
热门标签
热门文章
- 1文本三剑客——sed 修改、替换_sed替换
- 2ip地址查询代码_如何同时Ping1000个IP地址?下面的方法,让工作效率提高百倍!...
- 3基于Python爬虫江西南昌天气预报数据可视化系统设计与实现(Django框架) 研究背景与意义、国内外研究现状
- 4Kotlin协程巩固,kotlin框架_kotlin 协程 避免回调
- 5第八篇 交叉编译华为云Iot SDK到Orangepi3B_华为嵌入式交叉编译
- 6前端传数组,后端怎么接收的问题_前端传数组 后端用什么接收
- 7基于Java的坦克大战游戏的设计与实现毕业设计
- 8面试被问:说说分布式事务的两阶段提交与三阶段提交
- 9ssm,springboot代码生成器——添加vue.js支持,mac系统支持_sscms 可以使用vue
- 10Windows注入与拦截(1) -- DLL注入的基本原理_windows反程序注入
当前位置: article > 正文
Android面试题--HashMap原理分析_android hashmap原理
作者:你好赵伟 | 2024-03-11 11:34:01
赞
踩
android hashmap原理
一、序言
作为Android程序员,出去找工作面试,HashMap应该是最常被问到的一种数据类型。那它是怎么实现的呐?我们都知道,数据结构中有数组和链表来实现对数据的存储,这两者是两个极端。数组存储区间是连续的,占用内存严重,但查询效率高;而链表存储区间是离散的,占用内存较小,但时间复杂度高,查询复杂。有没有结合两者特性,既寻址容易、也插入删除简单的数据结构呢?答案是肯定的,哈希表(Hash table)就是其中之一。哈希表最常用的一种实现方式是——拉链法,可以把它看作“链表的数组”。
二 、HashMap原理分析
Hashmap存储数据的容器也是一个线性数组,它具有一个静态内部类Node,数据结构如下:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; //对Key计算的hash值
final K key; //Key
V value; //value
Node<K,V> next; //链表指向的下一个Node
}
- 1
- 2
- 3
- 4
- 5
- 6
存储时:
int index = (length - 1) & hash(key); // hash值与Node长度取模,得到数组下标
Node[index] = value;
- 1
- 2
取值时:
int index = (length - 1) & hash(key); // hash值与Node长度取模,得到数组下标
return Node[index];
- 1
- 2
其中的hash方法在java8中实现如下:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
- 1
- 2
- 3
- 4
这个“扰动”函数的价值是:将hash值右移16位(刚好32bit的一半),然后让自身的上半区与下半区做“亦或”操作,为的是加大低位的随机性,再与Node长度取模,做为下标,可以有效减少碰撞次数。

那么,两个key的hash值取模得到相同的index,会不会把前一个node覆盖呢?
这里就用到了hashmap的链式结构了,Node里面有一个next属性,指向下一个Node。例如,进来一个键值对A,对keyhash取模得到index=0,则Node[0]=A,有进来一个键值对B,得到对index也为0,hashmap这样处理,B.next=A,Node[0]=B,这时又进来一个C,同样index=0,则C.next=B,Node[0]=C。我们发现 数组中总是存放最新的一个Node元素
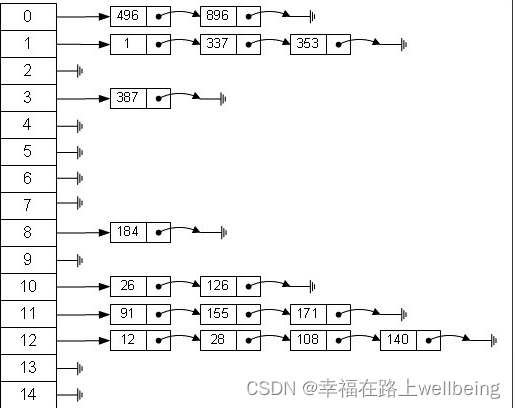
HashMap是如何根据Key取出value的呢? 我们看一段代码
public V get(Object key) { int hash = hash(key.hashCode()); //先定位到数组元素,再遍历该元素处的链表 Node<K,V>[] tab; Node<K,V> first, e; int n; K k; if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { if (first.hash == hash && ((k = first.key) == key || (key != null && key.equals(k)))) return first; if ((e = first.next) != null) { do { if (e.hash == hash &&((k = e. key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } return null; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
二、HashMap和Hashtable区别?
1.HashMap支持null Key和null Value;Hashtable不允许。这是因为HashMap对null进行了特殊处理,将null的hashCode
值定为了0,从而将其存放在哈希表的第0个bucket。
2.HashMap是非线程安全,HashMap实现线程安全方法为Map map = Collections.synchronziedMap(new HashMap());
Hashtable是线程安全
3.HashMap默认长度是16,扩容是原先的2倍;Hashtable默认长度是11,扩容是原先的2n+1
4.HashMap继承AbstractMap;Hashtable继承了Dictionary
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/218778
推荐阅读

相关标签

