
- 1Android发送标准广播无效问题_隐式广播发不出去
- 280端口攻击_内网端口转发工具的使用总结
- 3html播放rtp,GitHub - AOMediaCodec/av1-rtp-spec: Current draft (HTML): https://aomediacodec.github.io/a...
- 4ubuntu下使用systemd/service进行服务管理_unbantu system service
- 5突发!鸿蒙系统即将全面替代安卓?_鸿蒙next
- 6链式二叉树的创建
- 7数据库隔离级别------串行化,可重复读,读提交,读未提交
- 8微信小程序、百度小程序、支付宝小程序:发展历程与未来趋势_支付宝小程序,百度小程序
- 9Unable to create converter for class`_java.lang.illegalargumentexception: unable to crea
- 10【网站项目】基于ssm摄影约拍系统
web自动化 -- selenium及应用
赞
踩
selenium简介
随着互联网的发展,前端技术不断变化,数据加载方式也不再是通过服务端渲染。现在许多网站使用接口或JSON数据通过JavaScript进行渲染。因此,使用requests来爬取内容已经不再适用,因为它只能获取服务器端网页的源码,而不是浏览器渲染后的页面内容。
大多数情况下,数据是通过Ajax接口获取的。
----------->>>>
为了解决这个问题,我们可以使用Puppeteer、Pyppeteer、Selenium和Splash等自动化框架来获取HTML源码。这样,我们爬取到的源代码就是经过JavaScript渲染后的真正网页代码,数据提取也变得容易。这种方式绕过了分析Ajax和JavaScript逻辑的过程,实现了可见即可爬,难度较小,适合大规模采集。
----------->>>>
然而,Selenium作为一款知名的Web自动化测试框架,虽然支持大部分主流浏览器并提供了丰富的API接口,但也存在一些缺点。例如,速度较慢、对版本配置要求严格,并且经常需要更新对应的驱动。
----------->>>>
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器。
数据采集领域经常被我们借用过来作为爬虫工具使用。
官网:https://www.selenium.dev/
=====================================================================
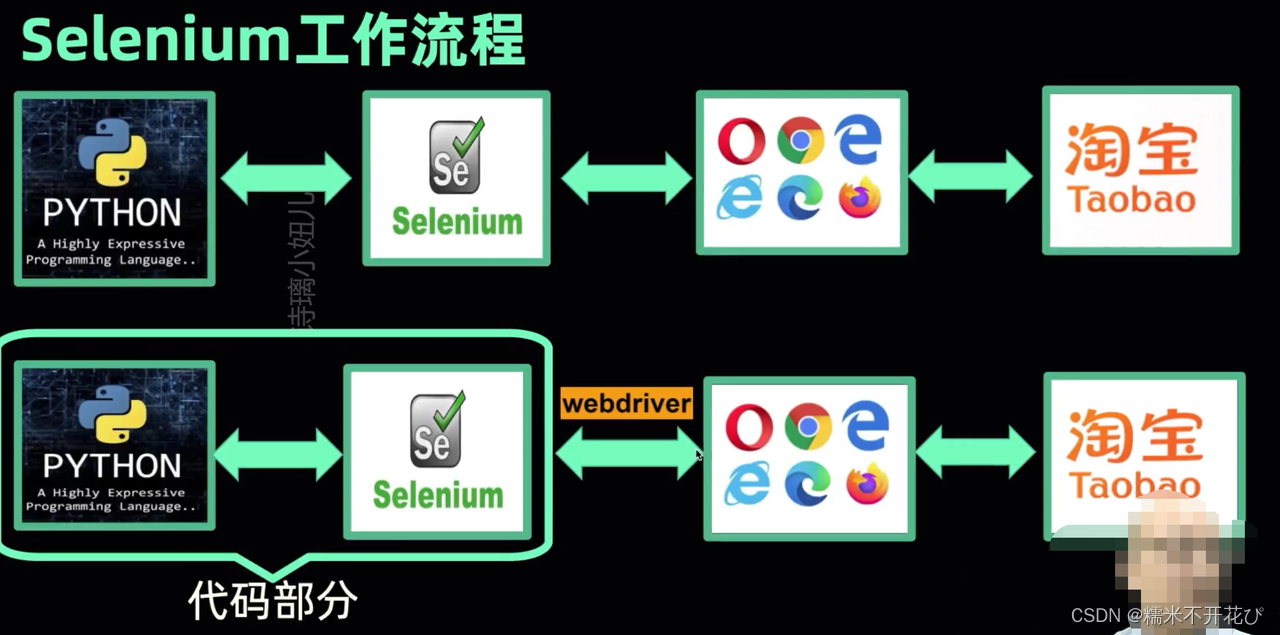
Selenium工作流程:
① 我们利用python脚本控制selenium驱动器(驱动器就是一段代码)
② selenium驱动器操作浏览器(具体哪个浏览器需要指定)
③ 浏览器访问网址后打开网页
④ python脚本通过selenium驱动器从浏览器中提取结果
selenium环境搭建
selenium的两种安装方式
命令安装:pip install selenium -i https://mirrors.aliyun.com/pypi/simple/
Pycharm安装:Pycharm-File-Setting-Project:xxxx-Python Interpreter,点击+号
webdriver下载及配置
安装指定版本的webdriver
● 查看对应浏览器和版本(通常是chrome或firefox)
● 国内镜像网站:国内镜像网站里可能版本比较少
https://npm.taobao.org/mirrors(淘宝的镜像网站)
https://sites.google.com/chromium.org/driver/(华为镜像)
Chrome for Testing availability(官方驱动下载网址)
● 解压后放入指定文件夹即可
ps:为了防止浏览器自动更新后,webdriver版本不匹配而造成无法正常使用,建议可以关闭浏览器的自动更新功能,具体关闭的操作可以自行百度。
=====================================================================
具体步骤如下:
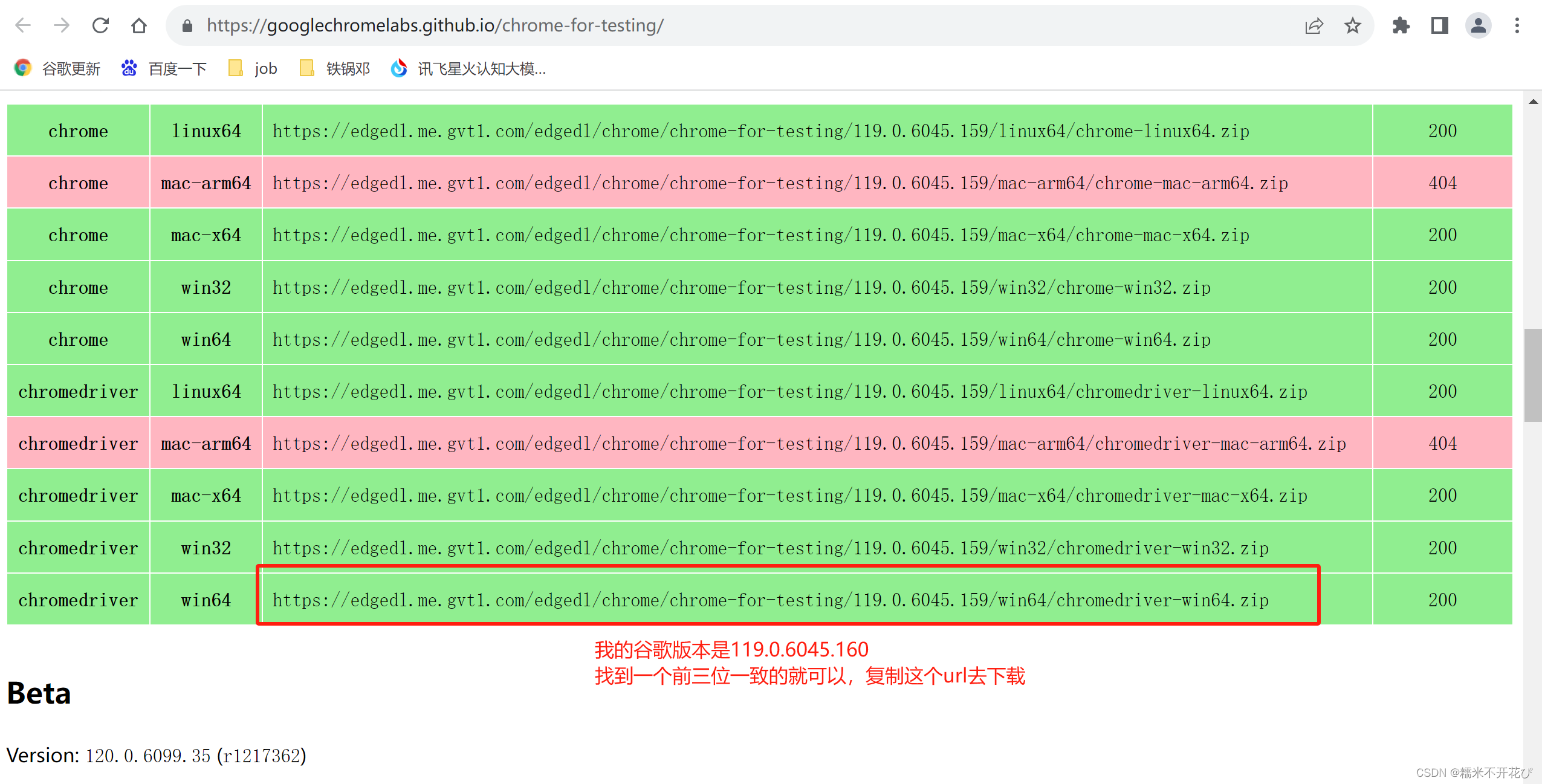
❶ 查看浏览器版本:

❷ 下载对应的浏览器驱动版本:
进入淘宝镜像网站,找到chromedriver;

由于我的浏览器版本在国内镜像中找不到相近的,所以重新进入一个能打开的官方网址进行下载:https://googlechromelabs.github.io/chrome-for-testing/
我的版本超过114版本,点击下图位置 (点击:the Chrome for Testing availability dashboard.)

尽量保证驱动版本和浏览器版本一致,前三位保持一致一般就可以正常使用
复制url去下载webdriver
❸ 安装selenium:
直接在pycharam中安装;或者使用pip命令安装都可以

❹ 环境配置:
先解压下载的chromedriver,解压后将它放在本地python安装Scripts 目录下即可
不清楚自己python安装在哪里的,可以使用以下命令进行查看:

将解压的chromedriver.exe放到python 的 Scripts 目录下

❺ 安装验证:
- from selenium import webdriver
-
- def run_webdriver():
- driver = webdriver.Chrome() #创建一个Chrome浏览器的WebDriver实例
- driver.maximize_window() #浏览器窗口最大化
- driver.get('https://baidu.com/') #发起访问请求
-
- if __name__ == '__main__':
- run_webdriver()
运行上面代码之后,已经正常打开了百度,说明安装和配置都搞定了!~

selenium实操运用
常用的selenium相关包
- #常用的selenium包:
- from selenium import webdriver #webdr驱动iver
- from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR等等
- from selenium.webdriver.common.keys import Keys #键盘按键操作
- from selenium.webdriver import ActionChains #拖拽动作
- from selenium.webdriver.support import expected_conditions as EC #等到特定条件发送
- from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素
- from selenium.webdriver.chrome.options import Options #设置浏览器启动参数
⑴ 元素定位
元素定位的八大法如下:
| 方法 | 说明 | 使用示例 |
| id | 通过元素的id属性进行定位; id是每个元素的唯一标识符,类似我们的身份证号码 | driver.find_element (By.ID, "value") |
| name | 通过元素的name属性进行定位 一个元素可能有多个name属性 | driver.find_element(By.NAME,"value") |
| class_name | 通过元素的class属性进行定位 一个元素可能有多个class属性 | driver.find_element (By.CLASS_NAME,"value") |
| tag_name | 通过元素的标签名进行定位 一个HTML文档中可能有多个相同标签名的元素 | driver.find_element (By.TAG_NAME,"input") |
| link_text | 用于超链接的定位 通过链接的显示文本来查找链接元素 | driver.find_element (By.LINK_TEXT,"value") |
| partial_link_text | 用于部分链接文本的定位 可以通过链接的部分文本来查找链接元素 | driver.find_element(By.PARTIAL_LINK_TEXT, "value") |
| xpath | 是一种非常强大的定位方式 可以根据元素的层级关系和属性来定位元素 | driver.find_element(By.XPATH,"//div[@id='content']/p") |
| css | 同样是一种非常强大的定位方式 可以根据元素的类名、标签名、id等属性来定位元素 | driver.find_element (By.CSS_SELECTOR,"#content > p") |
几个简单的方法查找示例:
- from selenium import webdriver
- from selenium.webdriver.common.by import By #导入By类
-
- def run_webdriver():
- driver = webdriver.Chrome() #创建一个Chrome浏览器的WebDriver实例
- driver.maximize_window() #浏览器窗口最大化
- driver.get('https://jd.com/') #发起访问请求
-
- #定位查找"key"这个ID
- search = chrome.find_element(By.ID,"key")
- #定位查找属性值为"button cw-icon"的calss
- button_class = chrome.find_element(By.CLASS_NAME,"button cw-icon")
-
- #查找定位属性值为"button cw-icon"的button按钮,xpath定位
- button_xpath = chrome.find_element(By.XPATH,'//button[@class="button cw-icon"]')
-
- chrome.quit() #关闭浏览器
-
-
- if __name__ == '__main__':
- run_webdriver()

⑵ 元素操作(节点交互)
Selenium可以驱动浏览器来执行一些操作,也就是说可以让浏览器模拟执行一些动作。
比较常见的用法有:
● send_keys():输入文字
● clear():清空文字
● click():点击按钮
find_element:只返回第一个找到的元素
find_elements:查找页面上所有满足定位条件的元素,打包在一个列表中返回
接下来就可以对元素执行以下操作,从定位到的元素中提取数据的方法:
定位元素并获取数据
● el.get_attribute(key): 获取key属性名对应的属性值
● el.text:获取开闭标签之间的文本内容
以下是一个代码示例:获取京东首页的6张轮播图的链接:
- from selenium import webdriver
- from selenium.webdriver.common.by import By #导入By类
-
- def run_webdriver():
- driver = webdriver.Chrome() #创建一个Chrome浏览器的WebDriver实例
- driver.maximize_window() #浏览器窗口最大化
- driver.get('https://jd.com/') #发起访问请求
-
- #查找京东首页的轮播图链接,共6个
- imgs = driver.find_elements(By.CLASS_NAME,'focus-item-img')
- for img_el in imgs:
- print(img_el.get_attribute("src"))
-
-
- driver.quit() #关闭浏览器
-
- if __name__ == '__main__':
- run_webdriver()
代码之后,自动打开京东首页,找到对应的元素后自动关闭浏览器,并在控制台输出链接:

定位元素并进一步操作
● el.click() : 对元素执行点击操作
● el.submit() :对元素执行提交操作
● el.clear() :清空可输入元素中的数据
● el.send_keys(data) :向可输入元素输入数据部分用法示例如下:
- import time
- from selenium import webdriver
- from selenium.webdriver.common.keys import Keys
- from selenium.webdriver.common.by import By #导入By类
-
- def run_webdriver():
- driver = webdriver.Chrome() #创建一个Chrome浏览器的WebDriver实例
- driver.maximize_window() #浏览器窗口最大化
- driver.get('https://jd.com/') #发起访问请求
-
- #查找京东首页的标签元素:
- search = driver.find_element(By.ID,"key")
- search.send_keys("apple watch") #在搜索框中输入"apple watch"
- search.send_keys(Keys.ENTER) #输入内容后,模拟点击回车键进行搜索
-
- #方式2:输入内容后,直接点击搜索按钮
- # button = driver.find_element(By.CLASS_NAME,"button")
- # button.click()
- time.sleep(5)
- driver.quit()
-
-
- if __name__ == '__main__':
- run_webdriver()
⑶ 动作链
在上面的实例中,一些交互动作都是针对某个节点执行的。
比如:
对于输入框,我们就调用它的输入文字和清空文字方法;
对于按钮,就调用它的点击方法。
其实,还有另外一些操作,它们没有特定的执行对象,比如鼠标拖曳、键盘按键等,这些动作用另一种方式来执行,那就是动作链。
------------>>>>>>
比如,现在实现一个节点的拖曳操作,将某个节点从一处拖曳到另外一处,可以这样实现:
例如:
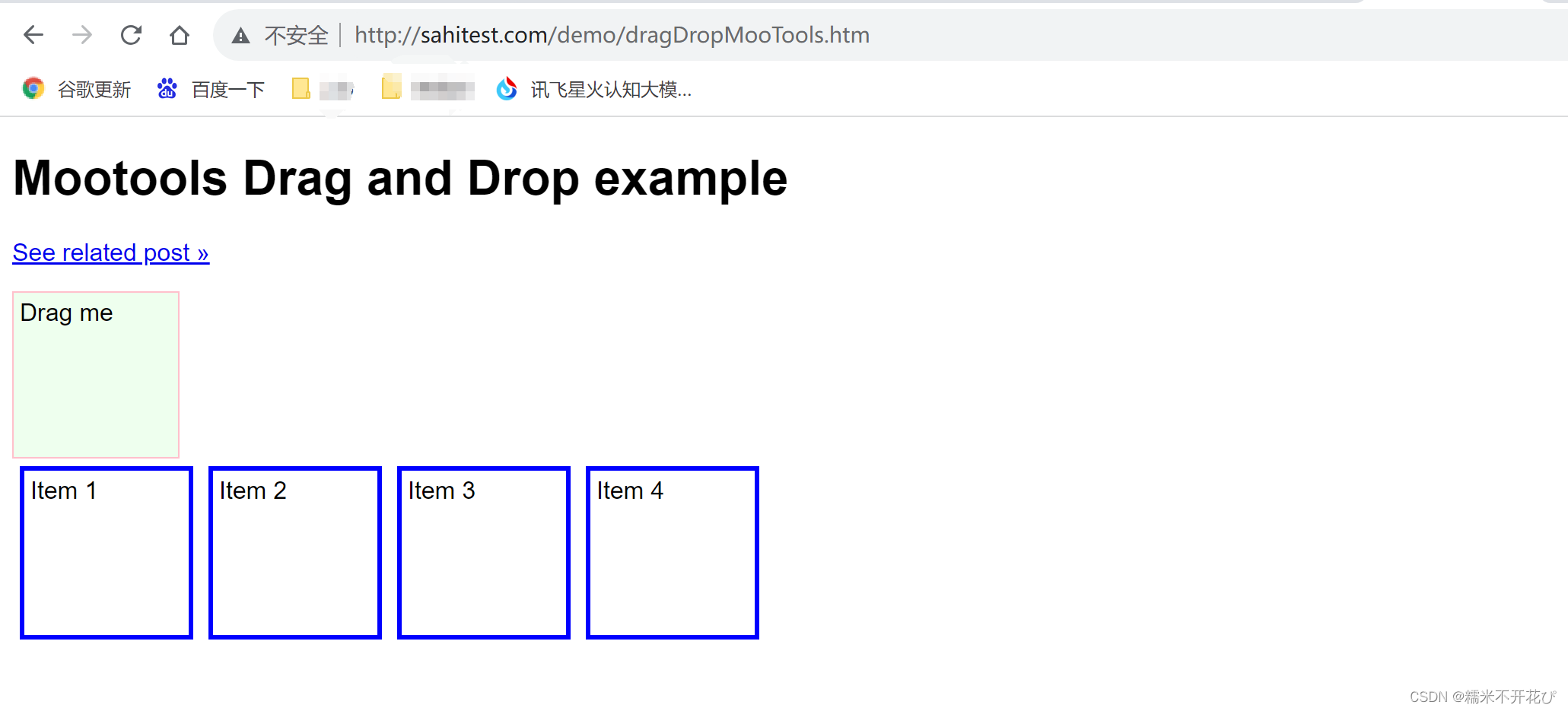
Mootools Drag and Drop Example
针对这个网站的元素进行拖拽(该网站打开如下显示):
代码示例:
- from time import sleep
- from selenium import webdriver
- from selenium.webdriver.common.by import By #导入By类
- from selenium.webdriver import ActionChains #拖拽动作
- def run_webdriver():
- driver = webdriver.Chrome() #创建一个Chrome浏览器的WebDriver实例
- driver.maximize_window() #浏览器窗口最大化
- driver.get('http://sahitest.com/demo/dragDropMooTools.htm') #发起访问请求
-
- #定位所有目标元素:
- dragger = driver.find_element(By.ID, 'dragger') # 被拖拽元素
- item1 = driver.find_element(By.XPATH, '//div[text()="Item 1"]') # 目标元素1
- item2 = driver.find_element(By.XPATH, '//div[text()="Item 2"]') # 目标2
- item3 = driver.find_element(By.XPATH, '//div[text()="Item 3"]') # 目标3
- item4 = driver.find_element(By.XPATH, '//div[text()="Item 4"]') # 目标4
-
- # 进行拖拽动作链:
- action = ActionChains(driver)
- #括号的参数:源是dragger,拖动后要放的位置是item1,通过.perform()来执行
- action.drag_and_drop(dragger, item1).perform() #1.移动dragger到目标1
- sleep(2)
-
- #这句是上面的源码,上面是简写方式
- action.click_and_hold(dragger).release(item2).perform() #2.效果与上句相同,也能起到移动效果
- sleep(2)
-
- #将dragger移动到item3的元素上
- action.click_and_hold(dragger).move_to_element(item3).release().perform() # 3.效果与上两句相同,也能起到移动的效果
- sleep(2)
- action.click_and_hold(dragger).move_by_offset(800, 0).release().perform()
- sleep(2)
-
- driver.quit()
-
- if __name__ == '__main__':
- run_webdriver()
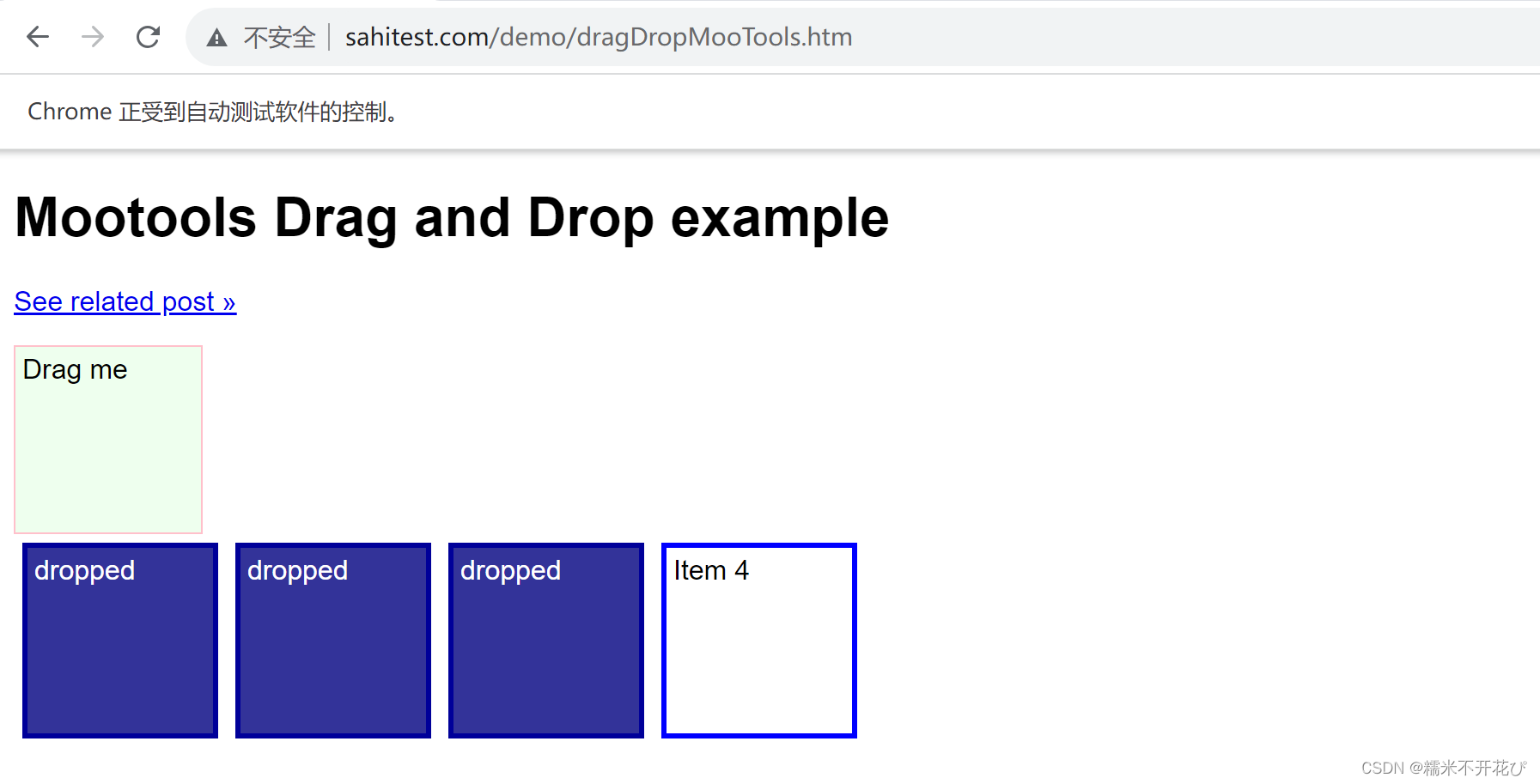
代码执行后,页面的效果:
⑷ 执行JS代码
selenium并不是万能的,有时候页面上操作无法实现的,这时候就需要借助JS来完成了。
当页面上的元素超过一屏后,想操作屏幕下方的元素,是不能直接定位到,会报元素不可见。这时候需要借助滚动条来拖动屏幕,使被操作的元素显示在当前的屏幕上。
滚动条是无法直接用定位工具来定位的。
selenium里面也没有直接的方法去控制滚动条,这时候只能借助Js代码了,还好selenium提供了一个操作js的方法:execute_script(),可以直接执行js的脚本。
示例如下:
比如京东首页的滚动条:
js代码:window.scrollTo(0, document.body.scrollHeight)
window:当前窗口
scroll:滚动条
To(从0的位置,document.body.scrollHeight:整个滚动条从上到下的总长)

通过f12-控制台执行js代码:
通过python执行js代码:
- from time import sleep
- from selenium import webdriver
- def run_webdriver():
- driver = webdriver.Chrome() #创建一个Chrome浏览器的WebDriver实例
- driver.maximize_window() #浏览器窗口最大化
- driver.get('https://www.jd.com/') #发起访问请求
-
- #执行拖动滚动条到底
- driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
-
- sleep(5)
-
- driver.quit()
-
- if __name__ == '__main__':
- run_webdriver()
⑸ 页面等待
为什么需要等待?
如果网站采用了动态html技术,那么页面上的部分元素出现时间便不能确定,这个时候就可以设置一个等待时间,强制等待指定时间,等待结束之后进行元素定位,如果还是无法定位到则报错 。
强制等待
强制等待也叫线程等待, 通过线程休眠的方式完成的等待,如等待5秒: Thread sleep(5000),一般情况下不太使用强制等待,主要应用的场景在于不同系统交互的地方。
import time
time.sleep(n) # 阻塞等待设定的秒数之后再继续往下执行--------------->>>
强制等待的缺点:不灵活
比如sleep(3),可能网比较卡,3秒过去了依然没有加载出来元素
比如sleep(5),可能网比较通畅,可能1秒就已经加载出来了,还得白白多卡4秒。。。
显式等待
显示等待也称为智能等待,针对指定元素定位指定等待时间,在指定时间范围内进行元素查找,找到元素则直接返回,如果在超时还没有找到元素,则抛出异常,显示等待是 selenium 当中比较灵活的一种等待方式,他的实现原理其实是通过 while 循环不停的尝试需要进行的操作。
代码示例:
- from telnetlib import EC
- from time import sleep
- from selenium import webdriver
- from selenium.webdriver.common.keys import Keys
- from selenium.webdriver.common.by import By #导入By类
- from selenium.webdriver.support.ui import WebDriverWait
-
- def run_webdriver():
- driver = webdriver.Chrome()
- driver.maximize_window()
- driver.get('https://www.jd.com/')
-
- #直接查找元素,不等待
- # search = driver.find_element(By.ID, "key")
-
- #创建一个等待对象,最大等待10秒,每间隔0.5秒检查一次元素是否出现,如果10秒结束还没出来则报错
- wait = WebDriverWait(driver,10,0.5)
- #创建需要等待的具体元素:ID="key"
- wait.until(EC.presence_of_element_located((By.ID, 'key')))
-
-
- sleep(5)
- driver.quit()
-
- if __name__ == '__main__':
- run_webdriver()
隐式等待
隐式等待设置之后代码中的所有元素定位都会做隐式等待。
通过implicitly Wait完成的延时等待,注意这种是针对全局设置的等待,如设置超时时间为10秒,使用了implicitlyWait后,如果第一次没有找到元素,会在10秒之内不断循环去找元素,如果超过10秒还没有找到,则抛出异常。
---------------------->>>>
隐式等待比较智能,它可以通过全局配置,但是只能用于元素定。
- from selenium import webdriver
- from selenium.webdriver.common.by import By #导入By类
-
- def run_webdriver():
- driver = webdriver.Chrome()
- driver.maximize_window()
- driver.get('https://www.jd.com/')
-
- #隐式等待:等于全局元素等待,设置所有元素等待10秒
- driver.implicitly_wait(10)
- search = driver.find_element(By.ID, "key")
- search = driver.find_element(By.CLASS_NAME, "key")
- search = driver.find_element(By.XPATH, "key")
-
- driver.quit()
-
- if __name__ == '__main__':
- run_webdriver()
显式等待与隐式等待的区别
1、selenium的显示等待
原理:显示等待,就是明确要等到某个元素的出现或者是某个元素的可点击等条件,等不到,就一直等,除非在规定的时间之内都没找到,就会跳出异常Exception(简而言之,就是直到元素出现才去操作,如果超时则报异常)
=====================================================================
2、selenium的隐式等待
原理:隐式等待,就是在创建driver时,为浏览器对象创建一个等待时间,这个方法是得不到某个元素就等待一段时间,直到拿到某个元素位置。
注意:在使用隐式等待的时候,实际上浏览器会在你自己设定的时间内部断的刷新页面去寻找我们需要的元素。
⑹ selenium的其他操作
无头浏览器
我们已经基本了解了selenium的基本使用了。 但是呢, 不知各位有没有发现, 每次打开浏览器的时间都比较长. 这就比较耗时了. 我们写的是爬虫程序. 目的是数据. 并不是想看网页. 那能不能让浏览器在后台跑呢? 答案是可以的。
====================================================================
导入设置参数的包:
from selenium.webdriver.chrome.options import Optionsopt = Options()
opt.add_argument("--headless") #无头模式
无头模式就是直接执行代码,不打开可视化的浏览器界面
比如前面的获取京东首页轮播图的链接:
- from time import sleep
- from selenium import webdriver
- from selenium.webdriver.common.keys import Keys
- from selenium.webdriver.common.by import By #导入By类
- from selenium.webdriver.support.ui import WebDriverWait
- from selenium.webdriver.chrome.options import Options
-
- #无头浏览器:
- def run_webdriver():
- opt = Options()
- opt.add_argument("--headless") #无头模式
- # opt.add_argument("--window-size=1200,600") # 设置窗口大小
- driver = webdriver.Chrome(options=opt) # 创建一个Chrome浏览器的WebDriver实例
- driver.get("https://www.jd.com/")
-
- # 查找京东首页的轮播图链接,共6个
- imgs = driver.find_elements(By.CLASS_NAME, 'focus-item-img')
- for img_el in imgs:
- print(img_el.get_attribute("src"))
-
- driver.quit() # 关闭浏览器
-
-
- if __name__ == '__main__':
- run_webdriver()
代码执行后直接拿到链接返回:
selenium 处理cookie
- dictCookies = driver.get_cookies() #获取所有的cookie
- driver.add_cookie(dictCookies) #添加cookie
- driver.delete_cookie("CookieName") #删除一条cookie
- driver.delete_all_cookies() #删除所有的cookie
页面前进和后退
- driver.forward() # 前进
- driver.back() # 后退
- driver.refresh() # 刷新
- driver.close() # 关闭当前窗口
demo实操--滑动验证案例
selenium整体还是比较简单的,就是模拟人工在web页面上进行操作
所以只要找到一些元素的属性,比如id、calssname就可以
=====================================================================
下面来进行学以致用,利用selenium模拟京东的账号密码登陆:
登陆页面的url:京东-欢迎登录
- from time import sleep
- from selenium import webdriver
- from selenium.webdriver.common.by import By #导入By类
-
- def run_webdriver():
- options = webdriver.ChromeOptions()
- options.add_experimental_option('detach', True) # 不自动关闭浏览器
- options.add_argument('--start-maximized') # 浏览器窗口最大化
- driver = webdriver.Chrome(options=options)
-
- #发起京东登陆页面的访问请求
- driver.get('https://passport.jd.com/new/login.aspx?')
- driver.implicitly_wait(5) #构建一个全局等待对象,等待5秒
-
- #输入账号
- loginname = driver.find_element(By.ID,"loginname")
- loginname.send_keys("123@qq.com")
-
- #输入密码
- nloginpwd = driver.find_element(By.ID,"nloginpwd")
- nloginpwd.send_keys("987612")
-
- #点击登陆
- loginBtn = driver.find_element(By.ID,"loginsubmit")
- loginBtn.click()
- sleep(3)
-
-
-
- if __name__ == '__main__':
- run_webdriver()
代码执行后,浏览器已经自动打开并完成了输入账号&密码,点击登陆,进入到滑块验证页面:
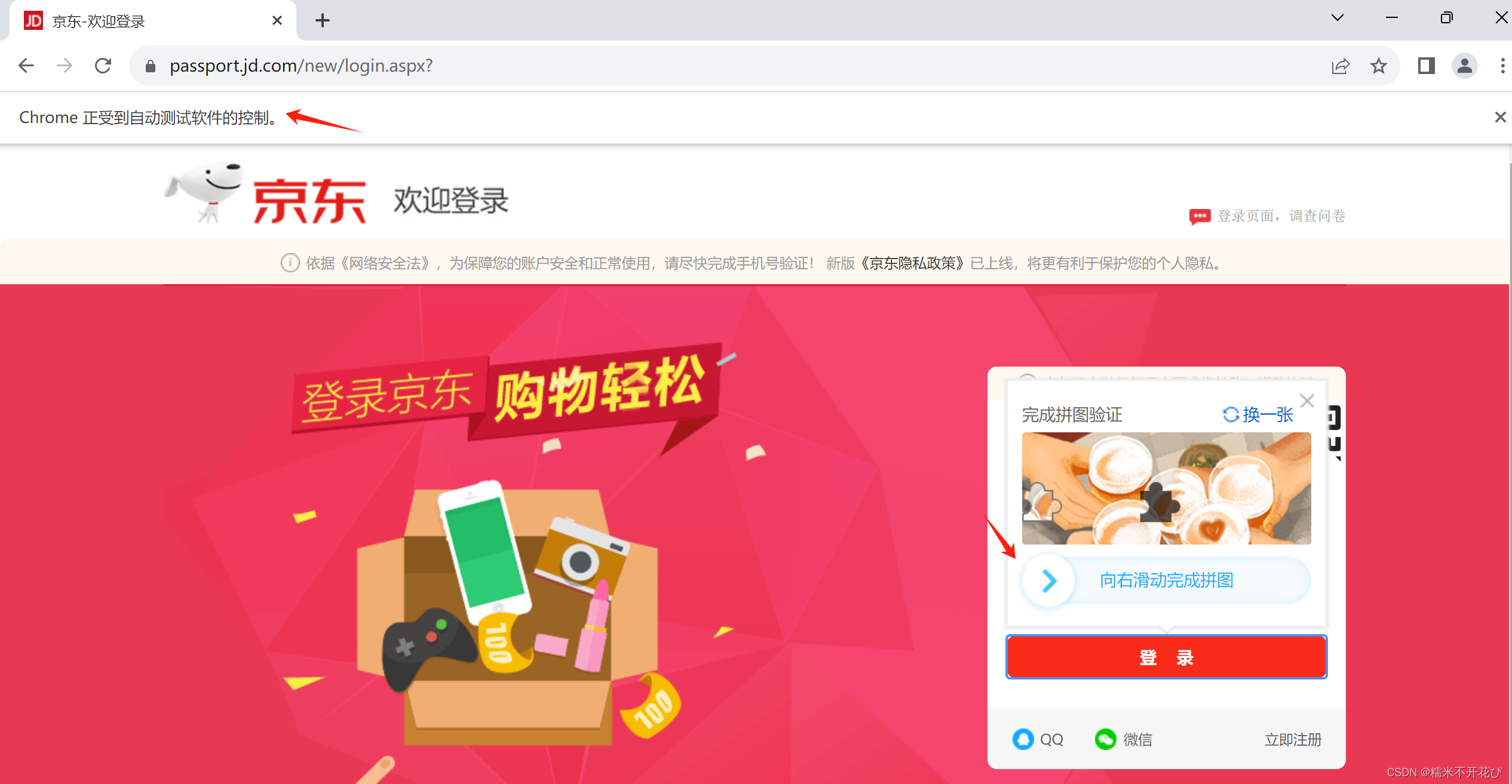
重点是,这种滑块的图片验证登陆应该怎么破?
方式有很多,可以利用一些工具
这里,我们采用掌握不多的,现有的知识来解决这个问题
首先来看看,滑块验证登陆的原理,用f12进行定位查看:
嗦嘎,原来需要匹配的小图标是个图片,它是缺口图片
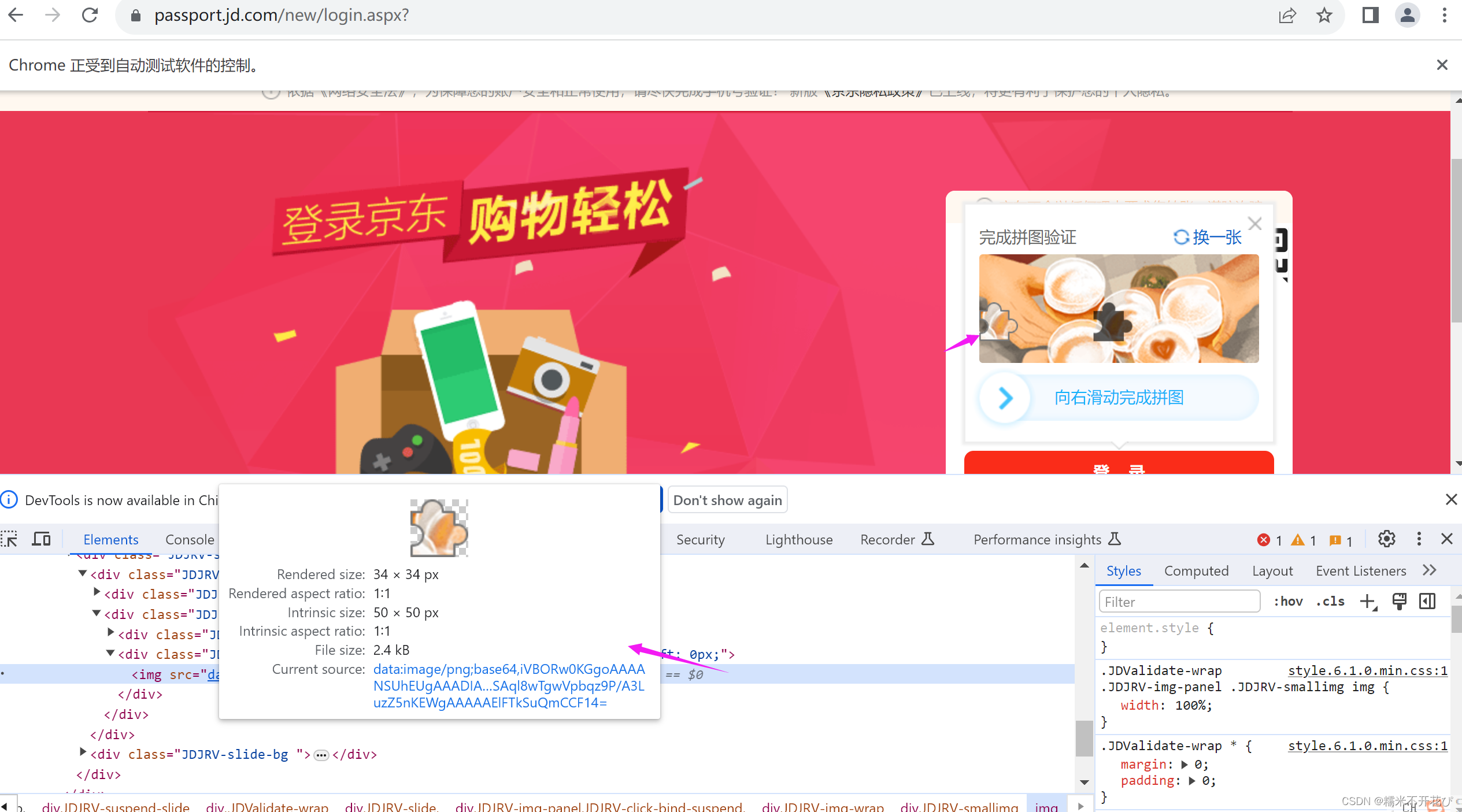
再康康后面的大图,也是一张图片,它背景图片
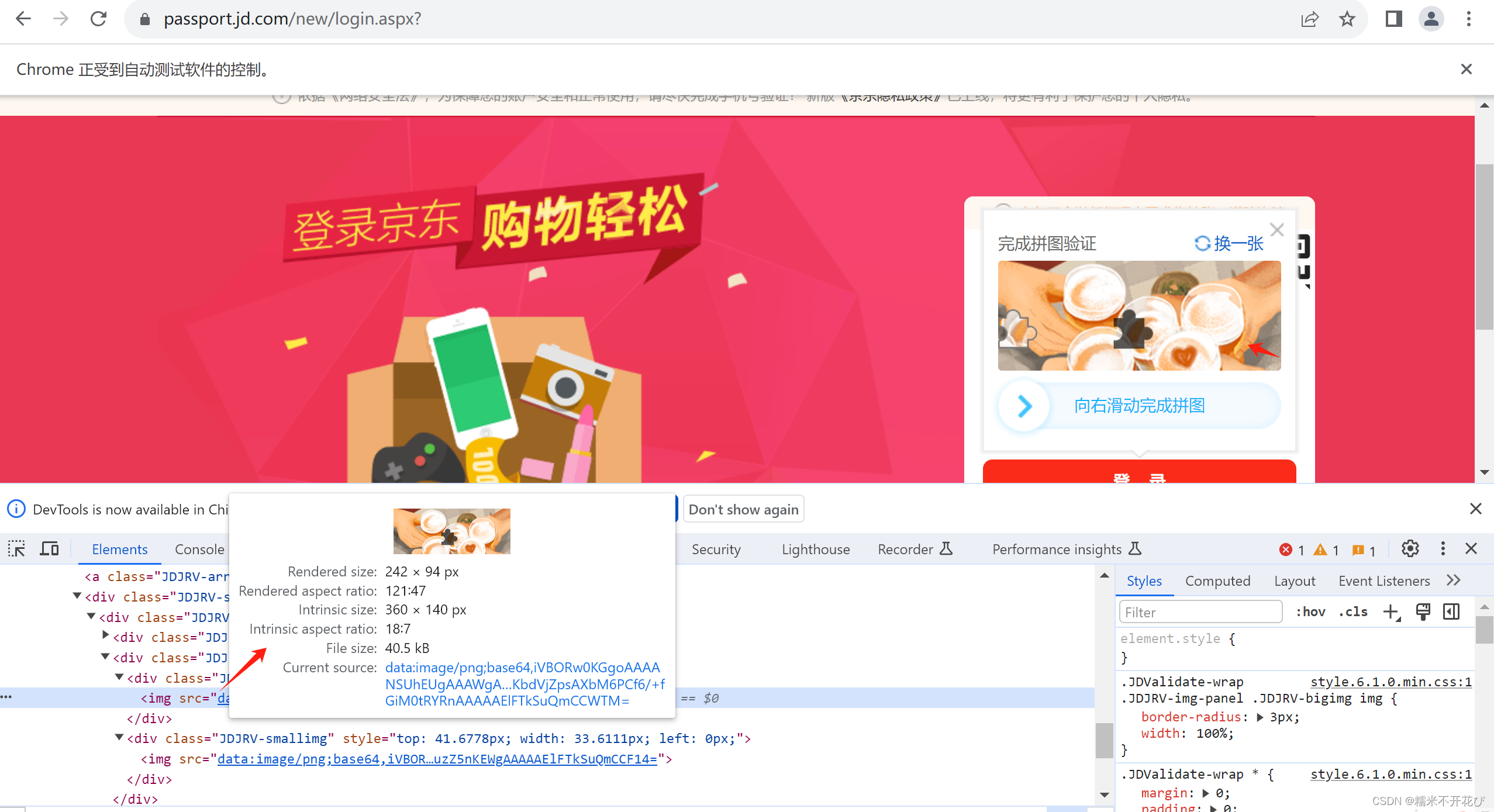
合着就是两张图片在一起玩儿呗
我们的目的:就是要拖动缺口图片放在背景图里,给它无缝拼接上
同时,最难的点也在于,滑动的距离,而且每次滑动的距离会发送变化,也就是说距离是动态的

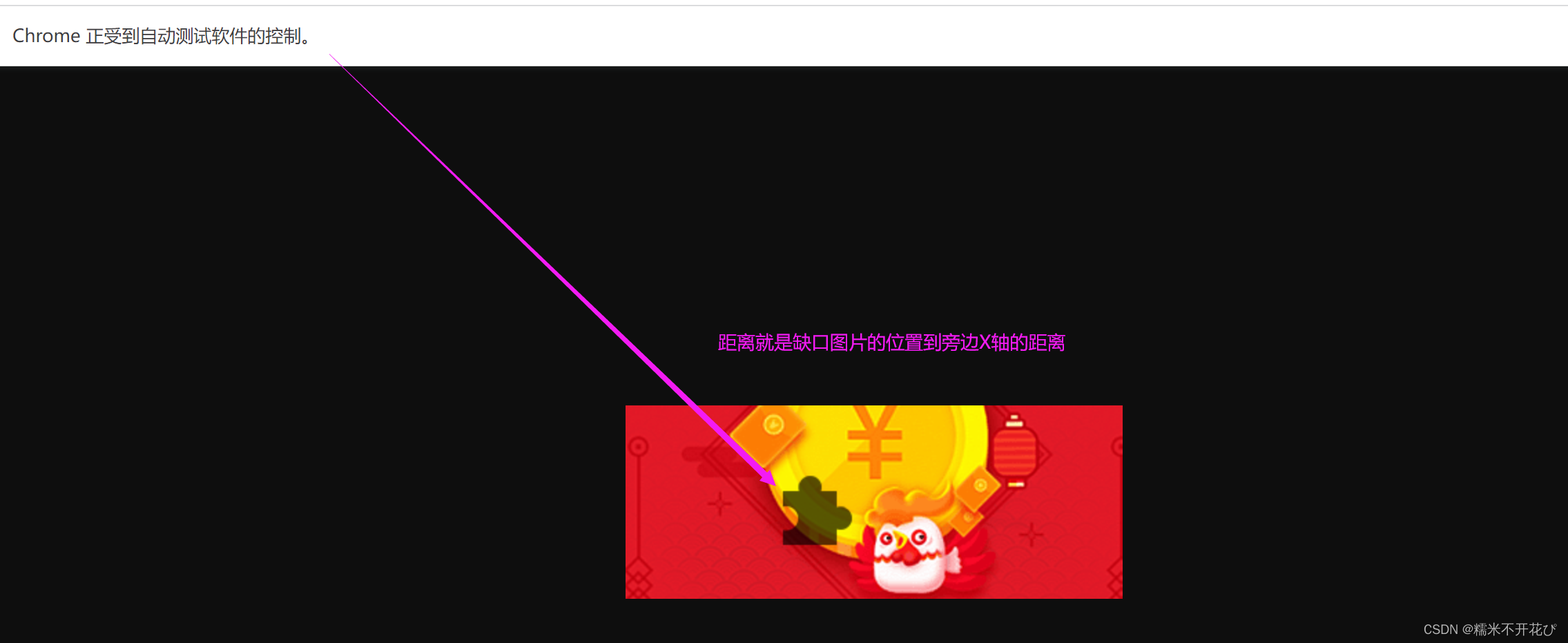
有些方式是利用像素点位进行处理的,如果遇到背景图和缺口图颜色比较相近的时候,就无法达到预期结果了;更有甚者,它的缺口图是从距离X轴有一定间隙的地方开始拖动的,好在目前京东的滑块验证登陆都是贴着X轴开始往右边拖动的。
所以,说了这么多,究竟怎么做?如何实现呢?
这里用python的第三库opencv(非常有名的图片处理、计算机视觉库),只要把背景图、缺口图这两张图片传递给opencv的match函数,它就会自动识别在背景图中目标图片的位置,而那个位置正是我们要滑动的距离。
那么接下来分为两步:
第一步,先用代码自动下载两张图片到当前代码的文件夹下
第二步用open cv进行识别缺口图在背景图中的位置
第一步代码如下(前面的代码+下载图片):
这里需要注意的是:用不上的包需要删掉,不然它会报错,原因不知道为什么,反正删了就不报错
- from selenium import webdriver
- from selenium.webdriver.common.by import By #导入By类
- from urllib import request
-
- def run_webdriver():
- options = webdriver.ChromeOptions()
- options.add_experimental_option('detach', True) # 不自动关闭浏览器
- options.add_argument('--start-maximized') # 浏览器窗口最大化
- driver = webdriver.Chrome(options=options)
-
- #发起京东登陆页面的访问请求
- driver.get('https://passport.jd.com/new/login.aspx?')
- driver.implicitly_wait(5) #构建一个全局等待对象,等待5秒
-
- #输入账号
- loginname = driver.find_element(By.ID,"loginname")
- loginname.send_keys("123@qq.com")
-
- #输入密码
- nloginpwd = driver.find_element(By.ID,"nloginpwd")
- nloginpwd.send_keys("987612")
-
- #点击登陆
- loginBtn = driver.find_element(By.ID,"loginsubmit")
- loginBtn.click()
-
- #定位背图片:
- background_src = driver.find_element(By.XPATH, '//*[@class="JDJRV-bigimg"]/img').get_attribute("src")
- gap_src = driver.find_element(By.XPATH, '//*[@class="JDJRV-smallimg"]/img').get_attribute("src")
-
- #下载图片:传递两个参数(图片的url、图片的名称),就会自动with open写入文件里
- request.urlretrieve(background_src, "background.png")
- request.urlretrieve(gap_src, "gap.png")
-
- if __name__ == '__main__':
- run_webdriver()
代码执行后,在当前文件下,两张图片就下载好了:

来安装一下opencv的库:
我习惯直接在pycharam中进行安装,搜索opencv会出来很多,我们选择opencv-python就可以
加入获取图片位置的函数
- import sys
- import cv2
- from selenium import webdriver
- from selenium.webdriver.common.by import By #导入By类
- from urllib import request
-
-
- #定义一个计算函数的方法:
- def get_distance():
- #读取两张图片对象
- background = cv2.imread("background.png",0)
- gap = cv2.imread("gap.png",0)
-
- #将两张图片放在一起,做归一化匹配处理:即找缺口图在背景图中的位置
- res = cv2.matchTemplate(background,gap,cv2.TM_CCOEFF_NORMED)
- print("res::",res)
-
- #取最大值、最小值
- value = cv2.minMaxLoc(res)
- print("value::",value)
- sys.exit()
- # return value * 278 /360
-
-
- def run_webdriver():
- options = webdriver.ChromeOptions()
- options.add_experimental_option('detach', True) # 不自动关闭浏览器
- options.add_argument('--start-maximized') # 浏览器窗口最大化
- driver = webdriver.Chrome(options=options)
-
- #发起京东登陆页面的访问请求
- driver.get('https://passport.jd.com/new/login.aspx?')
- driver.implicitly_wait(5) #构建一个全局等待对象,等待5秒
-
- #输入账号
- loginname = driver.find_element(By.ID,"loginname")
- loginname.send_keys("123@qq.com")
-
- #输入密码
- nloginpwd = driver.find_element(By.ID,"nloginpwd")
- nloginpwd.send_keys("987612")
-
- #点击登陆
- loginBtn = driver.find_element(By.ID,"loginsubmit")
- loginBtn.click()
-
- #定位背图片:
- background_src = driver.find_element(By.XPATH, '//*[@class="JDJRV-bigimg"]/img').get_attribute("src")
- gap_src = driver.find_element(By.XPATH, '//*[@class="JDJRV-smallimg"]/img').get_attribute("src")
-
- #下载图片:传递两个参数(图片的url、图片的名称),就会自动with open写入文件里
- request.urlretrieve(background_src, "background.png")
- request.urlretrieve(gap_src, "gap.png")
-
- if __name__ == '__main__':
- get_distance()
我们先将调用函数换成获取位置的函数,先看看opencv的获取结果是什么:
返回的value是缺口图片在背景图中的最大值、最小值的位置及坐标,那么我们要的是什么?
我们要的是x轴的最小值,也就是我们需要从x轴往右拖动的距离

最后加上进行滑动的代码即可,完整代码如下:
- import cv2
- from time import sleep
- from urllib import request
- from selenium import webdriver
- from selenium.webdriver.common.by import By
- from selenium.webdriver.common.action_chains import ActionChains
-
- #定义一个计算函数的方法:
- def get_distance():
- #读取两张图片对象
- background = cv2.imread(filename="background.png",flags=0,)
- gap = cv2.imread(filename="gap.png",flags=0)
-
- #将两张图片放在一起,做归一化匹配处理:即找缺口图在背景图中的位置
- res = cv2.matchTemplate(background,gap,cv2.TM_CCOEFF_NORMED)
-
- #取最大值、最小值
- value = cv2.minMaxLoc(res)[2][0]
- return value * 242 / 360
-
- def run_webdriver():
- options = webdriver.ChromeOptions()
- options.add_experimental_option('detach', True) # 不自动关闭浏览器
- options.add_argument('--start-maximized') # 浏览器窗口最大化
- driver = webdriver.Chrome(options=options)
- driver.implicitly_wait(5) # 构建一个全局等待对象,等待5秒
-
- #发起京东登陆页面的访问请求
- driver.get('https://passport.jd.com/new/login.aspx?')
-
- #输入账号
- loginname = driver.find_element(By.ID,"loginname")
- loginname.send_keys("123@qq.com")
-
- #输入密码
- nloginpwd = driver.find_element(By.ID,"nloginpwd")
- nloginpwd.send_keys("987612")
-
- #点击登陆
- loginBtn = driver.find_element(By.ID,"loginsubmit")
- loginBtn.click()
- sleep(5)
-
- #定位背图片:
- background_src = driver.find_element(By.XPATH, '//*[@class="JDJRV-bigimg"]/img').get_attribute("src")
- gap_src = driver.find_element(By.XPATH, '//*[@class="JDJRV-smallimg"]/img').get_attribute("src")
-
- #下载图片:传递两个参数(图片的url、图片的名称),就会自动with open写入文件里
- request.urlretrieve(background_src, "background.png")
- request.urlretrieve(gap_src, "gap.png")
-
- #计算滑动距离:
- distance = get_distance()
- print("distance:",distance)
-
- print('第一步,点击滑动按钮')
- element = driver.find_element(By.CLASS_NAME, 'JDJRV-slide-btn')
- ActionChains(driver).click_and_hold(on_element=element).perform() # 点击鼠标左键,按住不放
-
- ActionChains(driver).move_by_offset(xoffset=distance, yoffset=0).perform()
- ActionChains(driver).release(on_element=element).perform()
-
-
-
- if __name__ == '__main__':
- run_webdriver()
坑点记录:
在loginBtn.click()这里,我一开始没有加sleep,selenium本身打开网页就会有点慢,当网络开始不稳定的时候,运行就会报错下面截图的错,后来加上sleep就没有问题了

总结一下
优点:
这样的一套写法下来,特别是使用opencv来计算缺口图在背景图中的位置,没有什么边缘检测、去除阴影等繁杂代码,以最少的代码得到最佳效果,非常丝滑~~
另外,使用request.urlretrieve来下载图片,确保每次代码执行时下载的都是最新的图片,因为每组验证图片的位置会不同
------------------->>>>>
缺点:
不过因为滑动没有做拟人化处理,导致会嗖一下滑过去,就容易被识别为是爬虫,并且滑动完成之后,我们没有看到下一个页面,例如验证成功,或者验证失败的提示。
====================================================================
关于缺点的部分,将会在下一篇《web自动化 -- pyppeteer》的最后,用pyppeteer来完成~

