
- 1L1-6 剪切粘贴(Python)
- 2Caused by: java.lang.IllegalStateException: Expected BEGIN_OBJECT but was STRING at line 1 column 39...
- 3如何提升C++ 代码性能-以loop为例
- 4脑电分析系列[MNE-Python-2]| MNE中数据结构Epoch及其创建方法
- 5海思越影3516DV500效果对比,升级版越影1.1版本有大幅提升_tnr snr
- 6Tested采访扎克伯格:揭秘四款VR原型机更多细节_青亭网 meta pancake
- 7【Oracle笔记】数据库dump导入和导出_oracle dba_hist_datadump
- 8单阶段多层检测器:SSD (理论及Pytorch代码详解)
- 9【JavaSE】Java练习—方法 _Java SE_public static void main(string[] args) { scanner a
- 10微信小程序个人中心页面开发_个人中心微信小程序代码
机器学习中最优化算法总结(理论+实践)_最优化理论与实践
赞
踩
在使用tensorflow时,相信很多人把优化算法直接填上Adam,然后发现准确率不错,但是如果想真正研究机器学习,光会用是远远不够的,下面介绍目前机器学习中主流的优化算法:

0、引言
-
1.选择哪种优化算法并没有达成共识
-
2.具有自适应学习率(以RMSProp 和AdaDelta 为代表)的算法族表现得相当鲁棒,不分伯仲,但没有哪个算法能脱颖而出。
-
3.对于深度学习,普遍都是针对庞大的数据集,基本上极少会出现凸优化情况,对于解决传统凸优化问题的算法难以应用,将非凸问题转换为凸优化问题的难度不可想象,所以基于随机梯度下降的优化算法无疑是很好的选择。对于当前流行的优化算法包括括SGD、具动量的SGD、RMSProp、具动量的RMSProp、AdaDelta 和Adam而言,选择哪一个算法似乎主要取决于使用者对算法的熟悉程度(以便调节超参数)
-
4.启发式算法研究起步时间较早,但仍较有进一步研究价值。
-
5.基本不用二阶近似优化算法
1、梯度下降
1.1 传统梯度下降
公式:x += - learning_rate * dx
优点:易于理解,可解释强
缺点:计算复杂,数据庞大时难以实现
1.2 随机梯度下降(SGD)
在这里SGD和min-batch是同一个意思,抽取m个小批量(独立同分布)样本,通过计算他们平梯度均值。后面几个改进算法,均是采用min-batch的方式。
先上一些结论:
-
1.SGD应用于凸问题时,k次迭代后泛化误差的数量级是O(1/sqrt(k)),强凸下是O(1/k)。
-
2.理论上GD比SGD有着更好的收敛率,然而,泛化误差的下降速度不会快于O(1/k)。鉴于SGD只需少量样本就能快速更新,这远超过了缓慢的渐进收敛,因此不值得寻找使用收敛快O(1/k)。
-
3.可能由于SGD在学习中增加了噪声,有正则化的效果
-
4.在某些硬件上使用特定大小的数组时,运行时间会更少。尤其是在使用GPU时,通常使用2 的幂数作为批量大小可以获得更少的运行时间。一般,2 的幂数的取值范围是32 到256,16 有时在尝试大模型时使用。
-
5.如果批量处理中的所有样本可以并行地处理(通常确是如此),那么内存消耗和批量大小会正比。对于很多硬件设施,这是批量大小的限制因素
没啥太大难度,需要注意的是有必要随迭代步数,逐渐降低学习率。一种常见从做法是线性衰减学习率,直到这里写图片描述次t迭代:
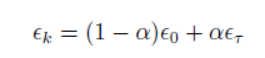
缺点:可能会收敛到局部最优,由于单个样本并不能代表全体样本的趋势。
1.3 随机梯度下降变体
随机梯度下降的优点对于深度学习来说实在是太香了,人们当然不会放过它,但是,搞不好就到了局部极小点,这也让很多人头皮发麻,为此,随机梯度下降变体应运而生:
这一部分就不详细讲解了,本部分参考:Deep Learning 之 最优化方法
1.3.1 Momentum(动量)
Momentum引入了动量v,以指数衰减的形式累计历史梯度,以此来解决Hessian矩阵病态问题。
该方法从物理角度上对于最优化问题得到的启发。
损失值是山的高度(因此高度势能是 [公式] ,所以有 [公式] )。最优化过程可以看做是模拟参数向量(即质点)在地形上滚动的过程。因为作用于质点的力与梯度潜在能量( [公式] )有关,质点所受的力就是损失函数的(负)梯度。
还有,因为 [公式] ,所以在这个观点下(负)梯度与质点的加速度成比例。
注意这个理解与随机梯度下降(SDG)不同,在SGD中,梯度影响位置。
而在这个版本的更新中,物理观点建议梯度只是影响速度,然后速度再影响位置:
动量更新 v = mu * v - learning_rate * dx # 与速度融合 x += v # 与位置融合
- 1
- 2
- 3
1.3.2 Nesterov(牛顿动量)
与普通动量不同,最近比较流行。在理论上对于凸函数能更好的收敛,在实践中也表现更好。核心思路 : 当参数向量位于某个位置 x 时,观察上面的动量更新公式,动量部分(momentum step)会通过mu * v改变参数向量。因此,如要计算梯度,那么可以将未来的近似位置 看做是“向前看”,这个点在我们一会儿要停止的位置附近。因此,计算 的梯度而不是“旧”位置 x 的梯度就有意义了。

既然动量会把参数带到绿色箭头指向的点,那就不要在原点(红色点)那里计算梯度了。
使用Nesterov动量,我们就在这个“向前看”的地方计算梯度。
也就是说,添加一些注释后,实现代码如下:
x_ahead = x + mu * v
# 计算dx_ahead(在x_ahead处的梯度,而不是在x处的梯度)
v = mu * v - learning_rate * dx_ahead
x += v
- 1
- 2
- 3
- 4
上面的程序还得写 dx_ahead,就很麻烦。但通过对 x_ahead = x + mu * v 使用变量变换进行改写是可以做到的,然后用x_ahead而不是x来表示上面的更新。也就是说,实际存储的参数向量总是向前一步版本。x_ahead 的公式(将其重新命名为x)就变成了:
v_prev = v # 存储备份
v = mu * v - learning_rate * dx # 速度更新保持不变
x += -mu * v_prev + (1 + mu) * v # 位置更新变了形式
- 1
- 2
- 3
1.3.3 AdaGrad
-
1.简单来讲,设置全局学习率之后,每次通过,全局学习率逐参数的除以历史梯度平方和的平方根,使得每个参数的学习率不同
-
2.效果是:在参数空间更为平缓的方向,会取得更大的进步(因为平缓,所以历史梯度平方和较小,对应学习下降的幅度较小)
-
3.缺点是,使得学习率过早,过量的减少
-
4.在某些模型上效果不错。
算法:https://blog.csdn.net/bvl10101111/article/details/72616097
1.3.4 RMSProp
1.AdaGrad算法的改进。鉴于神经网络都是非凸条件下的,RMSProp在非凸条件下结果更好,改变梯度累积为指数衰减的移动平均以丢弃遥远的过去历史。
2.经验上,RMSProp被证明有效且实用的深度学习网络优化算法。
相比于AdaGrad的历史梯度,RMSProp增加了一个衰减系数来控制历史信息的获取多少:
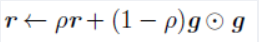
算法:https://blog.csdn.net/bvl10101111/article/details/72616378
1.3.5 Adam
大佬登场!!!!!!
1.Adam算法可以看做是修正后的Momentum+RMSProp算法
2.动量直接并入梯度一阶矩估计中(指数加权)
3.Adam通常被认为对超参数的选择相当鲁棒
4.学习率建议为0.001

1.3.6 综合对比
在实际操作中,推荐Adam作为默认算法,一般比RMSProp要好一点。
但是也可以试试SGD+Nesterov动量。
完整的Adam更新算法也包含了一个偏置(bias)矫正机制,因为m,v两个矩阵初始为0,在没有完全热身之前存在偏差,需要采取一些补偿措施。

2、二阶近似算法
在工程优化这门课中,这些方法应该都讲过,下面回顾一下。
2.1 牛顿法
同样考虑无约束优化问题minxf(x),其中f(x)是在RD上具有二阶连续偏导的函数。假设第k次迭代值为x(k),则根据目标函数的性质,我们可以将f(x)在x(k)的领域处进行二阶泰勒展开:
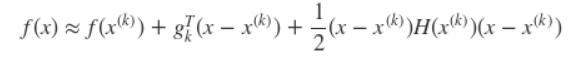
其中gk = g(x(k)) =∇f(x(k))为f(x)在x(k)的梯度,H(x(k))是f(x)的海塞矩阵(Hesse matrix) ,表达式为
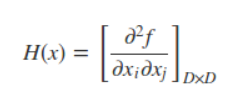
对于二次函数求极小值可以通过偏导为零来求得(当海森矩阵是正定矩阵时,f(x) 的极值就是极小值)
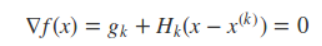
这样在第K + 1步时的最优解 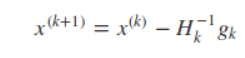
这种在领域内进行二次展开,并不断的通过求领域里的极小值来进行下降的方法就叫做牛顿法
牛顿法的下降速度会优于梯度下降法,牛顿法在领域内是用二次曲面去拟合真实的局部曲面,而梯度下降法是用平面去拟合,因此牛顿法的结果是更接近真实值的。而且牛顿法还利用了二阶导数信息把握了梯度变化的趋势,使得能够预测到下一步最优的方向,因此牛顿法比梯度下降法的预见性更远(梯度下降法每次都是从当前位置选择坡度最大的方向走,牛顿法不仅会考虑当前坡度是否最大,还会考虑之后的坡度是否最大),更能把握正确的搜索方向而加快收敛。
当然牛顿法也有很多缺点:
1)目标优化函数必须是二阶可导,海森矩阵必须正定
2)计算量太大,除了计算梯度之外,还要计算海森矩阵以及其逆矩阵
3)当目标函数不是完全的凸函数时,容易陷入鞍点。
2.2 拟牛顿法
拟牛顿法旨在解决牛顿法中的海森矩阵的问题。在拟牛顿法中考虑用一个D阶的正定矩阵来近似的代替海森矩阵的逆矩阵。这样就避免要去计算逆矩阵。
将x = x(k+1) 代入到下面的式子中
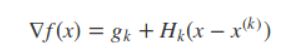
可以得到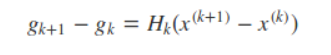
上式即为Hk满足的条件,称为拟牛顿条件。若将Gk作为H−1k的近似,则要求Gk满足同样的条件。而在每次迭代中,可以选择更新矩阵Gk+1:
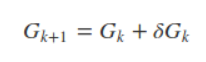
不同的Gk 的选择,就衍生出了不同的方法,常见的有DFP算法、BFGS算法(最流行的拟牛顿法)等。
深度学习
深度学习中有很多对梯度下降法的变体算法,都是用来加速神经网络的优化的(神经网络中数据量太大了,计算量太,优化慢)
2.3 共轭梯度法
共轭梯度法是介于梯度下降法与牛顿法之间的一个方法,它仅需利用一阶导数信息,但克服了最速下降法收敛慢的缺点,又避免了牛顿法需要存储和计算 Hessian 矩阵并求逆的缺点,共轭梯度法不仅是解决大型线性方程组最有用的方法之一,也是解大型非线性最优化最有效的算法之一。 在各种优化算法中,共轭梯度法是非常重要的一种。其优点是所需存储量小,具有步收敛性,稳定性高,而且不需要任何外来参数。
当然,对于凸优化是很不错的,通信中的凸优化问题就可以考虑,深度学习就考虑其他方法吧了。
2.4 BFGS
Broyden-Fletcher-Goldfarb-Shanno(BFGS)算法具有牛顿法的一些优点,但没有牛顿法的计算负担。在这方面,BFGS和CG 很像。然而,BFGS使用了一个更直接的方法近似牛顿更新。用矩阵Mt 近似逆,迭代地低秩更新精度以更好地近似Hessian的逆。
2.5 L-BFGS
存储受限的BFGS(L-BFGS)通过避免存储完整的Hessian 逆的近似矩阵M,使得BFGS算法的存储代价显著降低。L-BFGS算法使用和BFGS算法相同的方法计算M的近似,但起始假设是M^(t-1) 是单位矩阵,而不是一步一步都要存储近似。
3、启发式算法
启发式方法指人在解决问题时所采取的一种根据经验规则进行发现的方法。其特点是在解决问题时,利用过去的经验,选择已经行之有效的方法,而不是系统地、以确定的步骤去寻求答案。启发式优化方法种类繁多,包括经典的模拟退火方法、遗传算法、蚁群算法以及粒子群算法等等。
4、TensorFlow中的应用
class Adadelta:实现Adadelta算法的优化程序。
class Adagrad:实现Adagrad算法的优化程序。
class Adam:实现Adam算法的优化程序。
class Adamax:实现Adamax算法的优化程序。
class Ftrl:实现FTRL算法的优化程序。
class Nadam:实现NAdam算法的优化程序。
class Optimizer:更新了优化程序的基类。
class RMSprop:实现RMSprop算法的优化程序。
class SGD:随机梯度下降和动量优化器。
参考文献及推荐阅读:
如何理解Adam算法
Deep Learning 之 最优化方法
最后,感谢大家的阅读点赞关注,非常欢迎在评论区提出批评指正和交流。

