
- 1iconfont字体图标和各种CSS小图标
- 2pythondcnda算法聚类_ML-hand/5kmeans聚类.ipynb at master · Briareox/ML-hand · GitHub
- 3unity 3D模型展示旋转缩放_unity 模型旋转
- 4CFAR原理详解及其matlab代码实现
- 5OpenCV4.5 dnn模块+QT5.12.9实现人脸识别Demo_cv::facedetectoryn::create
- 6antd源码-form解析(初始化到表单收集校验过程)_antd validatemessages
- 7互动照片墙效果之扩散效果(一)_unity ui 扩散效果
- 8echarts实现3d环形饼状图_echart 3d饼状图
- 9ant-design-vue切换主题+换肤+自定义换肤+less动态换肤_ant-design-vue 在线换肤
- 10vue 循环数组使用el-input,输入一次以后光标不见了,无法输入第二次_el-input数组
并发编程(多线程)_两个线程执行同一个任务
赞
踩
一、进程与线程
多进程编程已经能够解决并发编程的问题了(已经可以利用cpu多核资源了).但是仍然存在这缺陷.
就是,进程太重了(消耗资源多,速度慢),线程应运而生被称为"轻量级编程",解决并发编程的各种问题的同时,让IO速度大大提升.
线程"轻"主要"轻"在申请资源/释放资源的操作上.
1.进程与线程的区别
这里我们举个例子:
如果在一个院子里有一条生产线,但现在产品饱和我们要扩大生产.该怎么办?
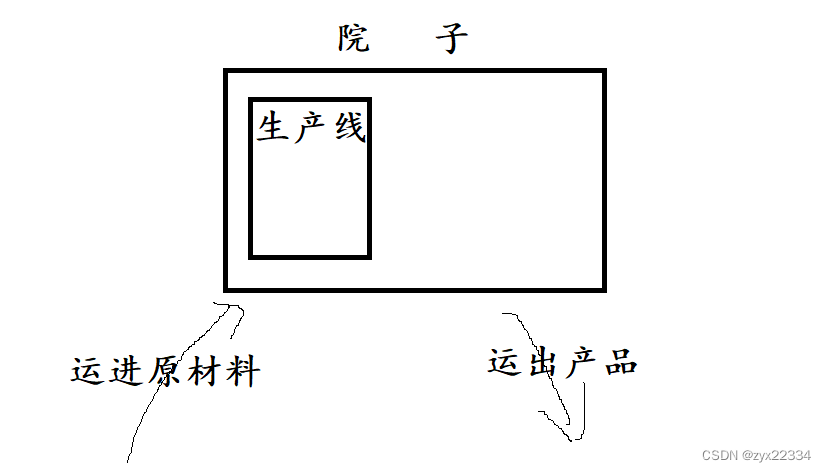
两种方法:
1.另外找一个院子复制一个一摸一样的生产线生产产品.(多进程)
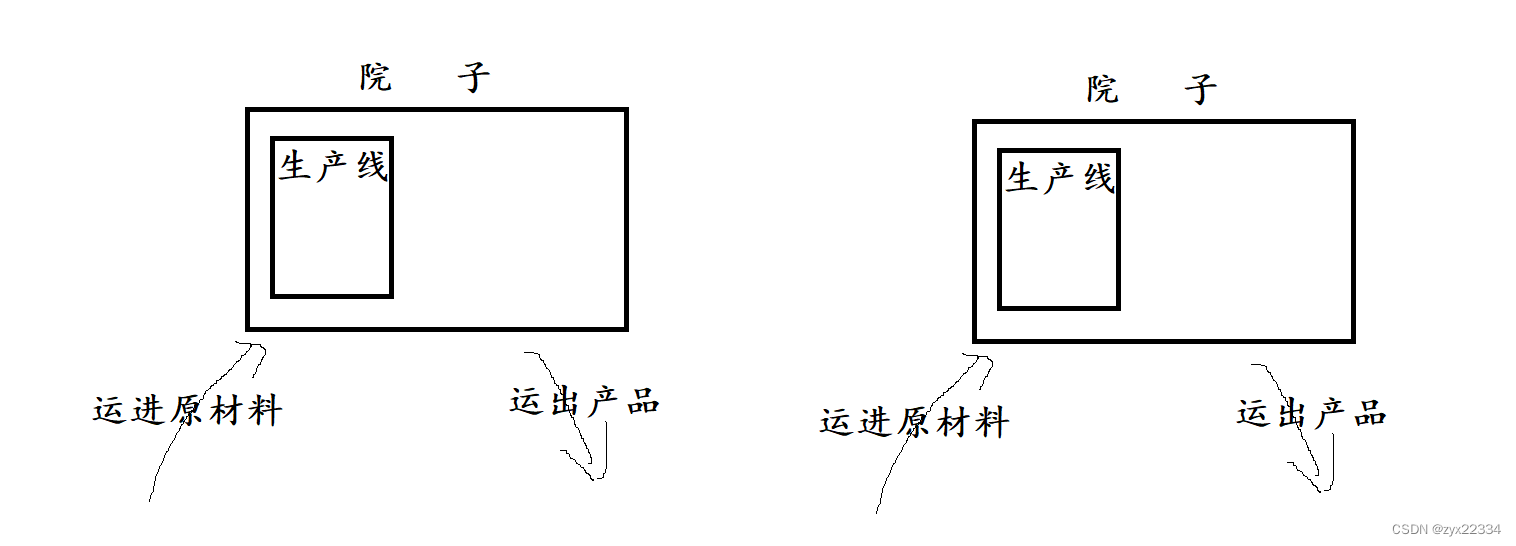
2. 在原有的院子中再创建一条生产线.扩大生产.(多线程)
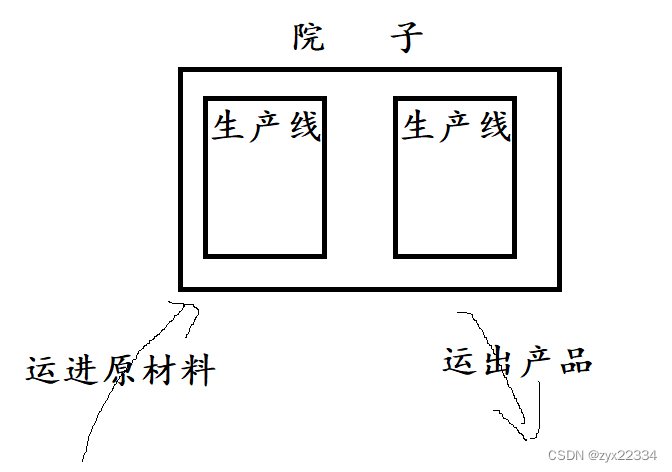
在这里方法一对应的就是进程的实现方法,而方法二对应的就是线程的实现方法.线程比进程节省了物流以及院子的资源.
进程和线程的关系:
进程包含一个或多个线程(不能没有),所以说在线程中只有第一个启动消耗的资源比较大.
在一个进程里的多个个线程调用的是同一份资源(主要指内存和文件描述表)
操作系统在实际调用的时候,其实是以线程为单位的.(进程调度相当于每个进程中只有一个线程)但如果进程中有多个线程,那么线程就是操作系统调度执行的基本单位.
总结:一个核心上只能有一个进程,而一个进程上有多个线程,在操作系统调度执行的时候只关心线程的线程的基本属性,而不关心进程.
二、进程安全问题
这里我们还是用一个例子来解释:
一个人吃100只鸡
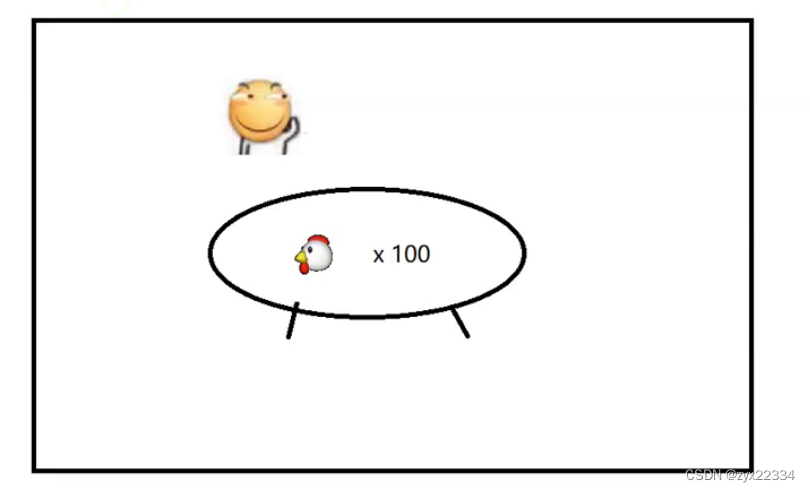
两个房间,两个人一人吃50只鸡,速度就快于之前(多进程)
现在我们考虑多线程方式吃鸡:在一个房间放很多人一起吃鸡
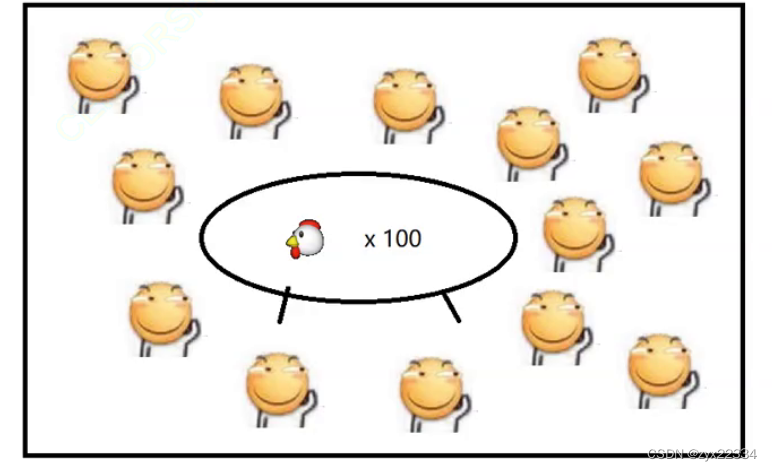
但是桌子的面积是有限的(CPU的核心数量是有限的),所以说速度提升也是有上限的.人太多,多数资源都被分配在了选择让谁去吃鸡上了,就影响了正在吃鸡的人(线程太多,核心数量有限,不少开销都被浪费在了线程调度之上了)
并且,多数的人吃鸡还有可能产生纠纷,如两个人同时访问一块肌肉.导致发生问题,这种问题就被称为"线程安全问题".
一旦出现"两个人争夺一个鸡的情况",程序会直接崩溃,所以要妥善解决线程安全问题.
三、多线程
Java多线程最重要的类就是Thread类(不需要import任何包).
1.最基本的多线程代码
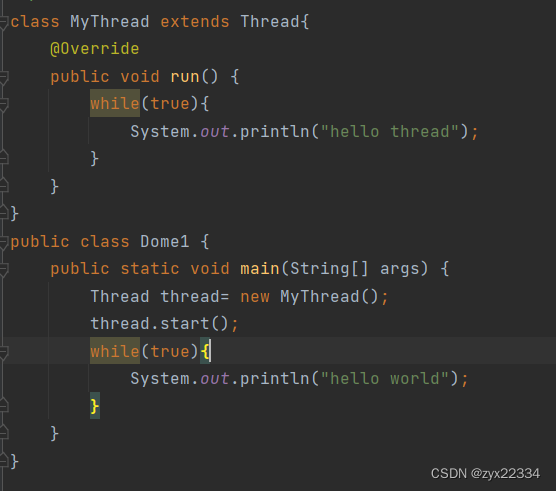
多线程需要使用Thread类在主线程上创建对象实现继承了Thread的自己创建的MyThread
![]()
在这里自己写的MyThread就是脱离主线程的另外的线程.
再在主线程里使用对象调用start()方法启动线程,就能保证两个线程同时运行了.
![]()
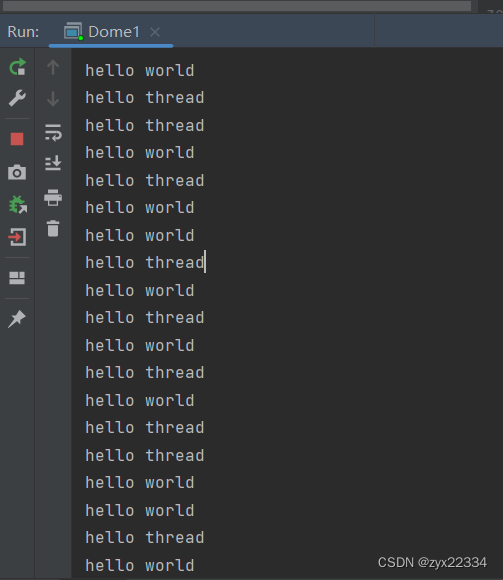
2.抢占式执行
抢占式执行是多线程编程最基本的性质.
看上面的代码运行结果:
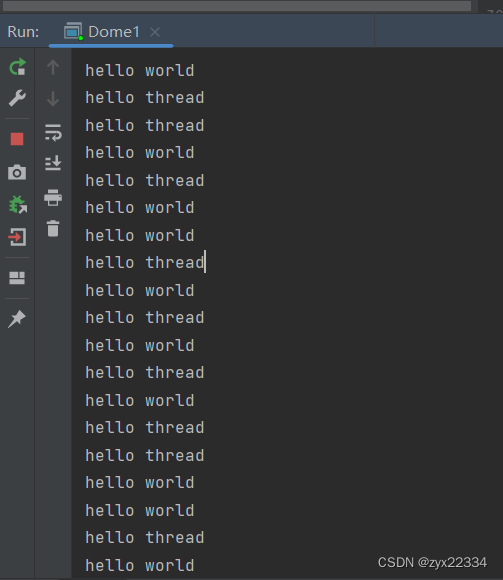
这里的hello world和hello thread的执行顺序是随机的.是不可控的.(基本上无解)
3.jconsole
jconsole是jdk自带的一个小工具,作用是查看Java中运行的进程.
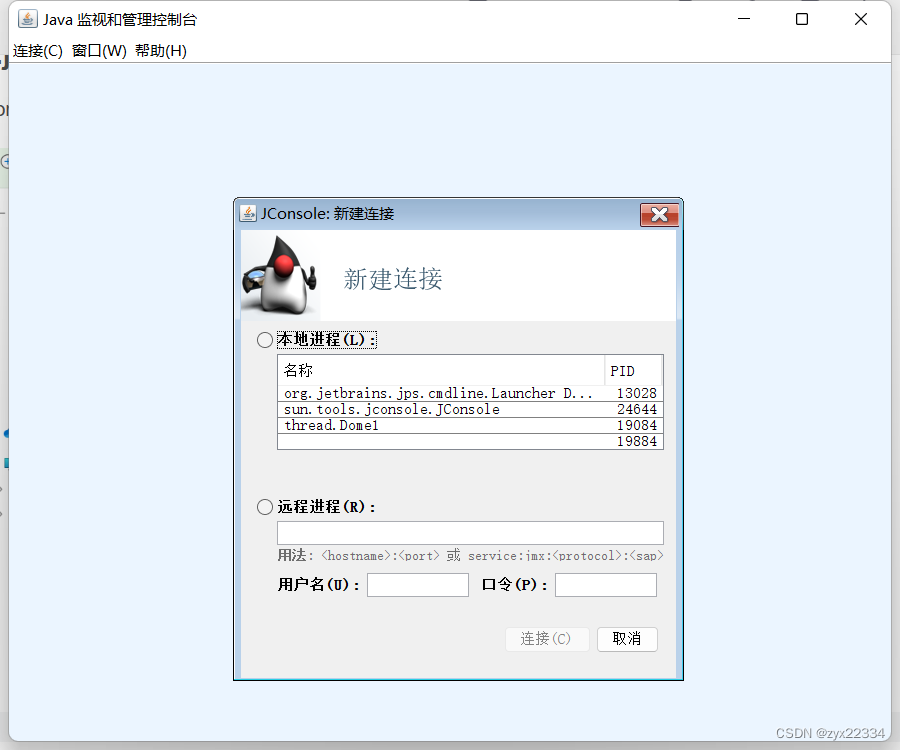
这里第一个是 IDEA,第二个是jconsole工具自己,第三个是我们刚才运行的进程.
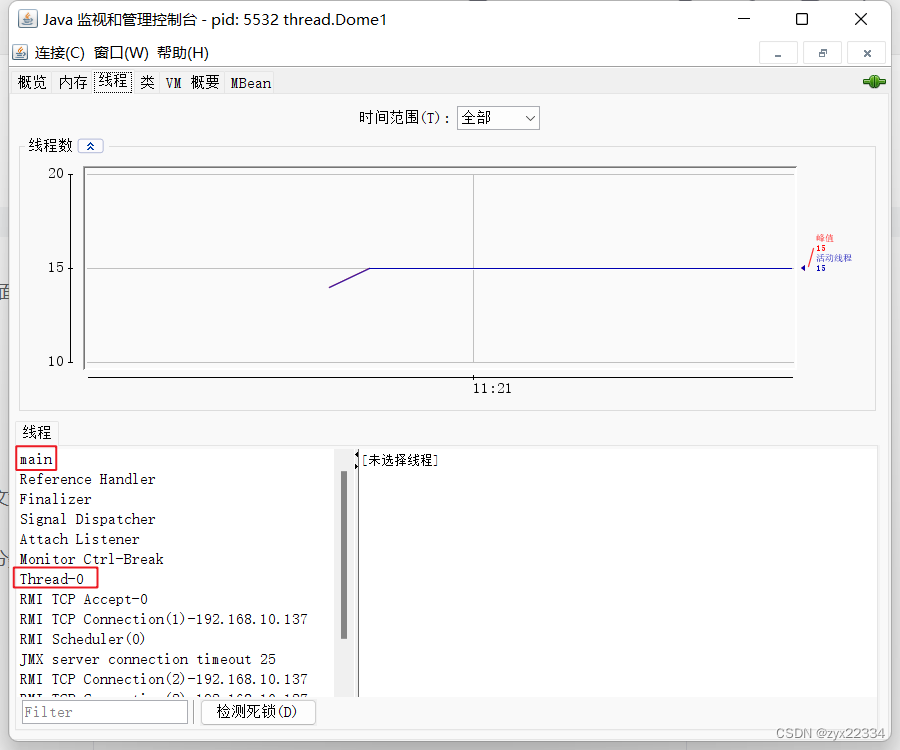
点击连接自己创建的线程可以看到里面用很多线程,其中main和Thread-0是和我们刚刚写的代码密切相关的.

也可以查看线程内部的调用栈来查看线程在哪里出错.
4.Java中创建线程的方法
1)继承Thread,重写run()
就是我们之前写的那个.
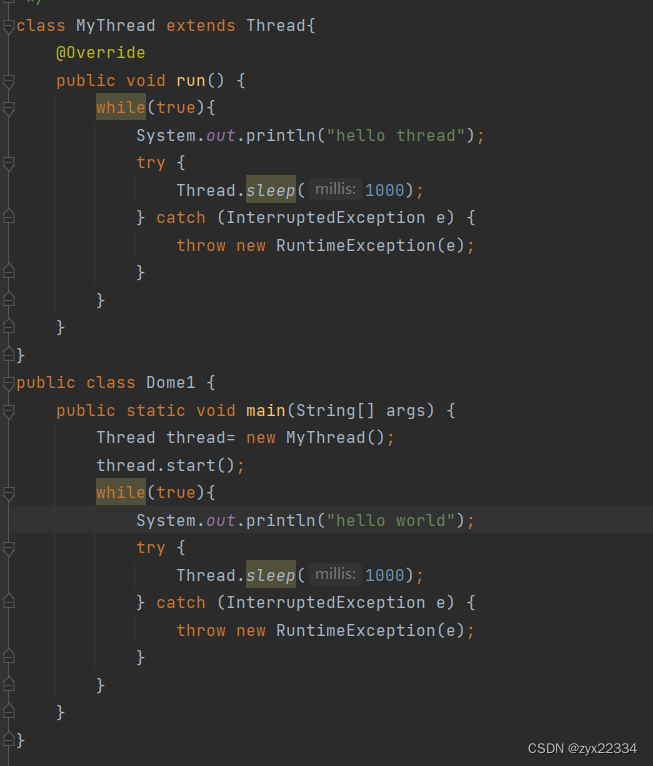
2)实现Runnable接口
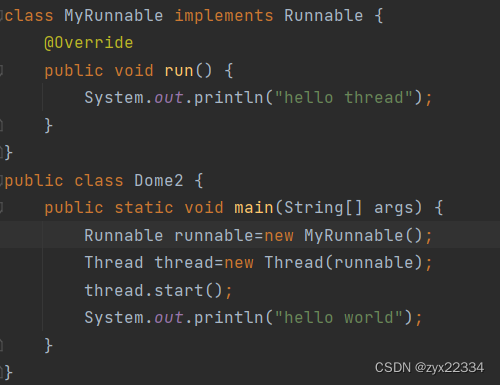
依然需要Thread配合Runnable使用,注意:Runnable接口,需要重写抽象方法run().
这里总结一下普通类、抽象类、接口:
抽象类里都是抽象方法和对象的抽象属性,而想要使用抽象类需要自己写个子类继承抽象类然后重写抽象方法.而接口里面只有抽象方法,想要使用的话也得写个子类继承抽象类然后重写抽象方法.
优势:解耦合,将线程创建与子类分开.
3)使用匿名内部类,继承Thread
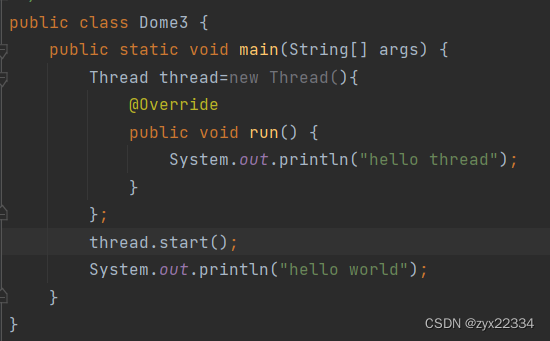
创建了一个Thread的子类.(子类没有名字,所以才被称为匿名),并且创建了子类的实例用thread启动.
优势:在一个类中实现多线程.
4)使用匿名内部类,实现Runnable接口.
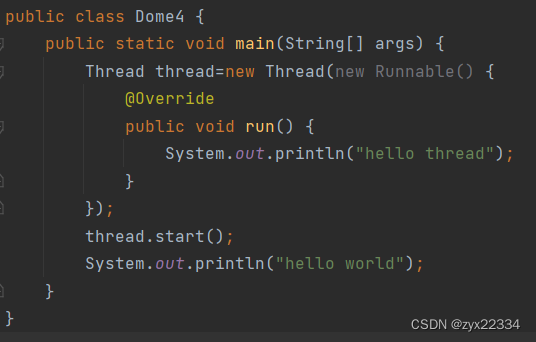
本质上和方法二相同,只不过把实现Runnable任务交给了匿名内部类的语法,此处是创建了一个类,实现Runnable,同时创建了类的实例,并且传给了Thread的构造方法.
5)使用Lambda表达式
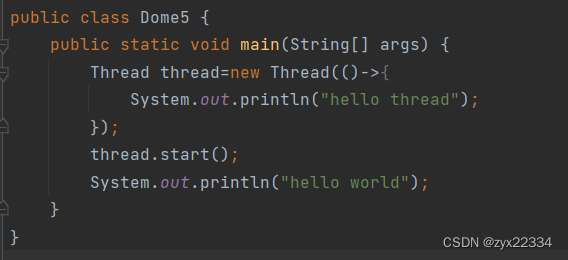
这种方法是最简单也是最推荐使用的对线程实现方法.
5.Thread的用法
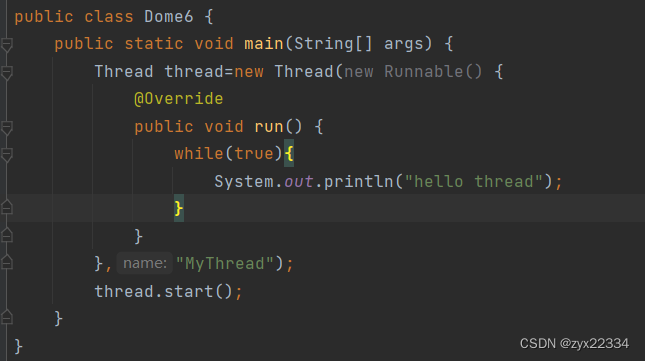
可以利用语法格式创建线程名字,也可用 jconsole查看线程
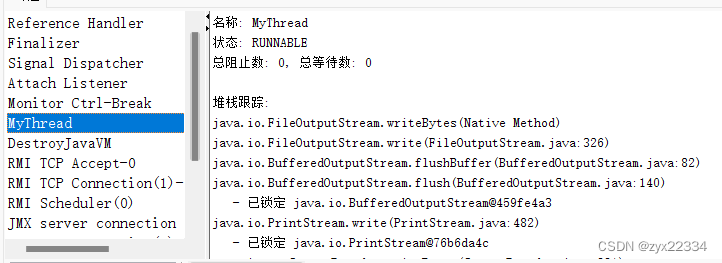
5.2 thread的几个常见属性

主要讲一下这个后台线程,在日常的代码中所写的所有代码都属于前台线程(包括main)用isDaemon()这个方法设置为后台线程.
后台线程的用法:
在程序中程序的是否结束就和后台线程无关了,只和前台线程有关.
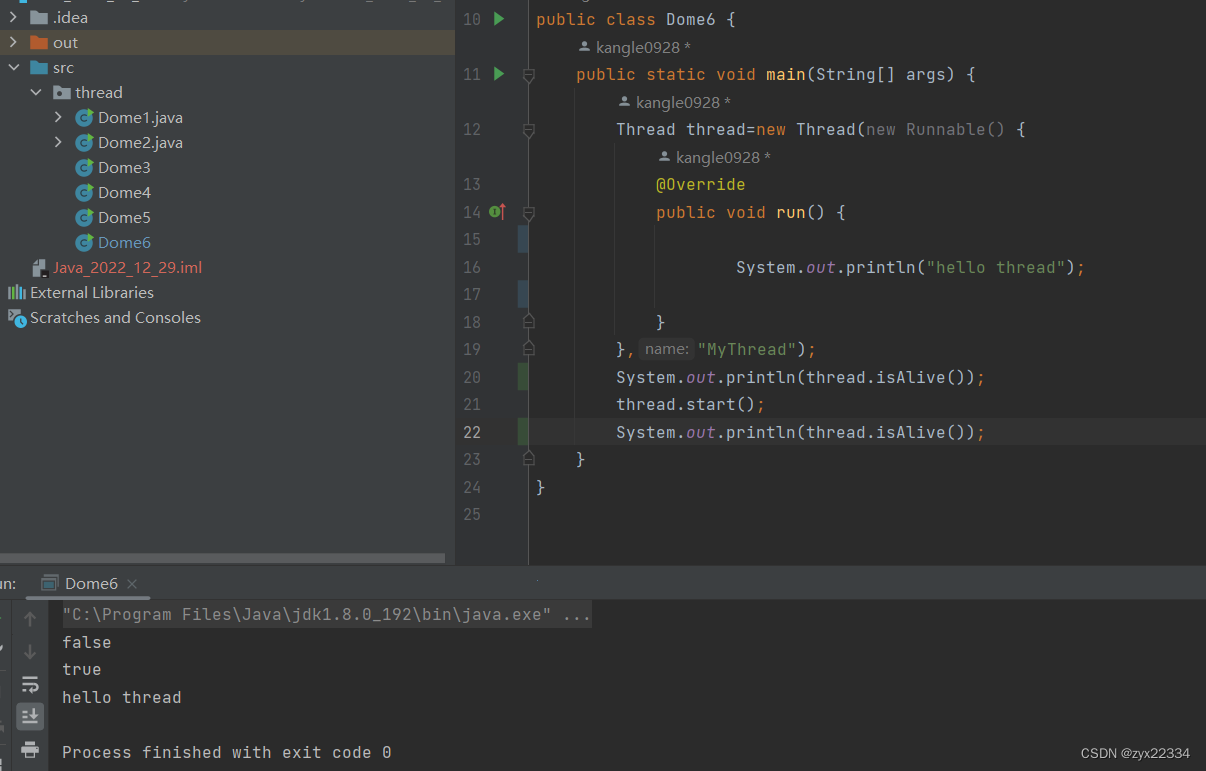
是否存活指的是代码是否进入运行阶段,如创建了一个线程thread,在调用线程thread.start()之前isAlice()就是false,在调用thread.start()之后isAlice()就是true.
5.3 线程中断
1).使用代码进行线程中断
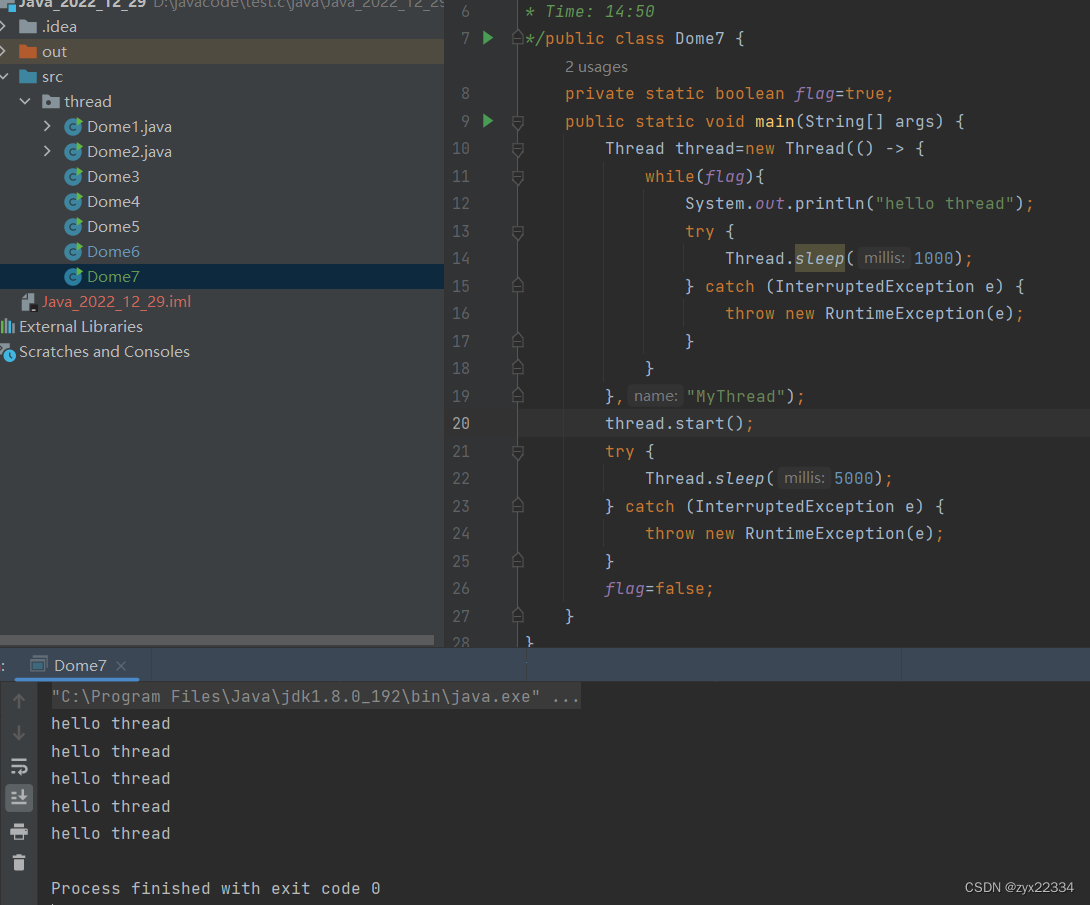
设置一个全局变量flag,再在线程中设置为while的条件,最后在主线程中修改它的值以达到中断线程的目的.
2).使用Thread自带的标志位,来进行判定,这个东西是可以唤醒Thread.sleep的.

这里主要解释一下这句:
![]()
![]()
这里的Thread.currentThread()方法意思就是在哪个线程里调用的就指代哪个线程,类似于this.
这里实在thread线程中调用的,所以说就是指代thread线程.
![]()
后面的isInterrupted()的意思是判断本线程是否结束. 所以本代码在不使用全局变量的情况下满足了功能.
在本程序中,intereupted做了两件事:
1.把线程内部标志位的boolean改为true.
2.如果线程在sleep,就会触发异常,把sleep唤醒,但在唤醒sleep的时候还会再做一件事,就是把标志位再设置为false.
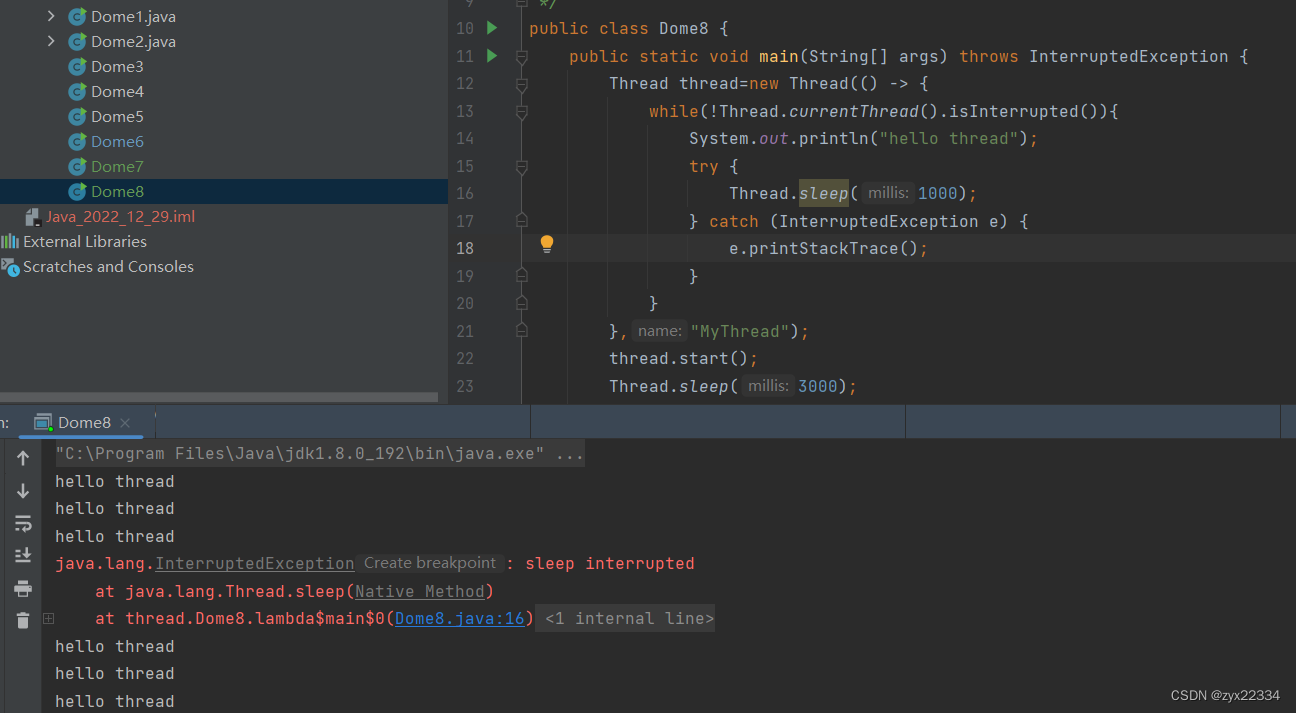
所以就出现了上述情况,触发异常后程序不会结束.
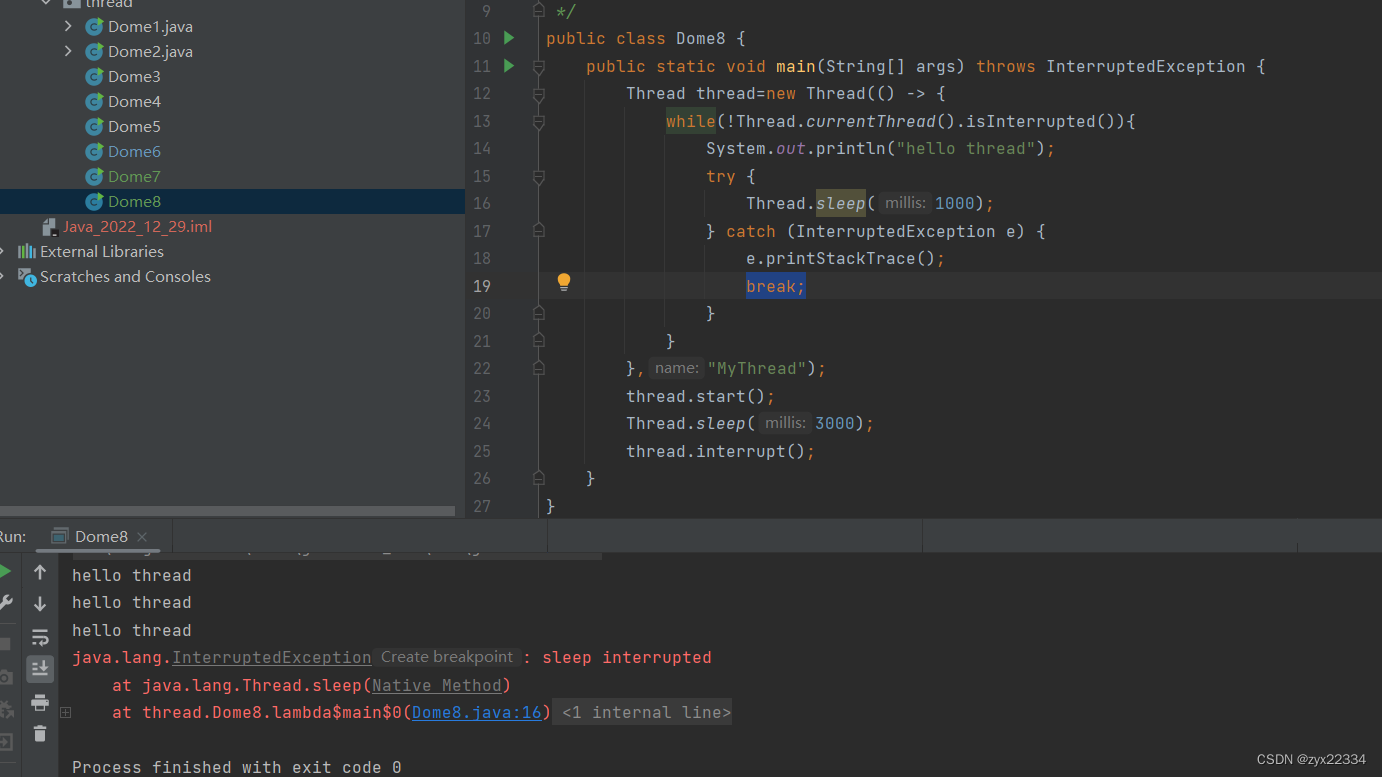
在程序中加入break就可以解决此问题.
相当于此种方法可以把选择权交到程序员自己手中,可以在catch中自行设定想要待会中止或者立刻终止或者根本就不中止都可以.
5.4 等待一个线程
线程是一个随机调度的过程,等待线程,就是在控制两个线程结束的顺序.
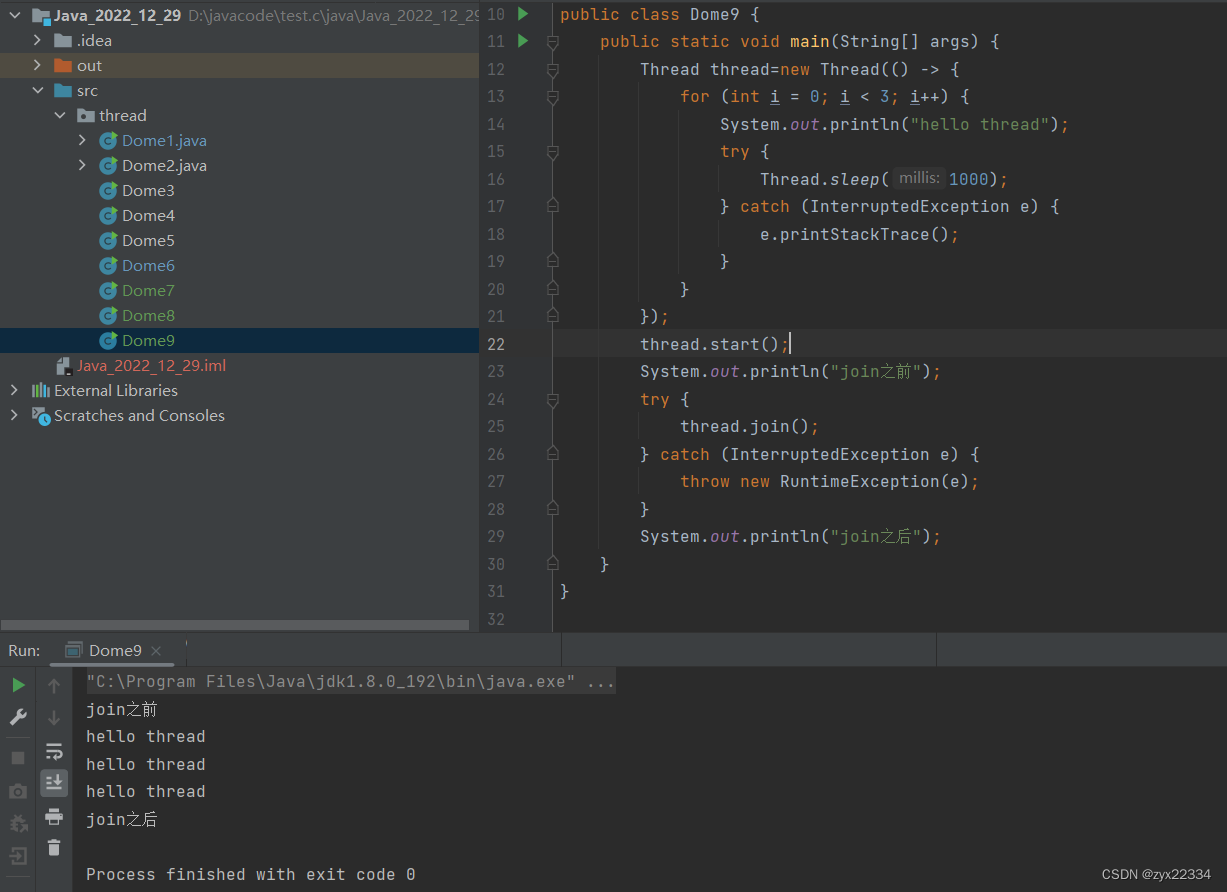
说到底,join的作用就是让调用它的哪个线程阻塞等待(block)它调用的线程,在上述代码中就是让main线程阻塞等待thread线程.
main线程得一直等到thread结束之后才能打印"join之后".(控制结束先后顺序)
另外,join也有多种版本:

5.5 获取当前线程引用
![]()
就是使用我们上面所提到过的Thread.currentThread()来进行操作,作用是调用本线程.
注意:本方法是静态方法,不必使用Thread thread=new Thread()进行操作,可以使用Thread.currentThread()直接调用.
5.6 休眠
![]()
sleep方法是静态方法,所以也是Thread.sleep()调用,下面主要讲一下它的原理:
首先,在操作系统内核中有这样两个由链表组成的队列:就绪队列、阻塞队列.
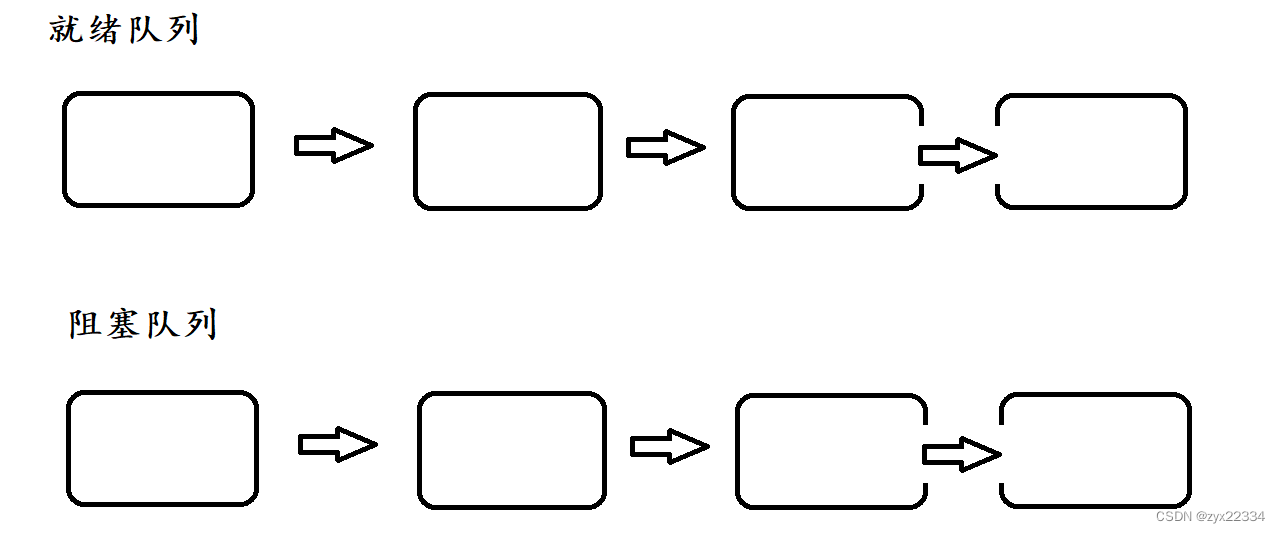
就绪队列都是"随叫随到"的,时刻处于就绪状态.在执行时,操作系统就从就绪队列中随机选择一个执行.就绪队列中的PCB调用sleep进入阻塞队列,阻塞队列中的内容暂时处于"阻塞状态",暂时不参加CPU的调度执行.
如sleep(1000)就是在阻塞队列中等待1000ms这么长的时间.
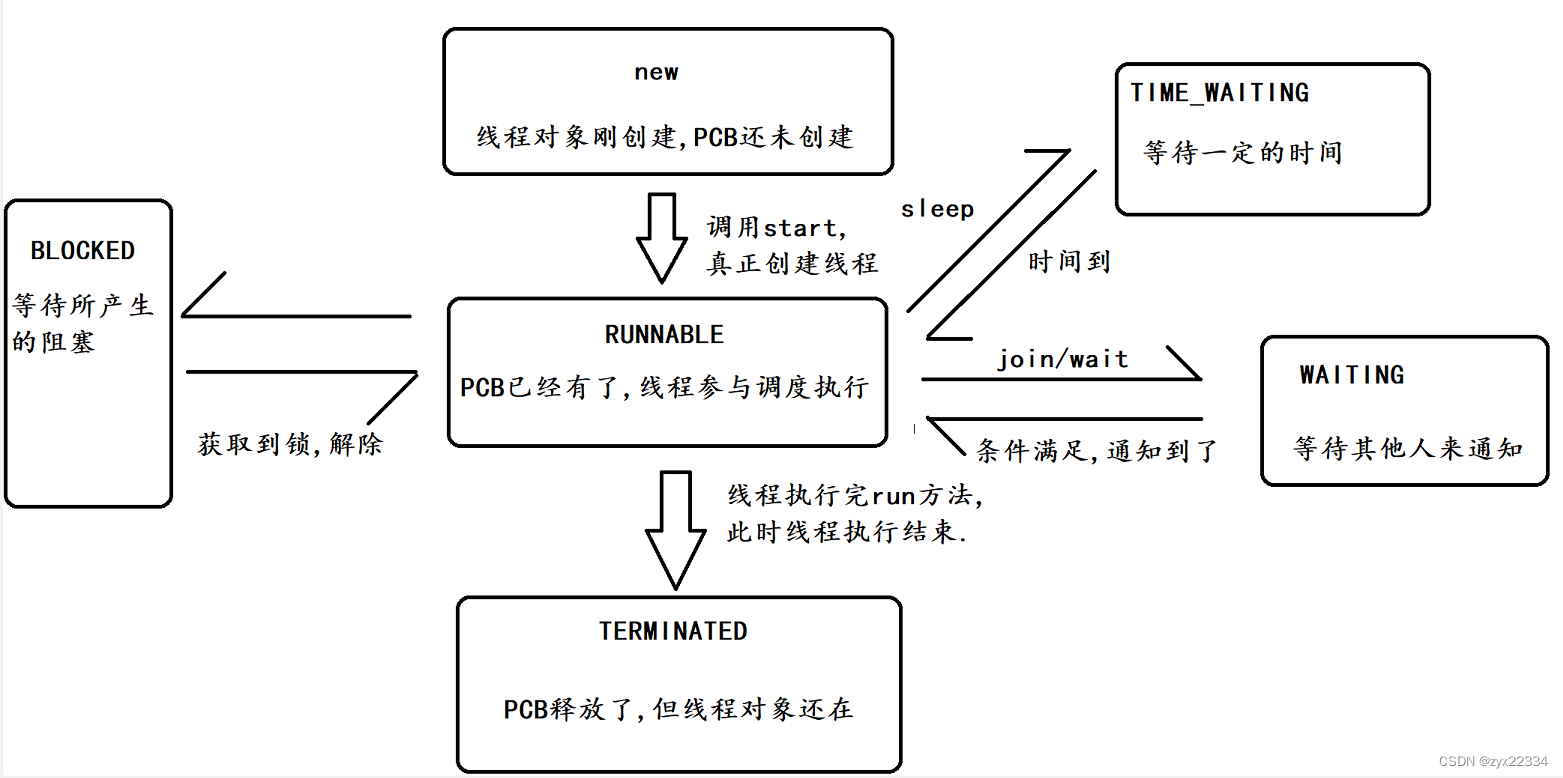
6.线程的状态
1)NEW
就是创建了Thread,但是还没有调用start(内核里还没有创建PCB).
2)TERMINATED
表示内核中的PCB已经执行完毕了,但是Thread队形还在.
3)RUNNABLE
可运行的(就做RUNNABLE,而不是RUNNING)
RUNNABLE:可运行的.在就绪队列中.
RUNNING:正在运行的.正在CPU上执行.
4)WAITING
5)TIMED_WAITING
6)BLOCKED
都是阻塞状态,只不过是不同的阻塞.
6.2 线程的状态转换
四、多线程的线程安全问题
1. 线程安全问题
万恶之源:抢占式执行所带来的随机性.代码执行顺序的可能性有无数中情况,我们的任务就是在无数种情况下都是程序运行的结果都是正确的.
这里举个例子:
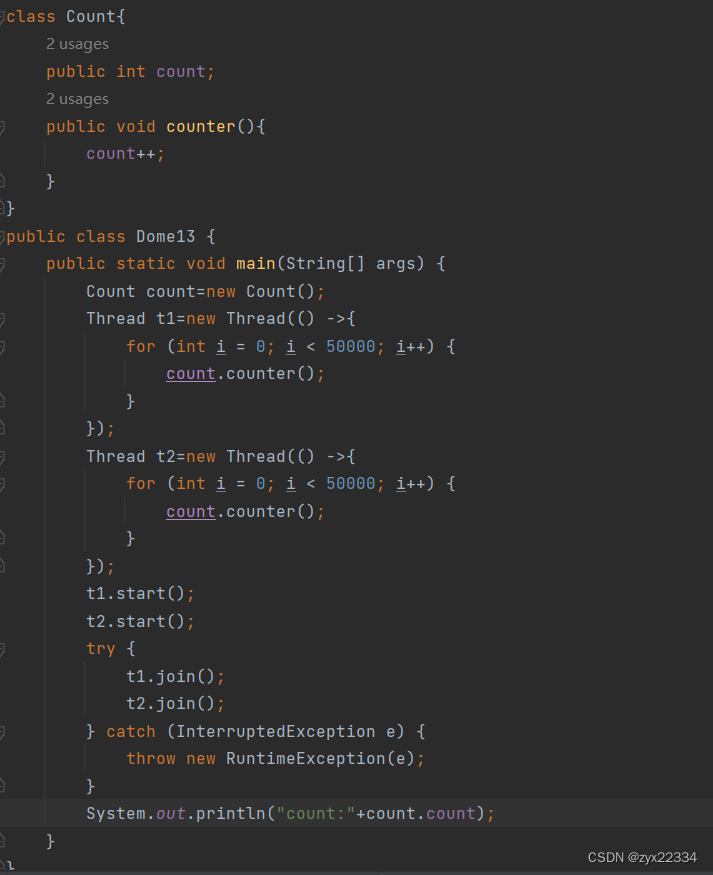
此代码自增count两次,这里按照常理来说count的值应该是10_0000,但是
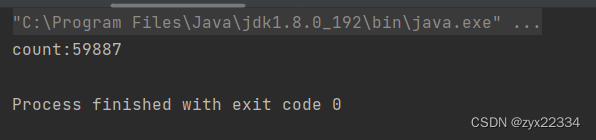
真实结果远远不到10_0000.这就是一个典型的线程安全问题.
这里就要分析一下count++操作:
1.把内存中的值,读取到CPU的寄存器中. load
2.把CPU寄存器里的数值进行+1操作. add
3.把得到的结果写回到内存中. save
这三个指令就是机器语言.就是CPU上执行的原生指令,是不可更改的.
如果是两个线程并发执行的count++,那相当于两组load、add、save进行执行,此时不同的线程调度顺序就会产生不同的结果.
用画图的方式表示:(箭头表示时间轴,而t1、t2分别表示一个线程).
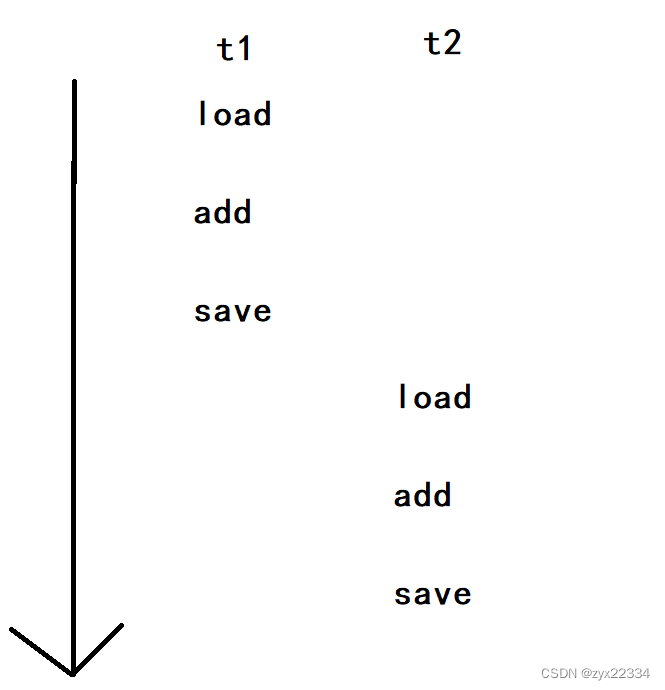
以上是正确的运行顺序
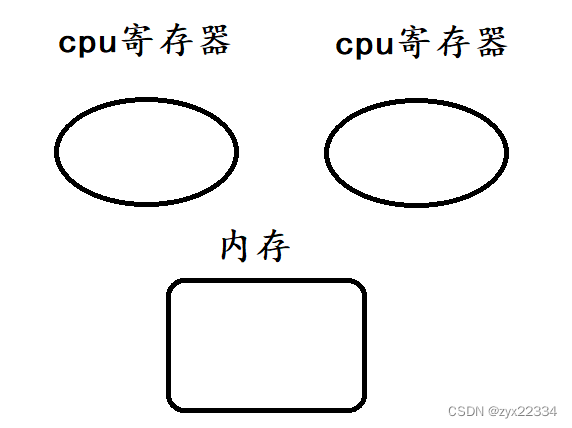
假设这是操作系统中真实的运行形式,首先是t1的load、add、save
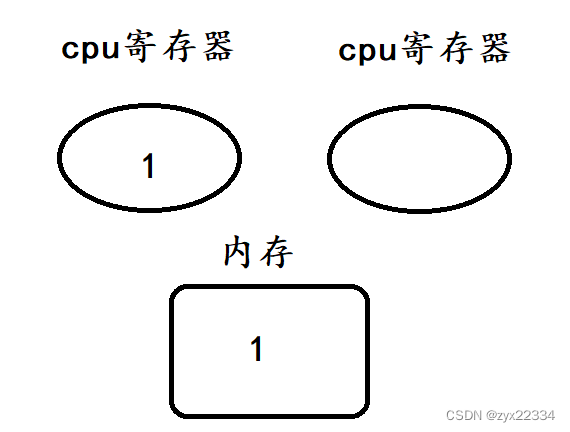
然后是t2的load、add、save
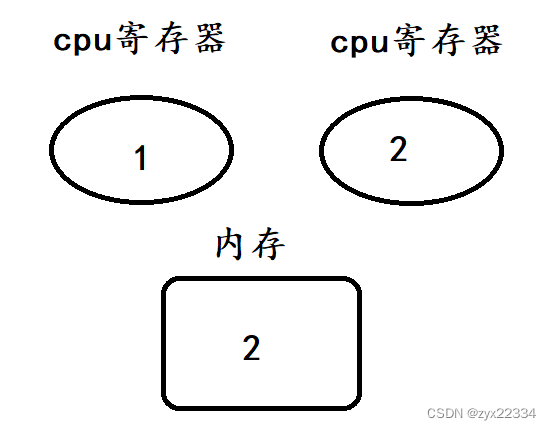
可以看到最终得到的结果是正确的2.
但如果发生了线程安全问题,导致操作系统调度顺序出现了不一样的结果呢?
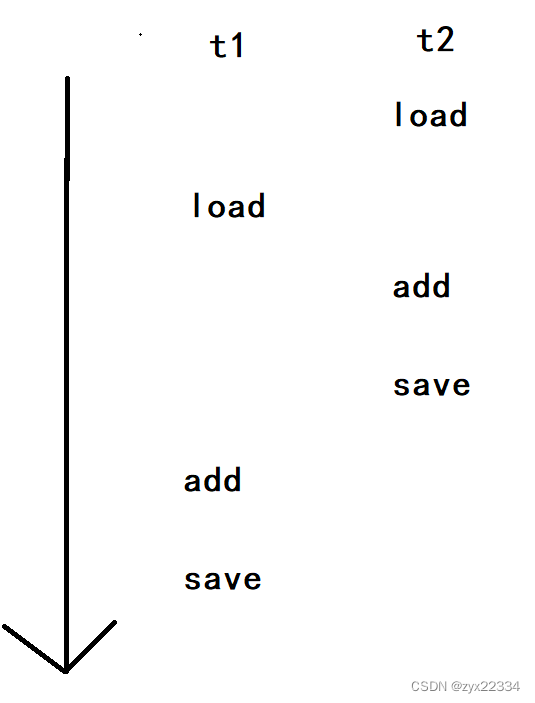
这是再重新分析:
首先是t2的load和t1的load
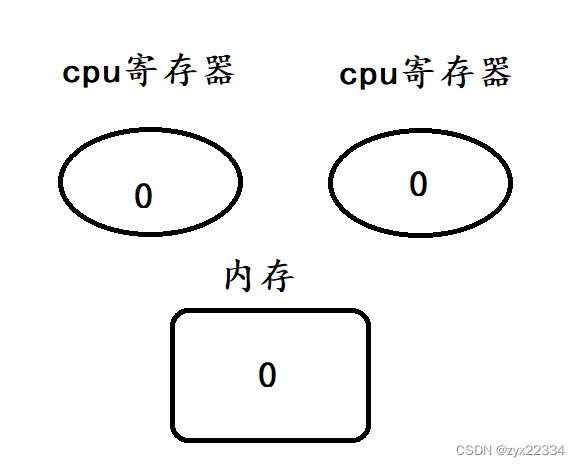
然后再是t2的add、save.
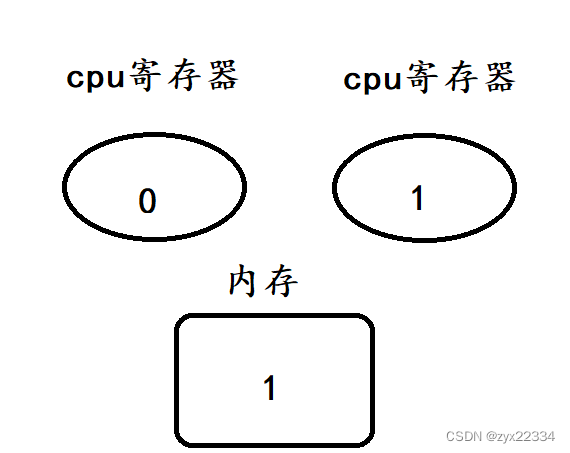
最后是t1的add、save
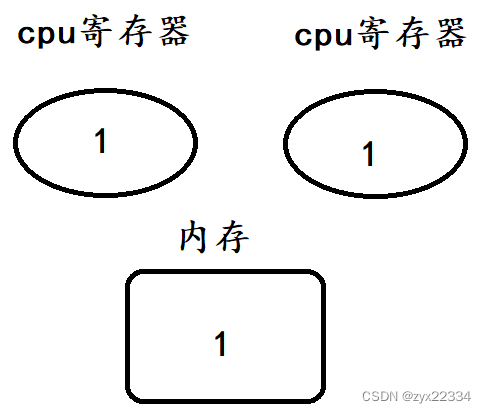
最后我们发现得到的是错误结果1,说明该程序发生了线程安全问题.
而再程序中,线程随即调度导致的引发线程安全问题的运行顺序还有好多.
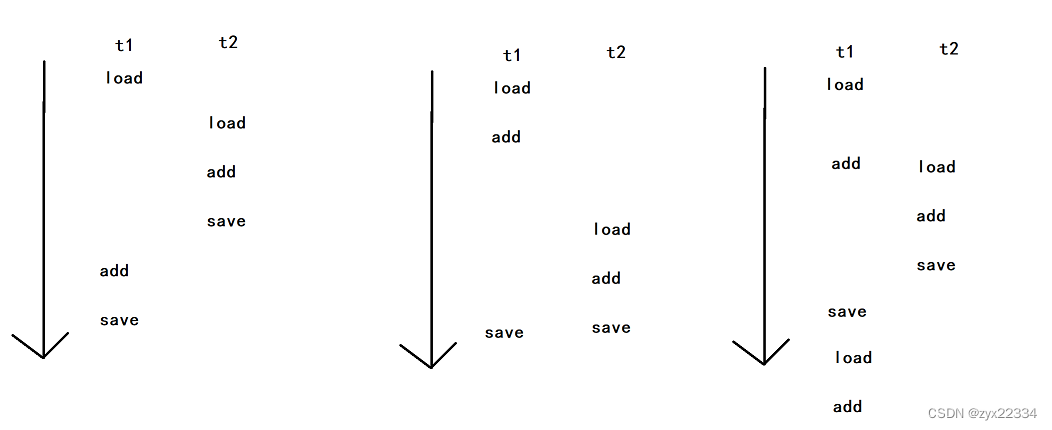
等等........
在这里我们还是要谈到原子性.
在上面的代码中,我们可以把count++拆分为三部分:load、add、save.
如果我们把这三部分设置为一个整体,将它们设定为原子性,那么线程安全问题将得到解决.
(也就是说永远保证load、add、save三部分在一起按顺序运行)
如何把非原子性手动设置为原子性呢?
2. 加锁
作用:将非原子性手动设置为原子性.
语法格式:
synchronized成功案例:
在修改后上面代码就能正确计算出自增结果了
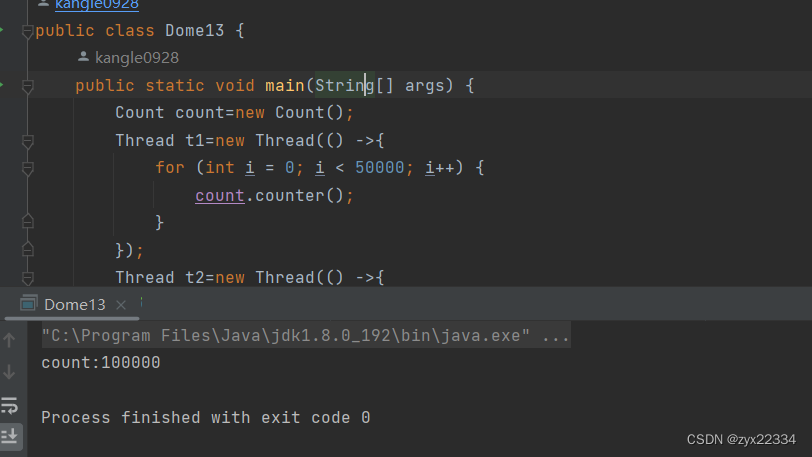
加锁,说是保证代码的原子性,但其实是让这三个操作一次完成,也不是这三个操作过程中不进行调度,而是让其他也想来操作的线程阻塞等待了.
加锁的本质,就是把并发变成了串行.
拿图来举例子:
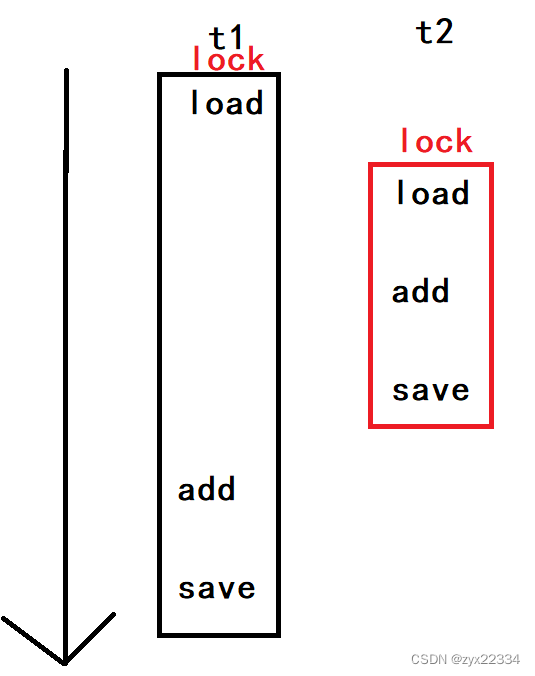
这里就是他t1的三个操作上锁后,这是先经历的t2的三个操作,并让它们进入阻塞队列进行阻塞等待,先将t1三个操作完成后再运行t2的三个操作.
2.2 synchronized的使用方法
1)修饰方法 进入方法加锁,离开方法解锁
a)修饰普通方法
锁对象就是this

b)修饰静态方法
锁对象就是类对象(Count.class)

2)修饰代码块
显示/手动指定锁对象
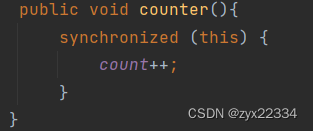
所以说加锁要明确对哪个对象进行加锁,如果两个线程对同一个对象进行加锁就会产生阻塞等待.(锁竞争/锁冲突)
2.3 可重入
一个线程对一个对象进行两次及以上的加锁,如果可以则称为可重入,如果不行则称为不可重入.
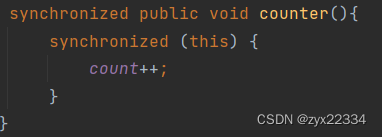
注意:Java的锁可重入的,而C++、python等是不可重入的.
2.4 死锁
程序一旦出现死锁程序就会直接崩毁,而且死锁很隐蔽一般测试不过来.
死锁的四个必要条件(四个条件必须同时出现才会出现死锁):
1.互斥使用 线程1拿到了锁线程2就得等着
2.不可抢占 线程1拿到锁后,必须是线程1主动释放.线程2不能强行获取
3.请求和保持 线程1拿到锁A后又尝试获取锁B,但是A依然保持.
4.循环等待 线程1和线程2同时尝试获取锁A和锁B;线程1再等待线程2释放锁B,同时线程2也在等待线程1释放锁A.
死锁一般分为三类:
1.一个线程,一把锁,连续加锁两次,如果锁是不可重入锁,就会发生死锁.但在Java中不会发生.
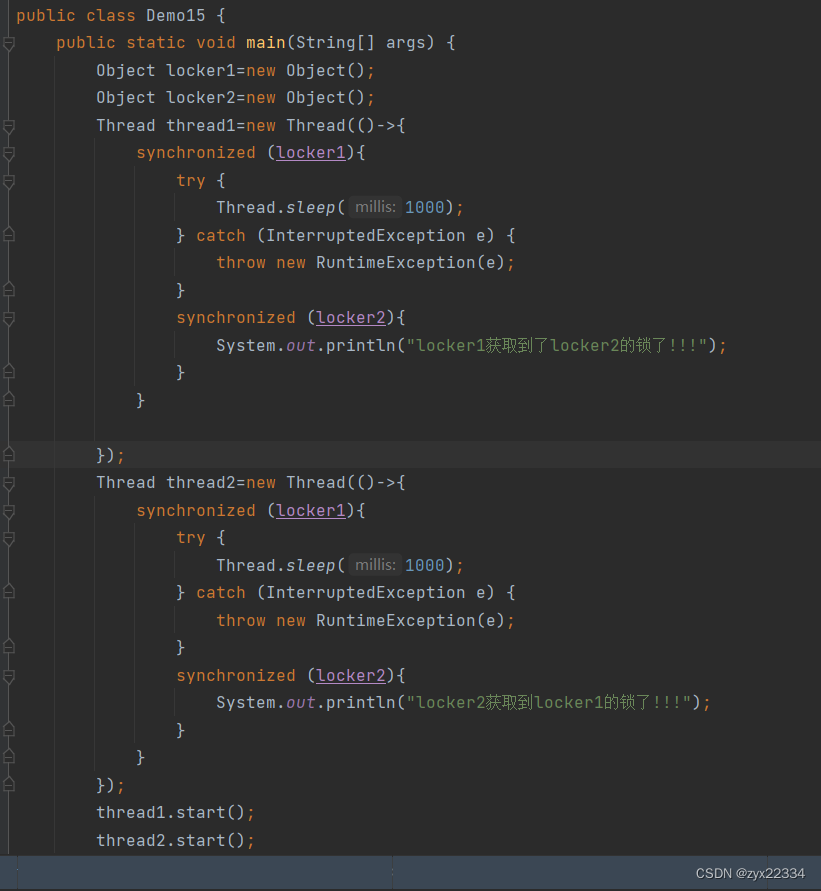
2.两个线程两把锁, t1 和 t2 先各自针对 锁A 和 锁B 加锁,再尝试获取对方的锁.
举个例子:去年一码通寄了,维护的程序员走到存放一码通服务器的大楼底下,遇到了个保安,但保安说让他出示一码通,但程序员说:我需要上楼修好bug后才能出示一码通.
这就是"死锁".
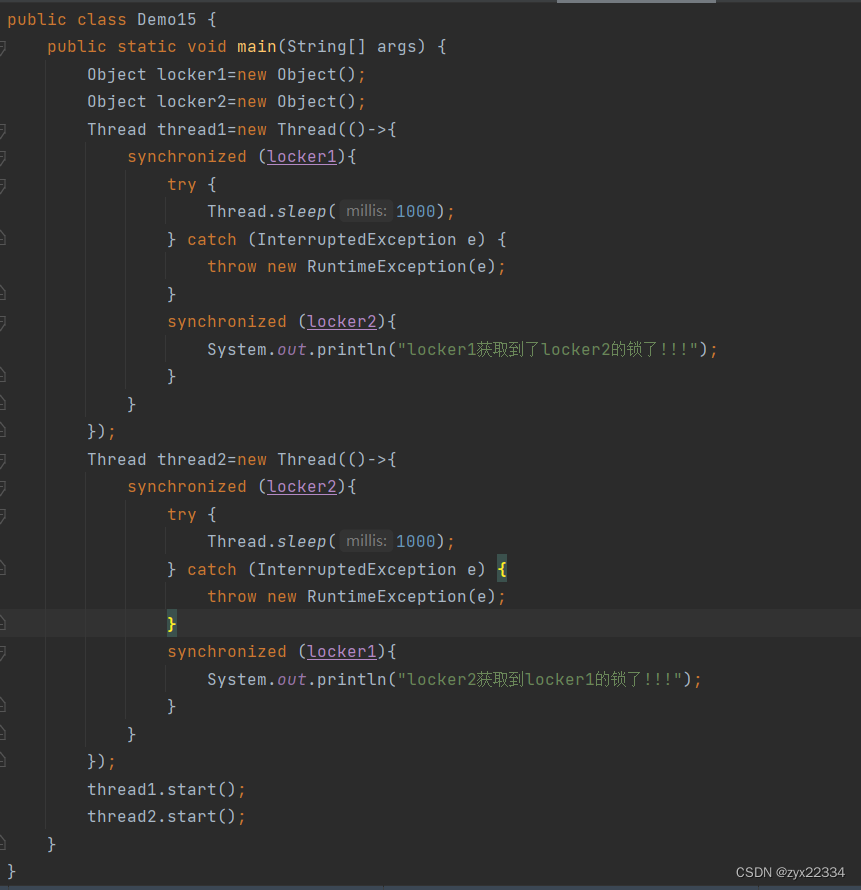
这个代码,使locker1和locker2分别尝试获取对方的锁,最终导致双方都无法达成目标,使得程序无响应.
3.多个线程多把锁(相当于2的一般情况)
例子:哲学家就餐问题(教科书上的经典案例)
现在又5个哲学家和一碗面
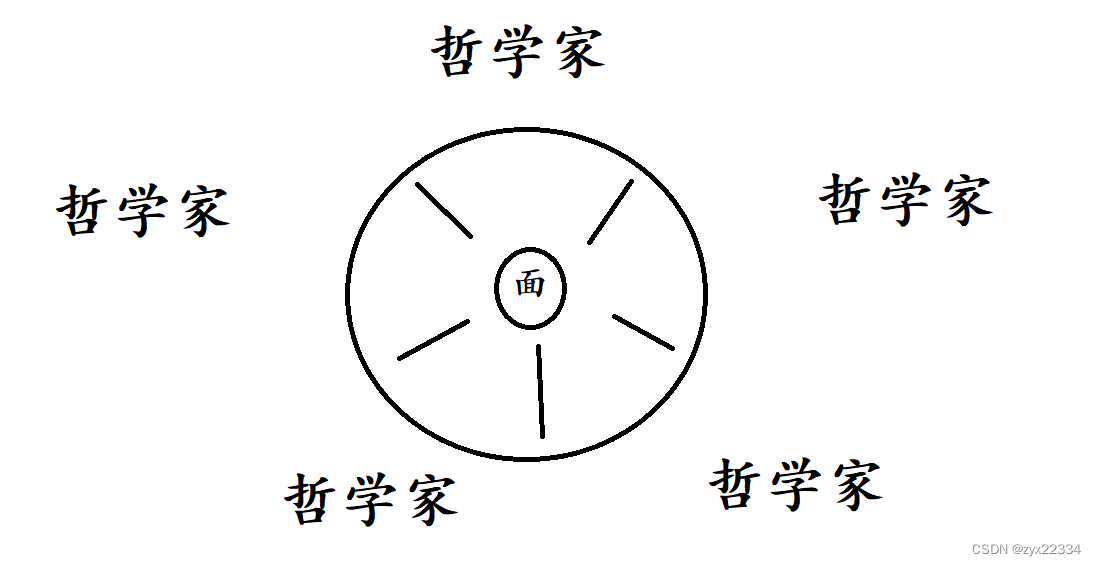
每个哲学家又两种状态:
1.思考人生(相当于线程的阻塞状态)
2.拿起筷子吃面条(相当于线程获取到了锁进行一些运算)
由于操作系统的随机调度,每个哲学家随时都有可能吃面条或者思考人生.但想要吃面条需要左手和右手同时拿起筷子.
假设出现了极端情况:
每个哲学家同时伸出了左手,但是这是他们都在阻塞等待其他人放下他们右手的筷子,这是就出现了"死锁".
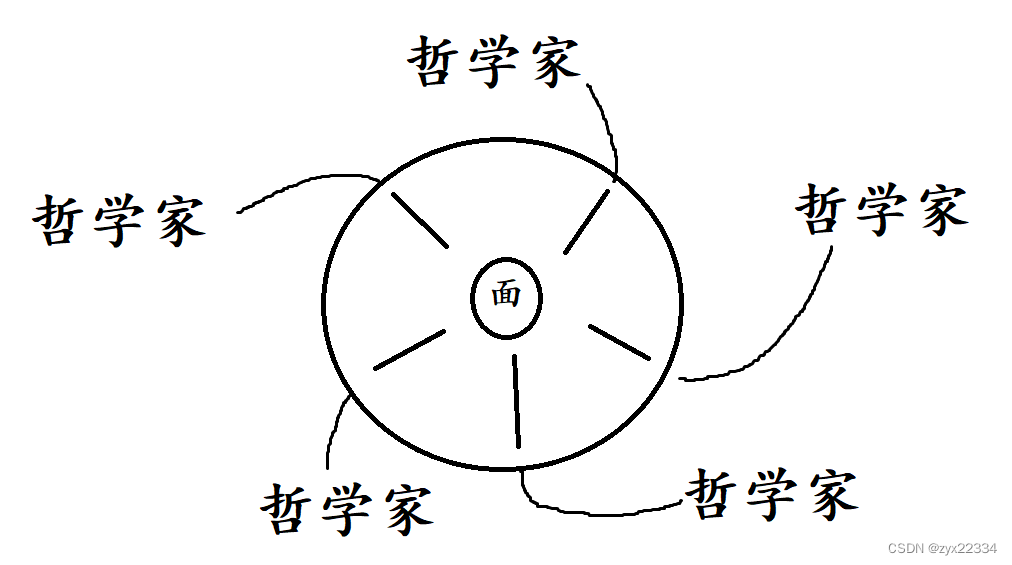
死锁的解决办法:
1.可以使用jconsole小工具查看出现死锁的行数再做调整.
2.突破口:循环等待(更改或者设置获取所得顺序)
如果将上面代码按照以上标准更改:
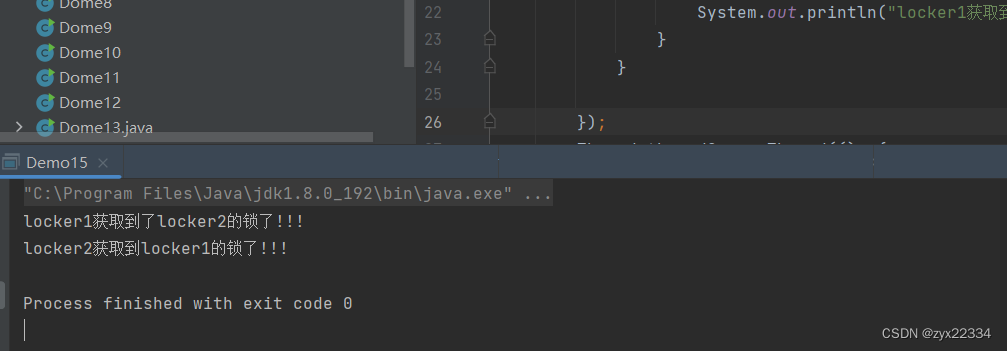
就能够正常运行:
3.内存可见性问题
本质上是JVM对编译自主对程序进行胜率的问题.
举个例子:
这个代码,实现的是用线程2修改flag的值使得线程1结束.
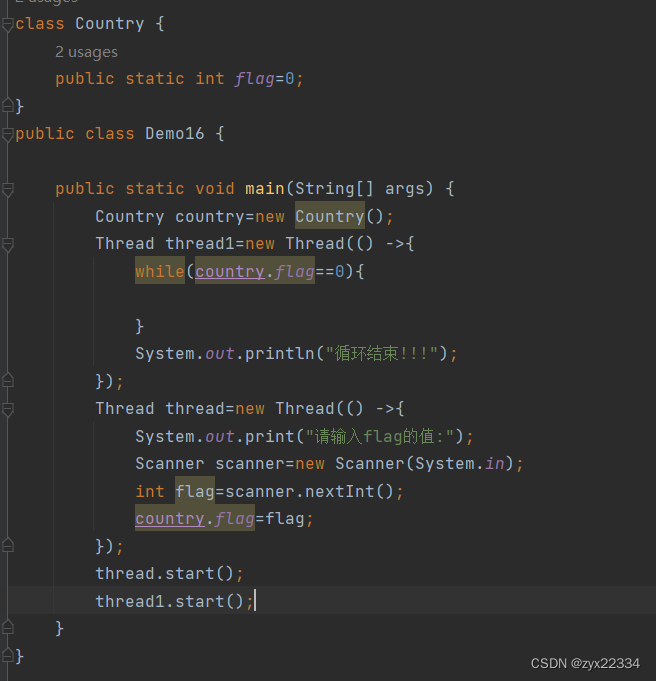
但真正运行后发现,修改值后程序并未结束.
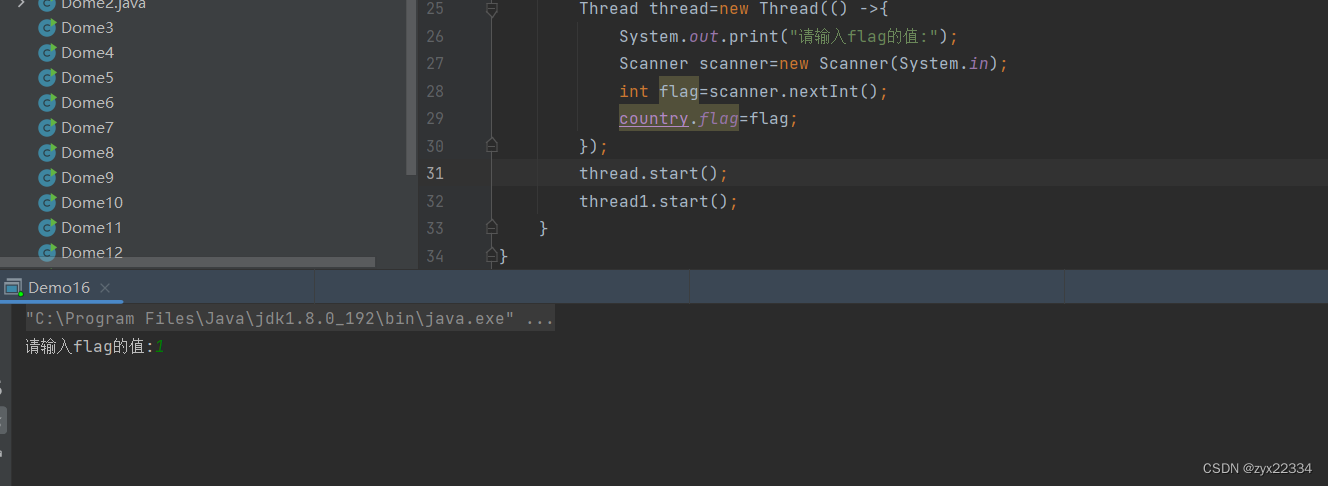
这里利用汇编得理解,大致是两个操作:
1.load,把内存中的flag值,读取到寄存器中.
2.cmp,把寄存器里的值和0进行比较,根据比较结果进行下一步的代码操作.
但由于load得速度太慢(相比cmp),而且每次load的值都一样,所以JVM觉得不需要多次重复进行这个操作,所以就自主的把此操作给"省了",这就是编译器优化.
所以说内存可见性问题大致可以概括为:
一个线程针对一个变量进行读取操作,同时另一个线程针对这个变量进行修改操作,此时读到的值,不一定是修改之后的值.(归根结底就是编译器/JVM再多线程环境下优化时产生了误判)
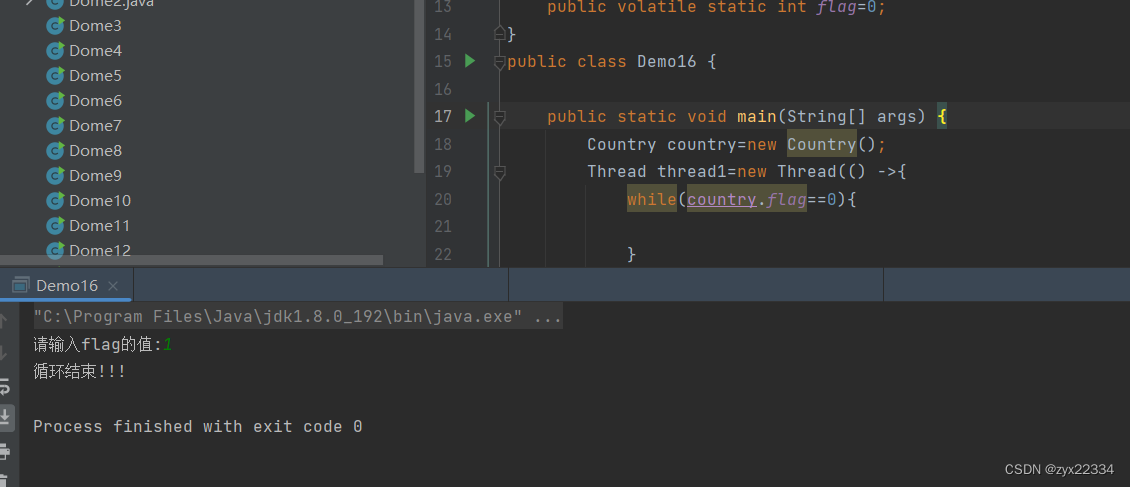
这时就应该由程序员手动引入一个关键词:
volatile让编译器取消优化.
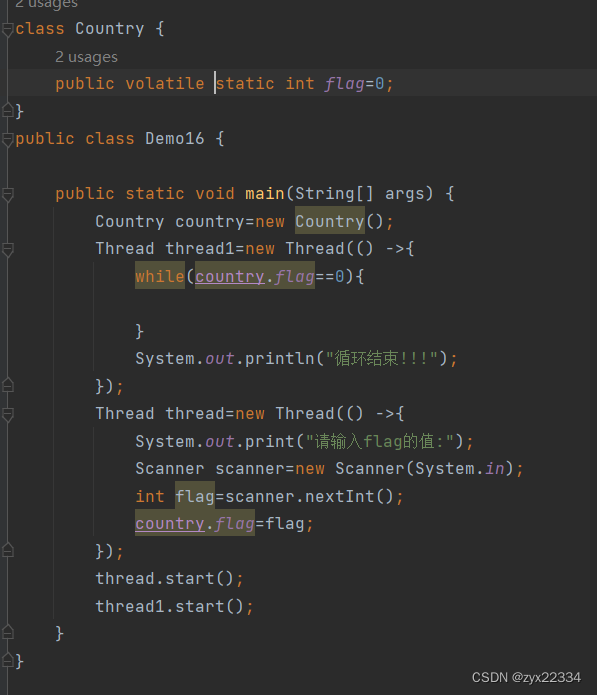
这样程序就可以顺利运行了!!!
4.Java标准库中的线程安全类
 这些类在使用中需要格外注意,容易发生线程安全问题.
这些类在使用中需要格外注意,容易发生线程安全问题.
 这些类都内置了锁,不会发生线程安全问题
这些类都内置了锁,不会发生线程安全问题
5. wait和notify
线程最大的特带就是随即调度,抢占式执行,但我们喜欢固定的东西,不喜欢随机的东西,所以说程序员就发明了一种利用api确定线程运行顺序的方式.就是使用wait和votify.
具体使用方法就是:比如,t1和t2俩线程,希望t1先干活,干的差不多,再让t2干,就可以先用wait让t2阻塞,等t1把该干的都干完,再通过votify唤醒t2,让t2接着干活.
注意:wait、notify、notifyAll这几个类都是Object类的方法.
所以在使用这些类之前必须要实例化Object对象.
但在使用之前,我们首先要弄清楚wait是干嘛的:
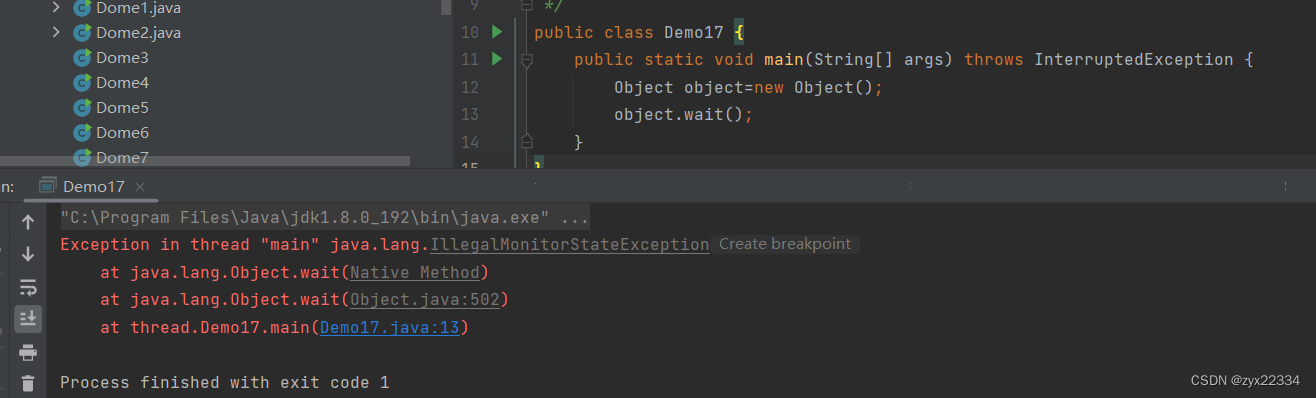
1.先释放锁.
2.再进行阻塞等待
3.收到通知后,重新尝试获取锁,并且再获取到锁后继续往下运行.
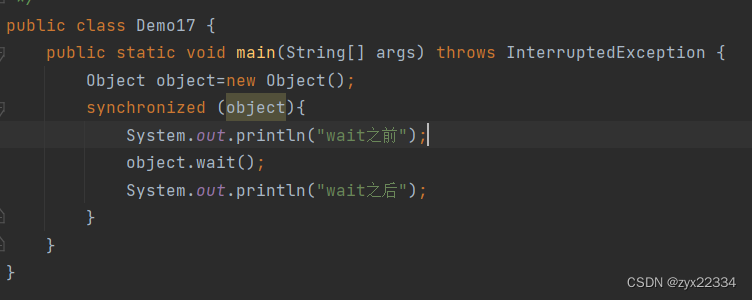
这里的object.wait()的作用是短时间把针对对象object的锁释放,此时可以随意调取或调整里面的变量,再object收到notify的通知后,恢复锁.
下面是一个wait、notify完整的使用过程:
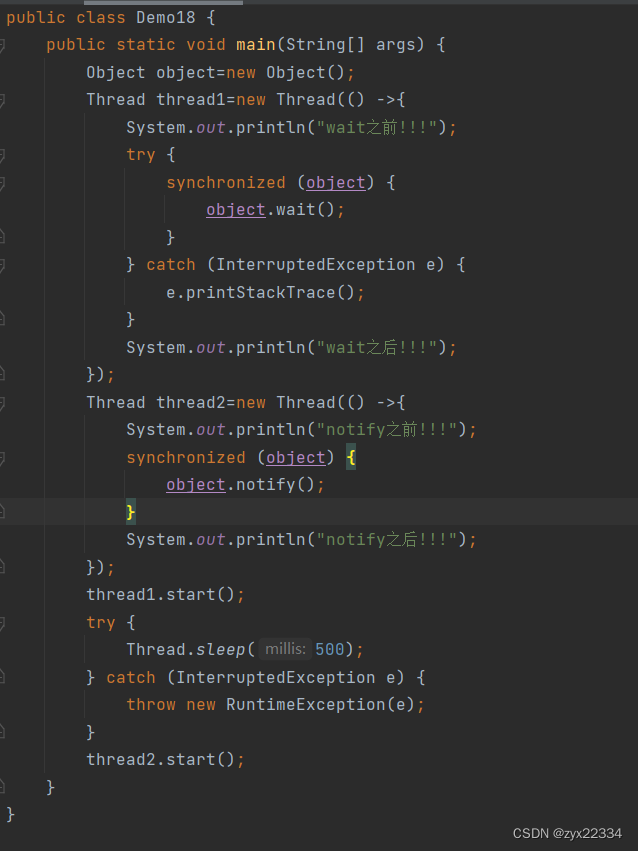
注意:wait、notify一个获取锁一个释放锁,两个都离不开锁,而且锁的对象还都得是一个否则无法达到上传下达的目的.
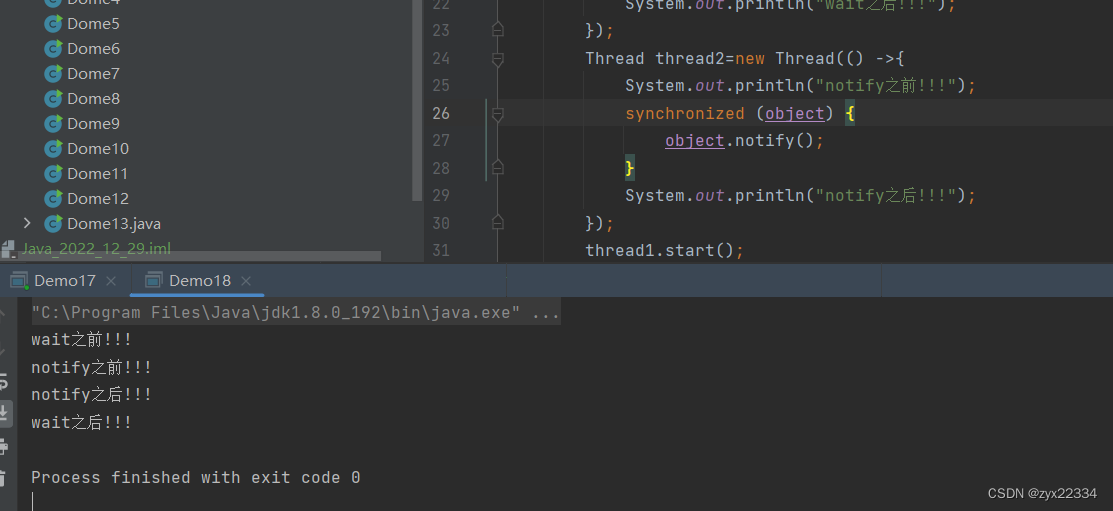
顺序:t1前->t2前->t2后->t1后.
notifyAll就是唤醒所有正在wait的线程,然后让他们自己竞争.
五、设计模式
设计模式是为了约束程序员们的代码,所制定的模板,只要按照模板完成程序就能极大程度的减少其中的错误和冗余.
编写代码的约定和规范.
1.单例模式
在有些场景中,由特定的类,只能创建出一个实例,不能创建出多个实例.
Java中实现单例模式的方式有很多,其中最主要的两种:
1)饿汉模式
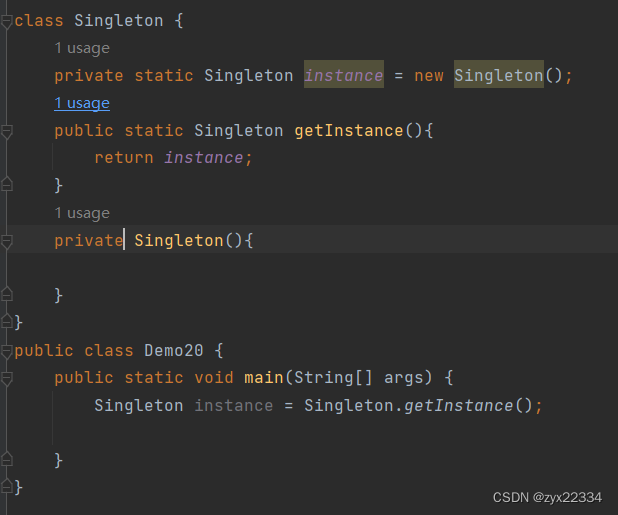
饿汉模式的设计就是为了不能实例化多个对象而生,所以说饿汉模式由三部分组成:
1.![]()
先将private的Singleton类型的instance实例在类的里面,让外界无法实例化.
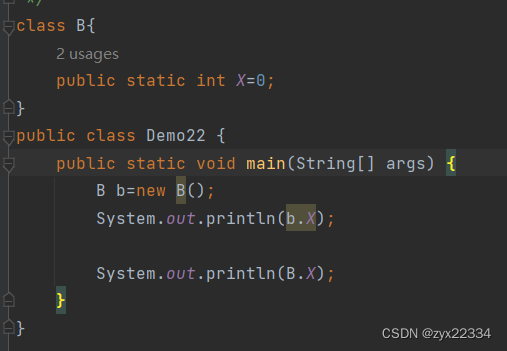
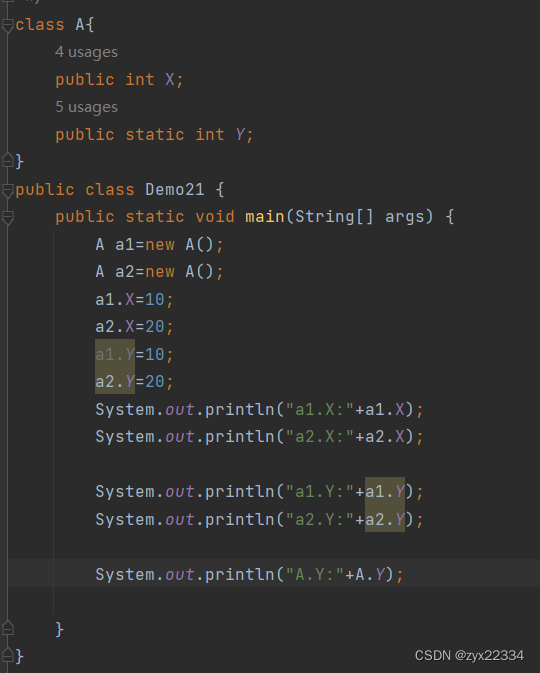
这里补充一个知识点:(静态成员和普通成员的区别)
首先,静态成员可以用两种方法调用:
使用new实例化的方式,然后用对象进行调用.
或者直接用类名调用.
普通成员实例化后,利用对象调用能够根据不同的对象调用来存储不同的值.
而静态成员实例化后,运行在编译阶段,不管怎么修改都只能存储最后的值.
利用静态成员在类的内部实例的instance只能有且只有它一个且还用private封装只能使用getInstance()获取,保证了它的唯一性.
这个static将成员变量规定为静态的,如果是普通的则需要在类外进行new然后调用,但此时的构造方法阻止了new,而且static还能将instance的创建时间固定在程序执行之前(静态代码块里).
为了使类外能够使用instance增加一个getInstance()方法:
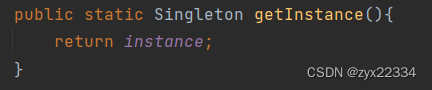
最后为了让Singleton不被外界复制多份,在类的内部完成其private的构造方法.
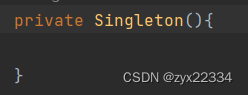
此刻,只能够有一份实例的饿汉模式就诞生了:
2)懒汉模式
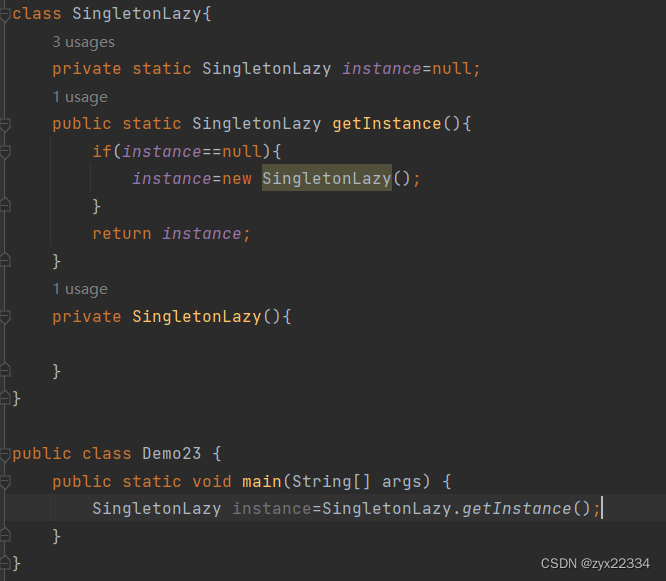
懒汉模式跟饿汉模式基本一样,只不过事先把instance设定为空,在用的时候再进行创建.
饿汉模式跟懒汉模式相比:
懒汉模式的效率更高.
另外,我们发现懒汉模式因为多了个和null比较的操作所以有可能发生线程安全问题.而饿汉模式就没有这种顾虑.

可以看到懒汉模式的t1与t2线程分别读到了null两次.所以也new了两次.发生了线程安全问题.
所以说懒汉模式必须要加锁:
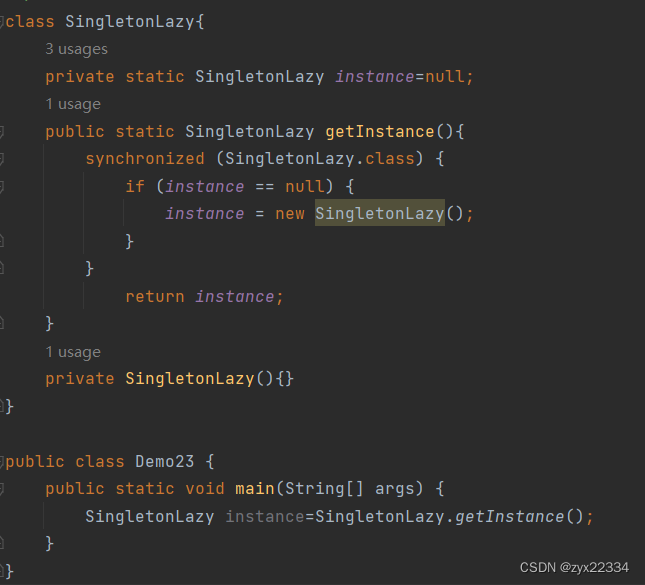
但是,加锁会对程序执行的效率产生极大的影响,而且在实例完对象后新的调用依然会使用到锁,这样会对程序的效率进一步的影响.所以说最好还是在锁的外面添加一个判断.
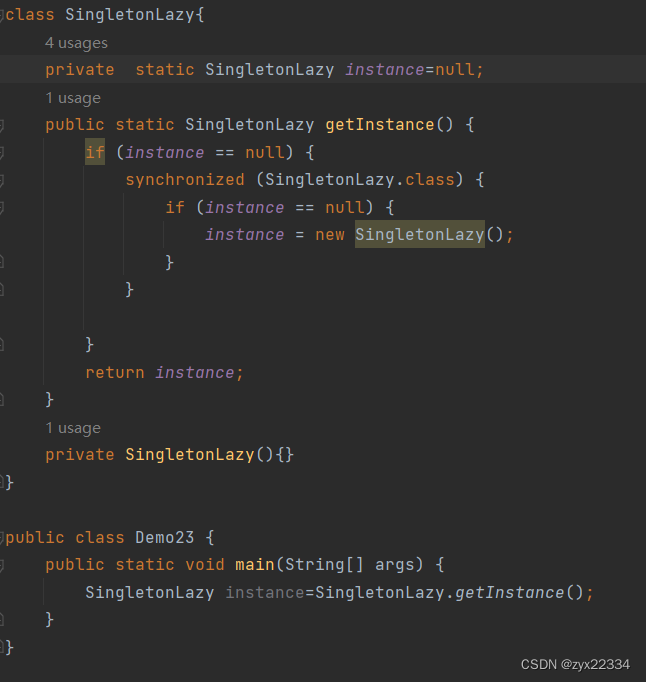
注意:这里的两个if(instance==null)都有存在的必要,其作用不一样,能够提高效率.
另外,懒汉模式还会遇到指令重排序问题:
就是编译器自主的为了提高效率,调整代码的执行效率.
主要是:instance=new SingletonLazy()这个语句,主要分为三个步骤:
1.申请内存空间.
2.调用构造方法,把这个内存空间初始化成一个合理的对象.
3.把内存空间的地址赋值给instance引用.
所以要加上volatile.
volatile有两个作用:
1.防止指令重排序.
2.解决内存可见性.
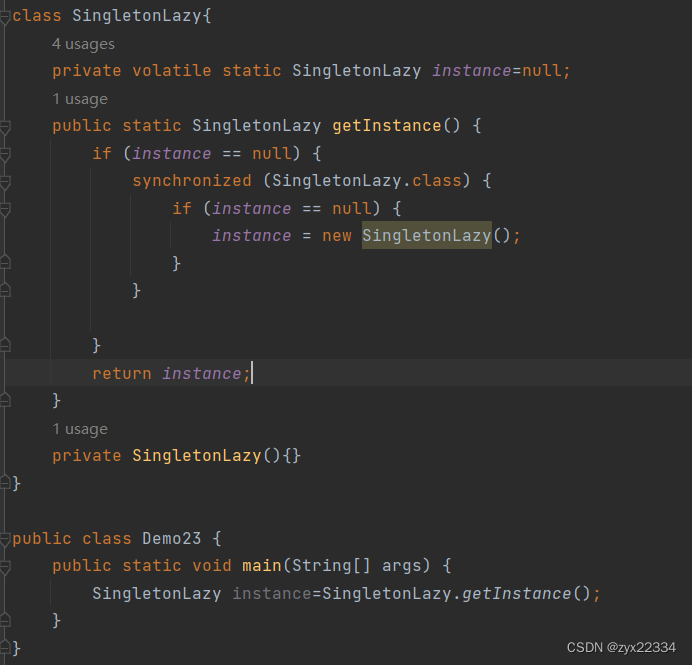
这样,懒汉模式才真正的完成了.
2.阻塞队列
阻塞队列是特殊的队列,虽然是先进先出的,但是带有特殊的功能:
1)如果队列为空,执行出列操作,就会阻塞.阻塞到另外一个线程往队列中添加元素(队列不空)为止.
2)如果队列满了,执行入队操作,也会阻塞.阻塞到另外一个线程从队列中取走元素为止(队列不满).
消息队列,实在阻塞队列的基础上加上一个附带"消息的类型"的功能.
基于阻塞队列的特性,可以让使用者实现"生产者消费者模型":
什么是"生产者消费者模型",简单来说就是流水线.
一部分线程负责生产,一部分线程负责消费,比如说,过年包饺子,最有效率的方式就是几个人"分工合作",一个人负责擀面皮,剩下人负责包饺子.
另外,生产者消费者模型也能为我们的程序带来很大的好处:
1)实现了接收方和发送方的"解耦合"
举个例子:开发中经典的服务器调用.
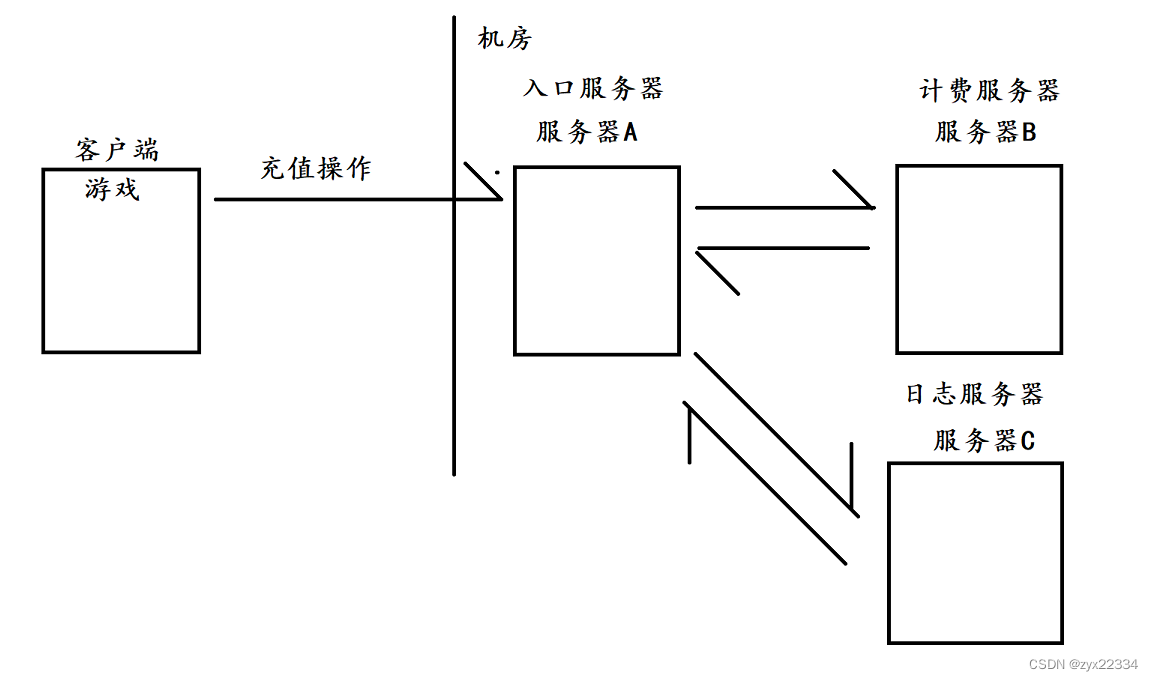
在这个案例中,客户端执行了充值操作,信息由客户端转到A,再由A分别转到B、C.这就属于耦合比较高的情况.我们要知道如果A要调用B和C,首先要知道B和C的存在,一但B和C出现了bug,A也不可能"独善其身",进而影响到客户端.
而且如果我们此时要新增一个服务器D,那么将会对A进行很大程度的代码部分的更改.
假如我们使用了"生产者消费者模型",就可以有效的降低耦合.
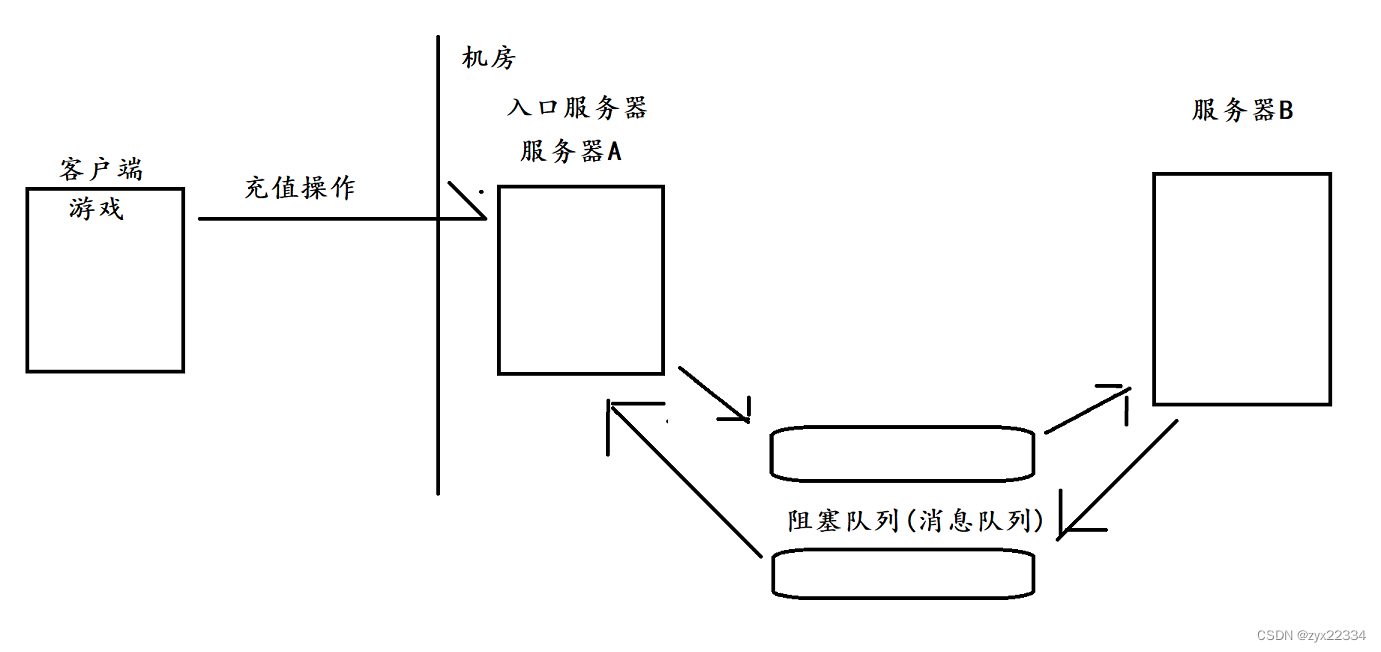 此时,A是不知道B的,A只知道阻塞队列(A中的任意一条代码和B都不相关)
此时,A是不知道B的,A只知道阻塞队列(A中的任意一条代码和B都不相关)
B也是不知道A的.B也是只知道阻塞队列.
如果B挂了,对于A没有任何影响,A仍然可以往阻塞队列中插入数据和从阻塞队列中提取数据.
而且如果想要新增一个C只要调用队列即可,对A和B的代码没有任何的影响.
2)生产者消费者模型,第二个好处就是"削峰填谷",以保证系统的稳定性.
"削峰填谷"是什么呢?举个例子:
三峡大坝
在每年发大水的时候,三峡大坝都能起到很好的御洪的效果.是我们人类工程的奇迹.
它的主要作用是:
削峰
如果上游水多了,三峡大坝就关闸蓄水.承担了上游的冲击,对下游起到了很好的保护作用.
填谷
如果上游水少了,三峡大坝就开闸放水.有效的保证了下游的用水,避免干旱的出现.
这个实现在我们的服务器开发上也是一样的,对于上游来的水的大小(客户端的数据量的大小)我们是无法掌控的.有的时候多,有的时候少.如果服务器扛不住客户端的大流量,服务器就会崩溃.而生产者消费者模型起到了良好的缓解的作用.
接下来我们来看代码的实现:
常用的阻塞队列:
1.LinkedBlockingDeque基于链表的阻塞队列

2.基于优先级队列的阻塞队列
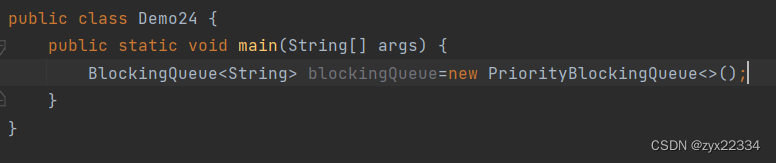
3.基于数组的阻塞队列

阻塞队列能够调用的方法:
Queue提供的方法由三个:
1.offer
2.poll
3.peek
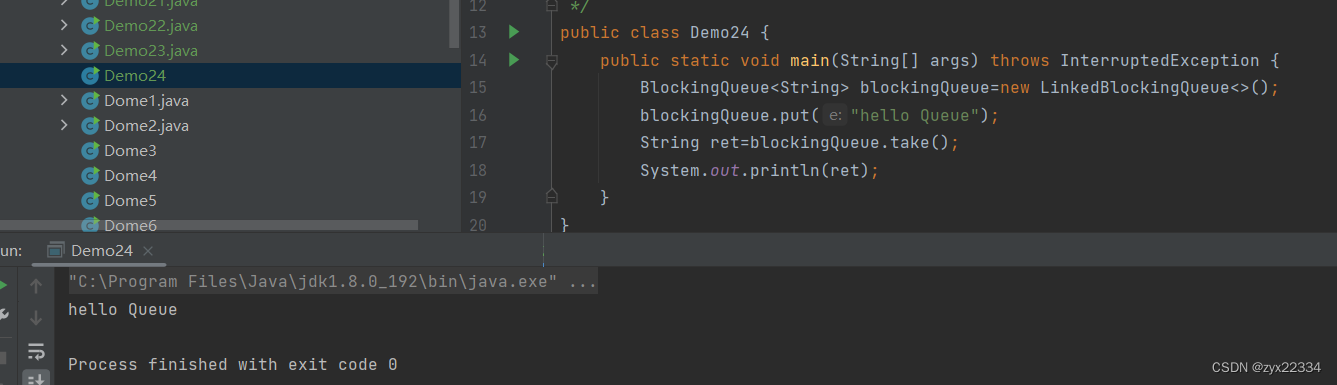
而BlockingQueue主要的方法是两个:
1.入队列:put
2.出队列:take
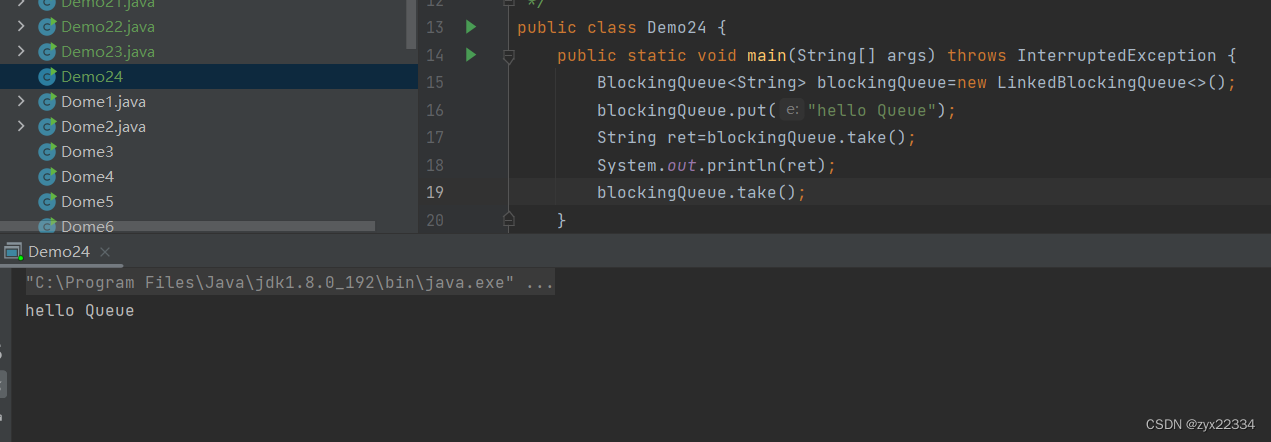
而再次从空队列中取元素就会产生阻塞:
阻塞队列自我实现:
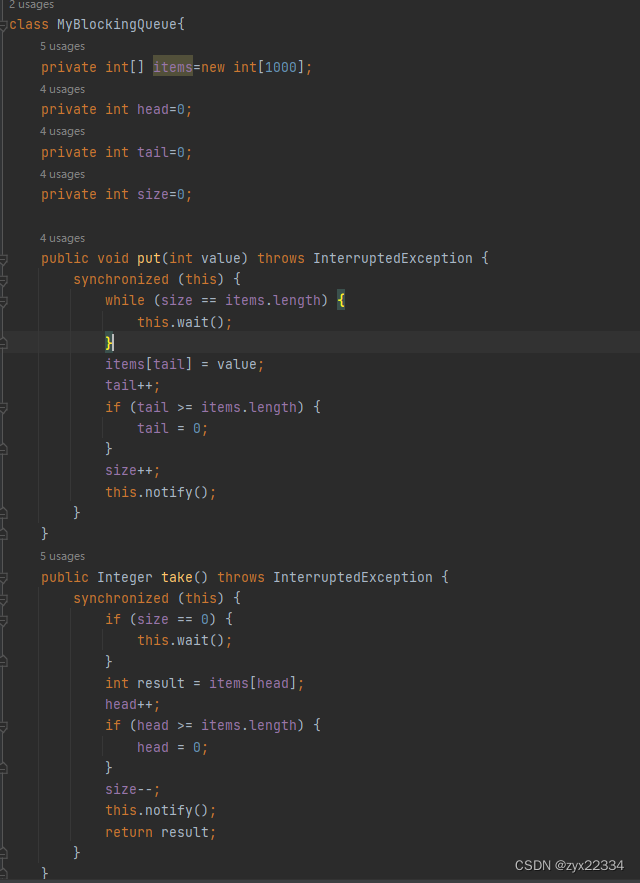
注意这里:

为确保在数组满了之后线程进入阻塞等待直至有元素被弹出,需要使用while循环判断数组是否满了.
这里面用来存储整形的数组,是循环数组,循环数组具体有两种实现的方式:
1)
- tail++;
- if(tail >= items.length){
- tail=0;
- }
2)
- tail++;
- tail=tail % items.length;
这两种方法相比,第一种强于第二种,因为如果拆分来看,第一种是比较+赋值操作,而第二种是取余+赋值操作.比较相比取余来说极大的提高了效率.
3.阻塞队列例子:定时器
定时器就类似于闹钟,日常生活中的定时器大概有两种风格:
1) 指定特定时刻,提醒
2) 指定特定时间段,提醒
这里我们选取的是第二种风格
首先我们要介绍一下标准库中的定时器:
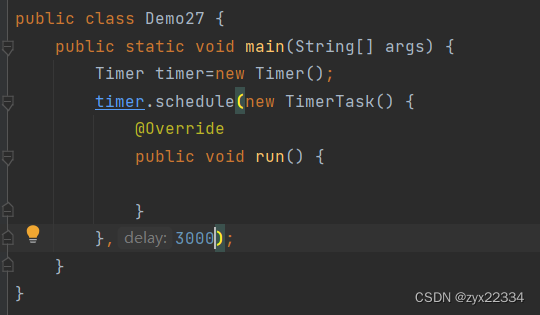
标准库中的Timer类中有两个参数:
1)Runnable
2)时间dalay(就是多久之后完成Runnable中的任务)
timer.schedule(安排)使用其功能.
之后我们自己实现这个定时器:
功能:
1.能够让任务在指定的时间得到执行
2.一个定时器可以注册N个任务,N个任务可以按照最初约定的时间,按顺序执行.
根据任务我们能得出结论:
1.我么需要一个线程扫描,负责判断时间是否到了/并执行任务.
2.还需要一个数据结构,来保存所有注册的任务.
因为我们希望程序会优先执行距离截至时间进的任务,所以我们能够想到,使用优先级队列这个数据结构更能解决这个问题.
这样我们的扫描线程就只扫描队首任务的时间就可以了.
另外,多线程代码,需要注意线程安全问题,而优先级队列是"不安全的",所以我们这里可以使用阻塞优先级队列
根据上面的分析:

我们在定时器里需要一个扫描线程和一个阻塞优先级队列
但是,这里的队列类型又怎么设定呢?
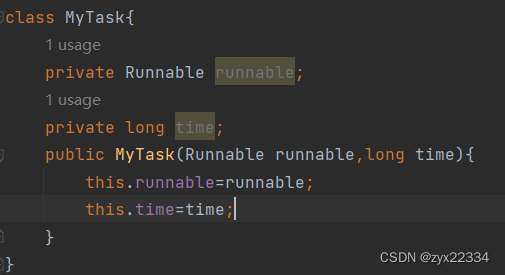
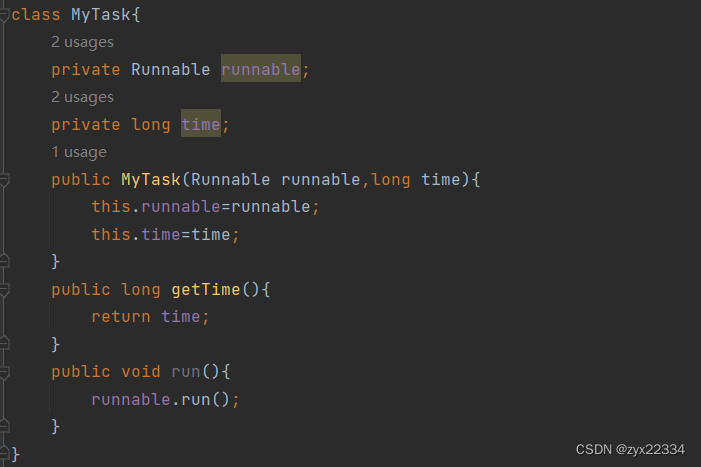
我们的任务类型中应当存储着一个任务类型和时间类型.
所以说可以新设定一个类来充当任务类型:
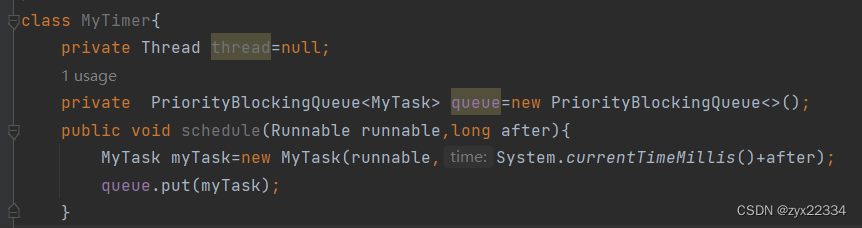
接下来就是schedule方法的编写了:

注意:这里我们的时间after需要加上当时的系统时间,就使用System.currentTimeMillis()来获取.
接下俩把任务塞到队列里去:
现在该来处理扫描线程了:
反复扫描队列里的任务时间,是否到达了现在的系统时间,
如果没到达,将任务重新塞回队列:

这里注意,要完成上面未完成的getTime方法,因为成员都是private的,所以要写个get方法获取时间和运行任务.
如果时间到了,运行任务:
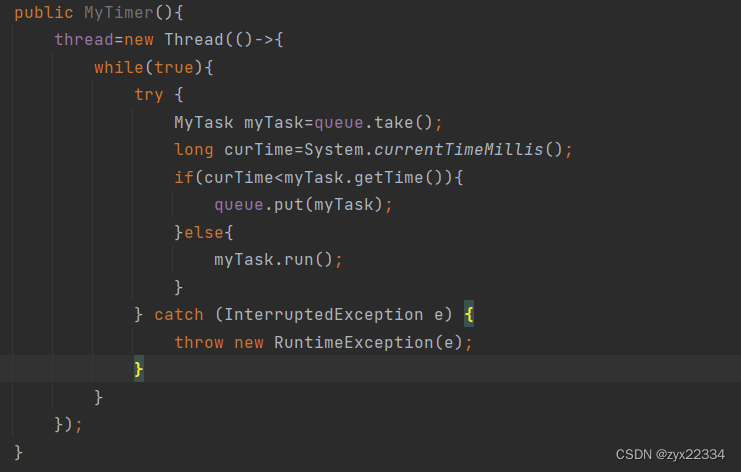
接下来的程序写的就已经差不多了:
但在上述代码中,还存在这三个重大的问题:
1)未指定MyTask依照怎样的优先级

如果现在尝试运行多个任务,系统就会报错.
需要实现compareTo方法:

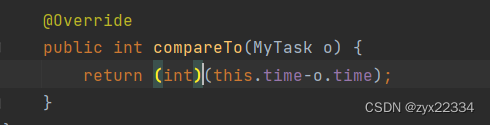
技巧:这里是this.time-o.time还是o.time-this.time不要去死记硬背,去程序中试一试就行了
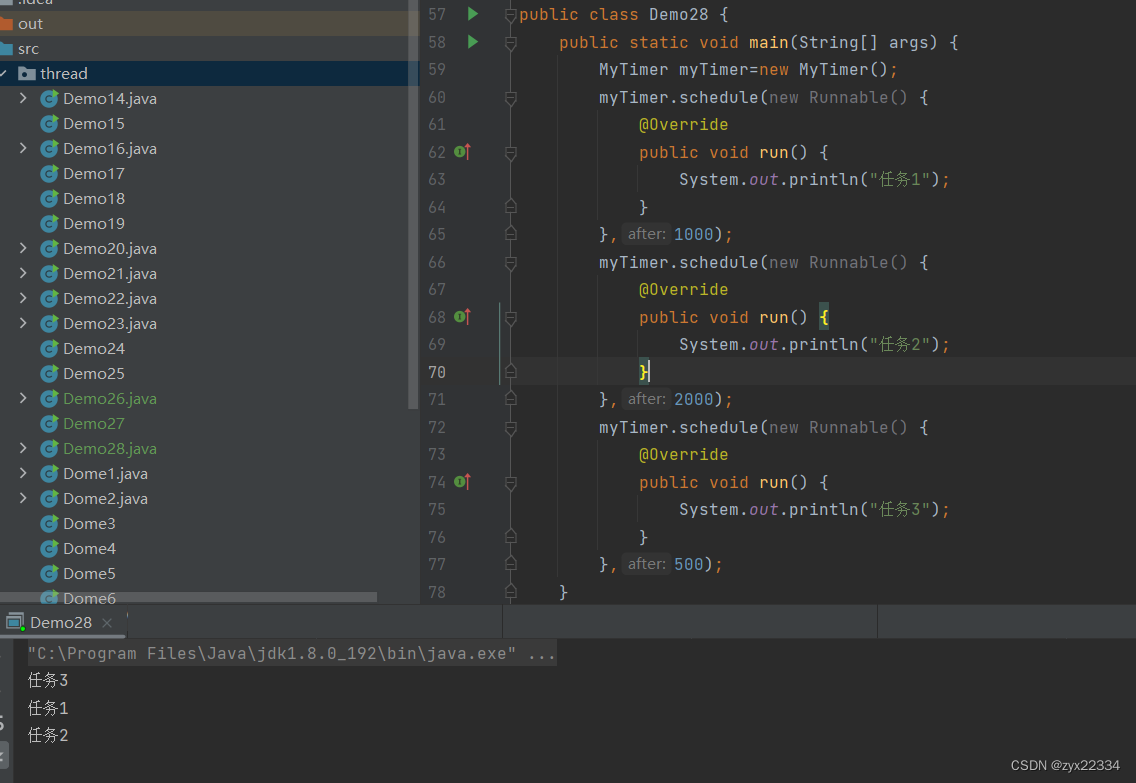
现在发现设定时间最短的任务3最先运行,所以就对了.
2)还有一个问题就是时间不到,系统会一直重复把队首任务取出来然后再塞回去的操作,浪费了极大的资源,这种问题被程序员称为"忙等".
这里我们可以使用wait、notify的超时时间版本来解决这个问题:
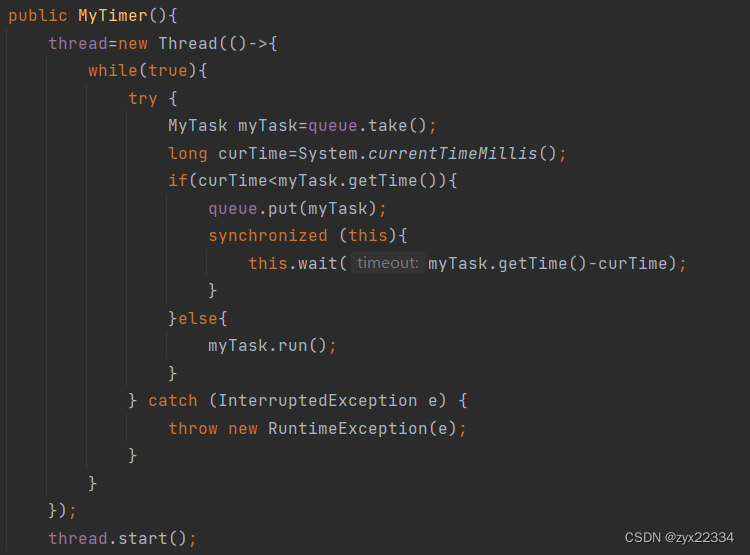
直接让循环阻塞,然后在schedule中进行notify通知线程唤醒.
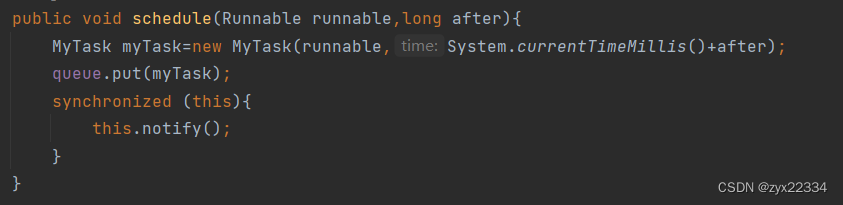
3)看下面这段代码:
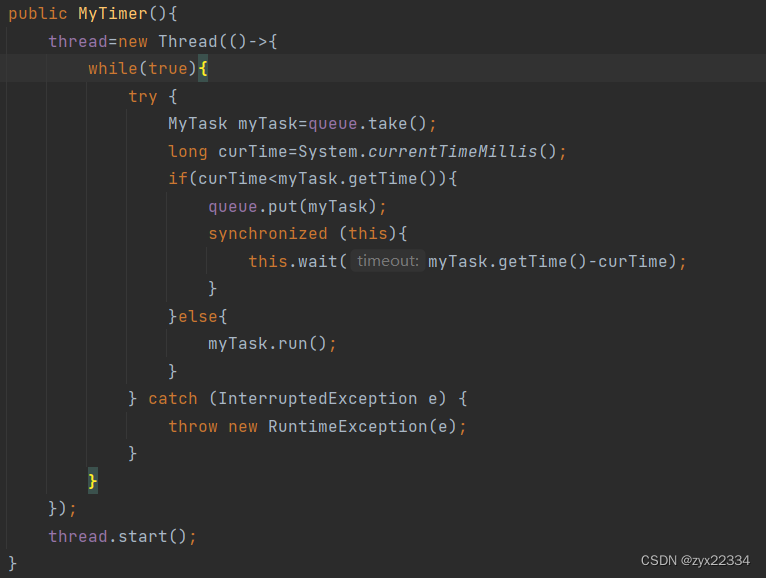
扫描线程代码,考虑一种极端情况:如果在MyTask myTask=queue.take();现在的队首元素被弹出正在比较之时,这是又进来了一个运行时间更短的任务夹在了队首,而这时,刚刚正在判断的myTask判断时间未到重新回到了队列,那么那个需要被执行的时间短的任务就被错过了.
假设现有一个队首任务1是在2点执行,而它正在判断的同时进来了个1:30执行的任务2,此时2点的任务又回到了队列,此时队首的任务1又回到队列成为了队首元素,而此时任务2就被永远错过了.
然而我们的解决方法还是很简单的,只要扩大下面锁的范围,让它包括住MyTask myTask=queue.take().
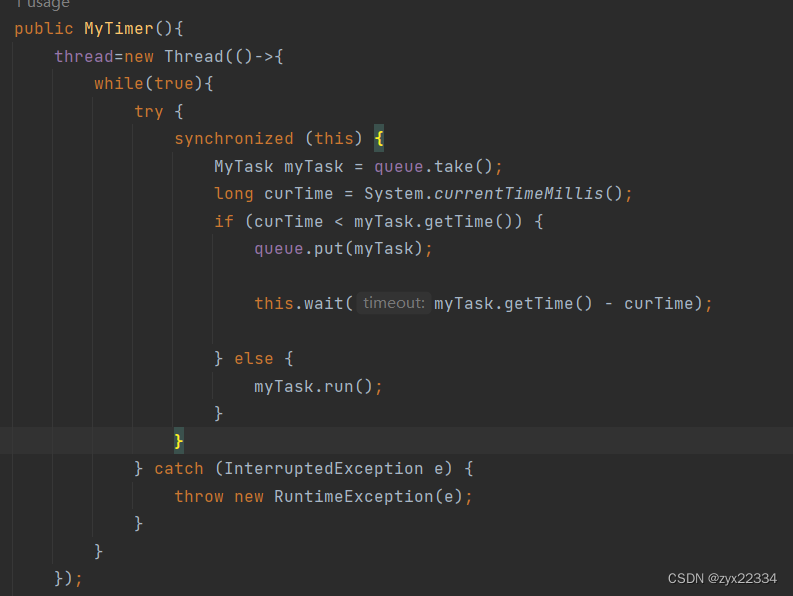
这样我们的定时器就完成了!!!
- package thread;
-
- import java.util.concurrent.PriorityBlockingQueue;
-
- /**
- * Created with IntelliJ IDEA.
- * Description:
- * User: DELL
- * Date: 2023-01-08
- * Time: 19:30
- */
- class MyTask implements Comparable<MyTask>{
- private Runnable runnable;
- private long time;
- public MyTask(Runnable runnable,long time){
- this.runnable=runnable;
- this.time=time;
- }
- public long getTime(){
- return time;
- }
- public void run(){
- runnable.run();
- }
-
- @Override
- public int compareTo(MyTask o) {
- return (int)(this.time-o.time);
- }
- }
- class MyTimer{
- private Thread thread=null;
- private PriorityBlockingQueue<MyTask> queue=new PriorityBlockingQueue<>();
- public void schedule(Runnable runnable,long after){
- MyTask myTask=new MyTask(runnable,System.currentTimeMillis()+after);
- queue.put(myTask);
- synchronized (this){
- this.notify();
- }
- }
- public MyTimer(){
- thread=new Thread(()->{
- while(true){
- try {
- synchronized (this) {
- MyTask myTask = queue.take();
- long curTime = System.currentTimeMillis();
- if (curTime < myTask.getTime()) {
- queue.put(myTask);
-
- this.wait(myTask.getTime() - curTime);
-
- } else {
- myTask.run();
- }
- }
- } catch (InterruptedException e) {
- throw new RuntimeException(e);
- }
- }
- });
- thread.start();
- }
- }
- public class Demo28 {
- public static void main(String[] args) {
- MyTimer myTimer=new MyTimer();
- myTimer.schedule(new Runnable() {
- @Override
- public void run() {
- System.out.println("任务1");
- }
- },1000);
- myTimer.schedule(new Runnable() {
- @Override
- public void run() {
- System.out.println("任务2");
- }
- },2000);
- myTimer.schedule(new Runnable() {
- @Override
- public void run() {
- System.out.println("任务3");
- }
- },500);
- }
- }

六、线程池
线程池的目的是,降低创建/销毁线程的开销.需要事先把使用的线程创建好,放到"池"中,需要用的时候,直接从"池"中获取,如果用完了,也还给"池".这样比创建和销毁线程更加高效.
线程的创建和销毁是在操作系统层由操作系统内核来进行操作的,而线程池的调用是在应用层由程序员进行操作的.所以说线程池的使用比创建销毁线程更加高效!!!
![]()
创建了一个线程池,里面的线程数固定是10个
newFixedThreadPool() 这个类,相当于某个静态方法直接new了一个对象,(相当于是把new操作隐藏到后面了),这样的方法,我们称为"工厂方法",提供它的类被称为"工厂类"而它使用的设计模式,就是"工厂模式".
工厂模式:就是使用普通的方法,来代替构造方法,创建对象.(为什么要代替构造方法?因为构造方法只能采用一种方法来描述对象,如果现在我想用复数的方法来描述对象,构造方法就不行了)
这里先梳理一下重载(overload)和重写(override)的区别:
首先是重载,重载只要求多个方法的方法名相同,返回类型,参数的个数类型不同,而重写要求方法的返回类型,方法名,参数的个数,类型都相同.
接下来是重载要求在一个类中构成重载,在父类或者子类中也可以构成重载的,而重写需要通过父类子类的继承关系来实现.本质上使用新的方法来代替旧的方法,所以方法的返回类型,方法名,参数的个数,类型都应该相同.
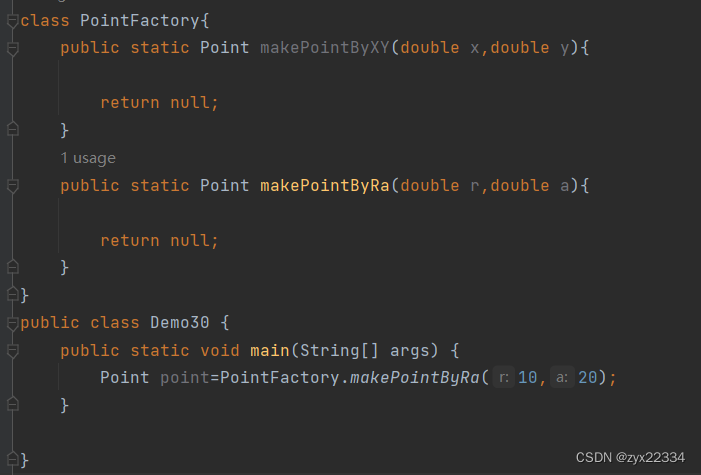
回归正题,如何使用线程池里的线程?
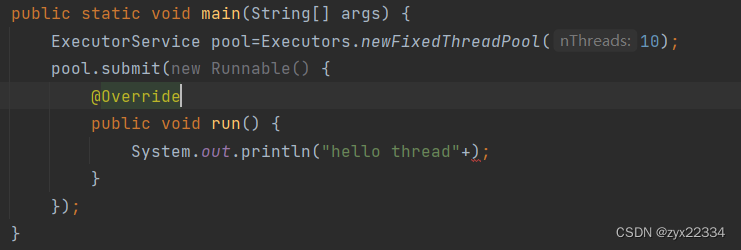
使用pool.submit使用线程池里的线程进行操作.
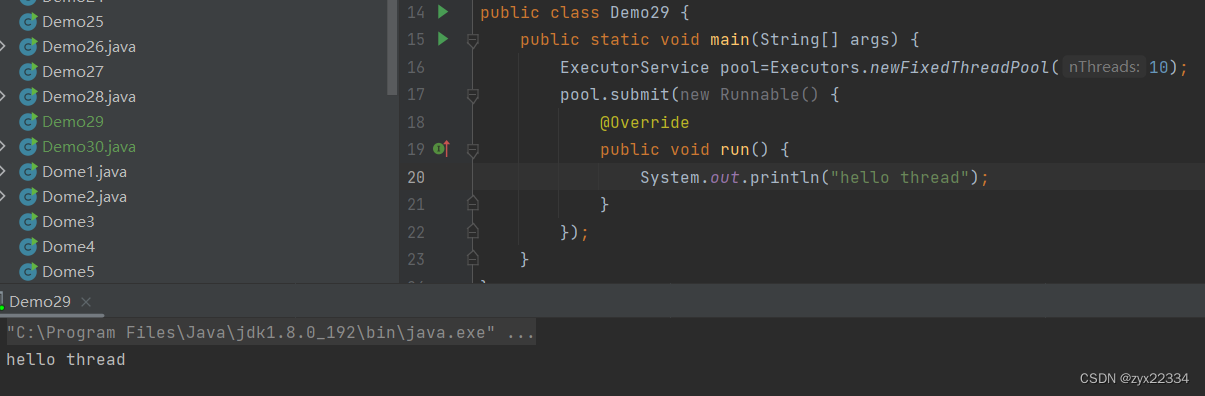
线程池不是一个线程执行一个任务,而是10(你设定的数量)个线程抢占式执行你布置的所有任务:
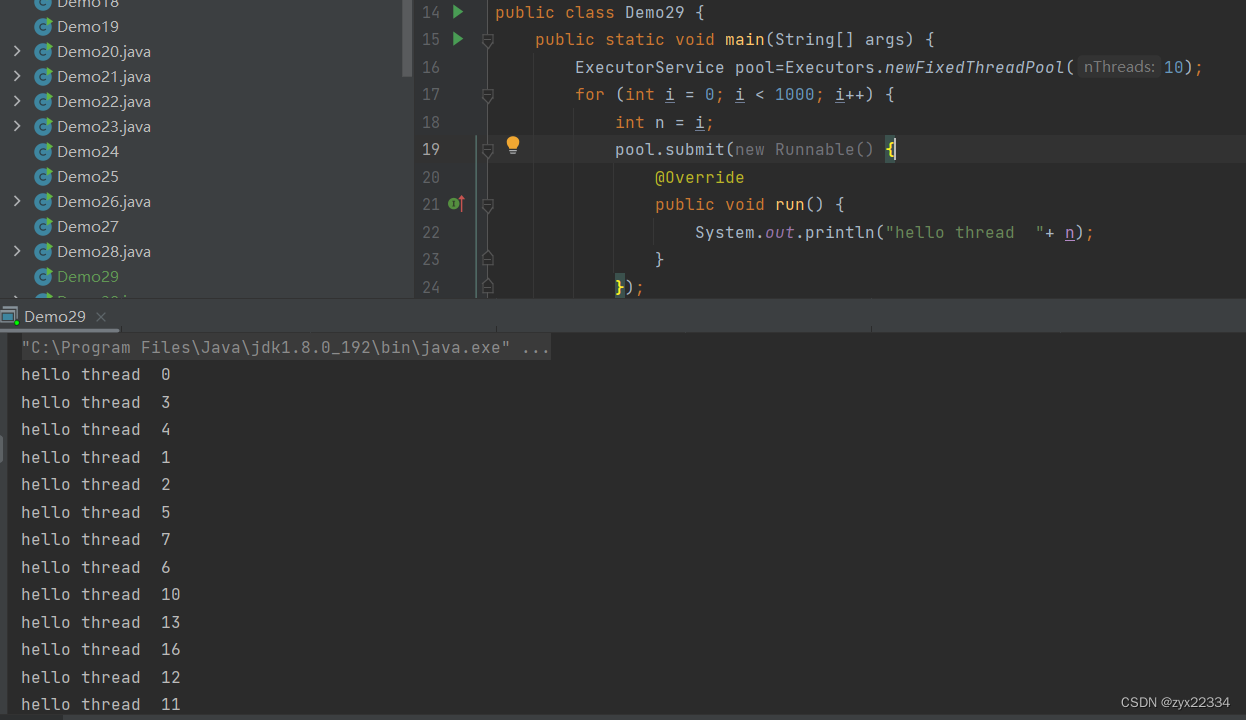
注意这里的i存在变量捕获问题,因为多线程的抢占式执行,所以很有可能在执行打印i的时候,i已经在栈上销毁了,所以需要用临时变量n来记录i然后使用n来打印.
另外,还有一些线程池:

这个线程池的代码import了java.util.concurrent这个包, concurrent指的就是并发编程简称juc

这是JDK手册里的线程池:
![]() 这是核心线程数
这是核心线程数
![]() 这是最大线程数
这是最大线程数
在ThreadPoolExecutor相当于把线程分为了两类:
1.正式员工(核心线程)
2.零时工/实习生
允许正式员工摸鱼,但不允许实习生摸鱼,实习生摸鱼太久了会直接被开除.
如果任务多,就会多创建一些线程,如果任务少了就会销毁一些线程.正式员工保底,临时工动态调节.
所以说线程池里的线程数目应该设置成多少合适呢?
答案是:我们要根据程序特点的不同,设置不同的线程数.
要考虑到两个极端情况:
1.CPU密集型,此时线程池线程数应不超过CPU核数,就算有过多的线程数也用不上,此时处于"狼多肉少"的情况.
2.IO密集型,此时每个线程都在等待线程IO,不吃CPU,所以此时理论上将线程池线程数设定为无穷大都可以.
但真实的程序中两种情况都可能参半.所以最好运用实验的方式来选取线程池线程数.
![]()
![]() 这组参数描述了实习工能够摸鱼的最大时间.
这组参数描述了实习工能够摸鱼的最大时间.
![]() 这个是我们线程池的任务队列
这个是我们线程池的任务队列
![]() 这个是线程工厂,用于创建线程.
这个是线程工厂,用于创建线程.
![]() 这个描述了线程池的"拒绝策略",描述了如果线程池满了再继续添加有什么样的行为.
这个描述了线程池的"拒绝策略",描述了如果线程池满了再继续添加有什么样的行为.


如果任务多了,队列满了,就直接抛出异常.

如果队列满了,多出来的任务谁加的谁负责执行.

如果队列满了,丢弃最早的任务

如果队列满了,丢弃最新的任务.
这就是标准库为我们线程池提供的拒绝策略.
简单的线程池代码自我实现:
首先我们要弄清楚要干嘛:
1.阻塞队列保存任务.
2.n个工作线程并发执行
使用方法跟上面的标准库中的一摸一样:
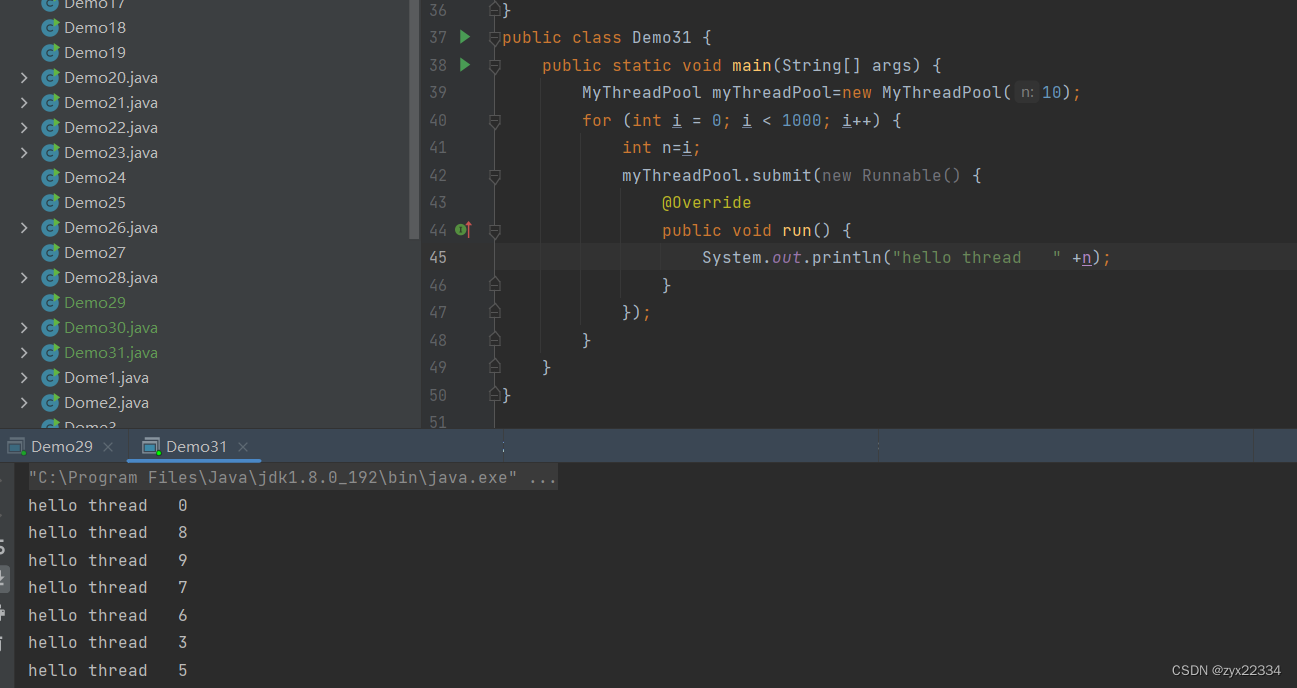
- class MyThreadPool{
- LinkedBlockingQueue<Runnable> queue=new LinkedBlockingQueue<>();
- public MyThreadPool(int n){
- for (int i = 0; i < n; i++) {
- Thread thread=new Thread(() ->{
- while(true) {
- try {
- Runnable runnable=queue.take();
- runnable.run();
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- });
- thread.start();
- }
- }
- public void submit(Runnable runnable){
- try {
- queue.put(runnable);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- }
- }
- public class Demo31 {
- public static void main(String[] args) {
- MyThreadPool myThreadPool=new MyThreadPool(10);
- for (int i = 0; i < 1000; i++) {
- int n=i;
- myThreadPool.submit(new Runnable() {
- @Override
- public void run() {
- System.out.println("hello thread " +n);
- }
- });
- }
- }
- }
七、锁策略
锁策略的目的是要让你设计一个锁,所以并不局限于Java,凡是谈到锁都可以用到锁策略.
1.乐观锁和悲观锁
乐观锁:预测锁竞争不是很激烈.(这里的工作就会相对少一点)
悲观锁:预测锁竞争会很激烈.(这里的工作就会相对多一些)
悲观和乐观唯一的区分主要是看预测锁竞争的激烈程度的结论.
2.轻量级锁和重量级锁
轻量级锁:加锁解除锁开销较小,效率更高.
重量级锁:加锁解除锁开销比较大,效率更低.
3.自旋锁和挂起等待锁
自旋锁是一种轻量级锁.
一但对象被其他锁放开,自旋锁就能第一时间获知,并且第一时间尝试获取,但是缺点也很明显:自旋锁占用了大量的系统资源.
挂起等待锁是一种典型的重量级锁.
挂起等待锁在对象被其他锁放开后,不会第一时间尝试获取,会默默等待,知道剩下的锁获取完了,或者对象尝试主动获取锁.但是优点也很明显:很节省CPU资源.
4.互斥锁和读写锁
互斥锁:就是类似synchronized类似的锁,提供了加锁和解锁两种功能,在加锁之后再尝试获取锁就会阻塞等待.
读写锁:提供了三种操作:针对读操作加锁,针对写操作加锁,解锁.
这个可以自行设置:如多线程并发读的时候可以解锁锁竞争,假设一组操作中有读又有写才会产生锁竞争.
5.公平锁和非公平锁
公平锁:就是按照先先来后到的方式对锁进行一个公平的获取.
非公平锁:就是不讲先来后到,全部锁直接对锁进行获取.
注意:Java中都是非公平锁,它不会关心锁的等待时间.
6.可重入锁和不可重入锁
可重入锁:一个线程一把锁,连续多次加锁都不会发生死锁.(synchronized就是)
不可重入锁:一个线程一把锁,连续加锁两次就会发生死锁.
接下来拿着synchronized对号入座一下,
1.synchronized既是乐观锁也是悲观锁:synchronized默认是乐观锁,一但发现当前环境竞争过于激烈,就会切换为悲观锁.
2.synchronized既是轻量级锁又是重量级锁:synchronized默认是轻量级锁,在竞争激烈的时候就会切换为重量级锁.
3.synchronized的轻量级锁是通过自旋锁实现的,synchronized的重量级锁是通过挂起等待锁实现的.
4.synchronized不是读写锁.
5.synchronized是非公平锁.
6.synchronized是可重入锁.
七、CAS
CAS就是比较和交换.
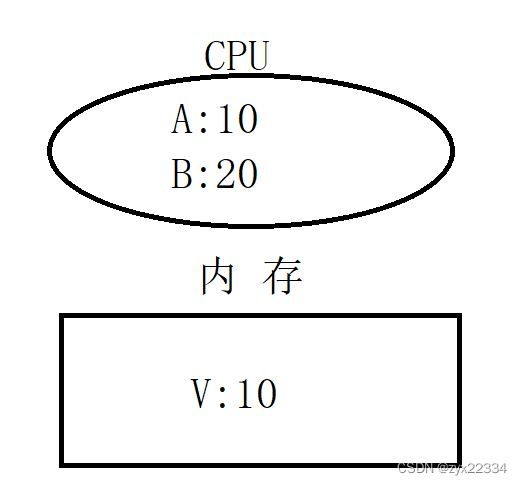
如上图,CAS操作就是首先让A和V进行比较,如果一样就把B和V进行交换,如果不一样就无事发生.
但是这样一个简单的比较和交换操作不是由几行代码完成的,而是由一条CPU指令完成的.这种操作就能完美的避开线程安全问题,因为一条CPU指令是原子的.它比加锁更能保证代码的效率,它避免了锁竞争等问题.
另外,Java基本库中也存在着可以用来CAS的原子类:
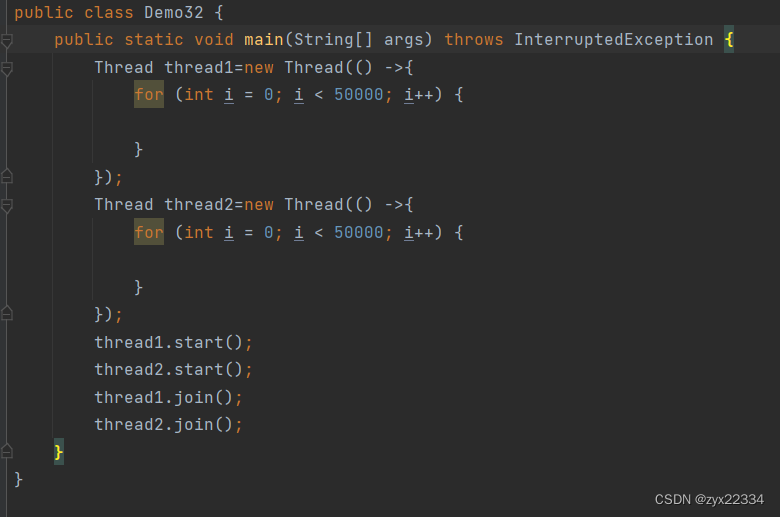
准备两个线程,每个线程自增50000次,如果用int类型或者创建类的方式进行自增需要加锁,否则会出现线程安全问题.
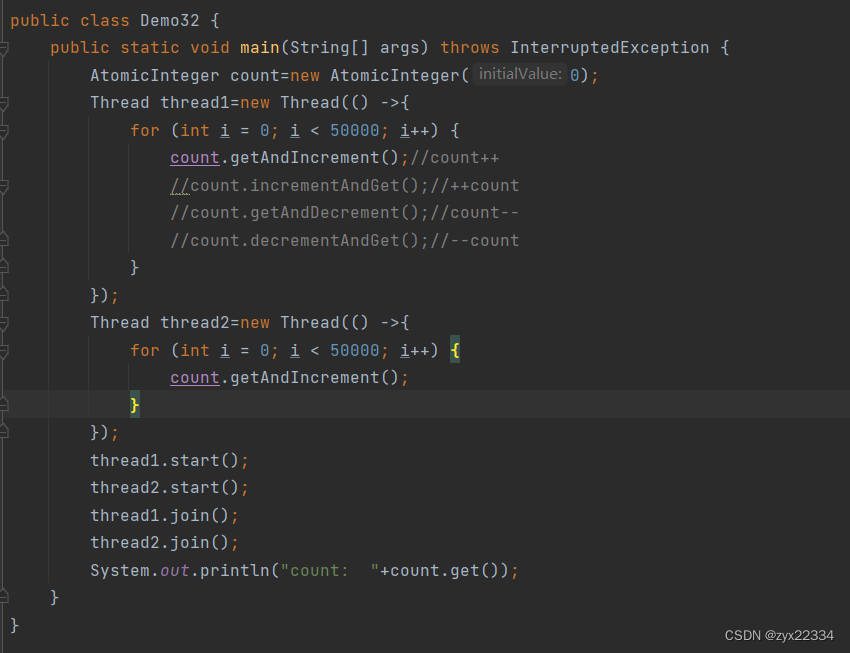
但如果使用原子类:
![]()
使用count调用count++方法
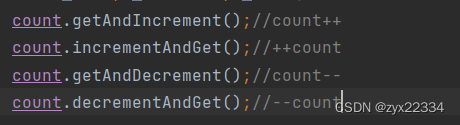
这是原子类常见的几个方法.
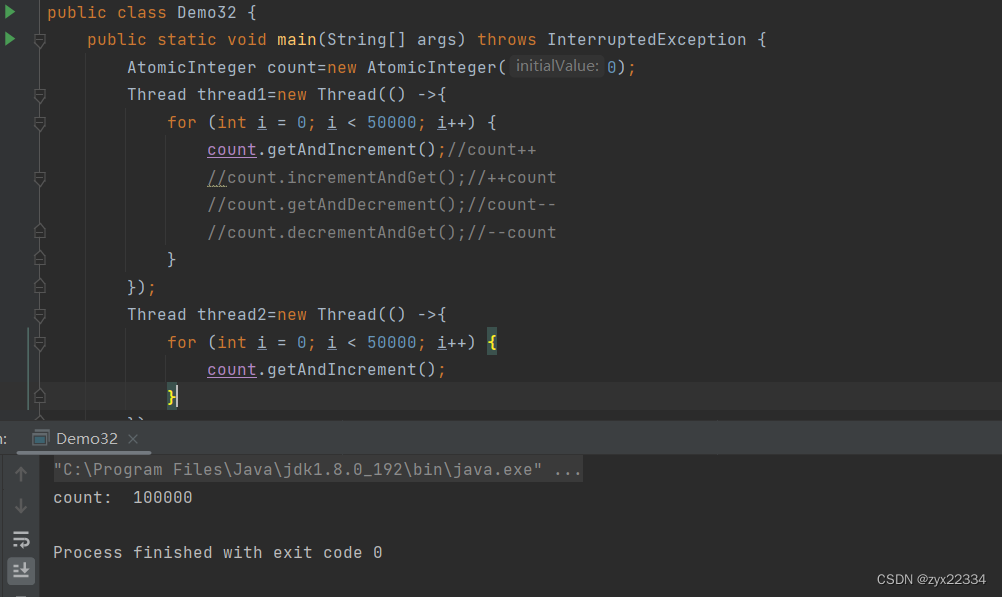
这是发现,程序不会发生线程安全问题:
另外,CAS问题还有一个典型问题:ABA问题
大体上就是,原来内存中存放的是A但后来又被改为了B,之后又还原为了A此时再和CPU中的A进行比较依然相等,也就是人们口中的"翻新""二手货".
解决ABA问题可以用到版本号进行解决.

八、synchronized原理
最后,在synchronized中还有一些优化机制,存在的目的就是使锁的使用更加高效.
1.锁升级/锁膨胀
1)无锁
2)偏向锁
偏向锁就是说,在加锁的过程中,对对象加锁但不完全加锁,就是我们常说的"吊着",先不对对象加锁,当有竞争的锁出现后,再对该对象加锁.被称为偏向锁.
3)轻量级锁
当发生锁竞争的时候,就会从偏向锁,升级成轻量级锁,此时锁是通过自旋锁的形式进行加锁的.
4)重量级锁
当自旋到一定程度的时候,锁就升级成挂起等待锁,变为重量级锁.
暂时,JVM中只有锁升级,没有锁降级.
2.消除锁
编译器的只能判断,判断当前代码是否真的需要加锁.
3.锁粗化
synchronized包含的代码越多,粒度越粗,synchronized包含的代码越少,粒度越细.
当然,粒度越细越好,因为在synchronized包含中的代码是无法并发执行的,所以说粒度越细,并发执行的代码越多,效率越高.
但是有的时候,粒度越好,当锁与锁之间的间隙过小的时候,还不如把它整成一把锁.
九、callable接口
callable接口是一种类似Thread的多线程方式,其擅长进行数据的计算的等操作(主要是不需要加锁).
1.callable的使用方法
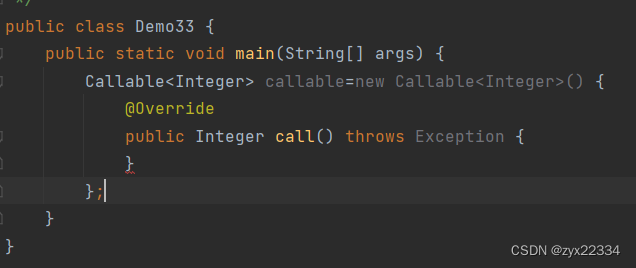
使用方法是通过匿名内部类的方法,重写call方法(类似run方法),但是其返回值是泛型类型,而run的返回值是void.
该方法建立线程依然需要使用Thread及逆行调用,但是不能将得到的callable直接传入Thread的构造方法中.
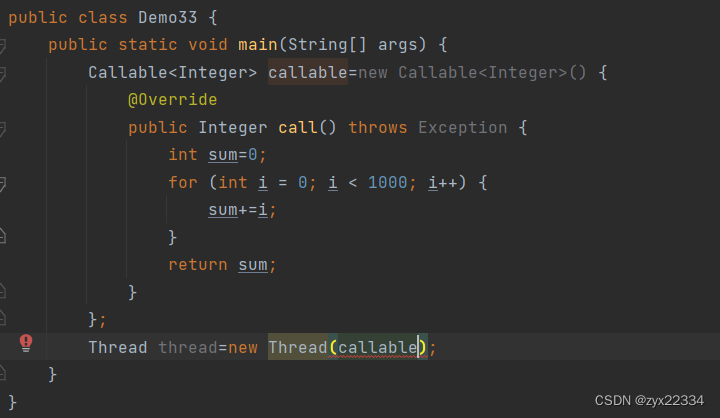
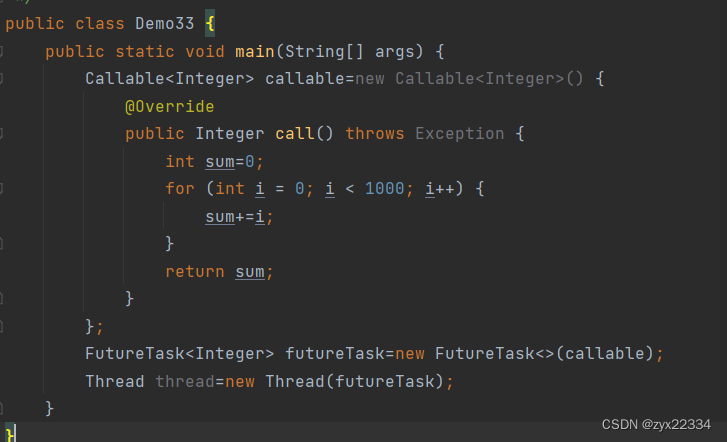
需要使用FutureTask(未来的任务)类进行任务的封装.
接下来使用futuretask.get()进行获取计算的返回值.
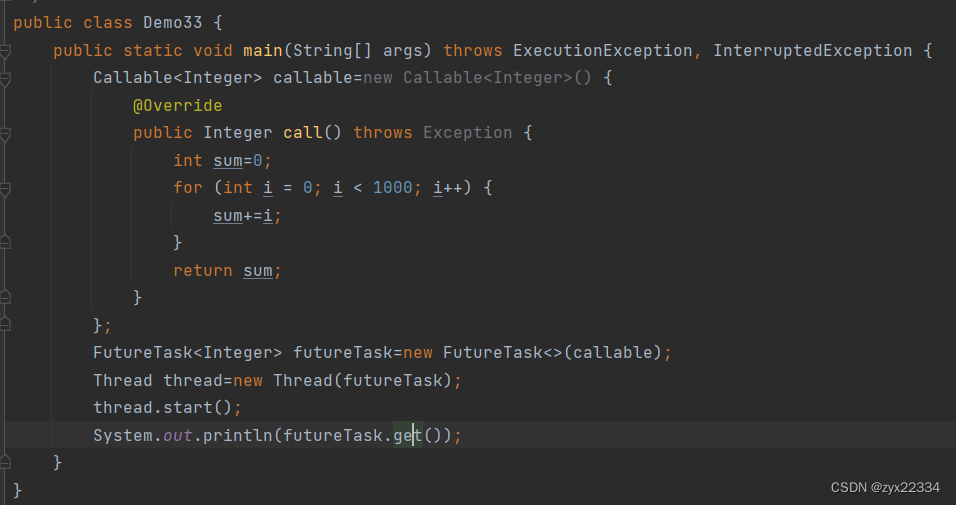
就可以正常运行了:
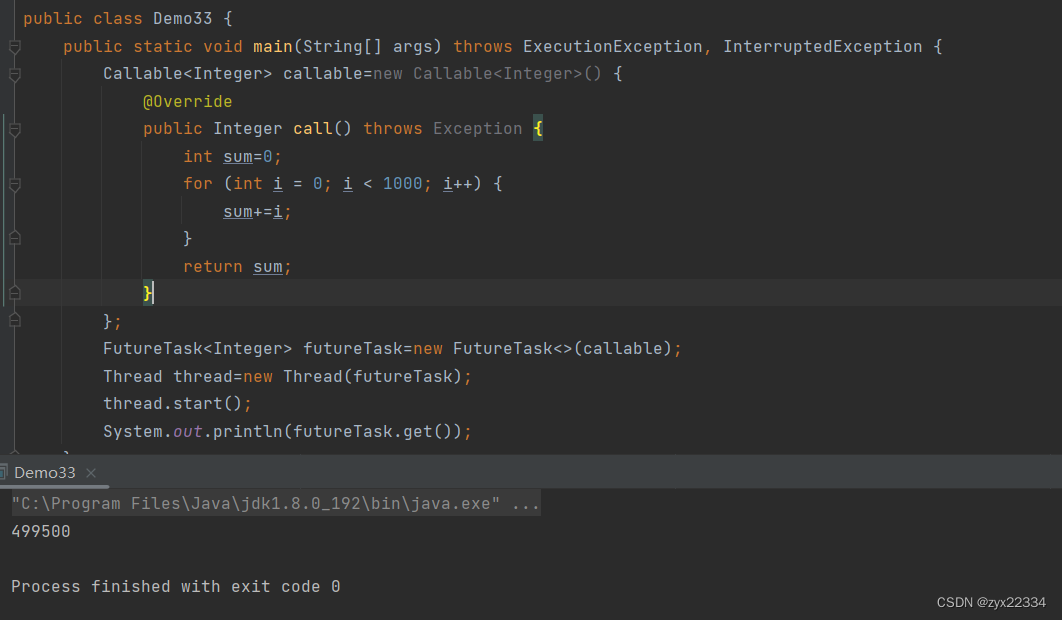
2.ReentrantLock
ReentrantLock,翻译为可重入锁,是Java标准库中给我们提供的另外一种可重入锁.
synchronized是直接基于代码块的方式来进行加锁的,
而ReentrantLock更加传统,使用了lock()和unlock()的形式进行加锁和解锁.
另外,肯定还是 synchronized的代码加锁方式更加好,因为
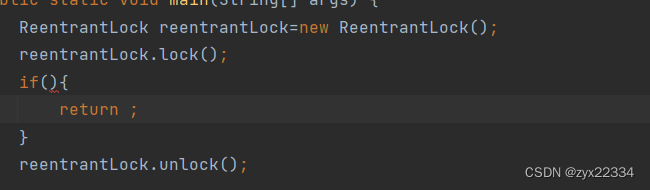
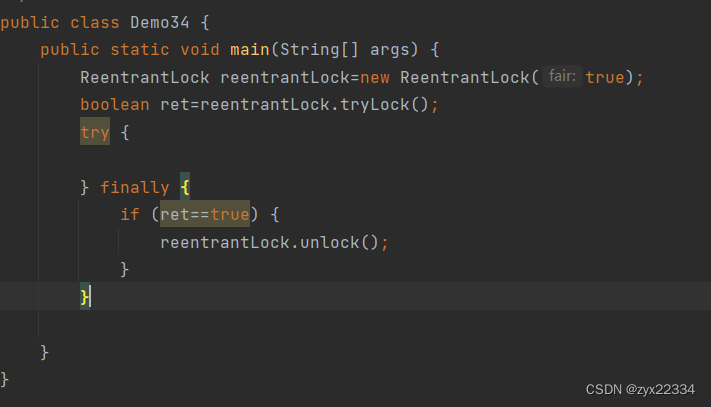
如果遇到这种情况(在日常生活的代码中很常见),上锁的变量在满足条件后就直接返回了,不会进行解锁,这样这个程序就会一直带着锁进行下去.
另外,有一种能够快速解决此问题的方法,就是使用try/catch将所有的if包裹起来
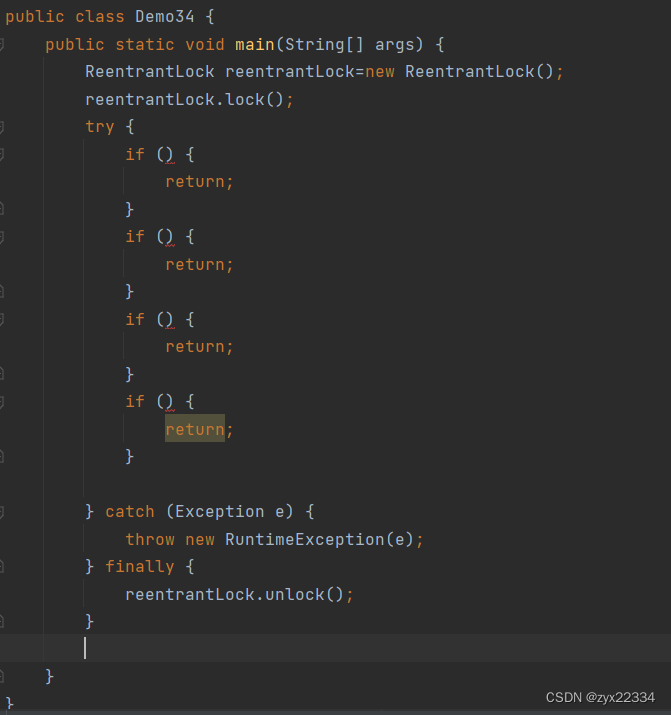
然后最后使用finally包裹reentrantLock.unlock(),使所用if从句return后直接解锁,就可以解决此问题.
1)以上是reentrantLock的缺点,但它还是有优点的:比如它可以实现公平锁
![]()
在构造方法中加一个true将锁设置为公平锁.
2)另外,synchronized在获取不到锁的时候,只能死等(阻塞等待),但是reentrantLock则不同,它提供了一个tryLock()的方法
![]()
tryLock()就是让线程尝试取获取锁,能获取到就获取,如果不能就放弃.
tryLock()有两个版本,有数版本设置了最大等待时间.
另外,tryLock()有个返回值,返回的是加锁的成功或者失败.
3)reentrantLock提供了一个更加强大的通知机制
十、信号量Semaphore
信号量本质上是一个计数器,描述了可用资源的个数.
是操作系统内核封装的一个小工具:(主要分为两个操作)
1.P操作:申请一个可用资源,计数器就要-1.
2.V操作释放一个可用资源,计数器就要+1.
如果计数器为0,在进行P操作就会阻塞等待.
Semaphore的需求场景:图书馆,停车场.......
使用方法:
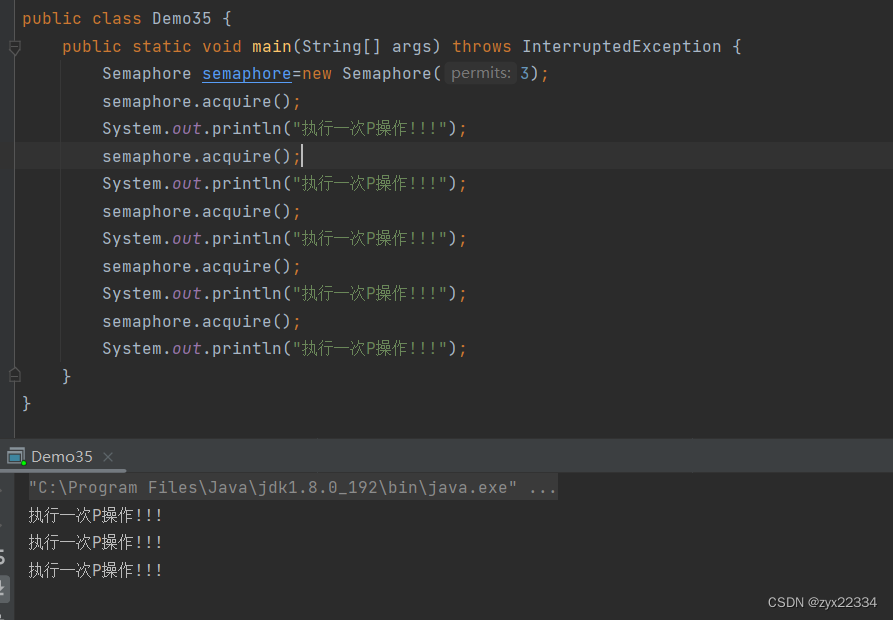
此时我们看到,semaphore的计数器中存放的是3,执行了三次P操作后,再执行第4次P操作,程序就会阻塞等待.
P操作acquire.(-1)
V操作:release.(+1)
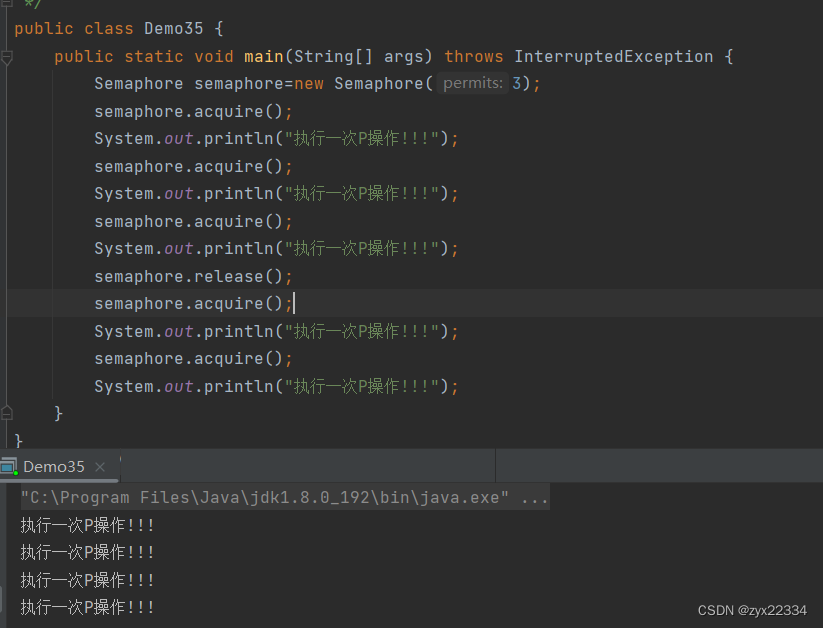
另外,acquire和release还可以自定义数量:
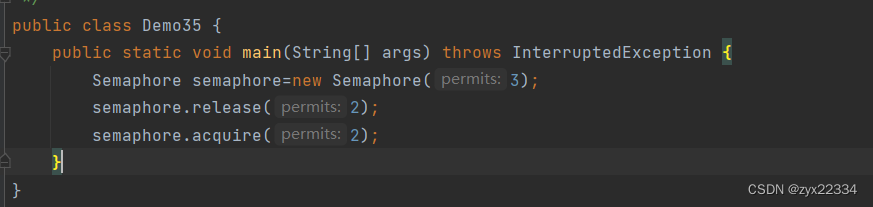
semaphore有的时候可以实现类似于锁的作用.
十一、CountDownLatch
类似一个计数器的小工具,只能用于特定场景.
主要方法:
在CountDownLatch创建的时候,在构造方法中,指定一个选手的数,主线程中调用await()方法使线程阻塞,其他线程反复调用countDown方法,直到到达在构造方法中创建的数量,就会解除阻塞,程序结束.
应用场景:
多线程下载大数据文件(将文件拆分成多部分进行下载).
十二、多线程环境使用ArraryList
我们要知道,大多数的数据结构都是线程不安全的,但是为了考虑效率问题,数据结构中一般都不会内置锁,所以需要程序员手动添加锁.这里我们拿ArraryList进行举例.
解决ArraryList的线程安全问题有以下几个方法:
1.自己加锁,手动添加reentrantLock或者synchronized
2.Collections.synchronizedList,这里会提供一些ArraryList相关的方法,同时这些方法是带锁的.
3.CopyOnWriteArraryList(简称COW也称"写实拷贝")就是说如果进行读操作,不会进行任何修改,假如进行写操作则会拷贝一份新的ArraryList进行修改,修改过程中如果有读操作,则会阅读旧的文件,如果写操作进行完毕,则会用新创建的ArraryList替换旧的文件.(本质上是一个引用之间的赋值,是原子的)
这种方法优点是不用加锁,缺点是拷贝的ArraryList不能够太大.
应用场景:服务器的配置文件的维护(my.ini)
如果要直接修改配置文件,则需要重新启动配置文件,但是大多数时候都无法重新启动配置文件(损失过大),所以说很多的服务器都提供了"热加载"的功能,用的就是写实拷贝的思路.
十三、多线程使用HashMap
我们已知,HashMap是线程不安全的,HashTable是线程安全的.给了关键方法,加了synchronized.
但是这里我们推荐在多线程的环境中使用ConcerrentHashMap.
ConcerrentHashMap比HashTable好在哪里?
1.最大的优化之处是:ConcerrentHashMap相比于HashTable大大缩小了锁冲突的概率,把一把大锁,转换成了好多把小锁.
HashTable的做法是直接在方法上添加synchronized,等于是直接给this加锁,只要操作哈希表中的元素,都会产生锁冲突,但实际上,很多元素都没有线程安全问题.
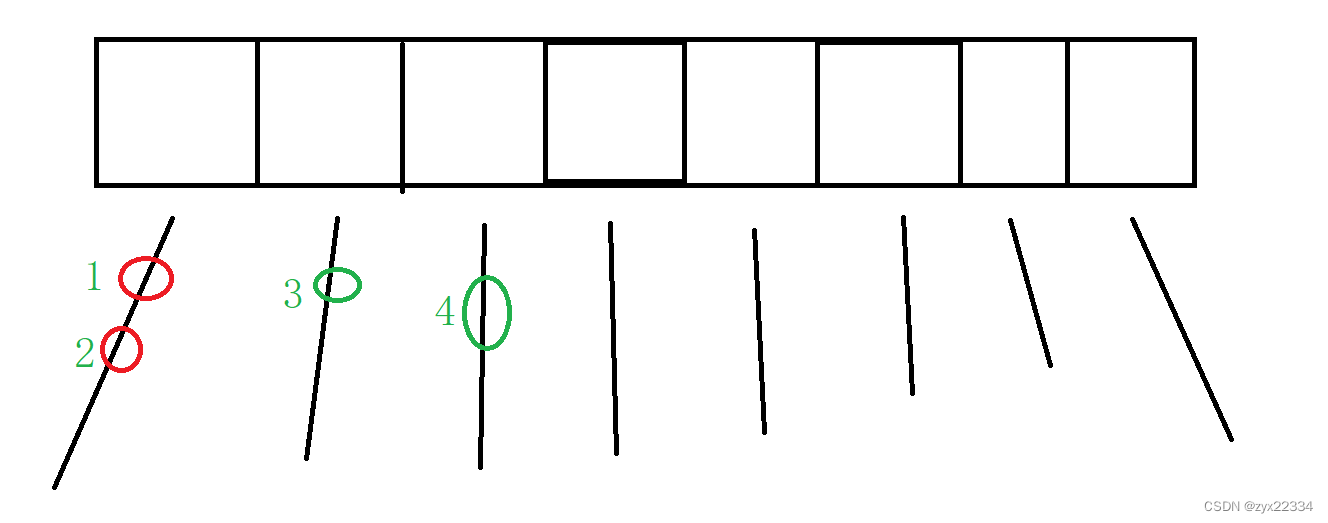
假设上图是一个哈希表, HashTable的做法是直接在方法上加锁,但是我们来看,同一个链表上的1和2会发生线程安全问题加锁无可厚非,但是不同链表的3和4不会发生线程安全问题,加锁就会影响效率.
而ConcerrentHashMap的做法是,把锁加在每个链表上面,增加了效率.
上述是Java1.8之后的情况,1.8之前是分段锁.
2. ConcerrentHashMap针对读操作不加锁,只对写操作加锁,很多情况下如果写操作不是原子的就会出现"脏读"的情况.(需要使用volatile)
3.ConcerrentHashMap内部充分使用了CAS操作
4.ConcerrentHashMap针对扩容,采取了"化整为零"的方式.
HashMap/HashTable的扩容:
创建一个更大的数组,把旧的数组的每个元素直接copy到新的数组(删除+插入)会在put时触发,如果元素过多,put操作则会很好事耗时,如某次put比之前的put要卡好多.
而ConcerrentHashMap的扩容:
是采取每次只搬运一小部分的方式进行扩容,创建新的数组,也保留旧的数组.当所有元素全都拷贝完成后才释放数组,这样put操作不会出现卡顿现象.
解释一下同步/异步:
同步:发送请求方主动等待响应的结果
异步:发送请求方发送完就去干别的了,等结果有了后对方主动把结果推送过来.
小知识:
1.ctrl+alt+T是surround With功能能供使选中语句包裹常见语句.
2.shift+F6是快速更改全局名字的快捷键.

