
- 1git安装
- 2CrossOver 24 for Mac版如何使用?CrossOver使用教程
- 3Leetcode hot 100
- 4vue3版本手把手教你如何搭建一个移动端项目。按照步骤来。_vue3 手机端
- 5elasticsearch(下载安装、基本操作、查询、聚合、SpringData-Elasticsearch)_spring data elasticsearch 聚合查询
- 6题解 | #查找入职员工时间排名倒数第三的员工所有信息#_欣锐科技 校招转正
- 7博主演讲实录:深入浅出谈联邦学习_成员推理攻击 联邦学习
- 8JVM调优面试题——垃圾回收专题
- 9区块链与金融科技:元宇宙数字新世界的构建者与创新者
- 10《中国人工智能学会通讯》——8.18 单目标优化中的机器学习
CV每日论文--2024.6.5_streamv2v
赞
踩
1、Looking Backward: Streaming Video-to-Video Translation with Feature Banks
中文标题:回顾过去: 使用 FeatureBanks 的视频到视频翻译流



简介:本文提出了一种名为 StreamV2V 的实时流媒体视频到视频翻译技术,它采用了一种扩散模型方法。与之前基于批处理的有限帧视频到视频翻译方法不同,StreamV2V 采用流式处理无限帧的方式。
StreamV2V 的核心思想是"向后看"的原则,即将当前帧与过去帧的信息关联起来。具体通过维护一个"特征库",记录和存储之前帧的特征信息。对于新输入的帧,StreamV2V 会拓展自注意力机制,将存储在特征库中的相似特征直接融合到输出中。特征库会不断更新,保持信息的紧凑性和丰富性。
这种基于流式特征融合的方法,使 StreamV2V 具有很强的适应性和高效性。它能够无缝集成到图像扩散模型中,无需额外的微调。在 A100 GPU 上,StreamV2V 能达到 20 FPS 的运行速度,相比其他方法快了 15-158 倍。定量指标和用户研究也证明了 StreamV2V 在时间一致性方面的出色表现。
2、From Sora What We Can See: A Survey of Text-to-Video Generation
中文标题:从Sora的见解中我们能看到:文本到视频生成的综述

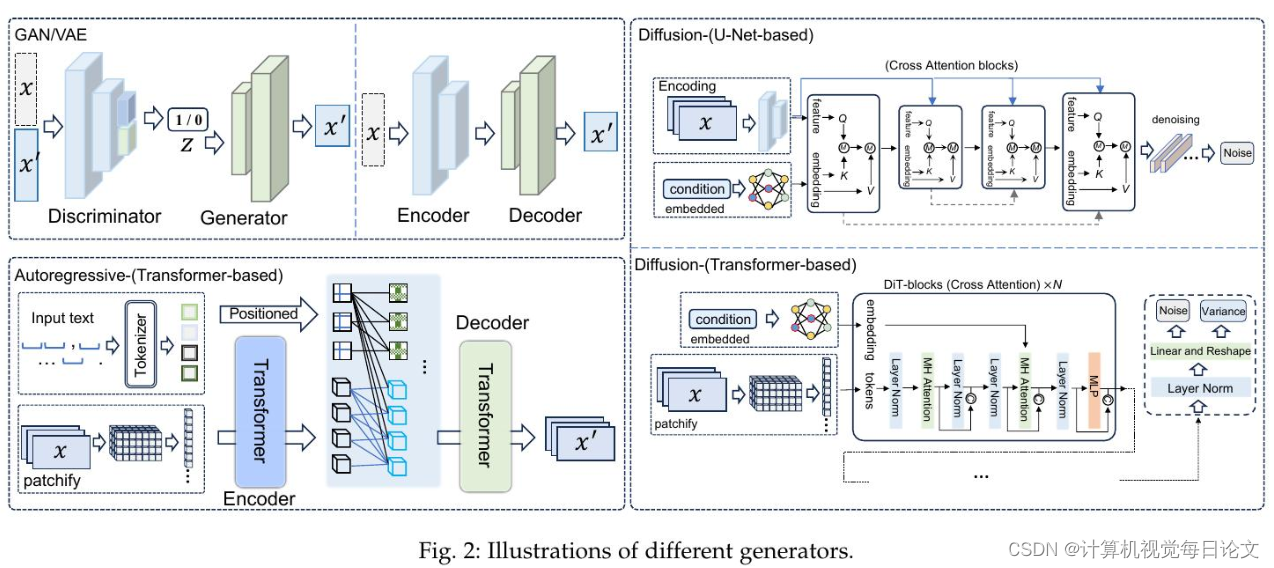
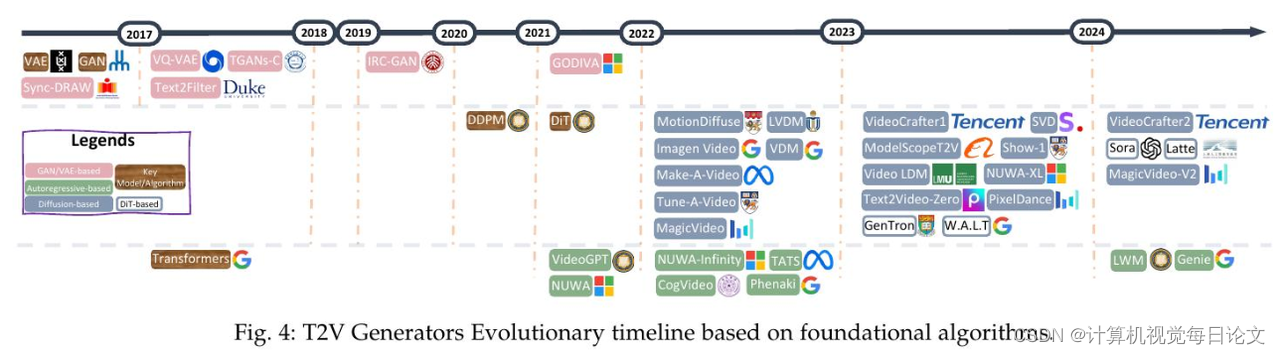

简介:随着人工智能取得令人瞩目的成就,AI正朝着人工通用智能的目标发展。OpenAI开发的Sora可以被视为这一发展进程的重要里程碑,它具有分钟级的世界模拟能力。然而,尽管Sora取得了显著进步,但仍然面临诸多有待解决的困难。
本综述从Sora在文本到视频生成方面的视角出发,对相关文献进行了全面梳理,试图回答"从Sora我们能看到什么"这一问题。首先介绍了一般算法的基本前提,然后从三个相互垂直的维度对文献进行了分类:进化生成器、优秀追求以及逼真的全景。
此外,本文还详细介绍了广泛使用的数据集和评估指标。最后,文章确定了该领域的一些挑战和开放性问题,并提出了未来研究和发展的潜在方向。
3、iVideoGPT: Interactive VideoGPTs are Scalable World Models
中文标题:iVideoGPT:可交互的VideoGPT是可扩展的世界模型

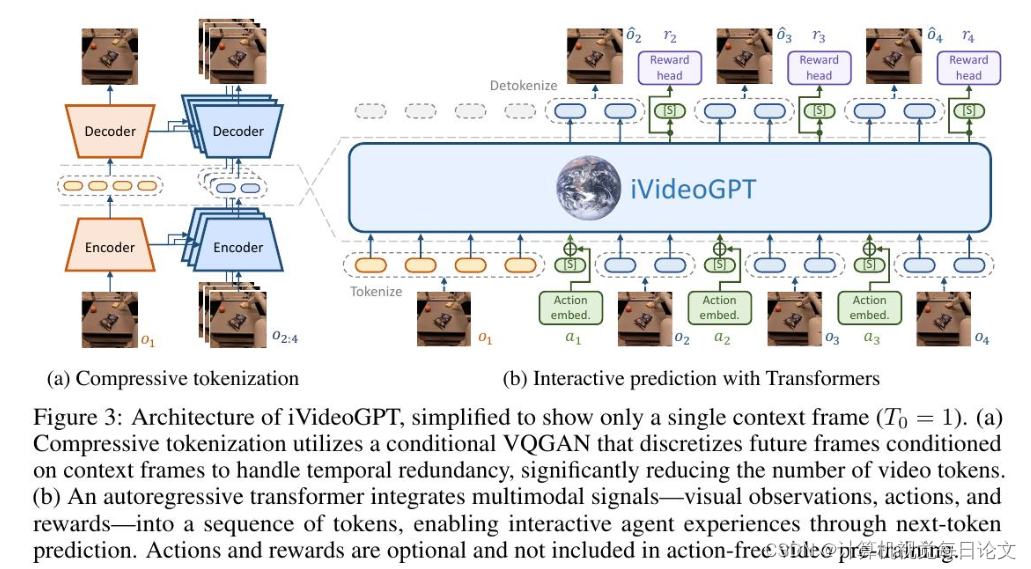

简介:这项研究介绍了iVideoGPT,这是一个可扩展的自回归变压器框架。iVideoGPT能够将多模态信号(视觉观察、动作和奖励)集成到一个标记序列中,通过预测下一个标记来实现代理的交互体验。该模型采用了一种新颖的压缩分词技术,可以有效地离散化高维视觉观察。利用其可扩展的架构,研究人员能够在大规模的人类和机器人行为轨迹数据上预训练iVideoGPT,建立一个适应性强的基础模型。这个基础模型可以作为各种下游交互式任务(如基于动作的视频预测、视觉规划和基于模型的强化学习)的世界模型。实验结果表明,iVideoGPT在这些任务上的性能优于最先进的方法。这项工作推进了交互式通用世界模型的发展,缩小了生成视频模型和基于模型的强化学习应用之间的差距。

