn.Embedding): in_features, out_features = base_layer.num_embeddings, base_layer.embedding_dim elif isinstance(base_layer, Conv1D): in_features, out_features = ( base_layer.weight.ds_shape if hasattr(base_layer.weight, "ds_shape") else base_layer.weight.shape ) elif hasattr(base_layer, "infeatures") and hasattr(base_layer, "outfeatures"): in_features, out_features = base_layer.infeatures, base_layer.outfeatures elif hasattr(base_layer, "input_size") and hasattr(base_layer, "output_size"): in_features, out_features = base_layer.input_size, base_layer.output_size elif hasattr(base_layer, "codebooks") and base_layer.__class__.__name__ == "QuantizedLinear": in_features, out_features = base_layer.in_features, base_layer.out_features elif hasattr(base_layer, "w_bit") and base_layer.__class__.__name__ == "WQLinear_GEMM": in_features, out_features = base_layer.in_features, base_layer.out_features elif base_layer.__class__.__name__ == "EetqLinear": in_features, out_features = base_layer.in_features, base_layer.out_features elif hasattr(base_layer, "W_q") and base_layer.__class__.__name__ == "HQQLinear": in_features, out_features = base_layer.in_features, base_layer.out_features else: if hasattr(base_layer, "in_features") and hasattr(base_layer, "out_features"): in_features, out_features = base_layer.in_features, base_layer.out_features else: in_features, out_features = None, None warnings.warn( f"Unsupported layer type '{type(base_layer)}' encountered, proceed at your own risk.", UserWarning ) self.in_features = in_features self.out_features = out_features
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
LoraLayer类的初始化方法关键行为在于获取可调节层(Embedding、Conv1D、Conv2D、Linear)的输入输出维度,方便构造新的层。- 我们回到
Linear类中,Linear类的初始化中另外一个关键方法是update_layer(),点击进入update_layer()函数中。 - 到这里我终于可以把
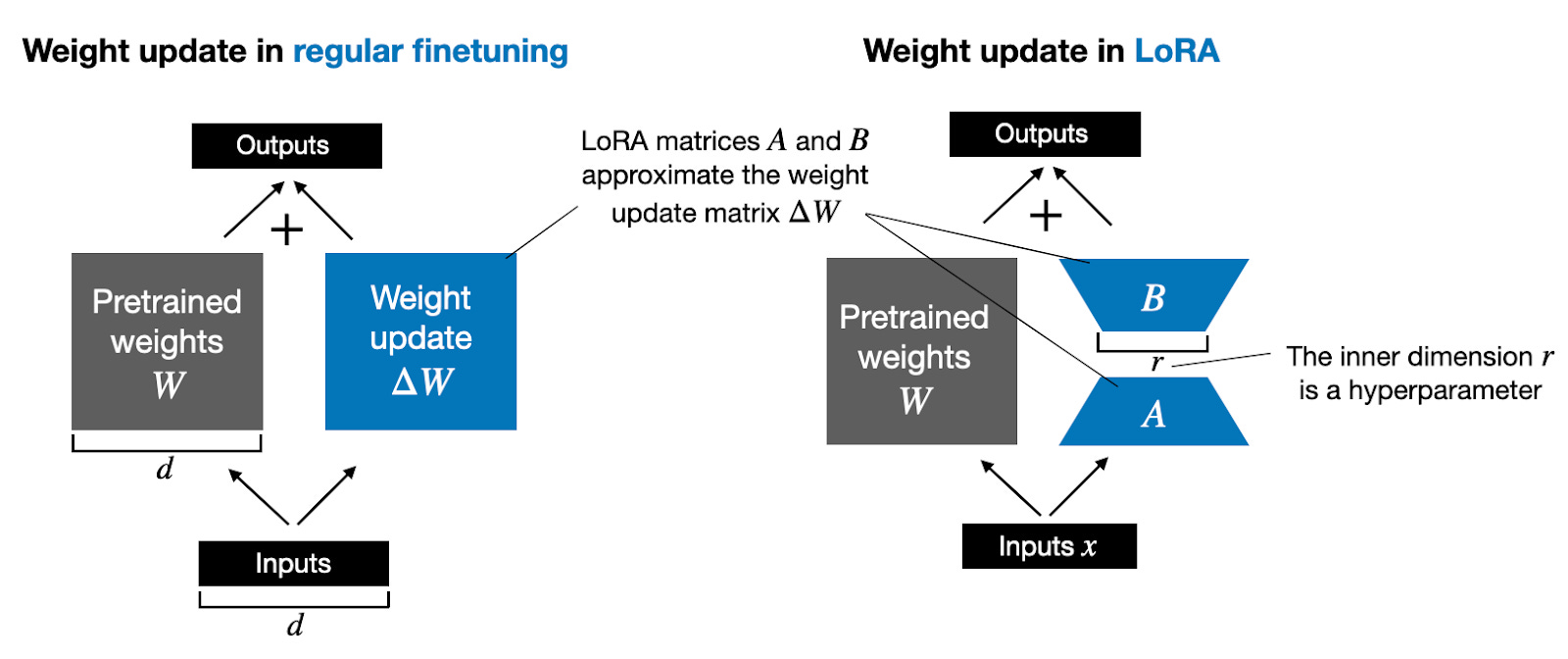
LoRA微调方法的经典原理图放上来了。
def update_layer( self, adapter_name, r, lora_alpha, lora_dropout, init_lora_weights, use_rslora, use_dora: bool = False ): # This code works for linear layers, override for other layer types if r <= 0: raise ValueError(f"`r` should be a positive integer value but the value passed is {r}") # 读取r、alpha参数 self.r[adapter_name] = r self.lora_alpha[adapter_name] = lora_alpha # 如果存在dropout参数则加入Dropout层 if lora_dropout > 0.0: lora_dropout_layer = nn.Dropout(p=lora_dropout) else: lora_dropout_layer = nn.Identity() # 在lora_dropout中加入lora_dropout_layer self.lora_dropout.update(nn.ModuleDict({adapter_name: lora_dropout_layer})) # 实际可训练参数,矩阵A,B self.lora_A[adapter_name] = nn.Linear(self.in_features, r, bias=False) self.lora_B[adapter_name] = nn.Linear(r, self.out_features, bias=False) if use_rslora: self.scaling[adapter_name] = lora_alpha / math.sqrt(r) else: self.scaling[adapter_name] = lora_alpha / r # for inits that require access to the base weight, use gather_param_ctx so that the weight is gathered when using DeepSpeed if isinstance(init_lora_weights, str) and init_lora_weights.startswith("pissa"): with gather_params_ctx(self.get_base_layer().weight): self.pissa_init(adapter_name, init_lora_weights) elif isinstance(init_lora_weights, str) and init_lora_weights.lower() == "olora": with gather_params_ctx(self.get_base_layer().weight): self.olora_init(adapter_name) elif init_lora_weights == "loftq": with gather_params_ctx(self.get_base_layer().weight): self.loftq_init(adapter_name) elif init_lora_weights: self.reset_lora_parameters(adapter_name, init_lora_weights) # call this before dora_init self._move_adapter_to_device_of_base_layer(adapter_name) if use_dora: self.dora_init(adapter_name) self.use_dora[adapter_name] = True else: self.use_dora[adapter_name] = False # 设置可训练参数 self.set_adapter(self.active_adapters)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
update_layer()方法的关键行为有:- 1、读取
LoRA关键参数r、alpha - 2、根据
Dropout参数判断是否加入Dropout层 - 3、创建
lora_A、lora_B线性层,并进行初始化。lora_A的初始化有多种方式,lora_B的初始值均为0,这样lora分支的值在没开始训练之前为0,不改变原模型权重值。 - 设置
lora分支为可训练参数,冻结其它层
- 1、读取
lora_A层的初始化方法可以在reset_lora_parameters()方法中找到,部分注释如下
def reset_lora_parameters(self, adapter_name, init_lora_weights): if init_lora_weights is False: return if adapter_name in self.lora_A.keys(): # 若init_lora_weights为true则使用kaiming初始化 if init_lora_weights is True: nn.init.kaiming_uniform_(self.lora_A[adapter_name].weight, a=math.sqrt(5)) # 如果为gaussian则进行正态初始化 elif init_lora_weights.lower() == "gaussian": nn.init.normal_(self.lora_A[adapter_name].weight, std=1 / self.r[adapter_name]) else: raise ValueError(f"Unknown initialization {init_lora_weights=}") # 对B矩阵使用全0初始化 nn.init.zeros_(self.lora_B[adapter_name].weight) if adapter_name in self.lora_embedding_A.keys(): nn.init.zeros_(self.lora_embedding_A[adapter_name]) nn.init.normal_(self.lora_embedding_B[adapter_name])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 设置可训练参数可以查看
set_adapter()方法,部分注释如下
def set_adapter(self, adapter_names: str | list[str]) -> None:
if isinstance(adapter_names, str):
adapter_names = [adapter_names]
for layer_name in self.adapter_layer_names:
module_dict = getattr(self, layer_name)
for key, layer in module_dict.items():
# 如果是adapter_names中需要训练的层,则开启梯度传播,否则关闭
if key in adapter_names:
layer.requires_grad_(True)
else:
layer.requires_grad_(False)
self._active_adapter = adapter_names
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 看完
Linear类的初始化方法,还可以看一下forward方法,描述了LoRA模型如何与原模型推理的结果进行合并的,代码部分注释如下
def forward(self, x: torch.Tensor, *args: Any, **kwargs: Any) -> torch.Tensor: self._check_forward_args(x, *args, **kwargs) adapter_names = kwargs.pop("adapter_names", None) if self.disable_adapters: if self.merged: self.unmerge() result = self.base_layer(x, *args, **kwargs) elif adapter_names is not None: result = self._mixed_batch_forward(x, *args, adapter_names=adapter_names, **kwargs) elif self.merged: result = self.base_layer(x, *args, **kwargs) else: # 得到原始模型中的结果 result = self.base_layer(x, *args, **kwargs) torch_result_dtype = result.dtype for active_adapter in self.active_adapters: if active_adapter not in self.lora_A.keys(): continue lora_A = self.lora_A[active_adapter] lora_B = self.lora_B[active_adapter] dropout = self.lora_dropout[active_adapter] scaling = self.scaling[active_adapter] x = x.to(lora_A.weight.dtype) if not self.use_dora[active_adapter]: # 原始模型输出+可训练lora层的结果 result = result + lora_B(lora_A(dropout(x))) * scaling else: x = dropout(x) result = result + self.lora_magnitude_vector[active_adapter]( x, lora_A=lora_A, lora_B=lora_B, scaling=scaling, base_layer=self.get_base_layer(), ) result = result.to(torch_result_dtype) return result
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 到这里,关于
LoRA部分的源码就解析完了,后面就是训练这些标记为可训练参数的模块。
后记
PEFT库是我看过的,封装的比较复制的库了,虽然看起来很繁琐,但是在看这些源码的过程中,我也逐渐明白了为什么代码需要这样构建,以后如果需要构建自己的大型项目应该如何做,受益匪浅。- 在这里也希望大家能深入底层原理去了解算法,只有明白了其机理,才知道算法的优缺点
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/代码探险家/article/detail/960774
推荐阅读
相关标签

