
- 1【开题报告】Springboot大学生创新创业项目管理60qsr计算机毕业设计_java项目springboot 大学生创新创业项目论文开题报告
- 2微调Llama2自我认知_self_cognition 数据集
- 3【MATLAB源码-第176期】基于matlab的16QAM调制解调系统频偏估计及补偿算法仿真,对比补偿前后的星座图误码率。
- 4强强联手,丝滑办公新体验!IdeaHub+华为云会议实测_华为idea hub接入
- 5第九层(16):STL终章——常用集合算法
- 6互联网架构演变过程_网络结构演进的过程
- 7图文带你彻底弄懂MySQL事务原子性之UndoLog_mysql undolog 原子性
- 8CVPR-2020笔记 | 文末送书
- 9【腾讯云 TDSQL-C Serverless 产品测评】Serverless集群高可用测评_tdsql-c mysql版 serverless
- 10OpenLayers 开源的Web GIS引擎_openlayers中文官网
kafka简介_kafaka
赞
踩
目录
目录
kafaka的发布-订阅模型

当一个topic下只有一个consumer group的时候,就是点对点的模型了。而topic下只有一个partition的时候,就是一个全局有序的消息的生产和消费了。
partition和consumer group
在分布式系统中,两大概念:分区和副本:
- 分区:目的是为了提高写吞吐量。通过将分区分布到不同的节点、每个分区独立承担写流量,从而达到提高写吞吐量
- 副本:这个是为了高可靠。通过日志复制技术对一条数据多份副本,当一个副本出现故障,通过故障切换到其他副本,保证系统的高可靠。
但是对于kafka的partition,一方面确实是提高broker消息接受的吞吐量,但是有kafka本身的特性,partition还有另外两个职责:
- 对于同一个partition中的消息,是按照队列的方式来存储。所以相同partition中的消息的消费是有序的,可以实现消息的局部有序;
- 和consumer group结合,可以提高消息消费的并发度。kafka的订阅关系是consumer group和topic之间的关系,一个consumer group下可以有多个消费者,每个消费者抢占一个partition进行消息的消费。
一个consumer group订阅到一个topic时,对于topic下的一个partition,有且仅有一个consumer group中的consumer实例消费这个partition中的消息(如上图),这个关系由broker中的Coordinator模块来负责维护,当consumer group中的consumer实例发生变化(增多、或减少时),就会触发consumer实例和partition关系的变化(这就是所谓的consumer的rebalance过程),然而这个变化是stop the world的,即会暂停这个consumer group中consumer的消息消费,所以rebalance过程就会造成消息的挤压。
当如下情况发生了,就会触发rebalance过程(参考:What happens when a new consumer joins the group in Kafka?)
- consumer group下的consumer实例发生变化。
- 正常扩/缩容、重启导致的。这种变化都是有计划、且短暂的,很快就会恢复,而且不会频繁发生。
- 心跳超时导致的。consumer会间隔heartbeat.interval.ms时间给broker汇报心跳,当broker在session.timeout.ms定义的时间超时还未收到心跳包,则认为这个consumer实例已经失效了,会重新发起rebalance。
- 消费超时导致的。kafka的消费采用的是pull模式,consumer端调用poll()方法去broker拉取消息,如果一次从broker拉取的消息在max.poll.interval.ms(默认为5min)还没有消费完成,则当前consumer会发起离开当前consumer group,从而触发一次rebalance。这种需要特别注意max.poll.interval.ms设置的较小、而消费逻辑又是比较重比较耗时的场景,另外就是consumer出现了full gc等导致的消费耗时增加。
调用一次poll()拉取的消息条数由参数max.poll.records(默认为500)控制。
- consumer group订阅的topic发生变化
- topic的分区数量发生变化。这种
kafka支持的分区策略是比较简单的:
1. 轮询/随机:这就相当于没有任何业务分区策略的兜底,纯粹是为了多个partition的写入和消费负载均衡。
2. 指定分区key(本质还是hash分区):这个可以实现业务的局部有序性
比较复杂的range分区,kafka官方没有支持,不过有扩展接口,可以通过扩展来实现,不过对于MQ(特别是需要有一定的有序性保证的),并没有很多场景需要
offset的管理
offset表达的是:消费者组a在topic1的partitionA的消费进度
zk的依赖:
1. 早期的offset。这个炸一看很棒,因为将这些数据存储在broker节点外,那么broker节点就是无状态的,对于无状态节点的扩容比有状态扩容要容易太多,但问题是它选择存放到了zk中,zk本身其实并不是一个数据存储的组件,而且它是没有分片机制的,所以它的写入是一个单节点的,所以zk的写入效率是很受限制的,但是offset又是一个变更非常频繁的,所以消息的消费吞吐会受zk的性能的影响。后面offset的管理放到了broker中,用一个专门的topic=__consumer_offsets来保存。
2. 集群管理:这个也是kafka的一个"特色",它的分布式集群能力,是依赖于一个外部组件的。但是像ES等一些分布式框架,分布式集群能力是自己基于日志复制算法来自己实现的,所以它是不依赖于外部组件的,但是其实现就会复杂得多。
3.3.1版本依赖zk的情况(当前(202212)的kafka最新版本,而且kafka已经退出了不依赖zk的部署模式了):
![]()
除了zookeeper是zk自己用的以外,其他的都是kafka存放在zk中的数据:

/config 保存的是配置信息
- changes 是用来实时监测动态参数变更的,不会保存参数值
- topics是用来保存Kafka主题级别参数的。虽然它们不属于动态Broker端参数,但其实它们也是能够动态变更
- users 和 clients 则是用于动态调整客户端配额(Quota)的 znode 节点。比如Kafka运维人员限制连入集群的客户端的吞吐量或者是限定它们使用的 CPU 资源
- /config/brokers 是用来保存动态Broker参数的地方。该 znode 下有两大类子节点
- /config/brokers/default 保存的是cluster-wide 范围的动态参数,即集群范围的参
- /config/brokers/<具体的brokerId> 保存的是特定Broker的 per-Broker范围参数。即特定的broker节点的参数。比如线程池
当消费者组中的消费者成功消费消息后,就会向这个topic发送一条offset变化的消息。consumer端的api提供了两种管理offset的方式:
- 自动提交offset。当enable.auto.commit=true的时候,consumer会每隔auto.commit.interval.ms指定的间隔向topic=__consumer_offsets下发送一条当前offset的消息,哪怕是offset没有变更也会发送。
这种有个固有的问题,那就是可能造成消息重复消费:比如一次poll()调用拉取了50条消息,这50条消息在3s内就消费完成了,还没来得及提交offset,这个时候再次poll()会拉取到重复的消息,就会造成重复消费。
问题:自动提交每隔5s就会往topic=__consumer_offsets发送一个offset提交消息,如果没有消息消费,那么n多次提交的offset都是一样的,这样长期下期,这种无用的数据将导致broker磁盘膨胀。
kafka的broker会有一个Log Cleaner线程,来定期的去整理topic=__consumer_offsets下的offset消息,将这些消息进行合并整理,以避免磁盘膨胀 - 手动提交,当enable.auto.commit=false的时候,消息消费成功后,就需要手动调用api来报告offset信息,api的背后就是向topic=__consumer_offsets发送了一条消息。
consumer客户端提供了两种提交offset的方式:同步和异步。- commitSync():同步提交。直到将offse写入到broker后,该方法返回,以及该方法背后是有重试机制的,如果提交offset不成功,会自动重试。所以问题就是:该方法会阻塞消费者实例,一定程度上会影响消费吞吐量。
- commitAsync(callback):异步提交。这个方法会立即返回,当提交出现异常时,会回调指定方法。因为是异步提交,可能
问题:异步提交失败会不会丢失消息?
异步提交本身不会丢消息,但要使用正确,比如我们一定是消息消费处理完成后才去提交offset,如果提交失败,最多只是可能出现重复消费。所以消费者消费逻辑一定要按照如下步骤进行:
{
1. poll();拉取消息
2. // 处理消息;
3. commitAsync() 提交offset。// 同步提交也是一样的。ps:这里示例的方式都是将 // poll()拉取的所有消息都处理完后再一次性提交offset,当然kafka的客户端api也 // 支持将poll()拉取到的消息进行分批提交offset,比如一次poll()拉取了500条消 // 息,每消费100条提交一次offset。
}
之所以只是可能(而不是一定)出现重复消费是因为:比如异步提交offset=100提交失败,但是另外一个offset=150提交成功了,那么broker就会认为150以前的消息都消费成功了,poll()的时候就会返回大于等于150的消息了。
kafka的事务
kafka的事务包括两方面语义:
1. producer发送多条消息的原子性。
2. comsumer侧,可以实现:消费一个topic的消息、再发送消息到另外一个topic的原子性。这个在流式数据处理很常见。
幂等producer
kafka的producer实现幂等的维度:<producer,partition>,所以kafka引入了producerId和消息序列号来实现消息发送的幂等:
- producer启动的时候,链接到broker后,broker 会为每个producer自动分配了一个 ProducerID, producer 向 broker 发送的每条消息,都会带上这个producerId,并且producer会为发送的消息维护一个递增的序列号
- 在 broker 端,broker在每个topic的partition下都维护了一个max(<producerId,序列号>),即每个producer发送到对应partition的最大序列号
当 broker 对应的partition,收到一个比当前最大<producerId,序列号>还小的 消息时,就会丢弃该消息,认为这个消息已经收到过了。 - broker中partition中存储的消息,都是存储了发送该消息的producerId和序列号,当复制到副本中时,副本中同样也就有对应消息的producerId和序列号。当因为broker异常,partition的leader重新选举后,因为新的leader依然有消息的producerId和序列号,所以这种幂等去重机制依然有效。
为了使用幂等producer,需要注意以下几个参数:
enable.idempotence:默认为false,要使用幂等producer,就需要将其设置为true。将这个参数设置成true后,kafka默认会设置如下参数,所以使用幂等producer不要显示设置如下参数,保持默认就好:
- retries=Integer.MAX_VALUE(表示消息发送失败会无限重试);
- acks=-1(后者all),表示当broker收到消息后,对应partition的所有副本都需要复制成功后,broker才会给producer返回成功的ack
- max.in.flight.requests.per.connection =5。该参数的含义是producer在收到broker的ack之前,可以再发送多少个消息。
对于还没有收到broker的ack之前,producer会将这些消息进行缓存,如果对于一条消息超时还没有收到ack、或者收到失败的回馈,那么producer会自动进行重试。
这其实是kafka为了提高吞吐量的一个批量操作,当这个值设置为1,那就是串行的单条发送,即发送一条消息,必须等到broker返回ack后,再发送下一条,这样producer发送消息的吞吐量是受影响的。
但是当没有启用幂等的时候,这个参数设置大于1,是有可能导致消息乱选的:比如该值设置成5,producer顺序发送:1、2、3、4、5。当发送了1消息后,不会等ack,会继续发送2、3、4、5,这个时候如果broker反馈2、3、4、5成功,但是1失败了,那么producer会重试发送1,那这个时候1就是在5之后了,和原本的顺序是不一样的。但是当开启了幂等后,就不存在这个问题了。
事务producer
幂等只能保证:单条消息发送到相同partition内不重复不乱序(如果partition的路由策略是hash,而不是轮询、随机这种和消息内容无关的策略,那其实就是单条消息发送的幂等性)。但是幂等是解决不了多条消息发送到broker的原子性的,为了解决这个问题,kafka引入了事务概念。所以反过来看,kafka的事务解决的问题:
- 一个producer发送多条消息到broker的原子性的问题。这多条消息可能同topic不同partition、也有可能是不同的topic。
- 另外在consumer侧,解决consume-transform-produce的原子性,即先从一个topic接收消息、然后经过处理后,再向另外一个topic发送消息,但要保证:一个topic下消息的消费和往另外一个topic发送消息这些操作是原子的。其实这个本质还是一个producer向多个topic发送多条消息的原子性问题:因为一个topic下消费成功,其实就是提交offset,其本质就是向____consumer_offsets中发送消息。所以这个问题就转换成了:一个producer向topic=____consumer_offsets以及其他topic发送多条消息的原子性问题。
kafka给这中场景提交offset专门有个sendOffsetsToTransaction()。
所以,总结下来,kafka事务解决的问题其实就只有:一个producer发送多条消息的原子性问题。
解决的问题定义清楚了,那我们就来看怎么解决了,目前业界流行的原子性协议,就是2PC(两阶段提交协议)
所以kafka为了解决producer发送多条消息原子性问题,引入了:
- 在broker端引入了TransactionCoordinator来负责协调两阶段提交。
- 引入了一个特殊的topic=__transaction_state来存储两阶段过程中的数据及状态(事务日志)
- 如果一条消息被发送多次,broker认为它是多条不同的消息,那也就不存在所谓的原子性了,一旦重试消费者就可能看到两条重复的消息,谈何原子性。所以为了解决原子性问题,消息的发送是依赖于幂等机制的。
事务性producer的基本使用方式:
- void initTransactions();// 初始化事务,比如去broker根据transactional.id获得producerId
-
- try{
-
- void beginTransaction()// 开启事务。
-
- send(msg1,topic1);// 事务内操作。因为设置了retries,所以只要失败就会重复、且幂等机制能保证不重复。
-
- send(msg2,topic2);
-
- send(msg3,topic3);
-
- commitTransaction(); // 提交事务
-
- }catche(Exeception e){
-
- abortTransaction() // 出现任何异常,回滚事务
-
- }

其实当producer调用send()成功后,消息就放到了对应的partition中,这个时候consumer调用poll()接口,其实也会拉取到这个还没提交的消息,但是consumer拉取到这个消息后,不会立即推给消费者消费,而是在客户端进行了缓存。当producer调用commit的时候,其实是发送了一个消息体为"提交"的消息到broker,当consumer后续通过poll()拉取到消息的发现是对应事务的提交信息,那么就会将原来缓存的消息推给消费者消费;如果拉到的是“回滚”,就丢弃原来缓存的消息。
怎么理解trasactional.id
在所有的分布式系统中,协调者一定是统一的,那更直白一点就是:这个协调者是个单点。单点的问题其实也很直观了
- 单点如果失效就会导致整个系统的失效不可用,可靠性比较低。解决这个问题的常规思路就是基于日志复制的备份。当失效后,自动切换到备份上,这样系统经理过短暂的不可用后能够自愈。
- 单点操作瓶颈问题。解决这个问题的思路就是:通过分片技术,将操作分散到不同的节点,这样各个节点分担操作压力,从而提高瓶颈。
所以,我们来看TransactionCoordinator是怎么来利用分片和副本来解决协调者单点问题的。
kafka的topic下的消息,天然就是支持分片和副本的:这里的分片就是partition、而每个partition又有多个副本,所以只要TransactionCoordinator能够利用上topic下消息的存储能力,那么他就天然解决了这两个问题。
这就是为什么kafka引入了topic=__transaction_state的主体来存储原子性相关的信息,TransactionCoordinator事务管理依赖的数据都是放在这个topic下的。所以接下来需要做的就是,指定路由策略,让同一个"事务",过程中的数据时钟都能放到topic=__transaction_state的同一个partition下,自然而然的一个想法就是topic=__transaction_state的partition策略按照事务Id来进行hash路由就好了。
所以生效的问题就是,如何标识一个"事务"了。kafka是一个分布式系统,数据通过partition分散到了多个机器节点上,所以"事务"也是一个分布式事务,但是如果了解过分布式数据库,比如TiDB等,他们实现的是ACID事务,为了实现线性一致性,都会依赖一个全局递增的id(全局时钟),这其实是分布式事务中一个大难点。但是kafka的"事务"是个阉割版本的,它其实就是一个producer端的原子批量发送消息,这个相比于分布式的ACID事务,要容易的多,它也就不需要一个全局的递增事务id。
kafka标识一个事务是通过Producer指定的trasactional.id,这个id没有任何要求,而且是producer来指定的。那么问题来了,如果两个Producer使用了相同的trasactional.id来开启一个事务,Broker会怎么处理呢?
kafka在特殊的topic=__transaction_state引入了epoch,它是__transaction_state这个topic下partition维度唯一且递增数字。producer在开启事务的时候,都会根据trasactional.id路由到__transaction_state主题下的一个partition,然后获得对应partition下的epoch,然后会将<producerId,transactional.id,epoch>存储到__transaction_state对应的partition中。
当事务提交的时候,broker就会根据transactional.id路由到__transaction_state的partition,然后找到事务开启存储的三元组<producerId,transactional.id,epoch>,然后会看提交请求中的epoch,如果partition中的epoch>请求中的epoch,那么broker就认为该事务已经提交了,就会报错:There is a newer producer with the same transactionalId which fences the current one。
"事务"的这种实现还有个好处:如果事务执行到一半producer实例失效了(这其实就是所谓的僵尸生产者),当另外一个producer实例顶上后,还能够继续上次没有完成的事务。这其实就是依靠producer自己管理transactional.id,在broker的__transaction_state的partition中记录了<producerId,transactional.id,epoch>来实现的。当producer初始化事务的时候,是根据transactional.id去broker获得producerId的,这样只要transactional.id一样,那么就能继续没有完成的事务
但这也有个副作用,就是在producer使用事务消息的时候,就需要注意多个事务设置进去的transactional.id了,如果多个事务Producer设置的transactional.id是一样的,那么就会错误的提交事务,并且导致其他事务回滚。
总结:
- 事务的实现依赖于幂等。为了实现幂等,kafka引入了producerId和partition级别的递增序列号。
- 在幂等基础之上实现事务(原子性):
- 引入了transactional.id来标记一次事务操作;
- 使用topic=__transaction_state来记录事务日志;
- 引入TransactionCoordinator组件来管理事务过程,并依靠kafka的topic天生的分片和副本解决协调者的单点问题;
另外一个小问题:第二阶段的提交/回滚如果出错了又怎么办呢(事务悬挂)?
- 直接报错,让业务自行处理,比如kafka。这种方式是解决不了超时还没有收到提交请求的场场景,只能依靠客户端收到异常的重试。
- 另外就是:状态回查。producer需要提供一个回查接口,当一个消息超时还未提交的时候,broker就会来不断回查,broker通过回查接口的返回来决定是回滚还是提交。
两阶段2pc简介
回过头来看下解决原子性的两阶段提交协议(2pc)
ps:可能也有人说TCC也是,仅仅个人看法,TCC算不上一个系统层面的原子性问题的解决方案,它更多的是一个在业务层解决这类问题的一个方法论的沉淀,按照TCC的方法实现,确实可以解决原子性问题,不过它是强侵入业务逻辑的。所以一般在讨论这种和具体业务无关的组件的时候,不会考虑TCC方案的。
但是朴素的两阶段提交协议是有一些问题的:
- 阻塞时间较长:对于一条数据prepare后,那么对该条数据的任何操作都会被阻塞,直到第二阶段
- 事务悬挂问题:第二阶段提交失败,一直收不到足够的参与者提交成功的回馈,那么当前事务就一直处于准备完成阶段了。
- 潜在的数据不一致:如果第二阶段提交,部分节点成功了、部分节点失败了。那个各个节点上的数据就是不一致的。
- 事务管理器单点问题:需要有一个统一的协调者来协同完成两阶段提交,即事务管理器。存在单点问题
问题1其实没有什么好的解决方式,只能是提搞两阶段效率,减少这个锁定时间,然后增加定时器;而第四点的单点问题,解决方式就是事务管理器可以通过日志复制的方式使得事务管理器也具有分布式的能力,从而减缓了单点问题。
而引起第二和第三点的根本原因是一样的:需要向所有的参与者都发送一次提交请求,如果有的成功了、有的不成功;有的响应太慢了,就会造成潜在的数据不一致的问题。所以google的percolator事务模型对两阶段的改进思路就是:通过mvcc+主锁的方式,变成了只需要向一个参与者节点发送提交请求就可以了,这次请求要么成功、要么失败,就是原子的了。
这里有没有发现一个问题,在介绍2pc的文章中,更多的都是从协调者的角度出发,在讲述协调者如何通过两阶段协议来保证各个参与者的原子性的。但是很少有将客户端加进来讲述,其实这就往往会导致一个问题:一说两阶段,好像都懂;一落到一个具体的框架上,就都蒙了。
下面我们就简单介绍下,到底有啥区别。如下就是一个完整的需要保证操作原子性的分布式系统:

需要保证原子性的其实就是:客户端对一个分布式系统中一个数据的操作,需要保证在参与者1、参与者2、参与者N上要么都执行要么都不执行。
第一种交互方式:不需要客户端端参与的两阶段提交:

客户单发送一个操作请求,然后阻塞住,协调这来完成两阶段的提交,当两阶段提交完成后,给客户端返回成功或者失败。这种起目的纯粹就是为了保证客户端对分布式系统中一个数据的操作,需要保证多个参与者上要么全都执行、要么全都不执行,保证手段就是两阶段提交,而这个两阶段过程对客户端是透明的。
第二种实现是需要客户端来参与的两阶段:
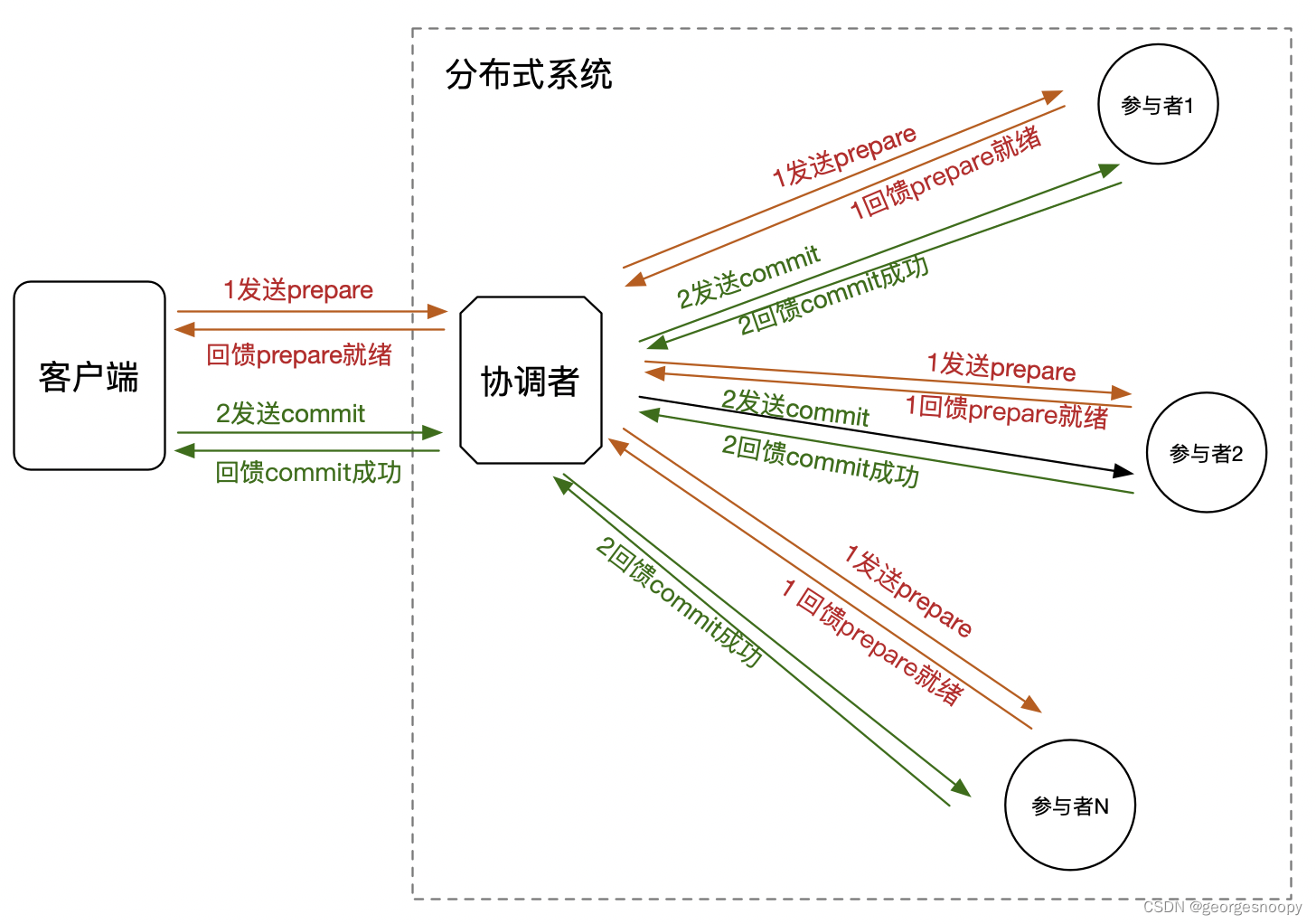
客户端能感知到两阶段提交协议。客户端会先发送prepare请求,然后协调者会返回给他prepare成功;然后客户端在发起commit请求,然后协调这返回给客户端commit是否成功。其实这是实现事务的标准交互模式,想想jdbc操作mysql,客户端api几乎是一模一样(开启事务、事务内操作、提交事务、回滚事务),对客户端的接口是不是也是这样的,因为它需要两个操作将一些列操作给包围起来构成一个事务内操作。只是说这些操作到了协调者那的处理方式不一样。对于mysql来说,因为是单体的,所以就是记录事务日志,然后返回;而对于分布式系统,其实就是两阶段协议。
对于使用了2pc的这两种交互方式,唯一的区别在于:
1. 第二阶段commit什么时候发起:
- 对于第一种实现方式,协调这收到了所有的参与这prepare成功后(可能是大多数),就直接会发起第二阶段commit;
- 对于第二种实现方式,协调这收到了所有的参与这prepare成功后(可能是大多数),是直接返回给客户端成功,然后等待客户端发起第二阶段commit。
2. 第二阶段rollback什么时候发起:
- 对于第一种实现,协调者收到1个prepare失败(可能是大多数),那么就会发起第二阶段rollback,回滚prepare的数据。
- 对于第二种实现,协调收到1个prepare失败(可能是大多数),那么就会返回给客户端prepare失败,然后依靠客户单发送第二阶段的rollback。
集群管理
partition的领导人并不是在leader失效的时候,通过raft等算法选出来的,而是kafka为每个partition在zk中都维护了一个ISR(In Sync Replication)集合,里面记录的就是哪些副本是已经和leader的数据保持一致了,当leader失效的时候,就随机在ISR中选择一个作为副本,所以kafka的leader切换会更快。
所以问题就变成了,什么时候以什么样的规则来维护ISR?
这里解释清楚几个参数的含义,那么同步时机和规则也就说清楚了:min.insync.replicas、acks以及replica.lag.time.max.ms。
producer的参数acks来使用的,acks用来在producer发送消息后,指示broker,消息至少要同步到多少副本才返回ack,这个参数有三个值:
- acks=0: producer不等broker返回ack,只要网络IO写入成功到buffer里,就会返回。
- acks=1:只要leader消息接收成功,就会给producer返回ack。
- acks=-1(all):默认值。leader收到消息后,需要等待ISR列表中的所有副本都写入消息成功了,才会给producer返回ack。注意:这里不是所有副本、而是所有ISR列表中的副本。
broker在等待满足min.insync.replicas指定副本数同步完成的时候,producer的这个请求就是缓存在Purgatory组件中的。
如上所属,只要副本的同步进度和leader想抄小于replica.lag.time.max.ms(默认10s),那么就会将这个副本维护到对应partition的ISR列表中。想象一个场景:一个partition是3副本,但是follower同步比较慢,在某一时刻只有一个副本的数据同步满足小于replica.lag.time.max.ms,所以这个partition的ISR列表中只有一个副本(即leader),这个时候producer设置acks=all发送消息,因为ISR只有leader,所以leader写入成功,也就会回馈ack。这种情况,如果leader失效,那么就会丢失数据。
为了解决这个问题,引入了min.insync.replicas,表示的是消息写入的时候,至少要同步到多少个副本,才算成功,即partition的ISR列表中副本个数的下限。所以这个参数是配合acks来使用的,当生产者acks=all,而在发送消息时,Broker的ISR数量没有达到n,Broker不能处理这条消息,需要直接给生产者报错(NotEnoughReplicasException异常)。
- 这个参数的设置绝对不能超过partition的副本数,否者当acks=all的时候,就一定不成功。所以它一定要小于partition的副本数
- 这个参数不应设置过小。为0的时候acks=all和acks=0几乎没啥区别了;为1的时候acks=all和acks=1的时候没有区别,都有消息丢失的风险
- 也不宜设置过大,比如就直接设置成partitions的副本数,这样数据缺失是绝对不会丢失,这样的问题一个是影响吞吐量、一个是减低可用性。影响吞吐量就不用说了,producer发送消息的时候,需要等待同步的副本数更多,所以耗时也就会更大;而影响可用性就是能够容忍失效的副本数就变成0了,只要有一个副本机器失效,那么producer写入就都会失败。
- 这个参数的合理设置,其实可以参考那些使用raft/paxos算法自己管理集群的组件对应参数的设置:设置成副本的大多数。在可用性和数据可靠性上有一个这种
ps:比如zk、ES等都有一个类似的同步副本数的设置,但是配合leader选举的大多数,其实可以做到不丢失数据的。
所以,可以发现,当acks=all的时候,min.insync.replicas指定个数的副本是同步更新的,因为只有min.insync.replicas个副本更新成功了,producer才会收到成功的acks。超过min.insync.replicas的那些副本就是异步更新了,只要这些副本同步进度赶上了leader,那么也是会被维护到ISR列表中,这样leader失效了他们也是可能成为新的leader的。
如果ISR中的一个副本已经失效,那么在写入的时候要等他赶上leader的进度,那就会导致写入失败。所以引入replica.lag.time.max.ms(3.3.1版本默认30s),如果ISR中发副本在这个参数指定时间没有向leader发送数据同步请求、或者指定时间内同步进度还没赶上leader,则这个副本就会从ISR中移除,从而避免这种问题
kafka的消息传输保证
常见的三种不同程度的传输保证:
- 最多一次:这种几乎没有实际使用的,因为会丢消息。
- 至少一次:这种是使用的最多的,因为不会丢消息。但是会有重复
- 正好一次:这种其实是最期望的,但是实现难度较大。kafka的正好一次也是有一些特定场景限定的。
对于一个消息引擎来说,这种传输语义的保证其实分三段,任何一段不满足都对应的传输保证,那么整个业务就没法保证。
- producer发送消息到broker
- broker保证收到的消息不丢失
- consumer从broker消费消息。
而且这三段是一个依赖关系,比如broker保证消息不丢失的前提是producer能够正确都将消息发送到broker;而consumer要能够保证一定能消费成功消息,必须依赖broker不丢失消息。
producer端
为了实现producer至少一次正确的将消息发送到broker,没有别的招,那就是重试,直到成功,从而保证至少一次。
但重试就可能产生重复送达,那就不满足正好一次,kafka为了支撑正好一次,引入了幂等producer和事务producer
- 同topic同partition消息的正好一次的送达broker,开启producer的幂等就好了
- 跨topic/跨partition消息的正好一次的送达broker,就需要开启producer的事务机制了。
broker端
对于broker端,对传输语义的保证贡献主要就是:当给producer返回消息接收成功的ack后,要保证在这条消息的不丢失(持久性)。
- 对于单节点的broker,那么就是只有producer发送过来的消息落盘了,才返回给producer成功。
- 对于集成的broker,那就是基于raft等日志复制算法的多副本来保证消息一定不会丢失。
对于kafka来说,就需要正确的设置min.insync.replicas参数,以及producer的acks=all来保证,broker端不丢失消息。
consumer端
kafka的消费模式是pull模式,即consumer主动去broker拉取消息来消费的模式。当consumer处理完拉取到的消息时,提交消费进度offset,则下次拉取的时候就拉取最新的消费进度的消息。
所以consumer至少一次的消费保证 ,就需要消费者正确的管理自己的消费进度offset的提交:即只要没有消费成功,不要去提交offset。只要满足了这个条件,那么每次poll的时候还会拉取到原来的消息,就一定能够消费得到。
所以对于普通的mq的应用场景:
- 做好offset的提交管理:保证消费不成功,一定不要提交offset。
- 消费逻辑的幂等,保证重复消费也不会有问题
- 注意队头阻塞(挤压):对于一个partition中的消息,还是按照队列中来消费的。如果说一条消息一直消费不成功,offset一直不去提交,那么每次拉取都还是拉取的那条消息,这样这个partition中后续的消息都不能消费。
这种因为一条消息消费不成功除了导致消息挤压以外,还会引发consumer group中consumer实例和partition之间的balance:consumer有个检测机制,如果两次poll()调用间隔超过max.poll.interval.ms(默认5min),那么这个consumer实例就会发起一个离开consumer group的请求,就会导致consumer group中的consumer实例发生变化,从而导致rebalance
在大数据生态中,kafka经常作为一个数据源来存在,就会有consume-transform-produce的场景,即:先消费某个topic下的消息,经过处理后,再向另外一个topic发送消息,而需要保证这两消费消息和发送消息的原子性,而这两个操作的原子性可以转换成:向__consumer_offsets发送消息(offset消息)和向另外一个业务topic发送消息的原子性,所以其实就回到了事务producer的解决方式了。
而kafka的正好一次语义,其实也就是指的consume-transform-produce场景下,利用事务producer来保证consum-produce的原子性,实现正好一次。
消息挤压
消息挤压本身不是什么问题,但是因为不合理的使用导致的消息长时间挤压就需要关注了
- consumer变更rebalance导致的挤压。对于kafka来说,只要consumer变更,会发起一次消费者组中的consumer抢夺partition的rebalance,过程中,消费是暂停的,会造成挤压。所以好多时候服务上线重启过程,会有一定的消息挤压。但是如果是因为参数设置不合理导致的频繁rebalance,就需要注意了,比如一次poll()拉取的消息过多、而两次poll()间隔过短导致的导致的rebalance,或者消费者fullgc导致消费时长变成导致超过两次poll()间隔超时等
- 使用mq来作流量整形,其实依靠的就是broker有一定的消息挤压能力。
kafak的存储
消息的存储是在broker端的log.dir指定目录中,文件结构如下(3.3.1版本):

也就是说,一个partition会独立放在一个文件夹中,
详细的存储格式,介绍的地方就很多了,不过这里的基于日志的存储的经典论文,这里贴一个译本:日志:每个软件工程师都应该知道的有关实时数据的统一抽象
kafka的高性能
不管是哪个系统,来考虑性能,主要的都是这么几个方面:

比如,kafka的高性能、redis的高性能、mysql的高性能,手段机会都是这些。举个栗子:
kafak的高吞吐量最容易被拿出来说的就是基于磁盘还能做到搞吞吐量,其本质无非也是:
- 虽然是基于磁盘,但是存储方式是基于log方式,这样磁盘的写入就可以使用顺序写。
- 虽然是基于磁盘,但是并不是但磁盘,使用partition将压力分担到了多个机器节点。
- 虽然是基于磁盘,在写操作的时候,也是使用了组提交
- 虽然基于磁盘,网络IO的时候,使用了0拷贝、IO多路复用提高IO消息。num.network.threads(默认3)就是用于创建接收网络请求的线程池大小、num.io.threads(默认8)就是用于处理网络请求的线程池大小
附录-kafka demo
官方文档:
启动zookeeper(3.3.1版本可以不依赖zk了,自己使用raft算来来实现集群管理了)
bin/zookeeper-server-start.sh config/zookeeper.properties启动kafka的broker集群:
bin/kafka-server-start.sh config/server.properties创建一个topic(zjj-test-topic就是topic的名称):
bin/kafka-topics.sh --create --topic zjj-test-topic --bootstrap-server localhost:9092连接到zookeeper(可以通过ls来看到zk中放了哪些节点数据)
bin/zookeeper-shell.sh localhost:2181实时查看发送到指定topic的消息(zjj-test-topic就是topic的名称),本质其实是一个消费者组:
bin/kafka-console-consumer.sh --topic zjj-test-topic --from-beginning --bootstrap-server localhost:9092简单的producer示例:
- public static void main(String[] args) {
- String topic = "zjj-test-topic";
-
- Properties properties = new Properties();
- //key.serializer和value.serializer指定key和value序列化操作的序列化器。
- properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
- properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
-
- // producer初始链接的broker节点,多个用逗号隔开
- properties.put("bootstrap.servers", "localhost:9092");
-
- KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
- try {
- System.out.println("send start");
- ProducerRecord<String, String> record = new ProducerRecord<>(topic, "hello, Kafka!");
- Future<RecordMetadata> future = producer.send(record);
- System.out.println("send done。"+future.get());
- } catch (Exception e) {
- e.printStackTrace();
- }
- producer.close();
- }
简单的consumer示例:
- public static void main(String[] args) throws Exception {
- String brokerList = "localhost:9092";
- String topic = "zjj-test-topic";//需要实现创建
- String consumerGroup = "zjj-test-consumer-group";// 不需要创建,kafkaConsumer.subscribe()会去创建且完成订阅关系
-
- Properties properties = new Properties();
- // consumer客户端启动后去链接的broker节点。
- properties.put("bootstrap.servers", brokerList);
- properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
- properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
- //配置消费者组名称,group.id相同的consumer会自动注册到同一个consumerGroup中。
- properties.put("group.id", consumerGroup);
- // 关闭自动提交offset。默认是true(consumer会间隔auto.commit.interval.ms(默认5s)提交一次offset)
- properties.put("enable.auto.commit", false);
-
- // 如果不设置,默认值是read_uncommitted,事务内发送但没有提交的消息也能消费到。如果producer不启用事务,这个参数没有意义
- properties.put("isolation.level", "read_committed");
-
- //创建 kafka 消费者实例
- KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);
- //订阅主题
- kafkaConsumer.subscribe(Collections.singletonList(topic));
-
- System.out.println("consumer start");
- while (true) {
- try {
- // 拉取一批消息到本地。
- final ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.of(1, ChronoUnit.SECONDS));
- System.out.println("poll size=" + records.count());
-
- // 遍历拉取到的消息
- for (ConsumerRecord<String, String> record : records) {
-
- // 消费消息的业务逻辑
- System.out.printf("topic = %s,partition = %d, key = %s, value = %s, offset = %d",
- record.topic(), record.partition(), record.key(), record.value(), record.offset());
- }
-
- // 拉取的消息消费完成后,提交offset。异步提交接口:kafkaConsumer.commitAsync();
- kafkaConsumer.commitSync();
-
- TimeUnit.SECONDS.sleep(5);
- } catch (Exception e) {
- System.out.println("记录下错误,这里不抛出异常,只要offset没有提交,那么下次poll的时候,还会拉过来重新消费。所以需要保证消费逻辑的幂等");
- } finally {
- kafkaConsumer.close();
- }
- }
- }
简单的trasactionProducer示例:
- public static void main(String[] args) throws ExecutionException, InterruptedException {
- String topic = "zjj-test-topic";
-
- Properties properties = new Properties();
- properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
- properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
-
- // producer初始化建立链接的broker节点,多个用逗号隔开
- properties.put("bootstrap.servers", "localhost:9092");
- // producer自己管理的用于标记一个事务的transactionId
- properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "zjjtransacitonid");
- // 开启幂等producer
- properties.put("enable.idempotence ","true");
-
- KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);
-
- // 初始化事务
- producer.initTransactions();
-
- try {
- // 开启事务
- producer.beginTransaction();
-
- // 事务内的发送的多条消息
- ProducerRecord<String, String> record1 = new ProducerRecord<String, String>(topic, "msg1");
- Future<RecordMetadata> metaFuture1 = producer.send(record1);
- System.out.println(metaFuture1.get());
- ProducerRecord<String, String> record2 = new ProducerRecord<String, String>(topic, "msg2");
- Future<RecordMetadata> metaFuture2 = producer.send(record2);
- System.out.println(metaFuture2.get());
- ProducerRecord<String, String> record3 = new ProducerRecord<String, String>(topic, "msg3");
- Future<RecordMetadata> metaFuture3 = producer.send(record3);
- System.out.println(metaFuture3.get());
-
- // 提交事务
- producer.commitTransaction();
- } catch (ProducerFencedException e) {
- // 中止回滚
- producer.abortTransaction();
- }
-
- }

