
- 1飞书ChatGPT机器人 – 打造智能问答助手实现无障碍交流_飞书机器人对话
- 2计算机控制面板设置命令,控制面板在哪里打开?快捷键是多少(最全4种方法详解)...
- 3Windows下安装Telnet工具_window2022安装telnet
- 4挂载命令mount_mount挂载
- 5【动态规划案例】彻底搞明白最长公共子序列LCS_lcs 公共
- 6Shell脚本中$0、$?、$!、$$、$*、$#、$@等的意义以及linux命令执行返回值代表意义
- 7【论文解读】transformer小目标检测综述
- 8备战蓝桥杯————k个一组反转单链表
- 9如何重置计算机服务到默认状态,电脑变慢不用愁,利用这个操作,一键将win10重置为默认出厂设置...
- 102024年阿里云2核4G云服务器性能如何?价格便宜有点担心
pd.DataFrame系列
赞
踩
文章目录
- 如何让dataframe优雅的增加一列?
- 获取一个dataframe的后三列,0行到100行
- 读取excel,将结果写入到一个excel的多个sheet
- 筛选数据啦
- DataFrame.groupby()
- .sort_index()和.sort_values()
- DataFrame的values
- DataFrame用drop_duplicates()去重
- read_csv和to_csv参数解释
- 在Dataframe中新添一列
- pd.DataFrame初始化以及set_index
- set_index
- print (df['uid'])
- df['score']=df['score'].astype('str');
- drop方法
- 求dataframe的列信息
- isnull函数
- pandas替换-3和3
- data1=data,data1仍然左右data!
- pndas删除某一行和某些行
如何让dataframe优雅的增加一列?
- 假设索引最大到287
- 那我怎么加一行呢?
data.loc[288] = data.loc[287]
获取一个dataframe的后三列,0行到100行
- 注意啊,索引是100的那个不包含哈!
a=grade[[grade.columns[-3],grade.columns[-2],grade.columns[-1]]][0:100]
- 1
a=grade[grade.columns][0:100]
- 1
读取excel,将结果写入到一个excel的多个sheet
项目.xlsx是输入,俺老子要把这个按照visibility分成公开的还是私有的,然后塞到项目-公私分开.xlsx中作为两个sheet
#encoding: utf-8 import pandas as pd input = "项目.xlsx" output = '项目-公私分开.xlsx' data = pd.read_excel(input) data['visibility']=data['visibility'].astype('category'); data['Paths']=data['Paths'].astype('str'); writer = pd.ExcelWriter(output) condition= (data['visibility']== 'private') data[condition].to_excel(writer, index = False,sheet_name= '私-底') condition= (data['visibility']== 'public') data[condition].to_excel(writer, index = False,sheet_name= '公-底') writer.save() writer.close()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 请问index=False是啥意思呢,意思就是别把索引写到第一列啊!
筛选数据啦
data[data['id']==424365]
- 1
DataFrame.groupby()
- groupby使你能以一种自然的方式对数据集进行切片、切块、摘要
等操作。
- 根据一个或多个键(可以是函数、数组或DataFrame列名)拆分pandas对象。
- 计算分组摘要统计,如计数、平均值、标准差,或用户自定义函数。
- 对DataFrame的列应用各种各样的函数。
- 应用组内转换或其他运算,如规格化、线性回归、排名或选取子集等。计算透视表或交叉表。执行分位数分析以及其他分组分析。
- groupby分组函数:
- 返回值:返回重构格式的DataFrame,groupby里面的字段内的数据重构后都会变成索引
- groupby(),一般和sum()、mean()一起使用
import pandas as pd
df = pd.DataFrame({'key1':list('ababa'),
'key2': ['one','two','one','two','one'],
'data1': np.random.randn(5),
'data2': np.random.randn(5)})
print(df)
data1 data2 key1 key2
0 -1.313101 -0.453361 a one
1 0.791463 1.096693 b two
2 0.462611 1.150597 a one
3 -0.216121 1.381333 b two
4 0.077367 -0.282876 a one
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 用groupby,分组键均为Series(譬如df[‘xx’]),
- 实际上分组键可以是任何长度适当的数组
#将df['data1']按照分组键为df['key1']进行分组 grouped=df['data1'].groupby(df['key1']) print(grouped.mean()) key1 a -0.257707 b 0.287671 Name: data1, dtype: float64 states=np.array(['Ohio','California','California','Ohio','Ohio']) years=np.array([2005,2005,2006,2005,2006]) #states第一层索引,years第二层分层索引 print(df['data1'].groupby([states,years]).mean()) California 2005 0.791463 2006 0.462611 Ohio 2005 -0.764611 2006 0.077367 Name: data1, dtype: float64 #df根据‘key1’分组,然后对df剩余数值型的数据运算 df.groupby('key1').mean() data1 data2 key1 a -0.257707 0.138120 b 0.287671 1.239013 #可以看出没有key2列,因为df[‘key2’]不是数值数据,所以被从结果中移除。默认情况下,所有数值列都会被聚合,虽然有时可能被过滤为一个子集。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 对分组进行迭代
#name就是groupby中的key1的值,group就是要输出的内容
for name, group in df.groupby('key1'):
print (name,group)
a data1 data2 key1 key2
0 -1.313101 -0.453361 a one
2 0.462611 1.150597 a one
4 0.077367 -0.282876 a one
b data1 data2 key1 key2
1 0.791463 1.096693 b two
3 -0.216121 1.381333 b two
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
canci
.sort_index()和.sort_values()
- df. sort_values()
- 既可根据列数据,也可根据行数据排序。
- 必须指定by参数,即必须指定哪几行或哪几列;
- 无法根据index名和columns名排序(由.sort_index()执行)
-
sort_values(by, axis=0, ascending=True, inplace=False, kind=‘quicksort’, na_position=‘last’)
-
axis:{0 or ‘index’, 1 or ‘columns’}, default 0,默认按照列排序,为1,则是横向排序。
-
by:str or list of str;如果axis=0,那么by=“列名”;如果axis=1,那么by=“行名”。
-
ascending:True则升,如果by=[‘列名1’,‘列名2’],则该参数可以是[True, False],即第一字段升序,第二个降序。
-
inplace:布尔型,是否用排序后的数据框替换现有的数据框。
-
kind:排序方法,{‘quicksort’, ‘mergesort’, ‘heapsort’}, default ‘quicksort’。似乎不用太关心。
-
na_position:{‘first’, ‘last’}, default ‘last’,默认缺失值排在最后面。
df = pd.DataFrame({'b':[1,2,3,2],'a':[4,3,2,1],'c':[1,3,8,2]},index=[2,0,1,3])
b a c
2 1 4 1
0 2 3 3
1 3 2 8
3 2 1 2
- 1
- 2
- 3
- 4
- 5
- 6
- 按b升序
df.sort_values(by='b') #等同于df.sort_values(by='b',axis=0)
b a c
2 1 4 1
0 2 3 3
3 2 1 2
1 3 2 8
- 1
- 2
- 3
- 4
- 5
- 6
- 按b列降,再按a升
df.sort_values(by=['b','a'],axis=0,ascending=[False,True]) #等同于df.sort_values(by=['b','a'],axis=0,ascending=[False,True])
b a c
1 3 2 8
3 2 1 2
0 2 3 3
2 1 4 1
- 1
- 2
- 3
- 4
- 5
- 6
df.sort_values(by=3,axis=1) #必须指定axis=1
a b c
2 4 1 1
0 3 2 3
1 2 3 8
3 1 2 2
- 1
- 2
- 3
- 4
- 5
- 6
canci
DataFrame的values
import pandas as pd
data = pd.DataFrame(columns=['a','b'], data=[[1,2],[3,4]])
print (data.values)
print (type(data.values))
[[1 2]
[3 4]]
<class 'numpy.ndarray'>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这个好啊,有多少个记录就有多少行,每列就是属性,成了数组了!每列没有列名喽
print(data.shape)
- 你可以机灵的看看这个data的shape
DataFrame用drop_duplicates()去重
- 经常需对DataFrame去重,但有时也会需要只保留重复值。
- 先创建一个包含一行重复值的DataFrame。
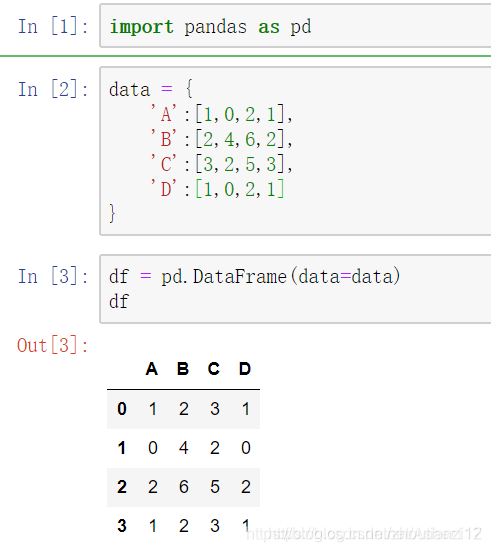
- 可以选择是否保留重复值,默认保留重复值,
- 不保留重复值的话直接设置参数keep为False
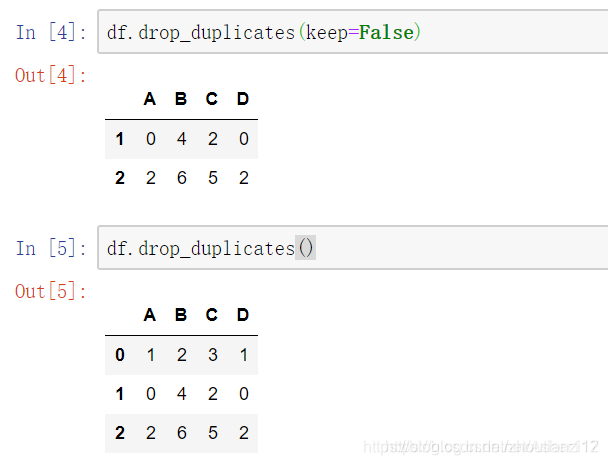
- 有时候要取重复数据,
- 就可根据刚刚上面我们得到的两个DataFrame
- 来concat到一起之后去重不保留重复值就可以。
- 这样就把重复值取出来了。

- 根据某列去重
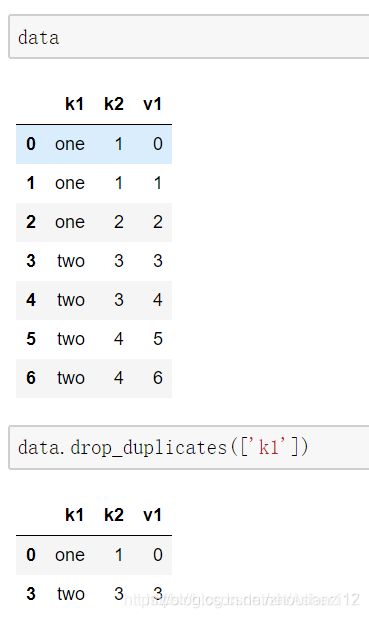

read_csv和to_csv参数解释
在Dataframe中新添一列
- 直接指明列名,然后赋值就可
import pandas as pd
data = pd.DataFrame(columns=['a','b'], data=[[1,2],[3,4]])
data
- 1
- 2
- 3
- 4
- 5
- 6
- 7
>>> data
a b
0 1 2
1 3 4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 添加一列’c‘,赋为空白值。
data['c'] = ''
>>> data
a b c
0 1 2
1 3 4
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
data['d'] = [5,6]
data
>>> data
a b c d
0 1 2 5
1 3 4 6
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
pd.DataFrame初始化以及set_index
import pandas as pd
df = pd.DataFrame([['a1', 1], ['a2', 4]], columns=['uid', 'score'])
print(df)
df.set_index('uid',inplace=True);
print (df)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

set_index
set_index():
-
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
-
keys:列标签或列标签/数组列表,需要设置为索引的列
-
drop:删除用作新索引的列
-
append:是否将列附加到现有索引
-
inplace:默认False,适当修改DataFrame(不要创建新对象)
-
verify_integrity:默认false,检查新索引的副本。否则,请将检查推迟到必要时进行。将其设置为false将提高该方法的性能。
print (df[‘uid’])
import pandas as pd
df = pd.DataFrame([['a1', 1], ['a2', 4]], columns=['uid', 'score'])
print(df)
print (df['uid'])
print ("sdfdsfdfgddddddddddddddddddddddddddddddddddddd")
print (df['score'])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
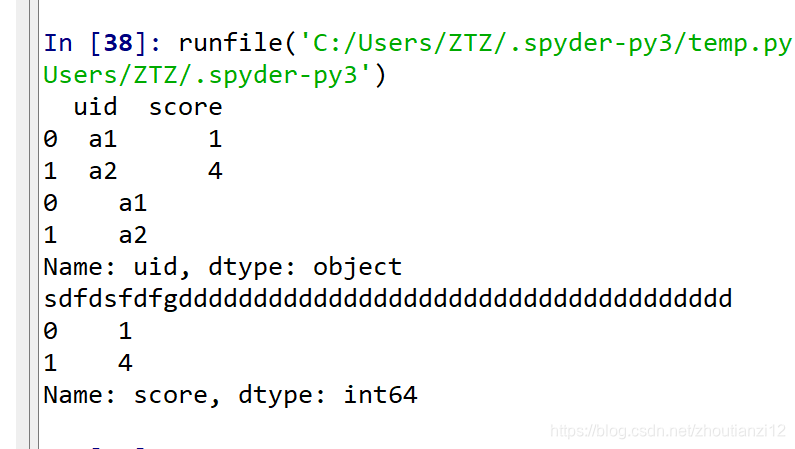
df[‘score’]=df[‘score’].astype(‘str’);
import pandas as pd df = pd.DataFrame([['a1', 1], ['a2', 4]], columns=['uid', 'score']) print(df) print (df['score']) df['score']=df['score'].astype('str') print (df['score'])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
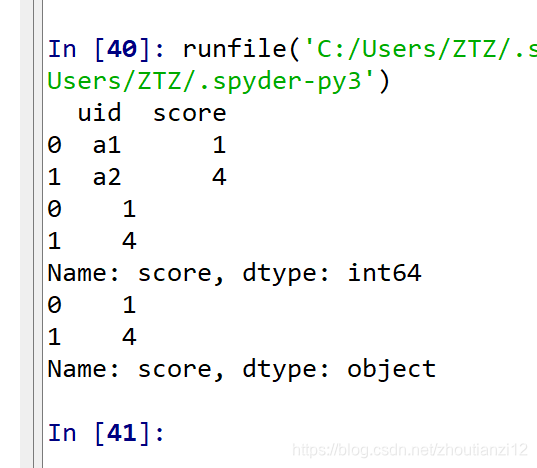
import pandas as pd
df = pd.DataFrame([['a1', 1], ['a2', 4]], columns=['uid', 'score'])
df['score']=df['uid'].astype('category');
print (df['score'])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

drop方法
-
drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors=‘raise’)
-
labels是指要删除的标签,一个或者是列表形式的多个,
-
axis指处哪一个轴
-
columns是指某一列或者多列,
-
level是指等级,针对多重索引
-
inplaces是否替换原来的dataframe
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(5,3),index = list('abcde'),columns = ['one','two','three'])
print (df)
df.drop(['one'],axis=1,inplace=True)
print (df)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14

import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(5,3),index = list('abcde'),columns = ['one','two','three'])
print (df)
df.drop(['a','b'],inplace=True)
print (df)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14

>>> df = pd.DataFrame(np.arange(12).reshape(3,4), ... columns=['A', 'B', 'C', 'D']) >>> df A B C D 0 0 1 2 3 1 4 5 6 7 2 8 9 10 11 #指定删除相关的列,没有带columns,所以要指出是哪个轴上的 >>> df.drop(['B', 'C'], axis=1) A D 0 0 3 1 4 7 2 8 11 #这里带有columns,所以不用加上axis参数 >>> df.drop(columns=['B', 'C']) A D 0 0 3 1 4 7 2 8 11 #删除指定索引的行,这里没有axis参数,就是默认axis=0,也就是删除行 >>> df.drop([0, 1]) A B C D 2 8 9 10 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
求dataframe的列信息
print (ad.columns)
Index(['Unnamed: 0', 'creative_id', 'ad_id', 'product_id', 'product_category',
'advertiser_id', 'industry'],
dtype='object')
print (type(ad.columns))
<class 'pandas.core.indexes.base.Index'>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
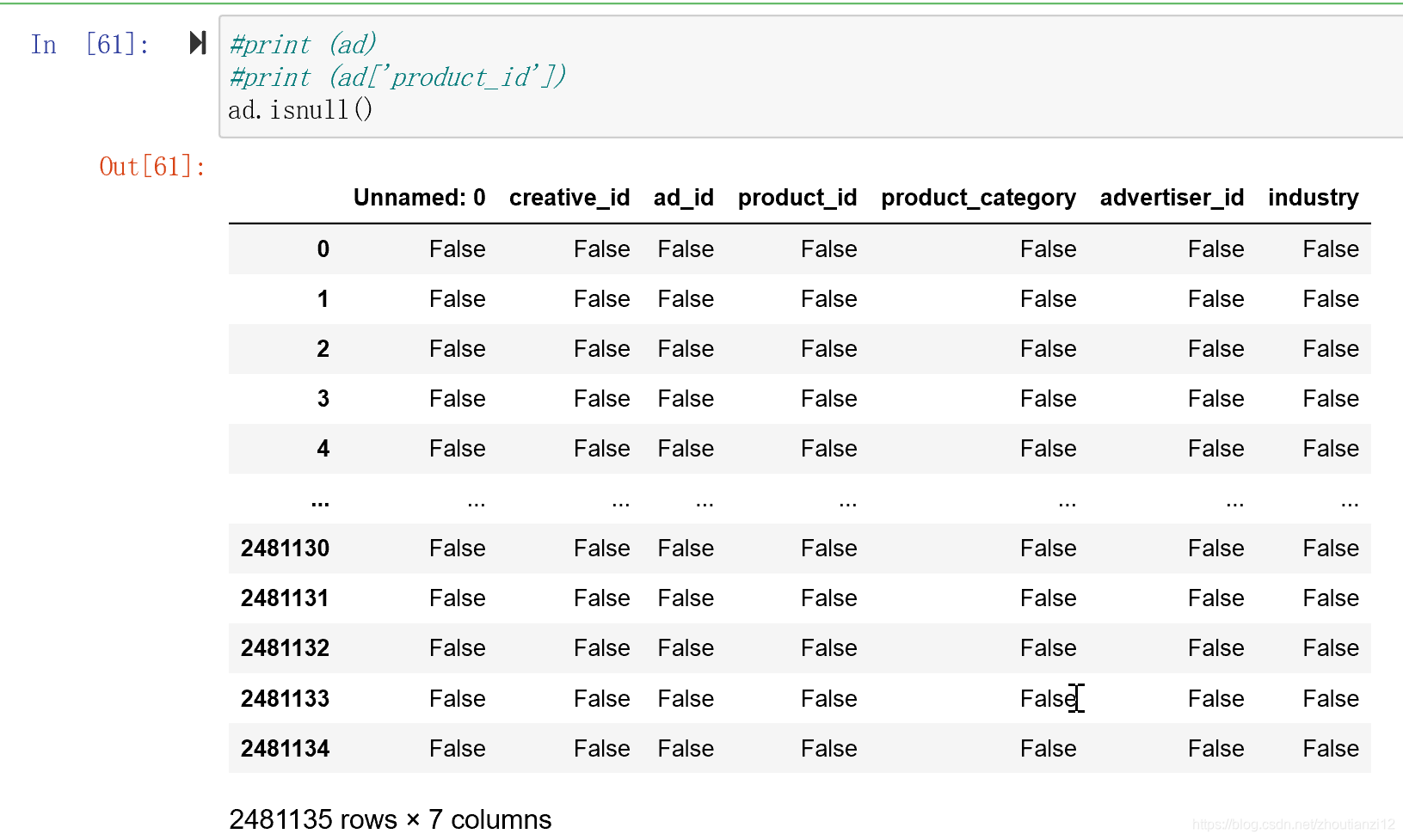
isnull函数
- 列级别的判断,只要该列有为空或者NA的元素,就为True,否则False
ad.isnull().any()
- 1
- 2

- 元素级别的判断,把对应的所有元素的位置都列出来,
- 元素为空或者NA就显示True,否则False
ad.isnull()
- 1
- 2
pandas替换-3和3
import pandas as pd import numpy as np data=pd.DataFrame(np.random.randn(10000,4)) print (data.head()) print (data.describe()) print (".....................................\n") print (data[(np.abs(data)>3).any(1)]) print (".....................................\n") print (np.sign(data)*3) print (".....................................\n") data[(np.abs(data)>3)]=np.sign(data)*3 print (data[(np.abs(data)>3).any(1)])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- any(1)
- 1代表1轴也就是行
- any的意思是每一行中只要有一个值满足条件就不排除
- 将异常值找出来, data[np.abs(data) > 3]
- 替换找到的异常值. data[np.abs(data) > 3] = np.sign(data)*3
data1=data,data1仍然左右data!
import pandas as pd import numpy as np data=pd.DataFrame(np.random.randn(10000,4)) print (data[0][0]) data1=data data1[0][0]=12 print (data[0][0]) -0.2163364765902928 12.0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
import pandas as pd import numpy as np data=pd.DataFrame(np.random.randn(10000,4)) print (data[0][0]) data1=data.copy() data1[0][0]=12 print (data[0][0]) -1.323364816178571 -1.323364816178571
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
pndas删除某一行和某些行
import pandas as pd import numpy as np data=pd.DataFrame(np.random.randn(8,4)) print (data) data.drop([0,1,2], axis=0, inplace=True) print (data) 0 1 2 3 0 -1.356098 -2.757676 1.298255 0.680684 1 -0.850784 -0.499739 0.735980 -1.367757 2 -0.136712 -1.517955 1.732635 -0.616452 3 -0.333158 0.247137 -0.778323 -0.619491 4 0.447829 0.319978 1.584691 -0.327392 5 0.842971 1.618222 -0.309938 -1.128479 6 1.317082 -1.590495 0.968119 0.699859 7 -0.815379 -0.034858 -2.285859 -1.610159 0 1 2 3 3 -0.333158 0.247137 -0.778323 -0.619491 4 0.447829 0.319978 1.584691 -0.327392 5 0.842971 1.618222 -0.309938 -1.128479 6 1.317082 -1.590495 0.968119 0.699859 7 -0.815379 -0.034858 -2.285859 -1.610159
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 牛逼的是我们的索引啊!!

