
热门标签
热门文章
- 1论文阅读:HeadGAN: One-shot Neural Head Synthesis and Editing
- 2如何在 Debian 上安装运行极狐GitLab Runner?【二】
- 3NetCat报错nc: forward host lookup failed: h_errno 11001: HOST_NOT_FOUND
- 4使用VIVADO中的MIG控制DDR3(AXI接口)二——用AXI4读写BRAM测试_axi ddr mig
- 5Java集合-Set详细分析_java set数据结构
- 6安装pycuda遇到错误_pycuda安装失败
- 7C练习——插入有序数组_c语言将元素插入有序数组
- 8stm32f407zgtx 烧录出现问题no target_device: stm32f407zgtx vtarget = 3.283v state of pi
- 9【RAG入门教程04】Langchian的文档切分_recursivecharactertextsplitter
- 10互联网这个圈子,程序员在BAT大厂跟在小厂初创公司的差距有多大_大厂和小厂的人能力区别
当前位置: article > 正文
Win10上运行本地大模型_metallama读取safetensors文件
作者:代码探险家 | 2024-08-18 22:49:38
赞
踩
metallama读取safetensors文件
说一下电脑配置是4090的显卡,cuda为12.2,显存24G,内存64G,可以实现模型的部署~
首先下载ollama框架,下载链接官方网站https://ollama.com/,国内在下载github时往往会下载过慢,也可以从此链接中ollama的win版本下载。
1.下载按照提示的步骤安装即可,安装成功后右下角会有一个羊驼的标志
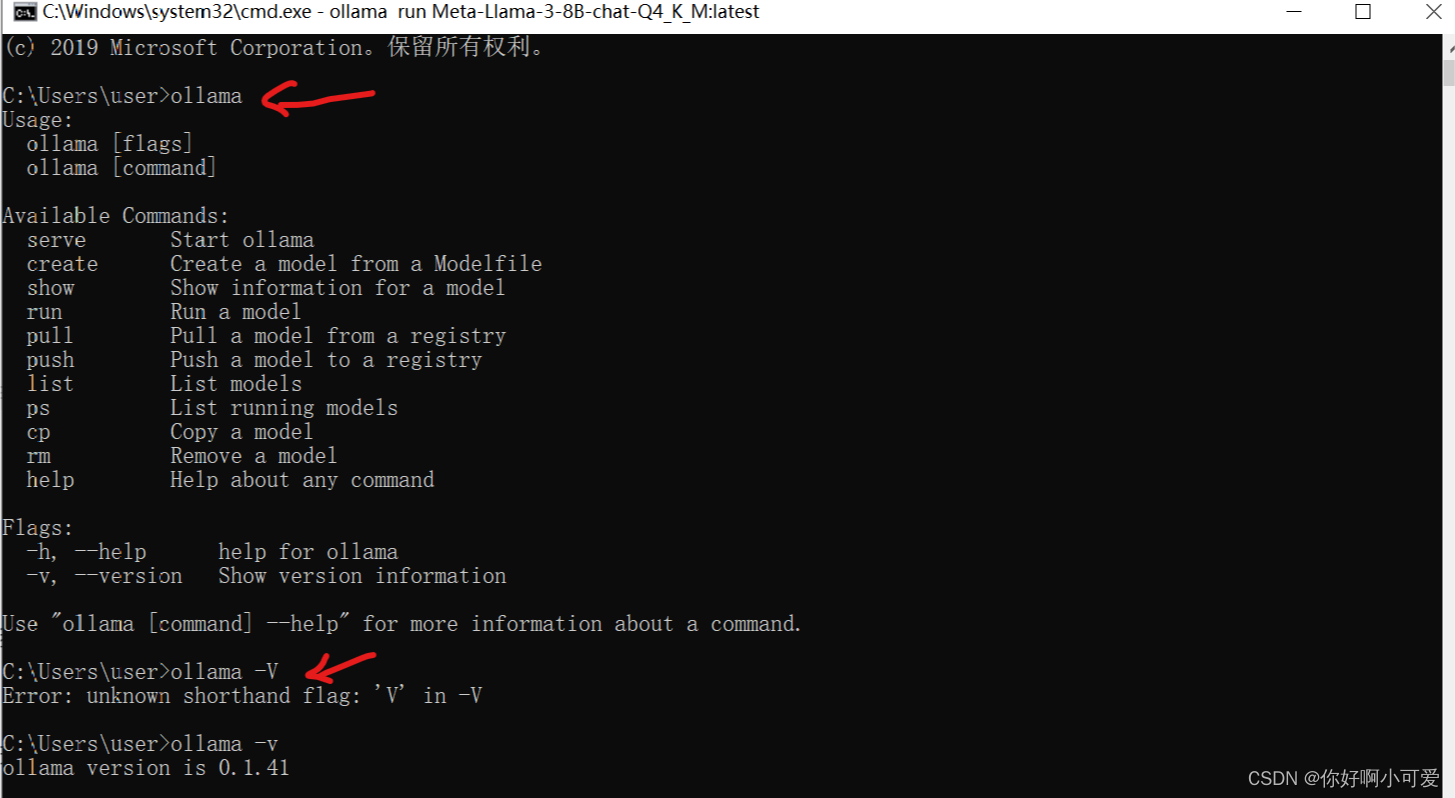
2.之后打开CMD窗口,检查ollama是否安装成功,输入以下命令如果出现类似提示,则显示安装成功。
3.在ollamav.1.39版本之后能够实现直接将模型量化,如Safetensors等格式可以用于ollama模型加载,转换模型过程十分简单。
从Hugging Face 下载一个带Safetensors 文件格式的模型,可以自行选择。用cd 切换到当前目录,如下所示

在当前文件夹下编写Modelfile文件,也就是在Meta-Llama-3-8B-Instruct文件夹下创建Modelfile文件
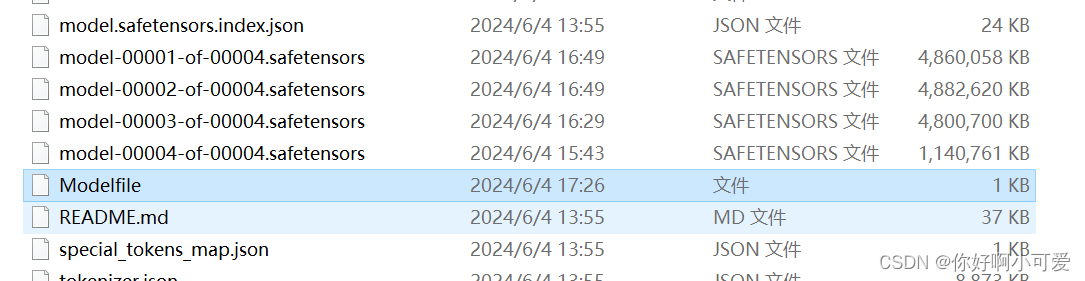
文件代码
FROM .
TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>"""
PARAMETER stop <|start_header_id|>
PARAMETER stop <|end_header_id|>
PARAMETER stop <|eot_id|>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
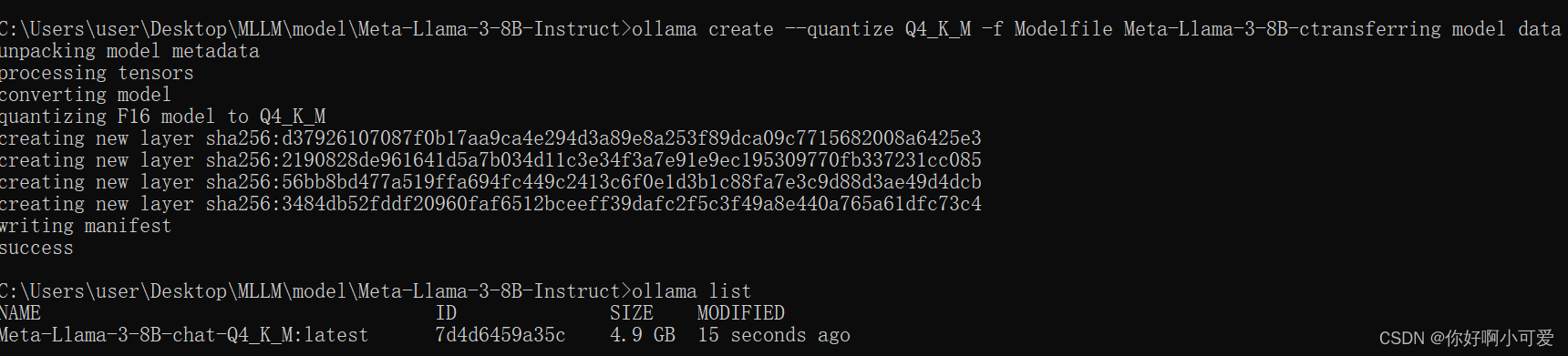
4.在cmd中输入模型量化命令
ollama create --quantize Q4_K_M -f Modelfile Meta-Llama-3-8B-chat-Q4_K_M
- 1
完事之后耐心等待,之后成为下图
5.最后运行模型,输入命令
ollama run Meta-Llama-3-8B-chat-Q4_K_M:latest
- 1
如下图所示

最后开启你的大模型学习之旅吧~
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/代码探险家/article/detail/999535
推荐阅读
相关标签

