
- 1如何在OpenAI创建一个api key(chatgpt)?_openai api key
- 2使用接口开发人脸融合 换军装, 换脸等类似功能开发
- 32024年手把手教CleanMyMac X v4.14.6破解版安装激活图文教程_cleanmymac x 4.14.6 for mac
- 4接口测试神器——Postman从入门到上手_postman download时间
- 5unity3d 资源网站(持续更新中。。。)_unity黄油网站
- 6TensorFlow YOLOv3 训练自己的数据集,详细教程_tensorflow yolov3训练自己的数据集
- 7unity中的DG.Tweening详解
- 8如何编写一个测试方案?---她是这样做的!
- 9Vector-常用CAN工具 - CANoe入门到精通_01_canoe测试工具
- 10ASP.NET ORM框架-SqlSugar_asp.net sqlsugar
AIGC学习笔记——CLIP详解加推理
赞
踩
clip论文地址:https://arxiv.org/pdf/2103.00020.pdf
clip代码地址:https://github.com/openai/CLIP
小辉问:能不能解释一下zero-shot?
小G答:零次学习(Zero-Shot Learning,简称ZSL)假设斑马是未见过的类别,但根据描述外形和马相似、有类似老虎的条纹、具有熊猫相似的颜色,通过这些描述推理出斑马的具体形态,从而能对斑马进行辨认。零次学习就是希望能够模仿人类的这个推理过程,使得计算机具有识别新事物的能力。

标准图像模型联合训练一个图像特征提取器和一个线性分类器来预测某些标签,而 CLIP 联合训练图像编码器和文本编码器来预测一个 batch 的 (图像, 文本) 训练示例的正确配对。在测试时,经学习的文本编码器通过嵌入目标数据集类别的名称或描述来合成一个零次线性分类器。
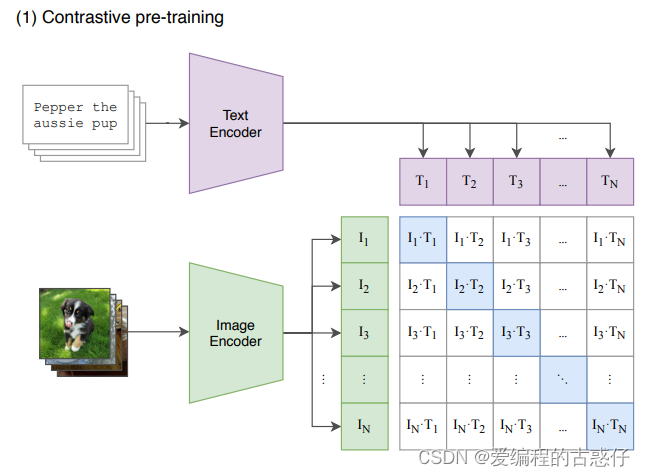
在预训练阶段,对比学习十分灵活,只需要定义好正样本对和负样本对就行了,其中能够配对的图片-文本对即为正样本。具体来说,先分别对图像和文本提特征,这时图像对应生成 I1、I2 ... In 的特征向量,文本对应生成T1、T2 ... Tn 的特征向量,然后中间对角线为正样本,其余均为负样本。这样的话就形成了n个正样本,n^2 - n个负样本。一旦有了正负样本,模型就可以通过对比学习的方式训练起来了,完全不需要手工的标注。
使用某种固定prompt结构,正如训练获得特征,通过图像与prompt特征相似度匹配,实现clip分类,如:图像猫、狗二分类,可分别输入 “ A photo of cat ” 和 “ A photo of dog ”,分别与图像特征算相似度,确定其图像类别。

图像与文本编码
CLIP为多模态模型是指图像维度与文本维度融合,那么需要对图像特征化与文本特征化,本文选择图像编码结构为VIT,文本编码结构为BERT。
CLIP(
(visual): VisionTransformer(
(conv1): Conv2d(3, 768, kernel_size=(32, 32), stride=(32, 32), bias=False)
(ln_pre): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(transformer): Transformer(
(resblocks): Sequential(
(0): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=768, out_features=3072, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=3072, out_features=768, bias=True)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(1): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=768, out_features=3072, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=3072, out_features=768, bias=True)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(2): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=768, out_features=3072, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=3072, out_features=768, bias=True)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(3): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=768, out_features=3072, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=3072, out_features=768, bias=True)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(4): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=768, out_features=3072, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=3072, out_features=768, bias=True)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(5): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=768, out_features=3072, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=3072, out_features=768, bias=True)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(6): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=768, out_features=3072, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=3072, out_features=768, bias=True)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(7): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=768, out_features=3072, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=3072, out_features=768, bias=True)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(8): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=768, out_features=3072, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=3072, out_features=768, bias=True)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(9): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=768, out_features=3072, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=3072, out_features=768, bias=True)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(10): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=768, out_features=3072, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=3072, out_features=768, bias=True)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(11): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=768, out_features=768, bias=True)
)
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=768, out_features=3072, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=3072, out_features=768, bias=True)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
)
)
(ln_post): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(transformer): Transformer(
(resblocks): Sequential(
(0): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(1): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(2): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(3): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(4): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(5): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(6): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(7): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(8): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(9): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(10): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(11): ResidualAttentionBlock(
(attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True)
)
(ln_1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): Sequential(
(c_fc): Linear(in_features=512, out_features=2048, bias=True)
(gelu): QuickGELU()
(c_proj): Linear(in_features=2048, out_features=512, bias=True)
)
(ln_2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
)
)
(token_embedding): Embedding(49408, 512)
(ln_final): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
Visual: 这是一个 Vision Transformer 模型,它接收图像作为输入,并对其进行特征提取和处理。具体来说,它包括以下几个部分:
-
- conv1: 一个二维卷积层,将输入图像的通道数从 3 扩展到 768。
- ln_pre: 一个 LayerNorm 层,用于在输入进入 Transformer 前对其进行归一化处理。
- transformer: 一个 Transformer 模块,包含多个 Residual Attention Block,用于对图像特征进行自注意力机制的处理。
Transformer: 这是一个 Transformer 模型,用于处理文本输入。它包括以下几个部分:
-
- resblocks: 一个由多个 Residual Attention Block 组成的序列,每个 Residual Attention Block 包括了自注意力机制和前馈神经网络等组件。
Token Embedding: 这是一个嵌入层,用于将输入文本中的 token 映射到一个低维的向量表示。这个嵌入层的大小为 49408,输出的向量维度为 512。
LayerNorm: 这是一个 LayerNorm 层,用于对最终的输出进行归一化处理。
小辉问:详细解释一下 Residual Attention Block(残差注意力块)
小G答:
Residual Attention Block 是一种用于处理 Transformer 模型中的注意力机制的基本组件。它结合了残差连接和自注意力机制,以更好地捕捉输入序列中的信息。下面我会逐步解释 Residual Attention Block 的组成部分和作用:
1、Multihead Attention(多头注意力):
- 在 Residual Attention Block 中,首先会使用 Multihead Attention 层。这是一个用于计算输入序列中各个元素之间的注意力权重的层。
- 它将输入序列分为多个头部,并分别计算每个头部的注意力权重,然后将所有头部的结果合并起来。
- 这种多头机制有助于模型同时关注输入序列中不同位置的信息。
2、Layer Normalization(层归一化):
- 在计算注意力权重之后,会对结果进行层归一化操作。层归一化是一种用于减少内部协变量转移的技术,有助于加速模型的训练并提高模型的泛化能力。
3、Feedforward Neural Network(前馈神经网络):
- 在经过注意力机制和归一化处理后,输入会通过一个前馈神经网络进行进一步的处理。
- 这个前馈神经网络通常由两个全连接层和一个激活函数组成,用于对输入进行非线性变换和特征提取。
4、Residual Connection(残差连接):
- 最后,Residual Attention Block 中还包括了残差连接。残差连接允许模型直接学习输入与输出之间的差异,从而更有效地传递梯度和加速训练。
- 具体来说,在残差连接中,输入会与经过前馈神经网络处理后的输出进行相加,然后再传递到下一个模块。
综上所述,Residual Attention Block 是一种用于处理 Transformer 模型中注意力机制的核心组件。它结合了多头注意力、层归一化、前馈神经网络和残差连接等技术,用于对输入序列进行特征提取和表示,从而提高模型的性能和泛化能力。
测试结果
推理代码
- import torch
- import clip
- from PIL import Image
- import numpy as np
-
- def class_demo():
- # 测试分类的demo
- device = "cuda" if torch.cuda.is_available() else "cpu"
- # 模型选择['RN50', 'RN101', 'RN50x4', 'RN50x16', 'ViT-B/32', 'ViT-B/16'],对应不同权重
- # 加载模型及对应的预处理方法
- model, preprocess = clip.load("./model/ViT-B-32.pt", device=device) # 载入模型
- image = preprocess(Image.open("./CLIP.png")).unsqueeze(0).to(device) # 打开并预处理图像
- # 待测试的文本内容
- text_language = ["a diagram", "a dog", "a cat"]
- # 对文本进行tokenize处理
- text = clip.tokenize(text_language).to(device)
-
- with torch.no_grad():
- # 使用模型进行推断
- logits_per_image, logits_per_text = model(image, text) # 第一个值是图像,第二个是文本
- # 对图像和文本的预测结果进行softmax处理并转换为numpy数组
- probs = logits_per_image.softmax(dim=-1).cpu().numpy()
-
- # 获取每张图像的最大概率的标签
- idx = np.argmax(probs, axis=1)
- # 输出每张图像的预测结果
- for i in range(image.shape[0]):
- id = idx[i]
- # 输出图像的预测结果及对应的概率
- print('image {}\tlabel\t{}:\t{}'.format(i, text_language[id],probs[i,id]))
- # 输出图像的所有预测结果及对应的概率
- print('image {}:\t{}'.format(i, [v for v in zip(text_language,probs[i])]))
-
-
- if __name__ == '__main__':
- class_demo()





