- 1python中tkinter实现GUI程序:三个实例_python 界面开发实例
- 2putty连接linux设置文件夹,【整理】Windows用ssh连接Linux,想要从Linux上面上传/下载文件 -> putty的子工具psftp...
- 3月球绘画软件测试,宇宙飞船简笔画:第一个登上月球的宇航员
- 4PuTTY用户手册(十二)_puttygen ed25519 key
- 5debug模式下动态代理invoke方法重复执行问题_invocationhandler的invoke方法 会执行多次
- 6【NLP实践-Task3 特征选择】TF-IDF&互信息_tfidftransformer互信息
- 7Android Studio无法自动填充代码的可能原因及解决办法_android studio没有代码补全
- 8postgresql数据库中出现锁表如何解决_pgsql锁表解锁
- 9神经网络发展历程_98年神经网络遇到
- 10nRF52832 DFU升级导致FDS数据丢失的问题_nrf fds烧录被擦除
Oracle基础-分组查询 备份
赞
踩
一、概述
数据分组的目的是用来汇总数据或为整个分组显示单行的汇总信息,通常在查询结果集中使用GROUP BY 子句对记录进行分组。在SELECT 语句中,GROUP BY 子句位于FROM 子句之后,语法格式:
SELECT columns_list
FROM table_name
[WHERE conditional_expression]
GROUP BY columns_list
GROUP BY 子句可以基于指定某一列的值将数据集合划分为多个分组,同一组内所有记录在分组属性上具有相同值,也可以基于指定多列的值将数据集合划分为多个分组。
二、分组查询的几种情况
1、使用GROUP BY子句进行单列分组
单列分组是指基于列生成分组统计结果。当进行单列分组时,会基于分组列的每个不同值生成一个统计结果。
【例1.1】在EMP表中,按照部门编号(deptno)和职务列进行分组。
select deptno,job from emp group by deptno,job order by deptno
group by 子句经常与聚集函数一起使用。使用group by 子句和聚集函数,可以实现对查询结果中每一组数据进行分类统计。所以,在结果中每组数据都有一个与之对应的统计值。
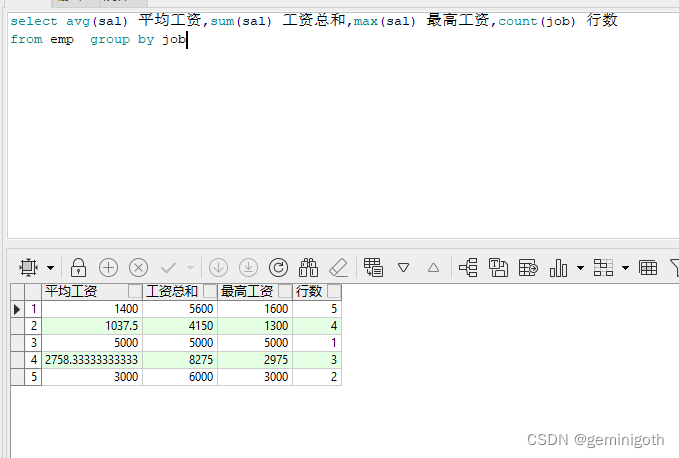
【例1.2】在emp表中,使用group by 对工资记录进行分组,并计算平均工资(avg)、所有工资的总和(sum)、最高工资(max)和各组的行数(count)
- select avg(sal) 平均工资,sum(sal) 工资总和,max(sal) 最高工资,count(job) 行数
- from emp group by job
注意:
1、在select 子句的后面只可以有两类表达式:统计函数和进行分组的列名。
2、select子句中的列必须是进行分组的列,除此之外添加其他的列名都是错误的,但是group by子句后面的列名可以不出现在select子句中。
3、在默认情况下,将按照group by子句指定的分组列升序排列,如果需要重新排序,可以使用order by 子句指定新的排列顺序。
group by 子句中的列可以不再select列表中。
【例1.3】查询emp表,显示按职位-job分类的每类员工的平均工资,并且显示的结果按照职位有小到大排列。
select avg(sal) 平均工资 from emp group by job 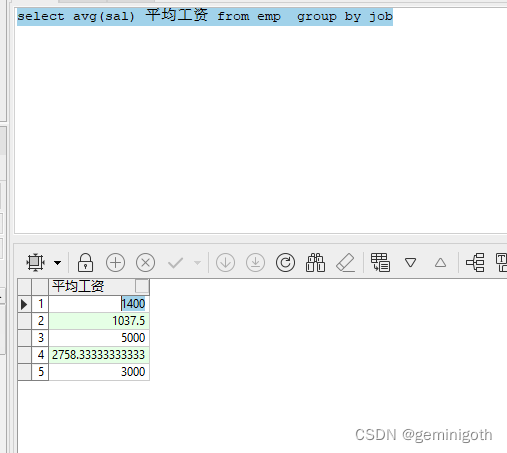
从上面的运行结果很难看出这一结果是按什么排序的。为了提高程序的可读性,应尽可能不使用这样的查询方法。实际的使用查询方法如下:
select job,avg(sal) 平均工资 from emp group by job
2、使用group by 子句进行多列分组
多列分组是指基于两个或另个以上的列生成分组统计结果。当进行多列分组时,会基于多个列的不同值生成统计结果。
【2.1】使用group by 进行多列分组,查询emp表,显示每个部门每种岗位的平均工资和最高工资。
select deptno,job,avg(sal) 平均工资,max(sal) 最高工资 from emp group by deptno,job 
3、使用order by 子句改变分组排序结果
当使用group by 子句执行分组统计时,会自动基于分组列进行升序排列。为了改变分组数据的排序结果,需要使用order by 子句。
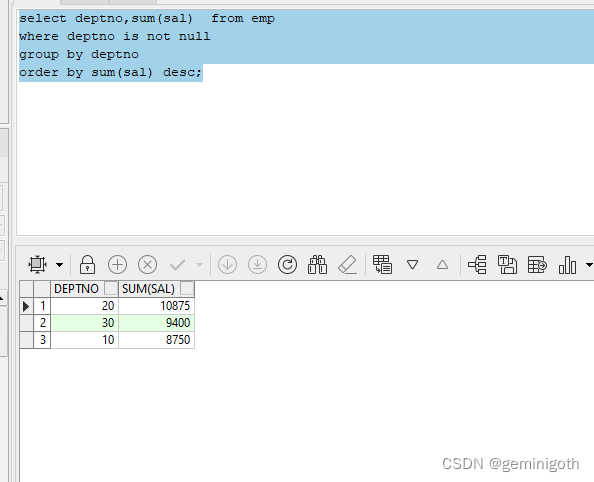
【例3.1】查询emp表,显示每个部门的部门号及工资总额,并按照工资总额降序排列。
- select deptno,sum(sal) from emp
- where deptno is not null
- group by deptno
- order by sum(sal) desc;
4、使用HAVING子句限制分组结果
having 子句通常与group by 子句一起使用,在完成对分组结果统计后,可以使用having 子句对分组的结果做进一步筛选。如果不使用group by 子句,having子句的功能与where一样。having子句与where的相似之处都是定义搜索条件。唯一不同的是having子句中可以包含聚合函数,如count,avg,sum等,在where子句中则不可以使用聚合函数。
如果在select语句中使用了group by 子句,那么having子句应用于group by 子句创建的那些组。如果执行了where子句,而没有指定group by 子句,那么having 子句应用于where子句的输出,并且整个输出被看作一个组,如果select 语句中既没有指定where,也没有指定group by ,那么having子句将应用于from 子句的输出,并且将其看作一个组。
提示:
对于having子句作用的理解有一个办法,就是记住select 语句中子句处理顺序。在select 语句中,首先由from 子句找到数据表,where 子句则接收from 子句输出的数据,而having 子句则接收来自group by 、where 或 from 子句的输出。
【例4.1】在emp表中,首先通过分组的方式计算出每个部门的平均工资,然后在通过having子句过滤出平均 工资大于2000的记录信息。
- select deptno 部门编号 ,avg(sal) 平均工资 from emp
- group by deptno
- having avg(sal) > 2000

从上面的查询结果中可以看出,select语句使用group by 子句对emp表进行分组统计,然后再由having子句根据统计值进一步筛选。
上面的例子无法使用where子句直接过滤出平均工资大于2000的部门信心,因为where 子句不能使用聚合函数。
通常情况下,having与group by 一起使用,这样可以汇总相关数据后在进一步筛选汇总的数据。
5、在group by 子句中使用rollup 和cube操作符
5.1 使用ROLLUP 操作符执行数据统计
当直接使用group by子句进行多列分组时,只能生成简单的数据统计结果。为了生成数据统计、横向小计和总计统计,可以在group by 使用rollup操作符。
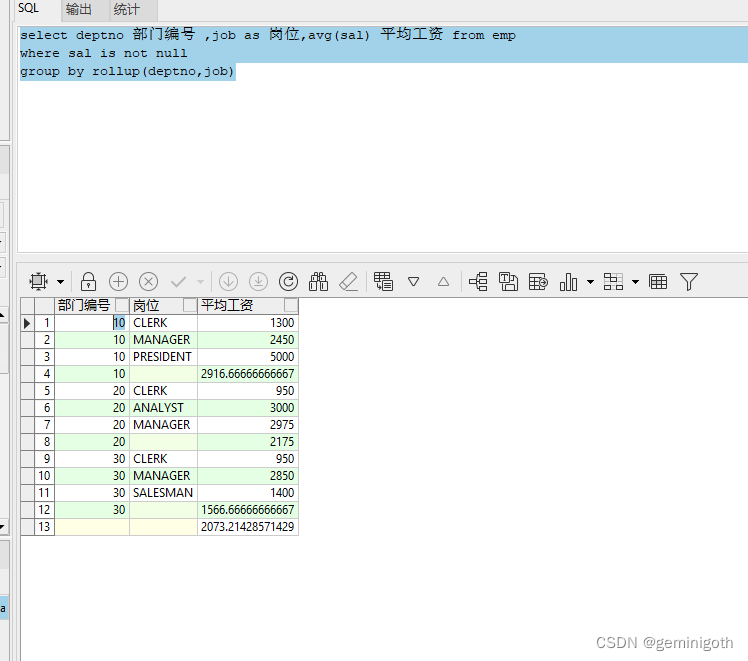
【例5.1.1】在emp表中,使用rollup操作符,显示各部门每个岗位的平均工资、每部门的平均工资、雇员的平均工资。
- select deptno 部门编号 ,job as 岗位,avg(sal) 平均工资 from emp
- where sal is not null
- group by rollup(deptno,job)
5.2 使用cubr操作符执行数据统计
为了生成数据统计、横向小计、纵向小计以及总计统计,可以使用cube操作符。
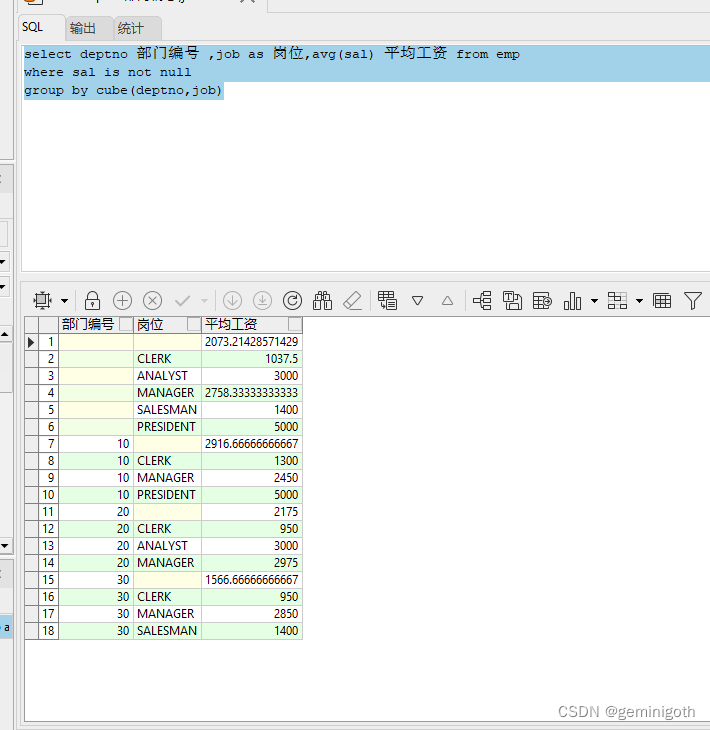
【5.2.1】在emp表中,使用cube操作符,显示各部门各岗位的平均工资、部门平局工资、岗位平均工资、所有雇员平均工资。
- select deptno 部门编号 ,job as 岗位,avg(sal) 平均工资 from emp
- where sal is not null
- group by cube(deptno,job)