
- 1【工具】——IDEA安装lombok_idea lombok-plugin.zip
- 2GEE:为机器学习方法(随机森林、支持矢量机等)添加时间序列特征_gee|基于时间序列特征的山东省玉米随机森林分类代码
- 3【nRF Connect】三、连接蓝牙设备_蓝牙连接preferred phy
- 4HarmonyOS 组件9--自定义组件_harmoney os export 组件
- 5小游戏开发引擎应该如何选型
- 6初识C语言(三)_c语言中int line什么意思
- 7Android中几种常用的定时器_mhandler.postdelayed(this, 1000);
- 8vue3中axios的封装以及使用_vue3 axios封装与使用
- 9django中的ajax_post请求_django ajax post
- 10Pytorch之Bert中文文本分类(二)_bertadam用什么声明
换脸效果媲美GAN!一文解析OpenAI最新流生成模型「Glow」
赞
踩


在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
这是 PaperDaily 的第 90 篇文章本期推荐的论文笔记来自 PaperWeekly 社区用户 @TwistedW。基于流的生成模型在 2014 年已经被提出,但是一直被忽视。由 OpenAI 带来的 Glow 展示了流生成模型强大的图像生成能力。文章使用可逆 1 x 1 卷积在已有的流模型 NICE 和 RealNVP 基础上进行扩展,精确的潜变量推断在人脸属性上展示了惊艳的实验效果。
如果你对本文工作感兴趣,点击底部阅读原文即可查看原论文。
关于作者:武广,合肥工业大学硕士生,研究方向为图像生成。
■ 论文 | Glow: Generative Flow with Invertible 1x1 Convolutions
■ 链接 | https://www.paperweekly.site/papers/2101
■ 源码 | https://github.com/openai/glow
图像生成在 GAN 和 VAE 诞生后得到了很快的发展,现在围绕 GAN 的论文十分火热。生成模型只能受限于 GAN 和 VAE 吗?OpenAI 给出了否定的答案,OpenAI 带来了 Glow,一种基于流的生成模型。
虽然基于流的生成模型在 2014 年就已经提出来了,但是一直没有得到重视。Glow 的作者在之前已经在基于流的生成模型上提出了 NICE [1] 和 RealNVP [2],Glow 正是在这两个模型基础加入可逆 1 x 1 卷积进行扩展,精确的潜在变量推断在人脸属性上展示了惊艳的实验效果,具体效果可在 OpenAI 放出的 Demo [3] 下查看。
论文引入
随着深度神经网络的发展,生成模型也得到了巨大的飞跃。目前已有的生成模型除了 Glow 外包括三大类,GAN、VAE 和 Autoregressive Model(自回归模型)。 其中自回归模型和 VAE 是基于似然的方法,GAN 则是通过缩小样本和生成之间的分布实现数据的生成。文中对这些已有的生成模型也做了一个小结:
1. 自回归模型(Autoregressive Model):自回归模型在 PixelCNN 和 PixelRNN 上展示了很不错的实验效果,但是由于是按照像素点去生成图像导致计算成本高, 在可并行性上受限,在处理大型数据如大型图像或视频是具有一定麻烦的。
2. 变分自编码器(VAE):VAE 是在 Autoencoder 的基础上让图像编码的潜在向量服从高斯分布从而实现图像的生成,优化了数据对数似然的下界,VAE 在图像生成上是可并行的, 但是 VAE 存在着生成图像模糊的问题,Glow 文中称之为优化相对具有挑战性。
3. 生成对抗网络(GAN):GAN 的思想就是利用博弈不断的优化生成器和判别器从而使得生成的图像与真实图像在分布上越来越相近。GAN 生成的图像比较清晰, 在很多 GAN 的拓展工作中也取得了很大的提高。但是 GAN 生成中的多样性不足以及训练过程不稳定是 GAN 一直以来的问题,同时 GAN 没有潜在空间编码器,从而缺乏对数据的全面支持。
基于流的生成模型,首先在 NICE 中得到提出并在 RealNVP 中延伸。可以说流的生成模型被 GAN 的光芒掩盖了,但是是金子总会发光。Glow 一文算是将流生成模型推到了学术的前沿,已经有很多学者在讨论 Glow 的价值,甚至有说 Glow 将超越 GAN。
具体还要看学术圈的进一步发展,不过 Glow 确实在图像的生成,尤其是在图像编码得到的潜在向量精确推断上展示了很好的效果。在 OpenAI 放出的 Demo 上展示了很惊艳的实验效果,就人脸合成和属性变化上可以看出 Glow 确实可以媲美 GAN。
基于流的生成模型总结一下具有以下优点:
1. 精确的潜在变量推断和对数似然评估,在 VAE 中编码后只能推理出对应于数据点的潜在变量的近似值,GAN 根本就没有编码器更不用谈潜在变量的推断了。在 Glow 这样的可逆生成模型中,可以在没有近似的情况下实现潜在变量的精确的推理,还可以优化数据的精确对数似然,而不是其下限。
2. 高效的推理和合成,自回归模型如 PixelCNN,也是可逆的,然而这样的模型合成难以实现并行化,并且通常在并行硬件上效率低下。而基于流的生成模型如 Glow 和 RealNVP 都能有效实现推理与合成的并行化。
3. 对下游任务有用的潜在空间,自回归模型的隐藏层有未知的边际分布,使其执行有效的数据操作上很困难;在 GAN 中,由于模型没有编码器使得数据点通常不能在潜在空间中直接被表征,并且表征完整的数据分布也是不容易的。而在可逆生成模型和 VAE 中不会如此,它们允许多种应用,例如数据点之间的插值,和已有数据点的有目的修改。
4. 内存的巨大潜力,如 RevNet 论文所述,在可逆神经网络中计算梯度需要一定量的内存,而不是线性的深度。
基于流的生成模型的优势展示了 Glow 的魅力,但是在 Glow 论文解读前,我们还是先回顾一下前两个基于流的生成模型 NICE 和 RealNVP。
NICE
NICE 的全称为 NON-LINEAR INDEPENDENT COMPONENTS ESTIMATION,翻译过来就是“非线性独立分量估计”。整体上来说,NICE 是为了对复杂的高维数据进行非线性变换,将高维数据映射到潜在空间,产生独立的潜在变量。这个过程是可逆的,即可以从高维数据映射到潜在空间,也可以从潜在空间反过来映射到高维数据。
为了实现这个可逆的映射关系,就需要找到一个满足映射的函数 f,使得 h=f(x),这里的 x 就是高维数据,对应到图像生成上 x 就是输入的图像,h 就是映射到的潜在空间。这个过程是可逆的,也就是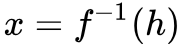 。这个潜在空间可以给定一个先验分布 pH(h),即 h∼pH(h)。 所以实现 NICE 的关键就是找到这个可逆的映射 f,这个不是一件容易的事,此时就引入了一个矩阵用于辅助实现映射,这就是雅可比矩阵。
。这个潜在空间可以给定一个先验分布 pH(h),即 h∼pH(h)。 所以实现 NICE 的关键就是找到这个可逆的映射 f,这个不是一件容易的事,此时就引入了一个矩阵用于辅助实现映射,这就是雅可比矩阵。
雅可比矩阵
假设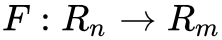 是一个从欧式 n 维空间转换到欧式 m 维空间的函数。这个函数由 m 个实函数组成
是一个从欧式 n 维空间转换到欧式 m 维空间的函数。这个函数由 m 个实函数组成 。 这些函数的偏导数(如果存在)可以组成一个 m 行 n 列的矩阵,这就是所谓的雅可比矩阵:
。 这些函数的偏导数(如果存在)可以组成一个 m 行 n 列的矩阵,这就是所谓的雅可比矩阵:
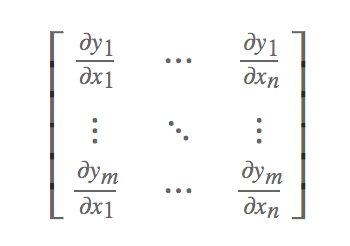
此矩阵表示为: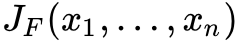 ,或者
,或者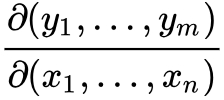 。
。
雅可比行列式
如果 m=n,那么 F 是从 n 维空间到 n 维空间的函数,且它的雅可比矩阵是一个方块矩阵,此时存在雅克比行列式。
雅克比矩阵有个重要的性质就是一个可逆函数(存在反函数的函数)的雅可比矩阵的逆矩阵即为该函数的反函数的雅可比矩阵。即,若函数 在点
在点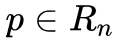 的雅可比矩阵是连续且可逆的,则 F 在点 p 的某一邻域内也是可逆的,且有
的雅可比矩阵是连续且可逆的,则 F 在点 p 的某一邻域内也是可逆的,且有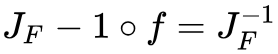 。
。
对雅克比矩阵有所了解后就可以实现映射:
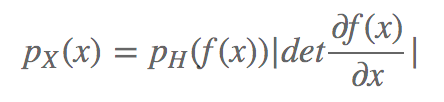
其中 就是 x 处的函数 f 的雅可比矩阵。
就是 x 处的函数 f 的雅可比矩阵。
设计这个映射函数 f 的核心就是将输入 x 进行分块,即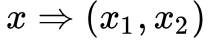 。
。
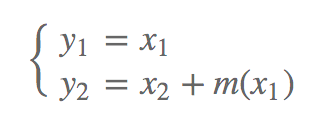
其中 m 是任意复杂的函数,但是这个分块对于任何 m 函数都具有单位雅可比行列式,且下面是可逆的:
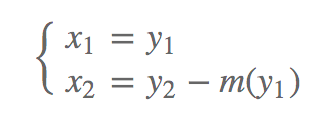
上面的映射用对数表示就是:

计算具有高维域函数的雅可比行列式并计算大矩阵的行列式通常计算量是很大的,所以直接去算雅克比行列式是不现实的,所以需要对计算做一定的简化。 NICE论文采用分层和组合变换的思想处理,即 (此处符号根据 NICE 一文与 Glow 有些许出入)。 在一些细节优化上可以采用矩阵的上三角矩阵和下三角矩阵做变换表示方阵。
(此处符号根据 NICE 一文与 Glow 有些许出入)。 在一些细节优化上可以采用矩阵的上三角矩阵和下三角矩阵做变换表示方阵。
有了分层和组合变换的处理,接着就是对组合关系的确立,文中采用寻找三角形雅克比矩阵函数簇,通过耦合层关联组合关系,也就是对 x 做分块找到合适的函数 m。 具体的细节这里不展开了,有兴趣的可以阅读原文了解。
RealNVP
RealNVP 的全称为 Real-valued Non-volume Preserving 强行翻译成中文就是“实值非体积保持”,文章的全称为 DENSITY ESTIMATION USING REAL NVP, 翻译过来就是“使用 RealNVP 进行密度估计”。RealNVP 是在 NICE 的基础上展开的,在 NICE 的基础上将分层和组合变换的思想进一步延伸。
NICE 中采用的耦合关系是加性耦合层,即对于一般的耦合层:
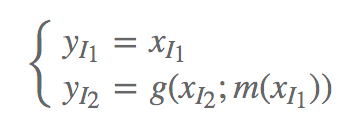
所谓加性耦合层就是取 g(a;b)=a+b,其中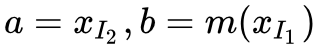 ,此时:
,此时:
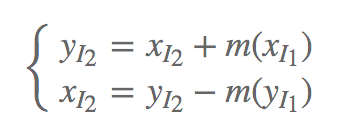
除了可以选择加性耦合层,还可以选择乘法耦合层或者仿射耦合层(affine coupling layer)。
而 RealNVP 正是采用仿射耦合层来代替加性耦合层,仿射耦合层采用 g(a;b)=a⊙b1+b2,其中 b1≠0,此时的 m 函数为: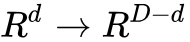 ,⊙ 为哈达马积,也就是矩阵的乘法表示,RealNVP 引入仿射耦合层后模型更加灵活。 用 s 代表尺度,t 代表平移量,此时的分块表示为:
,⊙ 为哈达马积,也就是矩阵的乘法表示,RealNVP 引入仿射耦合层后模型更加灵活。 用 s 代表尺度,t 代表平移量,此时的分块表示为:
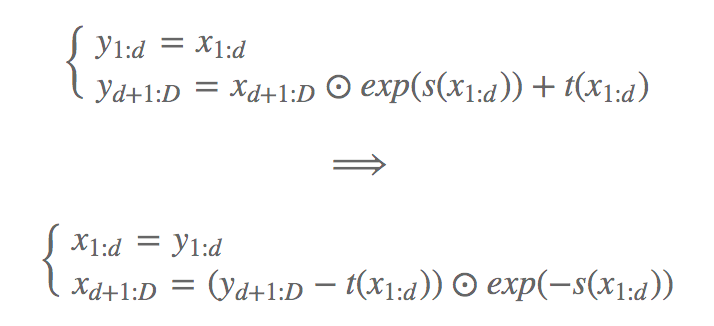
这样就实现了通过堆叠一系列简单的双射来构建灵活且易处理的双射函数。
RealNVP 在 NICE 的基础上的另一大改进就是做多尺度框架的设计。所谓的多尺度就是映射得到的最终潜在空间不是一次得到的,而是通过不同尺度的 潜在变量拼接而成的。我们看一下 RealNVP 给出的多样性示例解释图,这个图其实还不太清晰,在 Glow 中给的图就已经很清晰了。
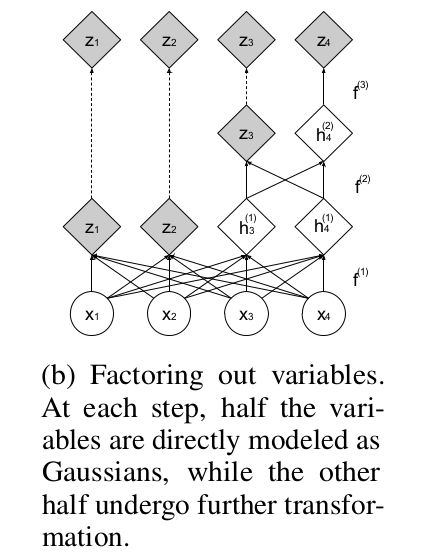
上图的意思就是每一次做流生成潜在变量时,由于要将两个潜在变量拼接后输出,为了保证多尺度就每次保留一个潜在变量,将另一个潜在变量返回到输入再次进行流操作, 经过 L−1 次流操作后将不再返回到输入而是直接输出和之前的 L−1 个潜在变量拼接形成最后的潜在变量的输出。我们再结合公式理解一下,这里稍微有点绕:
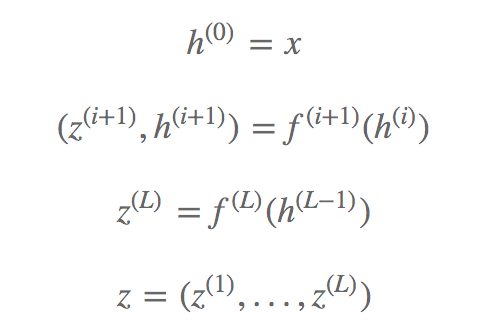
举个例子就是,比如输入 x 有 D 维,第一次经过流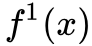 得到潜在变量 (z1,h1) 其中 z1 和 h1 维度都是
得到潜在变量 (z1,h1) 其中 z1 和 h1 维度都是![]() , 保留 z1,将 h1 送入下一轮流将得到
, 保留 z1,将 h1 送入下一轮流将得到![]() 的潜在变量,保留一个,送入另一个,直到第 L−1 轮将潜在变量直接输出和其余的潜在变量拼接形成最终的输出 z。 这里强调一下,多尺度框架的循环和流内部的经历的次数没关系,这里为了保留 RealNVP 原文的符号,采用的符号都是原文中的符号。
的潜在变量,保留一个,送入另一个,直到第 L−1 轮将潜在变量直接输出和其余的潜在变量拼接形成最终的输出 z。 这里强调一下,多尺度框架的循环和流内部的经历的次数没关系,这里为了保留 RealNVP 原文的符号,采用的符号都是原文中的符号。
RealNVP 基本上就是这样,但是细节还有很多,这里不详细展开,深入了解的可读原文。
Glow模型
我们先一起来看看 Glow 的模型框架:
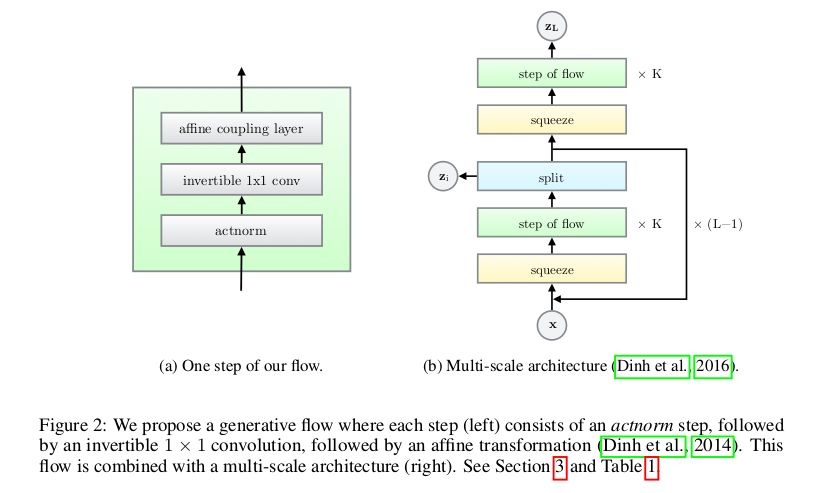
可以看到整个模型分为 (a) 和 (b),其实 (a) 只是对 (b) 中的“step of flow”的展开。Glow 的思想和前两篇整体上是一致的,都是为了找到可逆的双射来实现输入和潜在空间的相互转换。
在设计映射函数时,采用分层变换的思想,将映射 f 函数变换为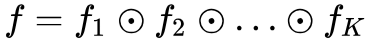 ,也就是一个完整的流需要 K 次单步流才能完成,即
,也就是一个完整的流需要 K 次单步流才能完成,即 (这里的 h 值是内部流的过渡符号和上文提到的多尺度结构不同)。在完整流结束后经过 split 后做多尺度循环,经过 L−1 循环最终的潜在变量就是
(这里的 h 值是内部流的过渡符号和上文提到的多尺度结构不同)。在完整流结束后经过 split 后做多尺度循环,经过 L−1 循环最终的潜在变量就是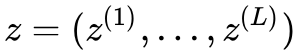 。
。
我们把单步流的框架再仔细分析一下。
Actnorm
单步流中的第一层就是 Actnorm 层,全称为 Activation Normalization 翻译为激活标准化,整体的作用类似于批归一化。但是批量归一化添加的激活噪声的方差与 GPU 或其他处理单元(PU)的小批量大小成反比,这样造成了性能上的下降,所以文章推出了 Actnorm。
Actnorm 使用每个通道的标度和偏差参数执行激活的仿射变换,类似于批量标准化,初始化这些参数,使得在给定初始数据小批量的情况下,每个通道的后行为动作具有零均值和单位方差。初始化后,标度和偏差被视为与数据无关的常规可训练参数。可以理解 Actnorm 就是对输入数据做预处理。
Invertible 1x1 Convolution
可逆 1x1 卷积是在 NICE 和 RealNVP 上的改进,NICE 和 RealNVP 是反转通道的排序,而可逆 1×1 卷积替换该固定置换,其中权重矩阵被初始化为随机旋转矩阵。具有相等数量的输入和输出通道的 1×1 卷积是置换操作的概括。通过矩阵的简化计算,可以简化整体的计算量。
Affine Coupling Layers
仿射耦合层在 RealNVP 中就已有应用,而 Glow 的基础是默认读者已经掌握了 NICE 和 RealNVP 所以单单只读 Glow 可能不能轻易的理解文章。
仿射耦合层的映入是实现可逆转换的关键,仿射耦合的思想我们上面也有提过,Glow 将其分为三部分讲解。
零初始化(Zero initialization):用零初始化每个 NN () 的最后一个卷积,使得每个仿射耦合层最初执行一个同一性函数,这有助于训练深层网络。
拆分和连接(Split and concatenation):split () 函数将输入张量沿通道维度分成两半,而concat () 操作执行相应的反向操作:连接成单个张量。 RealNVP 中采用的是另一种类型的分裂:沿着棋盘图案的空间维度拆分。Glow 中只沿通道维度执行拆分,简化了整体架构。
排列(Permutation):上面的每个流程步骤之前都应该对变量进行某种排列,以确保在充分的流程步骤之后,每个维度都可以影响其他每个维度。 NICE 完成的排列类型是在执行加性耦合层之前简单地反转通道(特征)的排序;RealNVP 是执行(固定)随机排列;Glow 则是采用可逆 1 x 1 卷积。文中也对三种方法做了实验上的比较。
对于单步流的内部操作,文章也做了解释:

Glow实验
实验的开篇是比较 Glow 和 RealNVP,反转操作上 NICE 采用反转,RealNVP 采用固定随机排列,Glow 采用可逆 1 × 1 卷积,并且耦合方式也影响实验的效果,文章比较了加性耦合层和仿射耦合层的性能差距。通过在 CIFAR-10 数据集的平均负对数似然(每维度的比特)来衡量不同操作的差距,其中所有模型都经过 K = 32 和 L = 3 的训练,实验效果如下图:
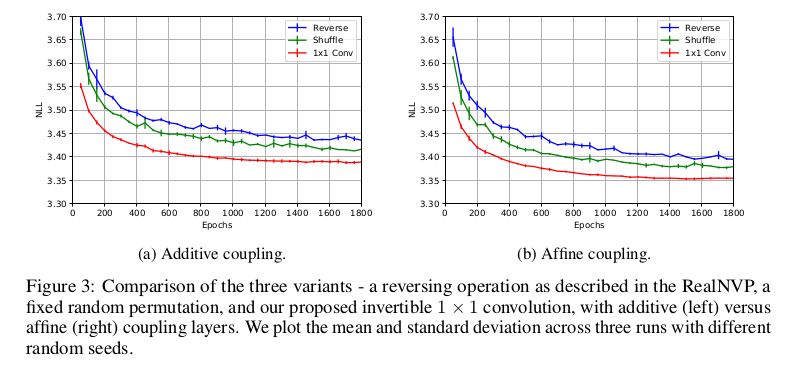
可以从上图看出,Glow 采用的方法都取得了较小的平均负对数似然,这说明了在实验上是由于其他几个模型的。
为了验证 RealNVP 和 Glow 整体的框架下的差距,实验进一步扩展,比较了 CIFAR-10,ImageNet 和 LSUN 数据集上两者的差距,在相同预处理下得到的结果如下:

正如表 2 中显示的,模型在所有数据集上实现了显着的改进。
在高分辨率图像的生成上,Glow 使用了 CelebA-HQ 数据集,数据集包含 3 万张高分辨率的图片。实验生成 256 x 256 图像,设置 K=32,L=6。我们看到这里的 L 取了 6,在高分辨率下,多尺度的丰富可能会让得到的潜在变量具有更多的图像细节。试验中采用了退火算法来优化实验,在退火参数 T=0.7 时候,合成的随机样本如下图:

可以看到合成的图像质量和合理性都是很高的,为了对潜在变量插值生成图像,实验以两组真实图片为依据,插值中间的过渡,生成的结果如下:

从上图能看出整体的过渡还是相当顺畅的,感觉很自然,这就是 Glow 在潜在变量精确推断的优势所在,这样的实验结果让人很惊讶!
为了生成更多含语义的图像,文章利用了一些标签来监督训练,对于不同人脸属性合成的图像如下:

生成的效果和过渡都是很自然合理。
退火模型对提高生成也是很重要的环节,文章对比了不同退火参数 T 下的实验效果,合理的 T 的选择对于实验效果还是很重要的。

为了说明模型深度(多尺度)的意义,文中对比了 L=4 和 L=6 的效果,可以看出多尺度对于整体模型的意义还是很大的。

总结
Glow 提出了一种新的基于流的生成模型,并在标准图像建模基准上的对数似然性方面展示了改进的定量性能,特别是在高分辨率人脸图像合成和插值生成上取得了惊艳的效果。从整体的阅读上可以看出 Glow可以完成较好的图像合成和变换的工作,具体的工作还要在吃透代码再进一步了解。写的过程中有什么问题,欢迎指正,谢谢。
参考文献
[1]. NICE: Non-linear independent components estimation" Laurent Dinh, David Krueger, Yoshua Bengio. ArXiv 2014.
[2]. Density estimation using Real NVP. Ding et al, 2016.
[3]. Glow Demo: https://blog.openai.com/glow/
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「阅读原文」即刻加入社区!
点击标题查看更多论文解读:
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文

