
- 1关于docker启动不了如何重新安装而不会删除现有镜像和容器_重装docker不影响容器
- 2yoloV5目标识别以及跟踪,功能识别动物(大象,犀牛,水牛,斑马)_yolov5目标跟踪
- 3Openstack制作image镜像_openstack 创建image
- 4jieba,为中文分词而生的Python库_jieba分词的版本
- 5Mybatis-insert/update时获取被更新的字段值,selectKey标签详解_mybatis更新后获取更新值
- 6学习笔记-华为IPD转型2020:3,IPD的实施_ipd 成果转移
- 7rocketmq使用常见问题_org.apache.rocketmq.client.exception.mqclientexcep
- 8修改Anaconda中的Jupyter Notebook默认工作路径(基于Windows10)_windows c.notebookapp.notebook_dir =
- 9uniapp 跳转返回携带参数(超好用)
- 10线程池四种使用方式的实现及详细介绍(必看):_线程池启动的四种方式
【目标检测】45、YOLOv3 | 针对小目标效果提升的 YOLO 网络_yolov3大目标和小目标
赞
踩

论文: YOLOv3: An Incremental Improvement
代码:https://github.com/pjreddie/darknet
作者:Joseph Redmon
时间:2018.08
贡献:
- 提出了 DarkNet-53,并且使用其输出的 3 种不同尺度的特征进行后续的预测
- 不同于 YOLOv2 中使用 5 个候选框,YOLOv3 中使用 9 个候选框(3 种尺度,每个尺度 3 个规格)
- 使用 objectness 对框进行划分,分为 1 和 -1。
- 当某个预测框和 gt 的 IoU 最大时,被分配为 1,即每个 gt 只会被分配一个预测框
- 当某个预测框和 gt 的 IoU 不是最大,但也大于阈值(如 0.5)时,被分配为 -1,意为 “忽略”,即不参与 loss 计算
- 如果某个预测框没有被分配到任何 gt 去,则不会对分类或回归的 loss 产生任何影响,只会对 objectness loss 产生影响
一、 背景
由于 YOLO 系列对小目标的检测效果一直不太好,所以 YOLOv3 主要是网络结构的改进,使其更适合小目标检测;
- 特征做的更细致,融入多持续特征图信息
- 候选框 B=9(3 种 scale,每种有 3 个规格)

二、方法
YOLOv3 的整体过程:
- 首先,Backbone,输入大小为 416x416 的图像,经过 DarkNet-53,输出 8、16、32 倍下采样的特征图,大小分别为 56x56、26x26、13x13
- 然后,Neck,对这三种不同分辨率的特征图,使用 PAN 进行特征融合,让不同分辨率的特征更好的交互
- 最后,YOLO Head,在每个分辨率上的特征图上,分别预测类别和位置,使用 conv+bn+激活的形式来实现,每个分辨率上得到的是 k × k × c h a n n e l s k \times k \times channels k×k×channels 的形式的输出,其中 k k k 为特征图的大小,channels =3 x (4(位置) + 1(objectness) + 类别个数)
1、Bounding box prediction
在 YOLO9000 中,使用如下方式来表达框的位置:
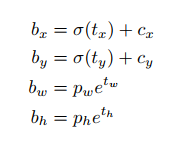
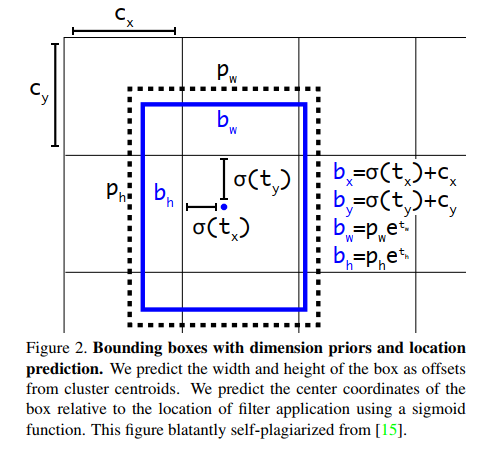
其中预测值 tx, ty 并不是 anchor 的坐标,而是 anchor 的偏移量,同样的 tw, th 是先验框的缩放因子,先验框的大小由 k-means 聚类 xml 标签文件中保存的坐标位置得到。
YOLOv3 提出了 objectness score,使用 logistic 回归的方法来对每个框预测 objectness score:
- 1:当一个先验框和 gt 的 IoU 大于其他先验框时,objectness score = 1
- -1:当一个先验框的 IoU 不是最大,但大于阈值时(0.5),则 objectness score = -1,不参与训练
YOLOv3 中的 objectness 可以理解成对应 True 和 False 逻辑值。
由于每个真实框只对应一个 objectness 标签为 1 的预测框,如果有些预测框跟真实框之间的 IoU 很大,但并不是最大的那个(比如大于 0.5),那么直接将其 objectness 标签设置为 0 当作负样本,可能并不妥当,所以就将其 objectness 标签设置为 -1,不参与损失函数的计算。
objectness 也可以表示目标在边界框内的概率。目标中心的网格和其相邻网格的 objectness 得分应该接近 1,而角落处的网格的 objectness 得分可能接近 0。
2、分类预测
作者使用 logistic classifier,使用二值交叉熵损失来进行分类训练
3、根据尺度进行预测
YOLOv3 在 3 个尺度上进行框的预测,最后输出三个信息:bbox、objectness、class
在 COCO 数据集中,就会在每个尺度上输出:
- N × B × [ 3 ∗ ( 4 + 1 + 80 ) ] N\times B \times [3*(4+1+80)] N×B×[3∗(4+1+80)] 偏移信息
- 1 个 objectness
- 80 个类别预测
预测要点:
- 使用 k-means 距离的方法来确定先验 bbox,9 个形心,然后使用尺度来将这些簇分开(因为最后的预测包括 3 个分辨率尺度,也就是给每个尺度上预测 3 个 anchor,9 个形心按照面积大小排列,然后按顺序分给 3 个尺度)
- COCO 上的 9 个簇分别为:(10x13), (16x30),(33x23), (30x61), (62x45), (59x119), (116x90), (156x198), (373x326)。
4、特征抽取
在 YOLOv2 中使用的是 Darknet-19,YOLOv3 使用 Darknet-53。
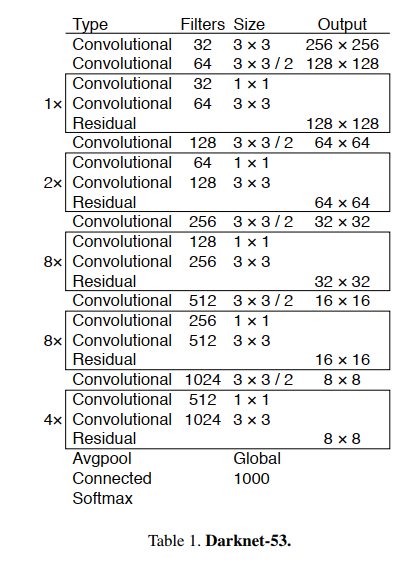
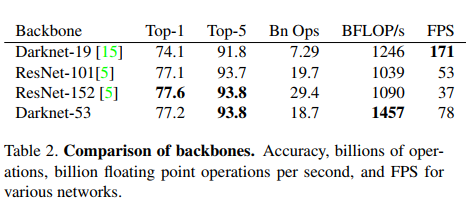
三、效果
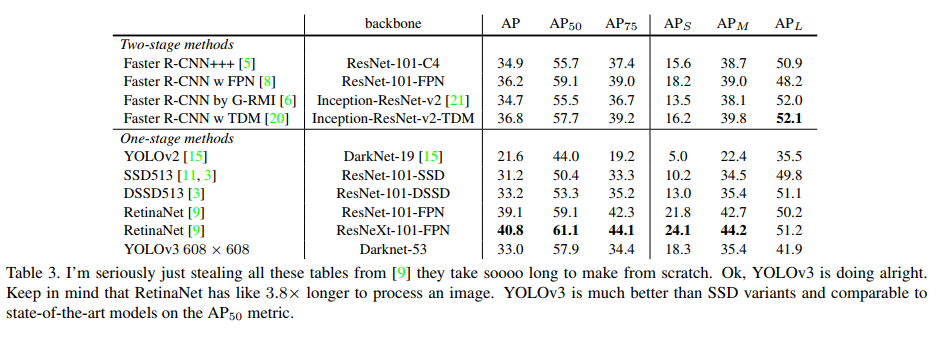
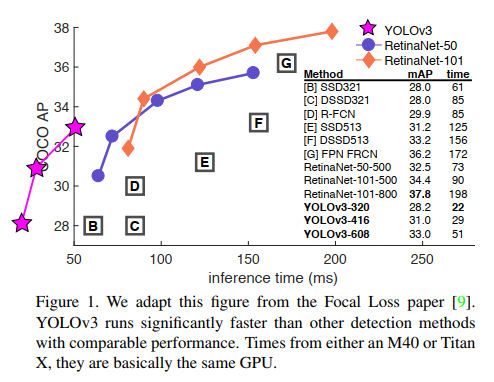
- YOLOv3 在 COCO 上获得了和 SSD 媲美的效果,且速度比 SSD 快 3x
- 当 IoU = 0.5 时,YOLOv3 效果很好,和 RetinaNet 效果相当,且高于 SSD,这说明 YOLOv3 性能很好
- 当 IoU 升高时,YOLOv3 没降低很多,说明其边框还是比较准确的
- 之前的 YOLO 方法对小目标都不太友好,YOLOv3 的 APs 指标表现很好,但在大中型目标上效果较差,需要继续研究
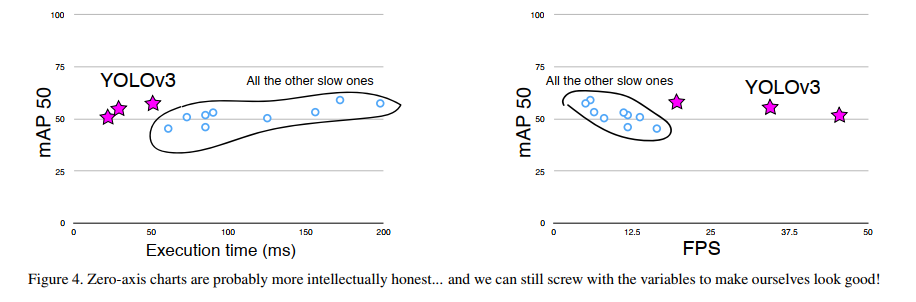
- 如图 5 所示,YOLOv3 可以称为 faster and better


