
- 12022年最新计算机专业毕业设计选题 - 选题推荐 毕设开题 简单易过 题目新颖_基于神经网络的公寓门禁物业管理系统的设计与实现
- 2Sklearn中CountVectorizer,TfidfVectorizer详解_countvectorizer(ngram_range=(1, 1))
- 3国产大模型KimiChat起飞了!200万字内测开启,AI助手能力大提升!_kimichat是国产吗
- 4数据分析之Logistic回归分析中的【多元有序逻辑回归】
- 5专家倡议推迟顶会截稿日期!半数以上国内学者无法参会AAAI!_aaai 截稿延期
- 6中文情感分析之TextCNN_中文textcnn
- 7动手学深度学习——残差网络ResNet(原理解释+代码详解)_resnet中的残差块
- 8ChatBox安装--ChatGPT的桌面客户端_chatbox安装和配置
- 9esp8266_arduino_PIO_wifi实现uint8_t 到 char* ,string类转换_arduino uint8_t转char
- 10评估指标详解:BLEUROUGE与METEOR的原理与实践_bleu rouge meteor
一张照片就能生成3D模型,GAN和自动编码器碰撞出奇迹,苏黎世联邦理工学院出品...
赞
踩
萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
2D图片“脑补”3D模型,这次真的只用一张图就行了——
只需要给AI随便喂一张照片,它就能从不一样的角度给你生成“新视图”:

不仅能搞定360°的椅子和汽车,连人脸也玩出了新花样,从“死亡自拍”角度到仰视图都能生成:

更有意思的是,这只名叫Pix2NeRF的AI,连训练用的数据集都有点“与众不同”,可以在没有3D数据、多视角或相机参数的情况下学会生成新视角。
可以说是又把NeRF系列的AI们卷上了一个新高度。
用GAN+自动编码器学会“脑补”
在此之前,NeRF能通过多视图训练AI模型,来让它学会生成新视角下的3D物体照片。
然而,这也导致一系列采用NeRF方法的模型,包括PixelNeRF和GRF,都需要利用多视图数据集才能训练出比较好的2D生成3D模型效果。
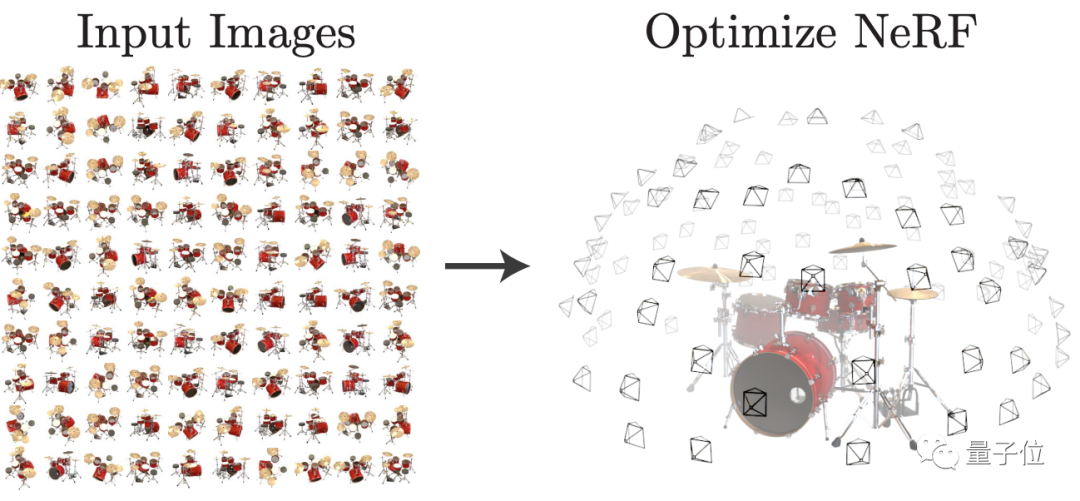
而多视图数据集往往有限,训练时间也比较长。
因此,作者们想出了一个新方法,也就是用自动编码器来提取物体姿态和形状特征,再用GAN直接生成全新的视角图片。
Pix2NeRF包含三种类型的网络架构,即生成网络G,判别网络D和编码器E。
其中,生成网络G和判别网络D组成生成对抗网络GAN,而编码器E和生成网络G用于构成自动编码器:
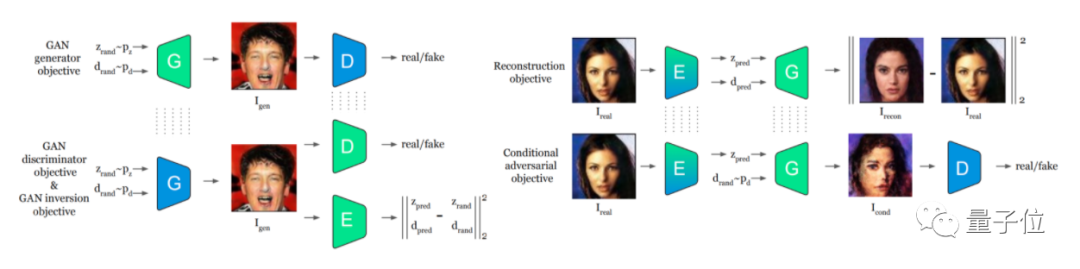
首先,自动编码器可以通过无监督学习,来获取输入图像的隐藏特征,包括物体姿态和物体形状,并利用学习到的特征重建出原始的数据;
然后,再利用GAN来通过姿态和形状数据,重构出与原来的物体形状不同的新视图。
这里研究人员采用了一种叫做π-GAN的结构,生成3D视角照片的效果相比其他类型的GAN更好(作者们还对比了采用HoloGAN的一篇论文):

那么,这样“混搭”出来的AI模型,效果究竟如何?
用糊图也能生成新视角
作者们先是进行了一系列的消融实验,以验证不同的训练方法和模型架构,是否真能提升Pix2NeRF的效果。
例如,针对模型去掉GAN逆映射、自动编码器,或不采用warmup针对学习率进行预热等,再尝试生成新视角的人脸:

其中,GAN逆映射(inversion)的目的是将给定的图像反转回预先训练的GAN模型的潜在空间中,以便生成器从反转代码中重建图像。
实验显示,除了完整模型(full model)以外,去掉各种方法的模型,生成人脸的效果都不够好。
随后,作者们又将生成照片的效果与其他生成新视图的AI模型进行了对比。
结果表明,虽然Pix2NeRF在ShapeNet-SRN的生成效果上没有PixelNeRF好,但效果也比较接近:
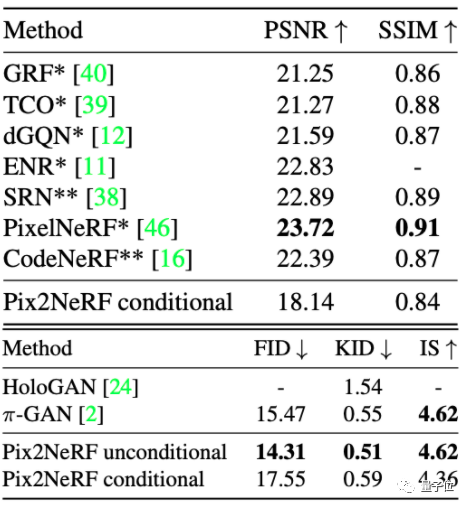
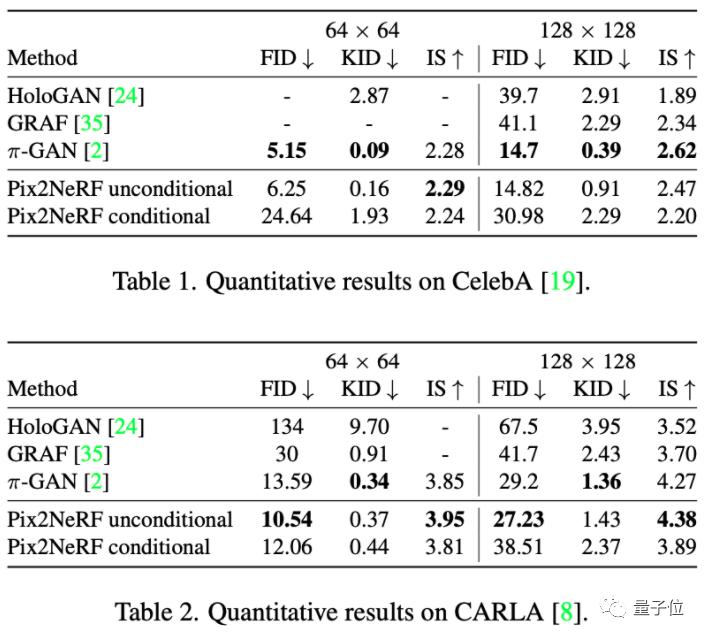
而在CelebA和CARLA数据集上,Pix2NeRF基本都取得了最好的效果。
而且模型还自带一些“美颜”功能,即使是糊图送进去,也能给GAN出更丝滑的轮廓:

整体而言,除了人脸能生成不同角度的新视图以外,物体还能脑补出360°下不同姿态的效果:

看来,AI也和人类一样,学会“脑补”没见过的物体形状了。
作者介绍
这次论文的作者均来自苏黎世联邦理工学院(ETH)。
论文一作Shengqu Cai,ETH硕士研究生,本科毕业于伦敦国王学院,研究方向是神经渲染、生成模型和无监督学习等,高中毕业于辽宁省实验中学。
Anton Obukhov,ETH博士生,此前曾在英伟达等公司工作,研究方向是计算机视觉和机器学习。
Dengxin Dai,马普所高级研究员和ETH(外部)讲师,研究方向是自动驾驶、传感器融合和有限监督下的目标检测。
Luc Van Gool,ETH计算机视觉教授,谷歌学术上的引用量达到15w+,研究方向主要是2D和3D物体识别、机器人视觉和光流等。
目前这项研究的代码还在准备中。

感兴趣的小伙伴可以蹲一波了~
论文地址:
https://arxiv.org/abs/2202.13162
项目地址:
https://github.com/sxyu/pixel-nerf
参考链接:
[1]https://arxiv.org/pdf/2102.03285.pdf
[2]https://arxiv.org/pdf/2012.02190.pdf
[3]https://www.mpi-inf.mpg.de/departments/computer-vision-and-machine-learning
[4]https://www.linkedin.com/in/shengqu-cai-818230185/

