
大型语言模型的检索增强生成:调查_模块化rag是谁提出的
赞
踩
大型语言模型的检索增强生成:调查
原文:《Retrieval-Augmented Generation for Large Language Models: A Survey》
原作者:Yunfan Gao[1], Yun Xiong[2], Xinyu Gao[2], Kangxiang Jia[2], Jinliu Pan[2], Yuxi Bi[3], Yi Dai[1], Jiawei Sun[1]and Haofen Wang[1][3]∗
[1]Shanghai Research Institute for Intelligent Autonomous Systems, Tongji University
[2]Shanghai Key Laboratory of Data Science, School of Computer Science, Fudan University
[3]College of Design and Innovation,Tongji University
邮箱:gaoyunfan1602@gmail.com
摘要
大型语言模型(LLM)表现出强大的能力,但它们在实际应用中仍然面临挑战,例如幻觉、知识更新缓慢和答案缺乏透明度。检索增强生成 (RAG) 是指在使用 LLM 回答问题之前从外部知识库中检索相关信息。 RAG 已被证明可以显着提高答案的准确性,减少模型幻觉,特别是对于知识密集型任务。通过引用来源,用户可以验证答案的准确性并增加对模型输出的信任。 它还有助于知识更新和特定领域知识的引入。RAG 有效地将 LLM 的参数化知识与非参数化的外部知识库相结合,使其成为实现大型语言模型的最重要方法之一。本文概述了LLM时代RAG的发展范式,总结了朴素RAG、高级RAG和模块化RAG三种范式。然后,它提供了 RAG 的三个主要组件的摘要和组织:检索器、生成器和增强方法,以及每个组件中的关键技术。此外,还讨论了如何评估RAG模型的有效性,介绍了RAG的两种评估方法,强调了评估的关键指标和能力,并介绍了最新的自动评估框架。最后,从垂直优化、横向可扩展性、RAG的技术栈和生态系统三个方面介绍了未来潜在的研究方向。[1]
1 引言
大型语言模型 (LLM) 比我们以前在自然语言处理 (NLP) 中看到的任何模型都更强大。 GPT系列模型 [Brown et al., 2020, OpenAI, 2023]、LLama 系列模型 [Touvron et al., 2023]、Gemini*[Google, 2023] * 和其他大型语言模型表现出令人印象深刻的语言和知识掌握能力,在多个评估基准中超过了人类基准水平 [Wang et al., 2019, Hendrycks et al., 2020, Srivastava et al., 2022]。
然而,大型语言模型也存在许多缺点。 他们经常捏造事实 [Zhang et al., 2023b],在处理特定领域或高度专业化的查询时缺乏知识 [Kandpal et al., 2023]。例如,当所寻求的信息超出模型的训练数据或需要最新数据时,LLM 可能无法提供准确的答案。在现实世界的生产环境中部署生成式人工智能时,这种限制带来了挑战,因为盲目使用黑盒 LLM 可能还不够。
传统上,神经网络通过微调模型来参数化知识来适应特定领域或专有信息。虽然这种技术产生了显著的成果,但它需要大量的计算资源,产生高昂的成本,并且需要专门的技术专长,使其对不断变化的信息环境的适应性较差。参数知识和非参数知识起着不同的作用。参数知识是通过训练LLM获得的,并存储在神经网络权重中,代表了模型对训练数据的理解和泛化,为生成的响应奠定了基础。另一方面,非参数知识驻留在外部知识源(如向量数据库)中,不直接编码到模型中,而是被视为可更新的补充信息。非参数知识使 LLM 能够访问和利用最新或特定领域的信息,从而提高响应的准确性和相关性。
纯参数化语言模型 (LLM) 将其从大量语料库中获得的世界知识存储在模型的参数中。然而,这种模型有其局限性。首先,很难从训练语料库中保留所有知识,尤其是对于不太常见和更具体的知识。其次,由于模型参数不能动态更新,参数化知识容易随着时间的推移而过时。最后,参数的扩展会导致训练和推理的计算费用增加。为了解决纯参数化模型的局限性,语言模型可以采用半参数化的方法,将非参数化语料库与参数化模型集成。这种方法称为检索增强生成 (Retrieval-Augmented Generation, RAG)。
检索增强生成 (RAG) 一词最早由 [Lewis et al., 2020] 引入。它将预训练的检索器与预训练的 seq2seq 模型(生成器)相结合,并进行端到端微调,以更可解释和模块化的方式捕获知识。在大型模型出现之前,RAG 主要专注于端到端模型的直接优化。检索端的密集检索,例如使用基于矢量的密集通道检索 (Dense Passage Retrieval, DPR)[Karpukhin et al., 2020],以及在生成端训练较小的模型是常见的做法。由于整体参数大小较小,检索器和生成器通常都进行同步的端到端训练或微调 [Izacard et al., 2022]。
在 ChatGPT 等 LLM 出现后,生成式语言模型成为主导,在各种语言任务中表现出令人印象深刻的性能 [Bai et al., 2022, OpenAI, 2023, Touvron et al., 2023, Google, 2023]。然而,LLM 仍然面临幻觉 [Yao et al., 2023, Bang et al., 2023]、知识更新和数据相关问题等挑战。 这影响了 LLM 的可靠性,使它们在某些严肃的任务场景中遇到困难,尤其是在需要访问大量知识的知识密集型任务中,例如开放领域问答 [Chen and Yih, 2020, Reddy et al., 2019, Kwiatkowski et al., 2019] 和常识推理 [Clark et al., 2019, Bisk et al., 2020]。 参数中的隐性知识可能不完整和不充分。
随后的研究发现,将RAG引入大型模型的上下文学习(ICL)可以缓解上述问题,并具有显着且易于实施的效果。在推理过程中,RAG 会从外部知识源动态检索信息,使用检索到的数据作为参考来组织答案。这大大提高了响应的准确性和相关性,有效地解决了 LLM 中存在的幻觉问题。这种技术在 LLM 出现后迅速获得关注,并已成为改进聊天机器人和使 LLM 更实用的最热门技术之一。通过将事实知识与LLM的训练参数分离,RAG巧妙地将生成模型的强大能力与检索模块的灵活性相结合,为纯参数化模型固有的不完整和不足的知识问题提供了有效的解决方案。
本文系统回顾和分析了RAG目前的研究途径和未来发展路径,将其归纳为朴素型RAG、高级型RAG和模块化型RAG三大范式。随后,本文对检索、增强和生成三个核心组件进行了综合总结,重点介绍了RAG的改进方向和当前技术特点。在关于增强方法的部分中,目前的工作分为三个方面:RAG的增强阶段、增强数据源和增强过程。此外,本文还总结了与RAG相关的评价体系、适用场景等相关内容。
通过本文,读者可以更全面、系统地了解大型模型和检索增强生成。他们熟悉知识检索增强的演进路径和关键技术,使他们能够辨别不同技术的优缺点,识别适用场景,并在实践中探索当前典型应用案例。
值得注意的是,在以往的工作中,Feng el al.[2023b]系统地回顾了大模型与知识相结合的方法、应用和未来趋势,主要关注知识编辑和检索增强方法。Zhu et al.[2023] 介绍了大型语言模型检索系统增强的最新进展,特别关注检索系统。同时,Asai et al.[2023a] 围绕“什么”、“何时”、“如何”等问题,分析和阐明了基于检索的语言模型中的关键过程。与它们相比,本文旨在系统地概述检索-增强生成(RAG)的整个过程,并特别关注与通过知识检索增强大型语言模型生成相关的研究。
RAG算法和模型的开发如图1所示。从时间轴上看,大多数与 RAG 相关的研究出现在 2020 年之后,在 2022 年 12 月发布 ChatGPT 时出现了一个重要的转折点。自ChatGPT发布以来,自然语言处理领域的研究进入了大模型时代。朴素的RAG技术迅速受到重视,导致相关研究的数量迅速增加。在增强策略方面,自引入RAG概念以来,关于预训练和监督微调阶段的强化研究一直在进行中。然而,大多数关于推理阶段强化的研究都出现在LLMs时代。这主要是由于与高性能大型模型相关的高训练成本。研究人员试图通过在推理阶段包含 RAG 模块,以具有成本效益的方式整合外部知识来增强模型生成。
关于增强数据的使用,早期的RAG主要关注非结构化数据的应用,特别是在开放域问答的背景下。随后,检索的知识来源范围扩大了,使用高质量的数据作为知识来源,有效地解决了诸如错误知识的内化和大型模型中的幻觉等问题。这包括结构化知识,知识图谱就是一个典型的例子。
最近,人们对自我检索的关注越来越多,这涉及挖掘 LLM 本身的知识以提高他们的表现。
本文的后续章节结构如下:第2章介绍了RAG的背景。第3章介绍了RAG的主流范式。第 4 章分析了 RAG 中的检索器。第 5 章着重讲述 RAG 中的生成器如何工作。第6章重点介绍了RAG中的增强方法。第7章介绍了RAG的评价体系。第8章对RAG的未来发展趋势进行了展望。最后,在第9章中,我们总结了调查的主要内容。
2 背景
在本章中,我们将介绍RAG的定义,以及RAG与其他模型优化技术(如微调)的比较。
2.1 定义
RAG的含义随着技术的发展而扩展。在大型语言模型时代,RAG的具体定义是指模型在回答问题或生成文本时,首先从庞大的文档语料库中检索相关信息。随后,它利用这些检索到的信息来生成响应或文本,从而提高预测的质量。RAG 方法允许开发人员避免为每个特定任务重新训练整个大型模型的需要。相反,他们可以附加知识库,为模型提供额外的信息输入,并提高其响应的准确性。RAG 方法特别适用于知识密集型任务。总之,RAG系统由两个关键阶段组成:
-
利用编码模型根据问题检索相关文档,例如 BM25、DPR、ColBERT 和类似方法 [Robertson et al., 2009, Karpukhin et al., 2020, Khattab and Zaharia, 2020]。
-
生成阶段:系统使用检索到的上下文作为条件,生成文本。
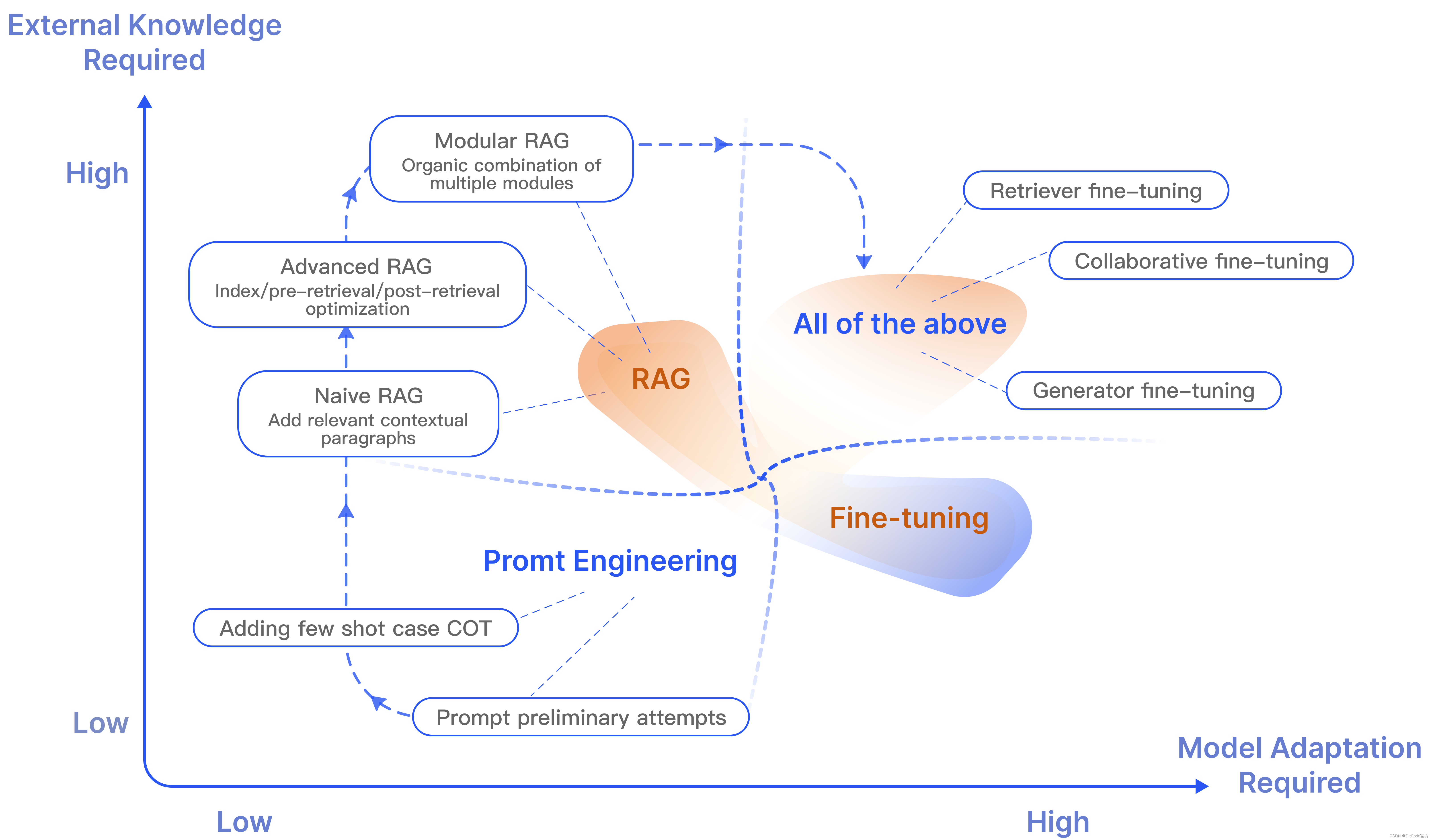
图 2:RAG 与其他模型优化方法的比较
2.2 RAG 与微调
在大型语言模型(LLM)的优化中,除了RAG之外,另一个重要的优化技术是微调。
RAG 类似于为模型提供教科书,允许它根据特定查询检索信息。此方法适用于模型需要回答特定查询或解决特定信息检索任务的场景。但是,RAG 不适合教授模型理解广泛的领域或学习新的语言、格式或样式。
微调(Fine-tuning) 类似于使学生能够通过广泛的学习来内化知识。当模型需要复制特定结构、样式或格式时,此方法非常有用。微调可以提高未微调模型的性能,并使交互更加高效。它特别适用于强调基础模型中的现有知识、修改或自定义模型的输出,以及为模型提供复杂的指令。但是,微调不适合将新知识合并到模型中,也不适合需要对新用例进行快速迭代的情况。
微调类似于让学生通过长时间的学习来内化知识。当模型需要复制特定结构、样式或格式时,此方法适用。微调可以实现优于非微调模型的性能,并且交互效率更高。微调特别适用于强调基础模型中的现有知识、修改或自定义模型的输出,以及使用复杂的指令指示模型。但是,微调不适合向模型添加新知识,也不适合需要针对新用例进行快速迭代的方案。RAG和微调(Fine-tuning,FT)之间的具体比较可以在表1中阐明。
RAG 和微调不是相互排斥的,而是可以相辅相成的,从而在不同层面上增强模型的功能。在某些情况下,将这两种技术结合起来可以实现最佳模型性能。使用 RAG 进行优化和微调的整个过程可能需要多次迭代才能获得满意的结果。
现有研究表明,与其他优化大型语言模型的方法相比,检索增强生成 (Retrieval-Augmented Generation, RAG) 在优化大语言模型 (Large Language Model) 方面,相较于其他方法具有显著的优势【Shuster et al., 2021; Yasunaga et al., 2022; Wang et al., 2023c; Borgeaud et al., 2022】:
- RAG 通过将答案与外部知识相关联,减少语言模型中的幻觉问题,并使生成的响应更加准确和可靠,从而提高了准确性。
- 使用检索技术可以识别最新信息。这使得 RAG 在保持回答的及时性和准确性方面,相较于只依赖训练数据的传统语言模型有明显优势。
- 透明度是RAG的一大优势。通过引用来源,用户可以验证答案的准确性,从而增加对模型输出的信任。
- RAG 具有定制功能。通过索引相关文本语料库,可以针对不同领域定制模型,为特定领域提供知识支持。
- 在安全和隐私管理方面,RAG凭借其在数据库中的内置角色和安全控制,可以更好地控制数据使用。相比之下,微调模型可能缺乏对谁可以访问哪些数据的明确管理。
- RAG 更具可扩展性。它可以处理大规模数据集,而无需更新所有参数和创建训练集,使其更具经济效率。
- 最后,RAG 产生的结果更值得信赖。RAG从最新数据中选择确定性结果,而微调模型在处理动态数据时可能会表现出幻觉和不准确,缺乏透明度和可信度。
3 RAG 框架
RAG的研究范式在不断发展。本章主要介绍RAG研究范式的演变。我们将其分为三种类型:朴素 RAG、高级 RAG 和模块化 RAG。虽然早期的RAG性价比高,性能也比原生的LLM好,但还是面临很多挑战。高级 RAG 和 模块化 RAG 的出现旨在解决 原始 RAG 中的特定缺陷。
| 特征比较 | RAG | 微调 (Fine-tuning) |
|---|---|---|
| 知识更新 | 直接更新检索知识库,确保信息保持最新状态,无需频繁重新培训,适用于动态数据环境。 | 存储静态数据,需要重新训练知识和数据更新。 |
| 外部知识 | 熟练利用外部资源,特别适用于文档或其他结构化/非结构化数据库。 | 可用于将预训练中从外部学习的知识与大型语言模型保持一致,但对于频繁更改的数据源可能不太实用。 |
| 数据处理 | 需要最少的数据处理和处理。 | 依赖于构建高质量的数据集,有限的数据集可能无法产生显著的性能提升。 |
| 模型定制 | 专注于信息检索和整合外部知识,但可能无法完全自定义模型行为或写作风格。 | 允许根据特定的语气或术语调整 LLM 行为、写作风格或特定领域知识。 |
| 可解释性 | 答案可以追溯到特定的数据源,提供更高的可解释性和可追溯性。 | 就像一个黑匣子,并不总是清楚为什么模型会以某种方式做出反应,可解释性相对较低。 |
| 计算资源 | 需要计算资源来支持与数据库相关的检索策略和技术。需要维护外部数据源集成和更新。 | 准备和管理高质量的训练数据集,定义微调目标以及提供相应的计算资源是必要的。 |
| 延迟要求 | 涉及数据检索,可能导致更高的延迟。 | 微调后的 LLM 可以在没有检索的情况下进行响应,从而降低延迟。 |
| 减少幻觉 | 本质上不太容易产生幻觉,因为每个答案都基于检索到的证据。 | 可以通过基于特定领域数据训练模型来帮助减少幻觉,但在面对不熟悉的输入时仍可能表现出幻觉。 |
| 道德和隐私问题 | 从外部数据库中存储和检索文本会产生道德和隐私问题。 | 由于训练数据中的敏感内容,可能会产生道德和隐私问题。 |
3.1 原始 RAG (Naive RAG)
原始 RAG (Naive RAG) 代表了早期研究方法,在 ChatGPT 广泛应用后迅速崭露头角。原始 RAG 的流程包括传统的索引、检索和生成步骤。原始 RAG 也被概括为一个“检索” - “阅读”框架 [Ma et al., 2023a]。
索引
用于从源获取数据并为其构建索引的管道通常处于脱机状态。具体来说,数据索引的构建涉及以下步骤:
-
数据索引: 包括清理和提取原始数据,将 PDF、HTML、Word、Markdown 等不同格式的文件转换成纯文本。
-
分块: 将加载的文本分割成更小的片段。由于语言模型处理上下文的能力有限,因此需要将文本划分为尽可能小的块。
-
嵌入和创建索引: 这一阶段涉及通过语言模型将文本编码为向量的过程。所产生的向量将在后续的检索过程中用来计算其与问题向量之间的相似度。由于需要对大量文本进行编码,并在用户提问时实时编码问题,因此嵌入模型要求具有高速的推理能力,同时模型的参数规模不宜过大。完成嵌入之后,下一步是创建索引,将原始语料块和嵌入以键值对形式存储,以便于日后进行快速且频繁的搜索。
检索
根据用户的输入,采用与第一阶段相同的编码模型将查询内容转换为向量。系统会计算问题向量与语料库中文档块向量之间的相似性,并根据相似度水平选出最相关的前 K 个文档块作为当前问题的补充背景信息。
生成
将给定的问题与相关文档合并为一个新的提示信息。随后,大语言模型(LLM)被赋予根据提供的信息来回答问题的任务。根据不同任务的需求,可以选择让模型依赖自身的知识库或仅基于给定信息来回答问题。如果存在历史对话信息,也可以将其融入提示信息中,以支持多轮对话。
原始 RAG 的挑战
原始 RAG 主要在三个方面面临挑战:检索质量、响应生成质量和增强过程。
-
检索质量: 该方面的问题是多方面的。最主要的问题是低精度,即检索集中的文档块并不都与查询内容相关,这可能导致信息错误或不连贯。其次是低召回率问题,即未能检索到所有相关的文档块,使得大语言模型无法获取足够的背景信息来合成答案。此外,过时信息也是一个挑战,因为数据冗余或过时可能导致检索结果不准确。
-
响应生成质量: 这方面的问题同样多样。最突出的问题是制造错误信息,即模型在缺乏足够上下文的情况下虚构答案。另一个问题是回答不相关,即模型生成的答案未能针对查询问题。进一步来说,生成有害或偏见性反应也是一个问题。
-
增强过程: 最后,增强过程面临几个重要挑战。特别重要的是,如何将检索到的文段的上下文有效融入当前的生成任务。如果处理不得当,生成的内容可能显得杂乱无章。当多个检索到的文段包含相似信息时,冗余和重复成为问题,这可能导致生成内容的重复。此外,如何判断多个检索到的文段对生成任务的重要性或相关性非常有挑战性,增强过程需要恰当地评估每个文段的价值。检索到的内容可能具有不同的写作风格或语调,增强过程需调和这些差异,以确保最终输出的一致性。最后,生成模型可能会过度依赖于增强信息,导致生成的内容仅是重复检索到的信息,而缺乏新的价值或综合信息。
3.2 高级 RAG
为了克服 原始 RAG 的局限性,高级 RAG 进行了针对性的改进。在检索生成质量方面,高级 RAG 结合了检索前和检索后的方法。为了解决原始 RAG 遇到的索引问题,高级 RAG 通过滑动窗口、细粒度分割和元数据等方法优化了索引。同时,提出了多种优化检索过程的方法。在具体实现方面,高级 RAG 可以通过流水线或端到端方式进行调整。
预检索处理
- 优化数据索引
优化数据索引的目的是提高索引内容的质量。目前,为此目的采用了五种主要策略:增加索引数据的粒度、优化索引结构、添加元数据、对齐优化和混合检索。
-
增强数据粒度:索引前优化的目标是提高文本的标准化、一致性,并确保事实准确性和上下文丰富性,以保证 RAG 系统的性能。文本标准化涉及删除不相关的信息和特殊字符,以提高检索器的效率。在一致性方面,首要任务是消除实体和术语中的歧义,同时消除重复或冗余信息以简化检索器的关注点。确保事实准确性至关重要,应尽可能验证每条数据的准确性。为了适应系统在现实世界中的交互上下文,上下文保留可以通过添加另一层具有特定域注释的上下文来实现,并通过用户反馈循环进行持续更新。时间敏感性是必不可少的上下文信息,应设计机制来刷新过时的文档。总之,优化索引数据的重点应放在清晰度、上下文和正确性上,以使系统高效可靠。下面介绍最佳实践。
-
优化索引结构:这可以通过调整块的大小、更改索引路径和合并图形结构信息来实现。调整块(从小到大)的方法包括收集尽可能多的相关上下文并最小化噪声。在构建 RAG 系统时,块大小是一个关键参数。有不同的评估框架来比较各个块的大小。LlamaIndex 利用 GPT4 评估数据的保真度和相关性,LLaMA[Touvron et al., 2023] 索引能自动评估不同块化方法的效果。跨多个索引路径查询的方法与以前的元数据筛选和分块方法密切相关,并且可能涉及同时跨不同索引进行查询。标准索引可用于查询特定查询,也可以使用独立索引基于元数据关键字(如特定“日期”索引)进行搜索或筛选。引入图结构涉及将实体转换为节点,并将其关系转换为关系。这可以通过利用节点之间的关系来提高准确性,尤其是对于多跃点问题。使用图形数据索引可以增加检索的相关性。
-
添加元数据信息:此处的重点是将引用的元数据嵌入到块中,例如用于筛选的日期和用途。添加元数据(如参考文献的章节和小节)也有助于改进检索。当我们将索引划分为多个块时,检索效率就成为一个问题。首先筛选元数据可以提高效率和相关性。
-
对齐优化:此策略主要解决文档之间的对齐问题和差异。对齐概念包括引入假设问题,创建适合在每个文档中回答的问题,以及将这些问题嵌入(或替换)到文档中。这有助于解决文档之间的对齐问题和差异。
-
混合检索:这种策略的优势在于利用不同检索技术的优势。智能组合各种技术,包括基于关键字的搜索、语义搜索和向量搜索,适应不同的查询类型和信息需求,确保一致地检索最相关和上下文丰富的信息。混合检索可以作为检索策略的有力补充,提高 RAG 管道的整体性能。
-
嵌入 (Embedding)
-
微调嵌入:微调嵌入模型直接影响 RAG 的有效性。微调的目的是增强检索到的内容和查询之间的相关性。微调嵌入的作用类似于在生成语音之前调整耳朵,优化检索内容对生成输出的影响。通常,微调嵌入的方法分为在特定领域上下文中调整嵌入和优化检索步骤的类别。特别是在处理不断发展或罕见的术语的专业领域,这些定制的嵌入方法可以提高检索的相关性。BGE[BAAI, 2023]嵌入模型是一个经过微调的高性能嵌入模型,例如由 BAAI 3 开发的 BGE-large-EN。为了对 BGE 模型进行微调,首先使用诸如 gpt-3.5-turbo 这样的大语言模型(LLM)根据文档块制定问题,其中问题和答案(文档块)构成了微调过程中的训练对。
-
动态嵌入:动态嵌入根据单词出现的上下文进行调整,这与对每个单词使用单个向量的静态嵌入不同。例如,在像 BERT 这样的转换器模型中,同一个单词可以根据周围的单词具有不同的嵌入。有证据表明,在 OpenAI 的文本嵌入ada-002 模型中,出现了意想不到的高余弦相似度结果,尤其是在文本长度小于 5 个标记的情况下。理想情况下,嵌入应包含尽可能多的上下文,以确保“健康”的结果。OpenAI 的 embeddings-ada-02 建立在 GPT 等大型语言模型的原理之上,比静态嵌入模型更复杂,可以捕获一定程度的上下文。虽然它在上下文理解方面表现出色,但它对上下文的敏感度可能不如 GPT4 等最新的全尺寸语言模型。
检索后处理流程
从数据库中检索有价值的上下文后,将其与输入查询合并到 LLM 中会带来挑战。一次向 LLM 提交所有相关文件可能会超出上下文窗口限制。将大量文档连接起来形成冗长的检索提示是无效的,会引入噪音并阻碍 LLM 对关键信息的关注。要解决这些问题,需要对检索到的内容进行额外处理。
-
ReRank 重新排名:重新排名以将最相关的信息重新定位到提示的边缘是一个简单的想法。这个概念已经在 LlamaIndex、LangChain 和 HayStack 等框架中实现[Blagojevi, 2023]。例如,Diversity Ranker 根据文档多样性确定重新排序的优先级,而 LostInTheMiddleRanker 则交替将最佳文档放在上下文窗口的开头和结尾。同时,为了解决解释基于向量的模拟搜索语义相似性的挑战,cohereAI rerank[Cohere, 2023]、bgererank 或 LongLLMLingua [Jiang et al., 2023a]等方法重新计算相关文本和查询之间的语义相似性。
-
Prompt 压缩:研究显示,检索文档中的噪音会对 RAG 性能产生不利影响。在处理的后期阶段,我们主要关注于压缩无关紧要的上下文,凸显关键段落,并缩短整体的上下文长度。例如 Selective Context[Litman et al., 2020] 和 LLMLingua [Anderson et al., 2022]等方法,它们运用小型语言模型来计算提示之间的互信息或困惑度,以此估算各个元素的重要性。不过,在 RAG 或者长篇上下文的情境中,这些方法可能会遗失关键信息。Recomp [Xu et al., 2023a]通过训练不同精细程度的压缩器来应对这一问题。在处理长篇上下文 [Xu et al., 2023b]时,这种方法通过分解和压缩来处理大量的上下文内容,而“在记忆迷宫中漫步”[Chen et al., 2023a]则设计了一个分层次的总结树来增强大语言模型(LLM)对关键信息的感知能力。
-
RAG 流水线优化:检索过程的优化旨在提高RAG系统的效率和信息质量,目前的研究主要集中在智能组合各种搜索技术,优化检索步骤,引入认知回溯的概念,灵活应用多样化的查询策略,并利用嵌入相似性。这些努力共同努力在RAG检索中实现效率和上下文信息的丰富性之间的平衡。
-
探索混合搜索:通过智能地融合各种技术,如基于关键字的搜索、语义搜索和向量搜索,RAG系统可以利用每种方法的优势。这种方法使 RAG 系统能够适应不同的查询类型和信息需求,确保一致地检索最相关和上下文最丰富的信息。混合搜索可作为检索策略的有力补充,增强 RAG 管道的整体性能。
-
递归检索和查询引擎:在 RAG 系统中优化检索的另一种强大方法是实现递归检索和复杂的查询引擎。递归检索需要在初始检索阶段获取较小的文档块,以捕获关键的语义含义。在此过程的后期阶段,将向语言模型 (LM) 提供具有更多上下文信息的较大块。这种两步检索方法有助于在效率和上下文丰富的响应之间取得平衡。
-
StepBack-prompt 方法: 集成到 RAG 流程中的 StepBack-prompt 方法[Zheng et al., 2023] 促使大语言模型 (LLM) 在处理具体案例时能够退一步,转而思考背后的普遍概念或原则。研究发现,这种结合后向提示的方法在处理各种复杂、推理密集的任务时表现卓越,充分展现了其与 RAG 的良好兼容性。这种方法既能用于后向提示的答案生成,也能用于最终的问答环节。
-
子查询:可以在不同的场景中采用各种查询策略,包括使用 LlamaIndex 等框架提供的查询引擎、使用树查询、使用向量查询或使用最基本的块顺序查询。
-
HyDE:这种方法基于这样的假设,即生成的答案在嵌入空间中可能比直接查询更接近。利用 LLM,HyDE 生成一个假设的文档(答案)来响应查询,嵌入该文档,并利用这种嵌入来检索与假设文档相似的真实文档。与基于查询寻求嵌入相似性相比,该方法强调从答案到答案的嵌入相似性。但是,它可能不会始终如一地产生有利的结果,尤其是在语言模型不熟悉所讨论主题的情况下,这可能会导致容易出错的实例的生成增加。
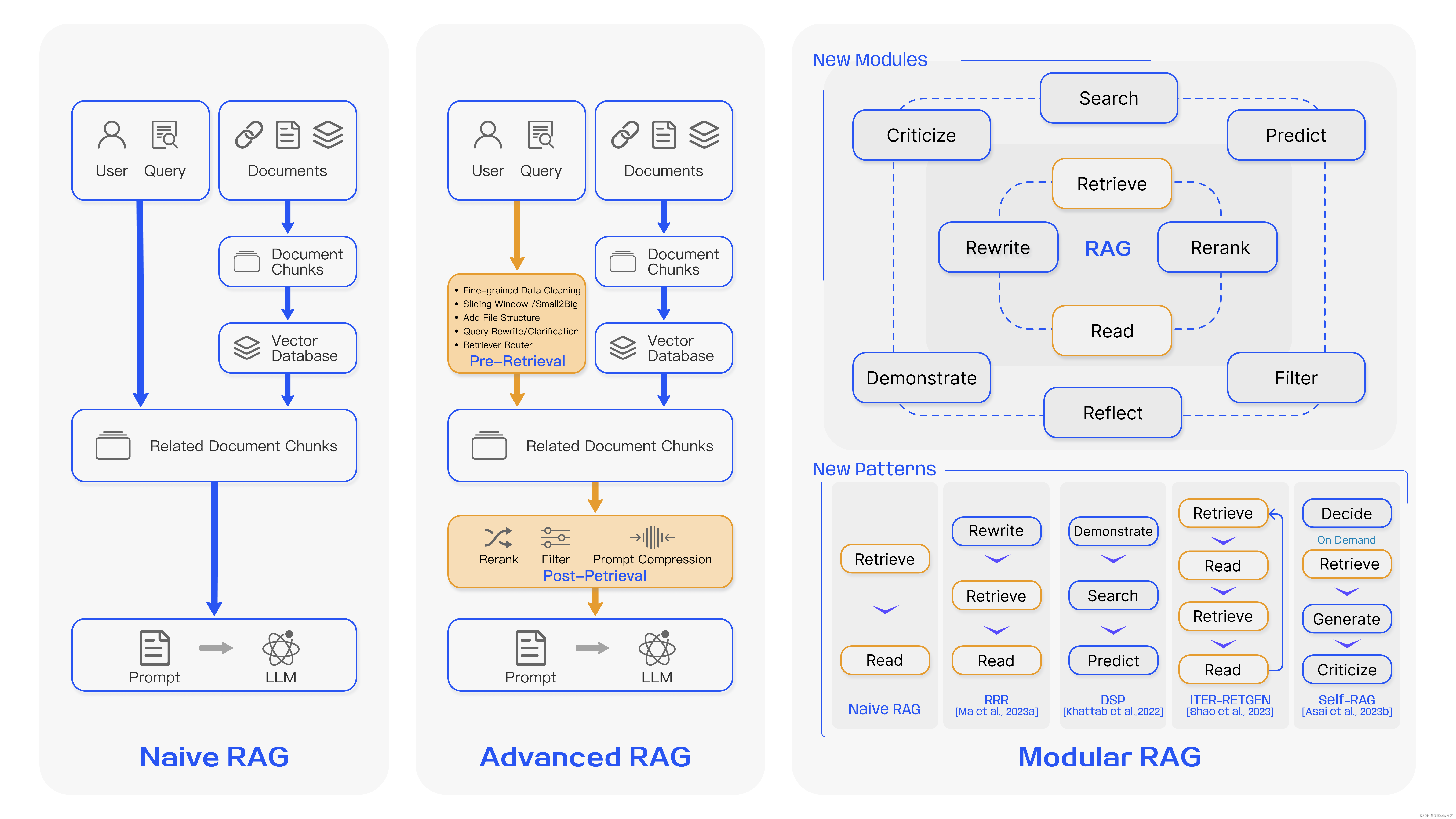
模块化 RAG
模块化的 RAG 结构打破了传统的 Naive RAG 索引、检索和生成框架,在整个过程中提供了更大的多样性和灵活性。一方面,它集成了多种方法来扩展功能模块,例如在相似性检索中加入搜索模块,并在检索器中应用微调方法[Lin et al., 2023]。此外,具体问题导致了重组 RAG 模块的出现[Yu et al., 2022]和迭代方法,如 [Shao et al., 2023]。模块化 RAG 范式正在成为 RAG 领域的主流,允许跨多个模块的序列化管道或端到端训练方法。三种RAG范式之间的比较如图3所示。
新模块
- 搜索模块:与 Naive/Advanced RAG 中查询和语料库之间的相似性检索不同,搜索模块针对特定场景量身定制,使用 LLM 生成的代码、查询语言(例如 SQL、Cypher)或其他自定义工具对(附加)语料库进行直接搜索。用于搜索的数据源可以包括搜索引擎、文本数据、表格数据或知识图谱[Wang et al., 2023c]。
- 内存模块:利用LLM本身的内存功能来指导检索,其原理涉及查找与当前输入最相似的内存。Self-mem [Cheng et al., 2023b]迭代地使用检索增强生成器来创建一个无界的记忆池,将“原始问题”和“双重问题”结合起来。检索增强的生成模型可以使用自己的输出来增强自身,使文本更接近推理过程中的数据分布,使用模型自己的输出而不是训练数据[Wang et al., 2022a]。
- 额外生成模块: 面对检索内容中的冗余和噪声问题,这个模块通过大语言模型生成必要的上下文,而非直接从数据源进行检索[Yu et al., 2022]。通过这种方式,由大语言模型生成的内容更可能包含与检索任务相关的信息。
- 任务自适应模块:UPRISE[Cheng et al., 2023a] 专注于转换 RAG 以适应各种下游任务,自动从预先构建的数据池中检索给定零样本任务输入的提示,增强了任务和模型的通用性。PROMPTAGATOR[Dai et al., 2022]利用 LLM 作为少样本查询生成器,并根据生成的数据创建特定于任务的检索器。利用LLM的泛化功能,PROMPTAGATOR只需几个例子就可以创建特定于任务的端到端检索器。
- 对齐模块:查询和文本之间的对齐一直是影响 RAG 有效性的关键问题。在模块化 RAG 时代,研究人员发现,在检索器中添加可训练的适配器模块可以有效缓解对齐问题。PRCA[Yang et al., 2023b] 利用强化学习来训练由 LLM 奖励驱动的上下文适配器,位于检索器和生成器之间。 它通过在标记的自回归策略内的强化学习阶段最大化奖励来优化检索到的信息。 AAR[Yu et al., 2023b]提出了一个通用插件,该插件从已知来源的LLM中学习LM偏好,以帮助未知或非协同微调的LLM。 RRR[Ma et al., 2023a]设计了一个模块,用于基于强化学习重写查询,以使查询与语料库中的文档保持一致。
- 验证模块: 在现实世界中,我们无法总是保证检索到的信息的可靠性。检索到不相关的数据可能会导致大语言模型产生错误信息。因此,可以在检索文档后加入一个额外的验证模块,以评估检索到的文档与查询之间的相关性,这样做可以提升 RAG[Yu et al., 2023a] 的鲁棒性。
新模式
模块化 RAG 的组织方法是灵活的,允许根据特定问题上下文替换或重新配置 RAG 流程中的模块。对于朴素 RAG,它由检索和生成两个模块组成(在一些文献中称为读取或合成),该框架提供了适应性和丰富性。本研究主要探讨两种组织范式,包括模块的添加或替换,以及模块间组织流程的调整。
- 添加或替换模块:添加或替换模块的策略需要保持 检索-读取(Retrieval-Read)的结构,同时引入其他模块以增强特定功能。RRR[Ma et al.,2023a] 提出了重写-检索-读取(RewriteRetrieve-Read)过程,利用 LLM 性能作为重写模块强化学习的奖励。这允许重写器调整检索查询,从而提高读取器的下游任务性能。同样,模块可以在 Generate-Read[Yu et al.,2022] 等方法中选择性地替换,其中 LLM 生成模块取代了检索模块。复述-读取[Sun et al., 2022] 则是将传统的外部检索转变为从模型权重中检索,首先由大语言模型记忆与任务相关的信息,然后生成处理知识密集型自然语言处理任务所需的输出。
- 调整模块间的工作流程:在调整模块间流程的领域,重点在于加强语言模型与检索模型之间的互动。DSP[Khattab et al., 2022] 引入了展示 - 搜索 - 预测的框架,将上下文学习系统视为一个明确的程序,而不是简单的终端任务提示,以此来应对知识密集型的任务。 ITER-RETGEN[Shao et al., 2023] 则是使用生成内容来指导检索,通过迭代执行“检索增强生成”和“生成增强检索”,形成一种检索 - 阅读 - 检索 - 阅读的工作流。Self-RAG[Asai et al., 2023b] 则采用决策 - 检索 - 反思 - 阅读的流程,引入了一个用于主动判断的模块。这种适应性和多样性的方法使得在模块化 RAG 框架中可以动态地组织各种模块。
4 检索器
在 RAG (检索增强生成)的上下文中,“R”代表检索,在 RAG 管道中起着从庞大的知识库中检索前 k 个相关文档的作用。然而,制作一只高质量的猎犬是一项艰巨的任务。在本章中,我们围绕三个关键问题进行讨论:1)如何获得准确的语义表示?2)如何匹配查询和文档的语义空间?3) 如何使检索器的输出与大型语言模型的首选项保持一致?
4.1 如何获得准确的语义表示?
在 RAG 中,语义空间是映射查询和文档的多维空间。当我们执行检索时,它是在语义空间内测量的。如果语义表达式不准确,那么它对RAG的影响是致命的,本节将介绍两种方法来帮助我们构建准确的语义空间。
块优化
在处理外部文档时,第一步是分块以获得细粒度的特征。然后嵌入块。但是,嵌入过大或过小的文本块可能无法获得良好的结果。因此,为语料库中的文档找到最佳块大小对于确保搜索结果的准确性和相关性至关重要。
选择分块策略时,重要的考虑因素包括:要编制索引的内容的特征、使用的嵌入模型及其最佳块大小、用户查询的预期长度和复杂性,以及如何在特定应用程序中使用检索结果。例如,应为较长或较短的内容选择不同的分块模型。不同的嵌入模型,如 Sentence-Transformer 和 text-embedding-ada-002,在处理不同大小的文本块时效果各异;例如,Sentence-Transformer 更适合单句处理,而 text-embedding-ada-002 更适合处理包含 256 或 512 Token 的文本块。用户问题文本的长度和复杂性,以及应用程序的特定需求(如语义搜索或问答),也会影响分块策略的选择。这可能与选用的大语言模型的 Token 限制直接相关,因此可能需要调整块大小。实际上,准确的查询结果是通过灵活应用多种分块策略来实现的,并没有最佳策略,只有最适合的策略。
目前RAG的研究采用了多种块优化方法来提高检索效率和准确性。滑动窗口技术等技术通过多次检索聚合全局相关信息来实现分层检索。Small2big 技术在搜索过程中利用较小的文本块,并为语言模型提供较大的附属文本块进行处理。摘要嵌入技术对文档摘要执行 Top K 检索,提供完整的文档上下文。元数据筛选技术利用文档元数据进行筛选。图形索引技术将实体和关系转换为节点和连接,从而显著增强了多跃点问题上下文中的相关性。这些方法的合并改善了检索结果并增强了RAG的性能。
微调嵌入模型
在确定了 Chunk 的适当大小之后,我们需要通过一个嵌入模型(Embedding model)将 Chunk 和查询嵌入到语义空间中。因此,嵌入模型是否能有效代表整个语料库变得极其重要。如今,一些出色的嵌入模型已经问世,例如 UAE[AngIE, 2023]、Voyage[VoyageAI, 2023]、BGE[BAAI, 2023] 等,它们在大规模语料库上预训练过。但在特定领域中应用时,这些模型可能无法准确地反映领域特定的语料信息。此外,为了确保模型能够理解用户查询与内容的相关性,对嵌入模型进行任务特定的微调至关重要,否则未经微调的模型可能无法满足特定任务的需求。因此,对嵌入模型进行微调对于其下游应用是必不可少的。
领域知识微调
嵌入模型微调的两个基本范式包括领域知识微调。为了让嵌入模型准确理解领域特定信息,我们需要构建专门的领域数据集来对嵌入模型进行微调。
然而,嵌入模型的微调与常规语言模型的微调不同,主要区别在于所使用的数据集。当前微调嵌入模型的主流方法使用的数据集包括查询(Queries)、语料库(Corpus)和相关文档(Relevant Docs)。嵌入模型基于查询在语料库中检索相关文档,然后根据查询的相关文档是否命中作为衡量模型的标准。
在构建数据集、微调模型和评估过程中,每个部分都可能遇到各种挑战。LlamaIndex [Liu, 2023] 专门为嵌入模型的微调过程引入了一系列关键类别和功能,大大简化了这一过程。通过准备领域知识的语料库并利用其提供的方法,我们可以轻松获得适合特定领域需求的专业嵌入模型。
对下游任务的微调
根据下游任务微调嵌入模型同样重要。使用 RAG 处理特定任务时,已有研究通过大语言模型 (LLM) 的功能来微调嵌入模型。例如,PROMPTAGATOR[Dai et al., 2022] 将大语言模型用作少样本查询生成器,基于此生成的数据创建了针对特定任务的检索器,这样做可以解决一些领域由于数据不足而难以进行常规监督微调的问题。LLM-Embedder[Zhang et al., 2023a] 则利用大语言模型为多个特定任务中的数据输出奖励值,并通过硬性标记数据集和来自 LLM 的软性奖励对检索器进行了双重微调。
这种做法在一定程度上通过引入领域知识和针对特定任务的微调,改善了语义表达。但是,这种训练方式得到的检索器并不总是直接有益于大语言模型,因此有研究通过从 LLM 获取反馈信号,直接对嵌入模型进行了监督微调。(更多细节将在第 4.4 节介绍)
4.2 如何匹配查询和文档的语义空间
在 RAG 应用程序中,一些检索器使用相同的嵌入模型对查询和文档进行编码,而另一些检索器则使用两个模型分别对查询和文档进行编码。而且,用户的原始查询可能存在表达不良、语义信息缺失等问题。因此,对齐用户查询和文档的语义空间是非常必要的。本节介绍实现此目标的两项关键技术。
查询重写
一种直接的方式是对查询进行重写。
如 Query2Doc[Wang et al., 2023b] 和 ITER-RETGEN[Shao et al., 2023] 所指出的,可以利用大语言模型的能力生成一个指导性的伪文档,然后将原始查询与这个伪文档结合,形成一个新的查询。
而在 HyDE[Gao et al., 2022] 中,则是通过文本标识符来建立查询向量,利用这些标识符生成一个相关但可能并不存在的“假想”文档,它的目的是捕捉到相关的模式。
Ma 团队于 2023 年提出的 RRR 框架,开创了一种新的方法,将检索和阅读的顺序进行了反转,专注于如何重新编写查询。在这个方法中,首先利用大语言模型来生成搜索查询,然后通过网络搜索引擎找到相关信息,最后用一个小型的语言模型来帮助这个大模型进行所谓的“训练重写”,以提高其效果。Zheng 团队在 2023 年提出的 STEP-BACKPROMPTING 方法,能够使大语言模型进行更深层次的抽象思考,抽取出关键的概念和原则,并基于这些进行信息检索。
此外,多查询检索方法让大语言模型能够同时产生多个搜索查询。这些查询可以同时运行,它们的结果一起被处理,特别适用于那些需要多个小问题共同解决的复杂问题。
嵌入转换
如果存在重写查询等粗粒度方法,则还应该有特定于嵌入操作的更细粒度的实现。在 LlamaIndex[Liu,2023] 中,可以在查询编码器之后连接一个适配器,并微调适配器以优化查询嵌入的表示,将其映射到更适合特定任务的潜在空间。当查询和外部文档的数据结构不同时,例如非结构化查询和结构化外部文档,使查询与文档保持一致非常重要。SANTA[Li et al.,2023d] 提出了两种预训练方法,使检索者感知结构化信息:1)利用结构化数据和非结构化数据之间的自然对齐关系进行对比学习,进行结构化感知预训练。2)掩码实体预测,它设计了一种面向实体的掩码策略,并要求语言模型填充掩码实体。
4.3 调整检索器结果以适应大语言模型的需求
在 RAG(Retrieval-Augmented Generation)流程中,即便我们采用各种技术提升检索效果,最终对 RAG 的整体性能可能仍无明显提升。原因在于检索到的文档可能并不符合大语言模型(LLM)的需求。本节将介绍两种方法,以使检索器的输出更好地符合 LLM 的偏好。
LLM 监督下的训练 众多研究通过从大语言模型获取的反馈信号来调整嵌入模型。AAR[20] 通过一种基于编解码器架构的语言模型(LM),为预训练的检索器提供监督信号。检索器通过分析 LM 偏好的文档(基于 FiD 的交叉注意力分数),进行微调,使用了“硬负样本采样”和传统的交叉熵损失方法。经过这样的训练,检索器能直接用于提升新的目标 LLM,在相关任务中取得更好的成绩。检索器的训练损失公式如下:
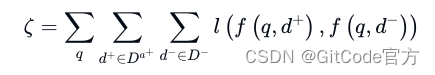
其中,Da+ 是 LLM 偏好的文档集,Da- 则是不受偏好的文档集。
ι
\iota
ι 代表传统的交叉熵损失函数。研究最后指出,LLM 可能更倾向于关注易于阅读而非信息量丰富的文档。
REPLUG[14] 则通过结合检索器和 LLM 计算出的文档概率分布,采用监督训练方式。训练过程中,通过计算 KL 散度来调整检索模型,使其性能得到提升。这种方法简单有效,利用 LM 作为监督信号,无需依赖特定的交叉注意力机制。检索器的训练损失公式如下:
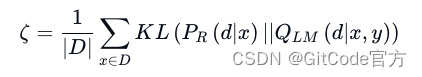
这里,D 表示输入上下文集合,PR 是文档的检索可能性,QLM 则是每份文档基于 LM 的概率。
UPRISE[Cheng et al., 2023a] 同样采用了冻结的大语言模型来对 Prompt Retriever 进行微调。
在这些研究中,无论是语言模型还是检索器,它们都以提示输入对作为输入。这些模型使用大语言模型 (Large Language Model) 提供的分数来指导检索器的训练,这相当于用大语言模型来对数据集进行标注。
Atlas[Izacard et al., 2022] 提出了四种微调监督嵌入模型的方法。其中之一,注意力蒸馏 (Attention Distillation),通过语言模型在生成输出时产生的跨注意力分数来进行学习。而 EMDR2 则运用期望最大化 (Expectation-Maximization) 算法,将检索到的文档作为隐藏变量,进行模型训练。困惑度蒸馏 (Perplexity Distillation) 直接利用模型生成的 Token 的困惑度 (perplexity) 作为训练指标。LOOP 则引入了一种新的基于文档删除对大语言模型预测影响的损失函数,这为模型更好地适应特定任务提供了有效的训练方法。
插入适配器
然而,微调嵌入模型可能会遇到一些挑战,例如使用 API 实现嵌入功能或本地计算资源不足。因此,一些研究选择外接适配器来进行模型对齐。PRCA[Yang et al., 2023b] 在上下文提取阶段和奖励驱动阶段训练适配器,并通过基于 Token 的自回归 (autoregressive) 策略来优化检索器的输出。
TokenFiltering[Berchansky et al., 2023] 的方法通过计算跨注意力分数,挑选出得分最高的输入 Token,有效地进行 Token 过滤。RECOMP[Xu et al., 2023a] 提出了提取和生成压缩器的概念,这些压缩器通过选择相关的句子或合成文档信息来生成摘要,实现多文档查询聚焦摘要。此外,PKG[Luo et al., 2023] 这一新颖方法,通过指令性微调将知识注入到一个白盒模型中,并直接替换了检索器模块,以便直接根据查询输出相关文档。
5 生成组件
在 RAG 系统中,生成组件是核心部分之一,它的职责是将检索到的信息转化为自然流畅的文本。这一设计灵感源自于传统语言模型,但不同于一般的生成式模型,RAG 的生成组件通过利用检索到的信息来提高文本的准确性和相关性。在 RAG 中,生成组件的输入不仅包括传统的上下文信息,还有通过检索器得到的相关文本片段。这使得生成组件能够更深入地理解问题背后的上下文,并产生更加信息丰富的回答。此外,生成组件还会根据检索到的文本来指导内容的生成,确保生成的内容与检索到的信息保持一致。正是因为输入数据的多样性,我们针对生成阶段进行了一系列的有针对性工作,以便更好地适应来自查询和文档的输入数据。
5.1 如何通过后检索处理提升检索结果?
在未调整的大型语言模型方面,大多数研究都依赖于 GPT4 等公认的大型语言模型[OpenAI,2023] 来利用其强大的内部知识来全面检索文档知识。然而,这些大型模型的固有问题(例如上下文长度限制和对冗余信息的脆弱性)仍然存在。为了缓解这些问题,一些研究在检索后处理方面做出了努力。检索后处理是指对检索器从大型文档数据库中检索到的相关信息进行进一步处理、过滤或优化的过程。其主要目的是提高检索结果的质量,以更好地满足用户需求或后续任务。它可以理解为对检索阶段获得的文件进行再处理的过程。检索后处理的操作通常涉及信息压缩和结果重新排序。
信息压缩
信息压缩方面,即使检索器能够从庞大的知识库中提取相关信息,我们仍然面临处理大量检索文档信息的挑战。一些研究试图通过扩大大型语言模型的上下文长度来解决这个问题,但当前的大模型还是受到上下文限制。在这种情况下,进行信息浓缩变得必要。总体来说,信息浓缩的重要性主要体现在减少信息噪音、解决上下文长度限制和提升生成效果等方面。
PRCA [Yang et al., 2023b] 解决这一问题的方法是训练了一个信息提取器。在提取上下文的阶段,这个提取器能够根据给定的输入文本 Sinput,生成一个输出序列 Cextracted,这个序列代表了输入文档中的精简上下文。训练的目标是让Cextracted尽可能接近实际的上下文Ctruth。他们使用的损失函数定义如下:
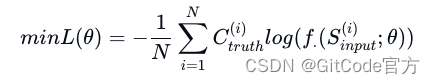
这里,f.表示信息提取器的功能,而
θ
\theta
θ 是其参数。另一个项目 RECOMP[11] 采用了对比学习法来训练一个信息浓缩器。在每个训练样本中,会有一个正样本和五个负样本。该项目在此过程中采用了对比损失方法 [13] 来训练编码器。具体的优化目标表达如下:
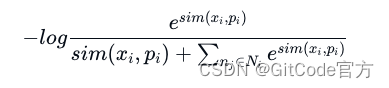
其中 Xi代表训练数据,pi是正样本,nj是负样本,sim(x,y) 用于计算 x 和 y 之间的相似度。还有一项研究则是致力于进一步减少文档的数量,以此提高模型回答问题的准确度。 [Ma et al., 2023b] 提出了一种新的“Filter-Ranker”模式,它结合了大语言模型 (LLMs) 和小语言模型 (SLMs) 的优点。在这种模式下,SLMs 充当过滤器,LLMs 则作为排序器。通过激励 LLMs 对 SLMs 筛选出的难点样本进行重新排序,研究表明,这在各类信息提取 (IE) 任务中都取得了显著的提升。
重新排序
重新排序模型的关键作用在于优化从检索器检索到的文档集。当添加额外的上下文时,LLM 会遇到性能下降和回顾性性能,而重新排序为解决此问题提供了有效的解决方案。核心思想涉及重新排列文档记录,将最相关的项目放在顶部,从而将文档总数减少到固定数量。这不仅解决了检索过程中可能遇到的上下文窗口扩展问题,还有助于提高检索效率和响应能力[Zhuang et al.,2023]。
在重新排序过程中引入上下文压缩,旨在仅根据给定的查询上下文返回相关信息。这种方法的双重意义在于,通过减少单个文档的内容和过滤整个文档,集中显示检索结果中最相关的信息。因此,重排序模型在整个信息检索过程中起到了优化和提炼的作用,为后续的LLM处理提供了更有效、更准确的输入。
5.2 如何优化生成器应对输入数据?
在RAG模型中,生成器的优化是架构的关键组成部分。生成器的任务是获取检索到的信息并生成相关文本,从而提供模型的最终输出。优化生成器的目的是确保生成的文本既自然又有效利用检索到的文档,以更好地满足用户的查询需求。
在典型的大型语言模型 (LLM) 生成任务中,输入通常是查询。在 RAG 中,主要区别在于输入不仅包括查询,还包括检索器检索到的各种文档(结构化/非结构化)。引入附加信息可能会对模型的理解产生重大影响,尤其是对于较小的模型。在这种情况下,微调模型以适应查询 + 检索文档的输入变得尤为重要。具体来说,在向微调模型提供输入之前,通常会对检索器检索到的文档进行检索后处理。需要注意的是,RAG 中对生成器进行微调的方法本质上类似于 LLM 的一般微调方法。这里,我们将简要介绍一些具有代表性的工作,包括数据(格式化/未格式化)和优化函数。
通用优化过程
通用优化过程涉及训练数据中的输入输出对,目的是让模型学会根据输入 x 生成输出 y。
在 Self-mem[Cheng et al., 2023b] 的研究中,采用了一种传统训练方法。给定输入 x 后,检索出相关文档 z(文中选取最相关的一个),然后结合 (x, z),模型便生成输出 y。
论文探讨了两种主流微调方法,分别是联合编码器 (Joint-Encoder) [Arora et al., 2023, Wang et al., 2022b, Lewis et al., 2020] 和双编码器 (Dual-Encoder) [Xia et al., 2019, Cai et al., 2021, Cheng et al., 2022]。
在联合编码器模式下,使用的是标准的编解码器模型,编码器首先处理输入,然后解码器通过注意力机制将编码结果结合起来,自回归地生成 Token。

在双编码器系统中,构建了两个独立的编码器,各自负责输入(查询、上下文)和文档的编码。接着,这些输出将依次经由解码器处理,进行双向交叉注意力处理。作者采用了 Transformer [Vaswani 等人,2017] 作为两种架构的基础,并对 Gξ 负对数似然(NLL)损失进行了优化。
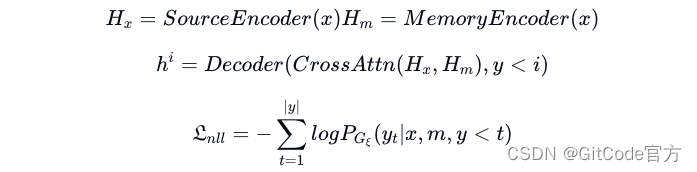
运用对比学习
在训练数据准备阶段,通常会生成输入和输出之间的交互对,以此进行对比学习。
在这种情境下,模型仅能接触到一个实际的输出,可能会导致“暴露偏差”问题 [Ranzato 等人,2015]:即在训练阶段,模型仅接触到单一的正确反馈,无法了解其他可能的生成 Token。
这可能影响模型在实际应用中的表现,因为它可能过度适应训练数据中的特定反馈,而不是有效泛化到其他情境。因此,SURGE [Kang 等人,2023] 提出了一种基于图文的对比学习方法。对于输入和输出之间的任何一对交互,这种对比学习方法的目标可以这样定义:
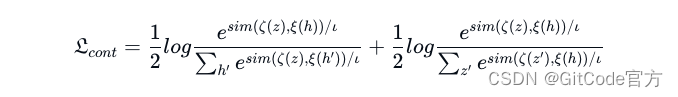
其中 ζ,ξ 是可学习的线性投影层。z 代表编码器中图形的平均表征,h 是解码器中的平均表征。z‘ h’ 分别代表相应的负面样本。
在这段文本中,符号 ‘h’ 和 ‘z’ 代表负样本。模型通过采用对比学习(contrastive learning)的方法,可以更有效地学习生成各种合理的回复,而不局限于训练数据中的示例。这种方法有助于降低过拟合的风险,从而在真实世界的场景中提高模型的泛化能力。
在处理涉及结构化数据的检索任务时,SANTA[Li et al., 2023d] 的研究采用了三个阶段的训练过程,旨在深入理解数据的结构和语义信息。
具体地,在检索器的训练阶段,使用了对比学习来优化查询和文档的嵌入表示,其优化目标如下:
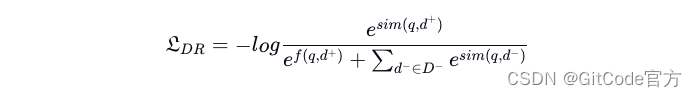
在这里,q 和 d 分别是编码器处理后的查询和文档。d- 和 d+ 分别代表负样本和正样本。在生成器的初期训练阶段,我们通过对比学习来对齐结构化数据和非结构化数据的相关文档描述。其优化目标与上述相同。
在生成器的后期训练阶段,我们受到参考文献 [16, 17] 的启发,认识到在检索任务中,实体语义对于学习文本数据表示的重要性。因此,我们首先对结构化数据进行实体识别,然后在生成器训练数据的输入部分对这些实体应用掩码,使得生成器能够预测这些被掩盖的部分。此阶段的优化目标为:
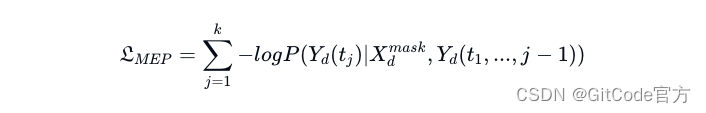
在序列 Yd中, Yd(yj 表示第 j 个 Token。这里,Yd =< mask >1,ent1,…,< mask >n,entn 表示一个包含了部分被掩盖的实体信息的序列。训练过程中,我们通过分析上下文中的信息来揭示这些被掩盖的实体,理解文本的结构性语义,并将其与结构化数据中的相关实体对应起来。我们的目标是让语言模型能够有效填补这些缺失的信息,并更深入地理解实体的含义[21]。
6 RAG 技术的增强手段
本章主要从增强阶段、增强数据源和增强过程三个维度进行梳理,阐述RAG发展中的关键技术。RAG核心组件的分类如图4所示。
6.1 RAG 在各个增强阶段的应用
RAG 作为一项知识密集型任务,RAG 在语言模型训练的预训练、微调和推理阶段采用不同的技术方法。
预训练阶段
在预训练阶段,研究人员努力通过检索方法来提升预训练语言模型在开放领域问答中的表现。预训练模型中隐含知识的识别和扩充是一项挑战。2023 年,Arora et al. 提出了 REALM,一种更为模块化且易于理解的知识嵌入方法。REALM 采用掩蔽语言模型(MLM)的方式,将预训练和微调视为一种先检索再预测的过程,即语言模型根据掩蔽的句子 x 预测掩蔽的 Token y,建模 P(x|y)。
2022 年,Borgeaud et al. 提出的 RETRO 则是利用检索增强来预训练自回归语言模型,它通过从大量标记数据集中检索信息,实现了从零开始的大规模预训练,并显著减少了模型的参数量。
RETRO 不仅与 GPT 模型共享主体结构,还增加了一个 RETRO 编码器,用于编码从外部知识库检索得到的相关实体的特征。
更进一步,RETRO 在其解码器的 Transformer 结构中加入了分块交叉注意力层,有效地融合了来自 RETRO 编码器的检索信息。这使 RETRO 在处理复杂问题时,比标准的 GPT 模型表现出更低的困惑度。此外,RETRO 在更新语言模型存储的知识时更加灵活,可以通过更新检索数据库来实现,无需重新训练整个模型 [Petroni et al.,2019]。
Atla[Izacard et al., 2022]采用了与 T5 架构[Raffel et al., 2020]相似的方法,在预训练和微调阶段都融入了检索机制。在开始预训练之前,Atla 会先用已经预训练好的 T5 初始化其编解码器的大语言模型基础,并用预训练好的 Contriever 初始化密集检索器。
在预训练的过程中,相较于传统的预训练模型,这种方法通过减少参数的使用,提高了效率。它特别擅长处理需要大量知识的任务,并可以通过在特定领域的语料库上训练来构建专门的模型。但这种方法也有其不足之处,如需要大量预训练数据、更多的训练资源,以及更新速度较慢。特别是当模型尺寸增大时,基于检索的训练成本会相对增高。尽管存在这些限制,这种方法在增强模型的鲁棒性方面表现出色。一旦训练完成,基于纯预训练的检索增强模型就不再需要外部库的依赖,从而提高了生成速度和操作效率。
微调阶段
在下游微调阶段,研究人员采用了各种方法来微调检索器和生成器,以改进信息检索,主要是在开放域问答任务中。关于检索器微调,REPlUG[Shi et al.,2023] 将语言模型 (LM) 视为黑匣子,并通过可调整的检索模型对其进行增强。REPLUG通过监督信号从黑盒语言模型中获取反馈,改进了初始检索模型。另一方面,UPRISE[Cheng et al.,2023a] 通过对各种任务集进行微调,通过创建轻量级和多功能的检索器来微调检索。 该检索器可以自动为零样本任务提供检索提示,展示其通用性以及跨任务和模型的改进性能。
同时,研究人员也在微调生成器方面做出了努力。例如,Self-Mem[Cheng et al., 2023b] 通过利用示例池对生成器进行微调,而 Self-RAG[Asai et al., 2023b] 则通过生成反射 Token (reflection tokens) 来满足主动检索的需求。
此外,SUGRE[Kang et al.,2023] 引入了对比学习的概念。它对检索器和生成器进行端到端微调,确保高度详细的文本生成和检索到的子图。 使用基于图神经网络 (GNN) 的上下文感知子图检索器,SURGE 从与正在进行的对话相对应的知识图中提取相关知识。这确保了生成的响应忠实地反映了检索到的知识。为此,SURGE 采用了不变但高效的图形编码器和图形-文本对比学习目标。
综上所述,微调阶段的增强方法表现出几个特点。 首先,微调 LLM 和 retriever 可以更好地适应特定任务,提供同时微调一个或两个的灵活性,如 RePlug[Shi et al.,2023] 和 RA-DIT[Lin et al.,2023] 等方法所示。其次,正如 UPRISE 所证明的那样,这种微调的好处延伸到适应不同的下游任务[Cheng et al.,2023a],使模型更加通用。此外,微调使模型能够更好地适应各种语料库中的不同数据结构,这对于图结构语料库特别有利,正如 SUGRE 方法所强调的那样。
然而,在此阶段进行微调会带来一些局限性,例如需要专门为 RAG 微调准备的数据集,以及与推理阶段的 RAG 相比,需要大量的计算资源。总体而言,在微调过程中,研究人员可以根据特定要求和数据格式灵活地定制模型,与预训练阶段相比减少了资源消耗,同时保留了调整模型输出样式的能力。
推理阶段
RAG方法与LLM的融合已成为推理阶段的热门研究方向。值得注意的是,原始RAG的研究范式依赖于在推理阶段纳入检索内容。
为了弥补 Naive RAG 的不足,研究者在推理阶段的 RAG 中引入了更多上下文。DSP[Khattab et al., 2022] 框架通过一个复杂的流程,在冻结的语言模型(LM)和检索模型(RM)间传递自然语言文本,为模型提供更丰富的上下文,从而提升生成质量。PKG 则为大语言模型装备了一个知识引导模块,允许模型在不更改参数的情况下访问相关知识,使其能够执行更复杂的任务。同时,CREA-ICL[Li et al., 2023b] 利用同步检索跨语言知识来获取额外信息,而 RECITE 则通过从大语言模型中抽取一个或多个段落来构建上下文。
在推理阶段,对 RAG 进程的优化有助于模型适应更复杂的任务。
例如,ITRG[Feng et al., 2023a] 通过迭代检索和寻找正确的推理路径,提高了模型处理多步推理任务的适应能力。
ITER-RETGEN[Shao et al., 2023] 采用了一种创新的迭代方式,将信息检索和内容生成紧密结合。这种方法轮流进行“以检索助力生成”的过程和“以生成反哺检索”的过程,从而有效地提升了信息的准确性和相关性。 而 IRCOT[Trivedi et al., 2022] 则是一种结合了 RAG 和 CoT[Wei et al., 2022] 理念的方法。它通过交替使用 CoT 引导的检索和利用检索结果来强化 CoT,有效地提升了 GPT-3 在各类问答任务中的表现,这突出了融合检索与生成技术的巨大潜力。
总结来说,推理阶段的增强技术因其轻量、高效、无需额外训练以及能够有效利用已有的强大预训练模型而备受推崇。其最大的特点是在模型微调时保持大语言模型(LLM)的参数不变,重点在于根据不同需求提供更加贴切的上下文信息,同时具有快速和成本低的优势。然而,这种方法也存在一些局限,比如需要额外的数据处理和流程优化,以及受限于基础模型的性能。为了更好地适应不同的任务需求,这种方法通常会与诸如逐步推理、迭代推理和自适应检索等优化技术结合使用。
6.2 数据增强来源
数据来源对 RAG (Retrieval-Augmented Generation) 的效果至关重要。不同的数据来源提供不同粒度和维度的知识,因此需要采取不同的处理方式。主要分为三类:非结构化数据、结构化数据以及大语言模型生成的内容。
使用非结构化数据进行增强
非结构化数据主要包括文本数据,通常来自纯文本语料库。此外,其他文本数据可以作为检索源,例如用于大模型微调的提示数据[Cheng et al.,2023a] 和跨语言数据[Li et al.,2023b]。
在处理文本的粒度上,除了常见的句子块之外,检索的单元还可以是 Token(例如 kNN-LM[Khandelwal et al., 2019])、短语(如 NPM[Lee et al., 2020],COG[Vaze et al., 2021])以及文档段落。更细致的检索单元能更好地应对罕见模式和领域外的场景,但相应地,检索成本也会上升。
在词汇层面,FLARE 实行一种主动检索策略,仅在大语言模型生成低概率词时启动检索。这种方法涉及先生成一个临时的下一句话用于检索相关文档,然后根据检索到的文档再次生成下一句话,以预测接下来的句子。
在文本块的层面,RETRO 则使用前一个块来检索与之最接近的块,并将这些信息融合进前一个块的上下文中,用以指导下一个块的生成。具体来说,RETRO 通过从检索数据库中提取前一个块的最近邻块 N(Ci−1),并将之前块的上下文信息(C1*,…,C*i−1)与 N(Ci−1) 的检索信息结合,通过交叉关注机制,来指导下一个块 Ci 的生成。为了保持因果逻辑的连贯性,生成第 i 个块 Ci 时,只能参考前一个块的最近邻 N(Ci−1),而不能使用 N(Ci)。
使用结构化数据进行增强
在结构化数据的增强方面,像知识图谱(Knowledge Graph, KG)这类数据源正逐步融入到 RAG 的框架中。经验证的知识图谱能提供更高品质的上下文信息,从而减少模型产生错觉的可能性。
例如,RET-LLM[Modarressi et al., 2023] 构建了一个个性化的知识图谱记忆,它通过从过往对话中提取关系三元组,用于未来的对话处理。
SUGRE[Kang et al., 2023] 使用图神经网络 (GNN) 嵌入从知识图谱中检索到的相关子图,这样做可以避免模型生成与话题无关的回复。
SUGRE[Kang et al., 2023] 采用一种图编码方法,该方法将图结构融入到预训练模型 (PTMs) 的表征空间,并利用图文模式之间的多模态对比学习目标来确保检索到的事实与生成文本的一致性。
KnowledgeGPT[Wang et al., 2023c] 生成的代码格式搜索查询适用于知识库 (KB),并包括预定义的 KB 操作函数。除了检索功能,KnowledgeGPT 还能够在个性化知识库中存储知识,以满足用户的个性化需求。这些结构化数据源为 RAG 提供了更加丰富的知识和上下文,从而提升模型性能。
LLM 生成的内容 RAG
鉴于 RAG 回忆的辅助信息有时效果不佳,甚至可能适得其反,部分研究对 RAG 的应用范式进行了拓展,深入探讨了大语言模型 (LLM) 的内部知识。这种方法通过利用 LLM 自身生成的内容来进行检索,目的是提高下游任务的性能。以下是该领域一些重要的研究: SKR[Wang et al., 2023d] 使用了一个标记好的训练集,将模型能够直接回答的问题归类为“已知”,而需要额外检索增强的问题归类为“未知”。该模型训练用于区分问题是否为“已知”,仅对“未知”的问题应用检索增强,而对其他问题直接给出答案。
GenRead[Yu et al., 2022] 将检索器替换为 LLM 生成器。实验结果显示,由 LLM 生成的上下文文档中包含正确答案的情况比传统 RAG 检索的更常见,并且生成的答案质量更高。作者认为,这是因为生成文档级上下文的任务与因果性语言建模的预训练目标相匹配,使得模型能更有效地利用存储在参数中的世界知识。
Selfmem[Cheng et al., 2023b] 通过迭代使用检索增强的生成器,建立了一个无限的记忆池。系统中包含一个记忆选择器,用于选择一个生成输出作为后续生成过程的记忆。这个输出对应于原始问题的另一面。通过结合原始问题和其对立面,检索增强的生成模型能够利用自身的输出来自我提升。
这些不同的方法展示了 RAG 检索增强领域的创新策略,目的是提高模型的性能和有效性。
6.3 增强过程
大多数RAG研究通常只执行一次检索和生成过程。然而,单次检索可能包含冗余信息,导致“中间丢失”现象[Liu et al.,2023]。这种冗余信息可能会掩盖关键信息或包含与真实答案相反的信息,从而对生成效应产生负面影响[Yoran et al.,2023]。此外,在需要多步骤推理的问题中,从单次检索中获得的信息是有限的。
目前优化检索过程的方法主要包括迭代检索和自适应检索。这些允许模型在检索过程中多次迭代,或自适应地调整检索过程以更好地适应不同的任务和场景。
迭代检索
根据原始查询和生成的文本定期收集文档可以为 LLM 提供额外的材料[Borgeaud et al.,2022,Arora et al.,2023]。在多次迭代检索中提供额外的引用,提高了后续答案生成的鲁棒性。然而,这种方法可能在语义上是不连续的,并可能导致收集嘈杂和无用的信息,因为它主要依赖于 n 个标记的序列来分离生成和检索的文档。
递归检索和多跳检索用于特定的数据场景。递归检索可以先通过结构化索引处理数据,然后逐级检索。检索层次丰富的文档时,可以对整个文档或长 PDF 中的每个部分进行摘要。然后根据摘要执行检索。确定文档后,对内部块进行第二次检索,从而实现递归检索。多跳检索通常用于进一步挖掘图结构数据源中的信息[Li et al.,2023c]。
一些方法结合了检索和生成步骤的迭代。
ITER-RETGEN [Shao et al., 2023] 结合了“检索增强生成”和“生成增强检索”,适用于需要复现信息的任务。即模型利用完成任务所需的内容来回应输入的任务,这些内容随后成为检索更多相关知识的信息背景。这有助于在下一次迭代中生成更优的回应。
IRCoT[Trivedi et al., 2022] 探索了在思维链的每个步骤中检索文档的方法,为每生成一句话就进行一次检索。它利用 CoT(连续任务)来指导检索,并用检索结果来优化 CoT,从而确保语义的完整性。
自适应检索
在适应性检索的领域,Flare[Jiang et al., 2023b] 和 Self-RAG[Asai et al., 2023b] 等方法对常规的 RAG 方法进行了改进。传统的 RAG 方法在检索信息时采取被动方式,而这些新方法则让大语言模型 (LLM) 能主动决定何时以及检索什么内容,从而提高信息检索的效率和准确性。
事实上,大语言模型 (LLM) 主动利用工具并进行判断的做法,并非始于 RAG,而是已在许多大型模型的 AI 智能体中得到广泛应用[Yang et al., 2023c, Schick et al., 2023, Zhang, 2023]。
以 Graph-Toolformer[Zhang, 2023] 为例,它的检索步骤分为几个阶段:LLM 主动利用检索器,通过少样本提示激发搜索查询。当 LLM 认为有必要时,会主动搜索相关问题,以收集必需信息,类似于 AI 智能体调用工具的过程。
WebGPT[Nakano et al., 2021] 则利用强化学习训练 GPT-3 模型,使其通过特殊 Token 在搜索引擎上进行查询、浏览和引用,从而在文本生成中有效利用搜索引擎。
Flare[Jiang et al., 2023b] 则通过自动判断信息检索的最佳时机,有效减少了文档检索的成本。该方法通过监测文本生成过程中的概率变化,一旦生成术语的概率降到一定阈值以下,就会触发信息检索系统,补充所需的知识。
Self-RAG[Asai et al., 2023b] 则引入了一种新颖的“反思 Token”,分为“检索”和“批评”两种。这使得模型能够根据设定的标准自主决定检索信息的时机,从而有效地获取所需段落。
在需要进行信息检索时,生成器会同时处理多个段落,并采用一种称为“片段级 beam search”的技术来确定最优的内容组合。这个过程中,各个部分的重要性通过一种叫做“评审分数 (Critic scores)”的方法来评估并更新,而且这些分数在生成答案的过程中可以根据需要调整,以此来定制模型的响应方式。Self-RAG 框架的一个创新之处在于,它允许大语言模型 (LLM) 自己决定是否需要回顾过去的信息,这样就避免了额外训练分类器或依赖于自然语言推理 (NLI) 模型。这大大提升了模型自主判断信息并生成准确回答的能力。
7 RAG 评估
在探索RAG的开发和优化过程中,有效评估其性能已成为一个核心问题。本章主要讨论RAG的评估方法、关键指标、应具备的能力以及一些主流的评估框架。
7.1 评估方法
主要有两种方法来评估 RAG 的有效性:独立评估和端到端评估[Liu, 2023]。
独立评估
独立评估涉及对检索模块和生成模块(即阅读和合成信息)的评估。
-
检索模块:评估 RAG 检索模块的性能通常使用一系列指标,这些指标用于衡量系统(如搜索引擎、推荐系统或信息检索系统)在根据查询或任务排名项目的有效性。这些指标包括命中率 (Hit Rate)、平均排名倒数 (MRR)、归一化折扣累积增益 (NDCG)、精确度 (Precision) 等。
-
生成模块:生成模块指的是将检索到的文档与查询相结合,形成增强或合成的输入。这与最终答案或响应的生成不同,后者通常采用端到端的评估方式。生成模块的评估主要关注上下文相关性,即检索到的文档与查询问题的关联度。
端到端评估
端到端评估是对 RAG 模型对特定输入生成的最终响应进行评估,涉及模型生成的答案与输入查询的相关性和一致性。
从内容生成的目标来看,评估可分为无标签和有标签的内容评估。无标签内容的评估指标包括答案的准确性、相关性和无害性,而有标签内容的评估指标则包括准确率 (Accuracy) 和精确匹配 (EM)。此外,根据评估方法的不同,端到端评估可分为人工评估和使用大语言模型 (LLM) 的自动评估。总的来说,这些是 RAG 端到端评估的常规方法。特定领域的 RAG 应用还会采用特定的评估指标,如问答任务的精确匹配 (EM)[Borgeaud et al., 2022, Izacard et al., 2022],摘要任务的 UniEval 和 E-F1[Jiang et al., 2023b],以及机器翻译的 BLEU[Zhong et al., 2022]。
这些指标有助于理解 RAG 在各种特定应用场景中的表现。
7.2 关键指标和能力
现有的研究往往缺乏对检索增强生成对不同LLM的影响的严格评估。在大多数情况下,对RAG在各种下游任务和不同检索器中的应用的评估可能会产生不同的结果。然而,一些学术和工程实践侧重于 RAG 的一般评估指标及其有效使用所需的能力。本节主要介绍评估RAG有效性的关键指标以及评估其性能的基本能力。
关键指标
最近的 OpenAI 报告 [Jarvis and Allard, 2023] 讨论了优化大语言模型(大语言模型)的多种技术,其中包括 RAG 及其评估标准。
此外,像 RAGAS [Es et al., 2023] 和 ARES [Saad-Falcon et al., 2023] 这样的最新评估框架也应用了 RAG 的评估标准。梳理这些研究,主要集中于三个关键指标:答案的准确性、答案的相关性和上下文的相关性。
-
答案准确性:这个指标着重保证模型生成的答案与给定上下文的真实性一致,确保答案不会与上下文信息发生冲突或偏离。这一评价标准对于避免大型模型中的误导至关重要。
-
答案相关性:此指标强调生成的答案需要紧密联系问题本身。
-
上下文相关性:此指标要求提取的上下文信息必须尽可能精确和具有针对性,以避免无关内容。毕竟,长文本的处理对大语言模型来说成本很高,过多无关信息会降低模型利用上下文的效率。OpenAI 的报告还特别提及了“上下文提取”作为一项补充指标,用于衡量模型回答问题所需的相关信息检索能力。这个指标反映了 RAG 检索模块的搜索优化程度。低回忆率可能暗示需要优化搜索功能,例如引入重新排序机制或调整嵌入,以确保检索到更相关的内容。
关键能力
RGB [Chen et al., 2023b] 的研究分析了不同大语言模型在处理 RAG 所需的四项基本能力方面的表现,包括抗噪声能力、拒绝无效回答能力、信息综合能力和反事实稳健性,从而为检索增强型生成设立了标准。RGB 关注以下四个能力:
-
抗噪声能力: 这项能力评估模型处理与问题相关但无效信息的噪声文档的效率。
-
拒绝无效回答能力: 当模型检索到的文档缺乏解决问题所需的信息时,模型应正确地拒绝回答。在测试拒绝无效回答时,外部文档仅包含无效信息。理想状态下,大语言模型应发出“信息不足”或类似的拒绝信号。
-
信息综合能力: 这项能力评价模型是否能整合多个文档中的信息,以回答更复杂的问题。
-
反事实鲁棒性测试: 此项测试旨在评估模型在被告知检索信息可能存在风险时,是否能识别并纠正文档中的错误信息。反事实鲁棒性测试包括一些大语言模型能直接回答的问题,但相关外部文档却含有错误事实。
7.3 评估框架
最近,LLM 社区一直在探索使用“LLM 作为判断者”进行自动评估,许多人利用强大的 LLM(例如 GPT-4)来评估自己的 LLM 应用程序输出。Databricks 使用 GPT-3.5 和 GPT-4 作为 LLM 法官来评估其聊天机器人应用程序的做法表明,使用 LLM 作为自动评估工具是有效的[Leng et al.,2023]。他们认为,这种方法还可以高效且经济地评估基于RAG的应用程序。
在RAG评估框架领域,RAGAS和ARES相对较新。这些评估的核心重点是三个主要指标:答案的忠实度、答案相关性和上下文相关性。此外,业界提出的开源库TruLens也提供了类似的评估模式。这些框架都使用 LLM 作为评估的评委。由于TruLens与RAGAS类似,本章将专门介绍RAGAS和ARES。
RAGAS
这个框架关注于检索系统挑选关键上下文段落的能力、大语言模型准确利用这些段落的能力以及生成内容的整体质量。RAGAS 是一个基于简单手写提示的评估框架,通过这些提示全自动地衡量答案的准确性、相关性和上下文相关性。在此框架的实施和试验中,所有提示都通过 OpenAI API 中的 gpt-3.5-turbo-16k 模型进行评估[Es et al., 2023]。
算法原理
- 答案忠实度评估:利用大语言模型 (LLM) 分解答案为多个陈述,检验每个陈述与上下文的一致性。最终,根据支持的陈述数量与总陈述数量的比例,计算出一个“忠实度得分”。
- 答案相关性评估:使用大语言模型 (LLM) 创造可能的问题,并分析这些问题与原始问题的相似度。答案相关性得分是通过计算所有生成问题与原始问题相似度的平均值来得出的。
- 上下文相关性评估:运用大语言模型 (LLM) 筛选出直接与问题相关的句子,以这些句子占上下文总句子数量的比例来确定上下文相关性得分。
ARES
ARES 旨在从三个方面自动评估 RAG 系统的性能:上下文相关性、答案忠实度和答案相关性。这些评估指标与RAGAS中的指标类似。然而,RAGAS作为一个基于简单手写提示的较新的评估框架,对新的RAG评估设置的适应性有限,这是ARES工作的意义之一。此外,正如其评估所表明的那样,ARES的表现明显低于RAGAS。
ARES 通过使用少量手动注释数据和合成数据来降低评估成本,并利用预测驱动推理 (PDR) 提供统计置信区间,提高评估的准确性[Saad-Falcon et,2023]。
算法原理
- 生成合成数据集:ARES 首先使用语言模型从目标语料库中的文档生成合成问题和答案,创建正负两种样本。
- 训练大语言模型 (LLM) 裁判:然后,ARES 对轻量级语言模型进行微调,利用合成数据集训练它们以评估上下文相关性、答案忠实度和答案相关性。
- 基于置信区间对 RAG 系统排名:最后,ARES 使用这些裁判模型为 RAG 系统打分,并结合手动标注的验证集,采用 PPI 方法生成置信区间,从而可靠地评估 RAG 系统的性能。
8 展望
在本章中,我们深入探讨了RAG的三个未来前景,即RAG的垂直优化、水平扩展和生态系统。
8.1 RAG 的垂直优化
尽管RAG技术在过去一年中取得了快速发展,但其垂直领域仍有几个领域需要进一步研究。
首先,RAG中的长上下文问题是一个重大挑战。正如文献中提到的 [Xu et al.,2023c],RAG 的生成阶段受到 LLM 上下文窗口的约束。如果窗口太短,可能没有包含足够的相关信息;如果太长,可能会导致信息丢失。目前,扩展LLM的上下文窗口,甚至到无限上下文的程度,是LLM发展的一个关键方向。然而,一旦上下文窗口约束被移除,RAG应该如何适应仍然是一个值得注意的问题。
其次,RAG的鲁棒性是另一个重要的研究重点。如果在检索过程中出现不相关的噪音,或者检索到的内容与事实相矛盾,则会严重影响 RAG 的有效性。这种情况被形象地称为“打开一本书,看到毒蘑菇”。因此增强 RAG 的稳健性越来越受到研究人员的关注,如 [Yu et al.,2023a,Glass et al.,2021,Baek et al.,2023] 等研究所示。
然后,RAG和Fine-tuning的协同作用问题也是一个主要研究点。混合已逐渐成为 RAG 的主流方法之一,以 RADIT 为例 [Lin et al.,2023]。如何协调两者之间的关系,同时获得参数化和非参数化的优势,是一个亟待解决的问题。
最后,RAG的工程实践是一个重要的关注领域。 易于实施和与企业工程需求的一致性促成了 RAG 的崛起。 然而,在工程实践中,如何提高大规模知识库场景下的检索效率和文档召回率,如何保障企业数据安全,如防止LLM被诱导泄露文档的来源、元数据或其他信息,是亟待解决的关键问题[Alon et al.,2022]。
RAG 的水平扩展
对RAG的研究在横向领域迅速扩展。从最初的文本问答领域开始,RAG的思想逐渐应用于更多的模态数据,如图像、代码、结构化知识、音视频等。这方面已经有很多作品了。
在图像领域,BLIP2 [Li et al.,2023a] 使用冻结图像编码器和大规模语言模型进行视觉语言预训练的 propozhiyosal 降低了模型训练的成本。此外,该模型还可以从零个样本生成图像到文本的转换。
在文本生成领域,采用VBR[Zhu et al.,2022]方法生成图像,指导语言模型的文本生成,在开放文本生成任务中具有显著效果。
在代码领域,RBPS[Nashid et al.,2023] 用于与代码相关的小规模学习。通过编码或频率分析,可以自动检索与开发人员任务相似的代码示例。该技术已在测试断言生成和程序修复任务中证明了其有效性。在结构化知识领域,像 CoK[Li et al.,2023c] 这样的方法首先从知识图谱中检索与输入问题相关的事实,然后以提示的形式将这些事实添加到输入中。该方法在知识图谱问答任务中表现良好。
对于音频和视频领域,GSS[Zhao et al.,2022] 方法从口语词汇库中检索和连接音频片段,立即将 MT 数据转换为 ST 数据。UEOP[Chan et al.,2023] 通过引入语音到文本映射的外部离线策略,在端到端自动语音识别方面取得了新的突破。 文本转语音方法生成的音频嵌入和语义文本嵌入可以通过基于KNN的注意力融合对ASR进行偏置,从而有效缩短领域适应时间。Vid2Seq[Yang et al.,2023a] 架构通过引入特殊的时间标记来增强语言模型,使其能够在同一输出序列中无缝地预测事件边界和文本描述。
8.2 RAG 生态系统
下游任务和评估
通过整合来自广泛知识库的相关信息,RAG 在增强语言模型处理复杂查询和生成信息丰富的响应的能力方面显示出巨大的潜力。大量研究表明,RAG 在各种下游任务中表现良好,例如开放式问答和事实验证。RAG 模型不仅提高了下游应用中信息的准确性和相关性,还增加了响应的多样性和深度。
鉴于RAG的成功,探索该模型在多领域应用中的适应性和普遍性将是未来工作的一部分。这包括它在专业领域知识问答中的使用,例如医学、法律和教育。在专业领域知识问答等下游任务的应用中,RAG 可能比微调提供更低的培训成本和更好的性能优势。
同时,改进RAG的评估系统,以评估和优化其在不同下游任务中的应用,对于模型在特定任务中的效率和收益至关重要。这包括为不同的下游任务开发更准确的评估指标和框架,例如上下文相关性、内容创造力和无害性等。
此外,通过RAG增强模型的可解释性,使用户能够更好地理解模型如何以及为什么做出特定的响应,也是一项有意义的任务。
技术栈
在RAG的生态系统中,相关技术栈的开发起到了推动作用。 例如,随着 ChatGPT 的普及,LangChain 和 LLamaIndex 迅速广为人知。它们都提供了丰富的 RAG 相关 API,逐渐成为大模型时代不可或缺的技术之一。同时,新型技术栈也在不断开发中。尽管它们提供的功能不如 LangChain 和 LLamaIndex 那么多,但它们更注重其独特的特性。例如,Flowise AI强调低代码,允许用户实现以RAG为代表的各种AI应用,而无需编写代码,只需拖放即可。其他新兴技术包括 HayStack、Meltno 和 Cohere Coral。
除了AI原生框架外,传统软件或云服务提供商也扩大了服务范围。例如,由矢量数据库公司Weaviate提供的Verba专注于个人助理。亚马逊为其用户提供了基于RAG思维的智能企业搜索服务工具Kendra。用户可以通过内置连接器在不同的内容存储库中进行搜索。
技术栈和RAG的发展是相辅相成的。新技术对现有技术栈提出了更高的要求,而技术栈功能的优化又进一步推动了 RAG 技术的发展。综合来看,RAG 工具链的技术栈已经初步建立,许多企业级应用逐步出现。然而,一个全面的一体化平台仍在完善中。
9 结论
本文深入探讨了检索增强生成 (RAG),这是一种使用外部知识库来补充大型语言模型 (LLM) 上下文并生成响应的技术。值得注意的是,RAG 结合了来自 LLM 的参数化知识和非参数化外部知识,缓解了幻觉问题,通过检索技术识别了及时的信息,并提高了响应的准确性。此外,通过引用来源,RAG 提高了模型输出的透明度和用户信任度。RAG 还可以通过索引相关文本语料库来根据特定域进行定制。
RAG的发展和特点归纳为三种范式:朴素型RAG、高级型RAG和模块化型RAG,每种范式都有其模型、方法和缺点。朴素RAG主要涉及“检索-读取”过程。Advanced RAG 使用更精细的数据处理,优化知识库索引,并引入多次或迭代检索。随着探索的深入,RAG 集成了微调等其他技术,导致了模块化 RAG 范式的出现,该范式通过新模块丰富了 RAG 流程并提供了更大的灵活性。
在随后的章节中,我们将进一步详细分析RAG的三个关键部分。第4章介绍了RAG的检索器,如何处理语料库以获得更好的语义表示,如何缩小Query和文档之间的语义差距,以及如何调整检索器以适应生成器。第5章解释了生成器如何通过对检索到的文档进行后处理来获得更好的生成结果,避免了“中间丢失”的问题,以及调整生成器以适合检索器的方法。随后,在第6章中,我们从检索阶段、检索数据源和检索过程等方面回顾了目前的检索增强方法。
第7章解释了如何评估当前的RAG方法,包括评估、关键指标和当前的评估框架 最后,我们对RAG未来潜在的研究方向进行了展望。RAG作为一种结合检索和生成的方法,在未来的研究中具有许多潜在的发展方向。通过不断改进技术并扩大其应用范围,可以进一步提高RAG的性能和实用性。

