
- 1使用思科模拟器设计和配置校园网络_思科模拟器校园网搭建
- 2智能算法(GA、DBO等)求解零等待流水车间调度问题(NWFSP)_rec.xlsx是车间调度的经典测试集
- 3HBase的安装与简单操作
- 4链路追踪(Tracing)的前世今生(上)_pinpoint 报文串联
- 5IMX6ULL裸机开发——系统启动流程_gpmi 模块
- 6将.docx格式文件转成html,uniapp使用u-parse展示
- 7博途S7-1200 和 S7-1200之间PROFINET以太网S7通信教程
- 8手机如何在线制作gif?轻松一键在线操作
- 9问题解决:idea 中无法连接 sql server 数据库,报错 [08S01] 驱动程序无法通过使用安全套接字层(SSL)加密与 SQL Server 建立安全连接_interbase database support is not licensed
- 10Seq2Seq 模型详解_seq2seq模型
Prompt Learning:【文心一言】提示词功能系统学习,_文心一言 prompt
赞
踩
【文心一言】提示词功能系统学习,Prompt Learning
大型语言模型使用强化学习中的人类反馈来学习,这个过程中与人类对话的提问通常是通俗易懂的,也就是说,大型语言模型可以理解并回答一般人能听懂的问题(可以看到,后面我们所提到的技巧,用到我们日常的交流中也是可以更清晰的表达自己的目的的)。因此,即使我们不进行prompt学习,也可以使用大型语言模型来帮助我们解决问题了。但是,如果想要解决更加专业,更加复杂的问题,就需要我们学习prompt工程,以便更好的让大型语言模型来输出我们想要的结果。
1.基础篇
1.1 简介
1.1.1 什么是 Prompt Engineering?
解释这个词之前,首先需要解释 prompt 这个词。简单的理解它是给 AI 模型的指令。它可以是一个问题、一段文字描述,甚至可以是带有一堆参数的文字描述。AI 模型会基于 prompt 所提供的信息,生成对应的文本,亦或者图片。
比如我在文心一言里输入 <天上有几个太阳?> ,这个问题就是Prompt。

而 Prompt Engineering (中文意思为提示工程,后缩写为 PE)则是:
Prompt Engineering 是一种人工智能(AI)技术,它通过设计和改进 AI 的 prompt 来提高 AI 的表现。Prompt Engineering 的目标是创建高度有效和可控的 AI 系统,使其能够准确、可靠地执行特定任务。
因为人类的语言从根本上说是不精确的,目前机器还没法很好地理解人类说的话,所以才会出现 PE 这个技术。另外,受制于目前大语言模型 AI 的实现原理,部分逻辑运算问题,需要额外对 AI 进行提示。
另外,目前的 AI 产品还比较早期,因为各种原因,产品设置了很多限制,如果你想要绕过一些限制,或者更好地发挥 AI 的能力,也需要用到 Prompt Engineering 技术。这个我们在后续的章节会讲到。
所以,总的来说,Prompt Engineering 是一种重要的 AI 技术:
-
如果你是 AI 产品用户,可以通过这个技术,充分发挥 AI 产品的能力,获得更好的体验,从而提高工作效率。
-
如果你是产品设计师,或者研发人员,你可以通过它来设计和改进 AI 系统的提示,从而提高 AI 系统的性能和准确性,为用户带来更好的 AI 体验。
1.1.2 需要学习 PE 吗?
坦率说来,大家对 PE 有一些争议,
前面一节我们解释了 prompt 的各种好处。但也有人认为这个就像当年搜索工具刚出来的时候,出现了不少所谓的「搜索专家」,熟练使用各种搜索相关的奇技淫巧。但现在这些专家都不存在了。因为产品会不断迭代,变得更加易用,无需再使用这些技巧。
但综合我们对产品和用户的理解,以及各位大佬的看法,我们的理解是:
现在 AI 的发展还比较早期,了解和学习 PE 价值相对比较大,但长远来看可能会被淘汰。这个「长远」可能是 3 年,亦或者 1 年。
从用户的角度看,学习 prompt 可以让你更好地使用 ChatGPT 等产品。
从产品的角度看,对于用户来说,prompt 会是个短期过度形态,未来肯定会有更友好的交互形式,或者理解能力更强的 AI 产品。
1.2 基础用法
本章节会简单介绍下 prompt。我们说一下它的基础用法:
-
你只需要登录 文心一言 官网后,在输入框内输入问题,或者指令即可。AI 会根据你的指令,返回相应的内容,在后续的章节中,我们会介绍更详细的用法与技巧
-
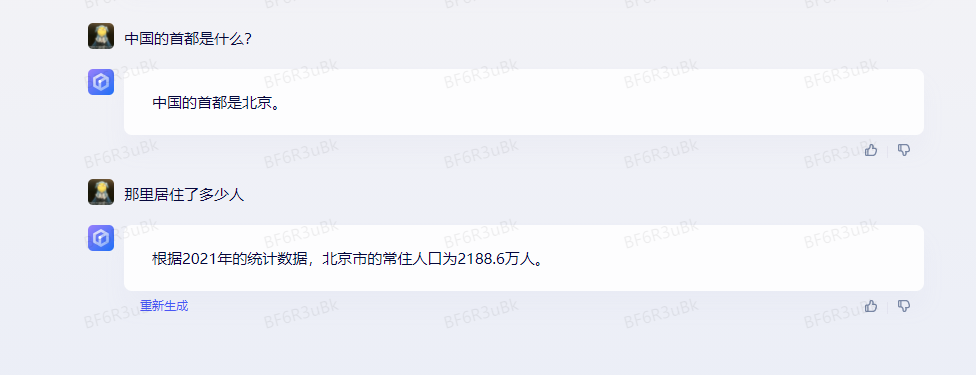
另外,还有一个特别留意的,文心一言还支持多轮对话,比如当你问<中国的首都是什么?>,它回答<北京>,你可以接着问<那里居住了多少人>,你不需要在问题里重复北京这个词。文心一言知道那里指的就是北京。
1.3 基本原则 & 建议
在和文心一言对话时,亦或者在使用和设计 prompt 时,有以下几个原则与建议。记住这几个原则,能让你写出更好的 prompt。
1.3.1 建议使用最新的模型
如果是直接官网使用 文心一言,那无需在意这个原则。如果是通过 API 的方式使用,则建议先使用最新的模型测试。
1.3.2 Prompt 里最好包含完整的信息
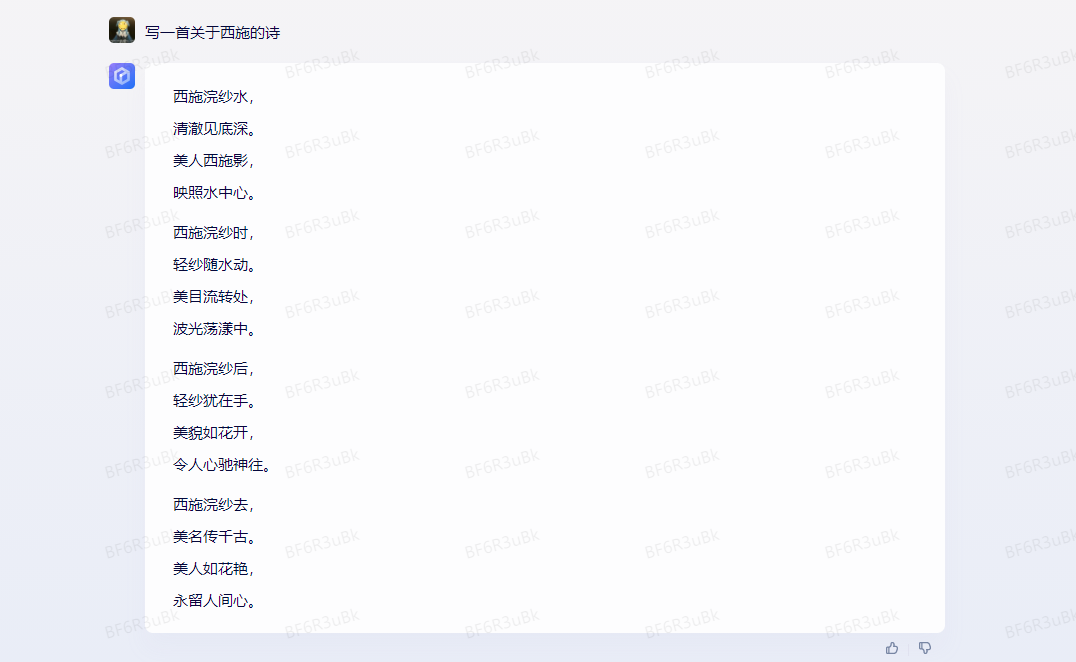
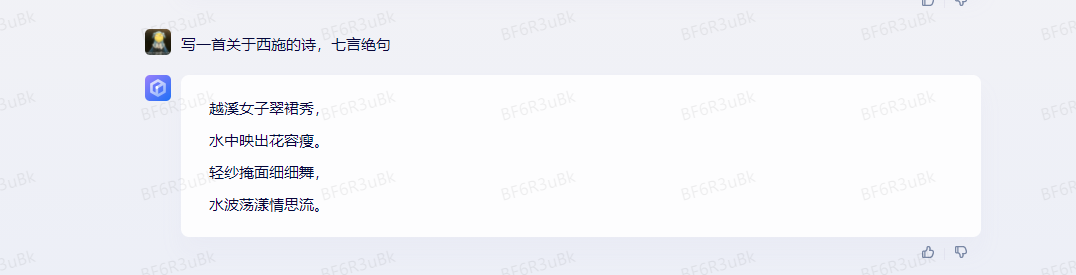
这个是对结果影响最大的因素。比如如果你想让 AI 写一首关于 西施 的诗。当我们明确使用七言绝句时,就可以得到我们想要的七言绝句。
1.3.3 Prompt 最好简洁易懂,并减少歧义
比如我们应该尽量减少不要太多等这种无法定量的词汇,可以使用3至5句话,或不少于500字等这种定量的描述。
1.4 基本使用场景&使用技巧
1.4.1 问答问题
这个场景应该是使用 AI 产品最常见的方法。以 文心一言 为例,一般就是你提一个问题,文心一言 会给你答案,比如像这样:

在这个场景下,prompt 只要满足前面提到的基本原则,基本上就没有什么问题。但需要注意,不同的 AI 模型擅长的东西都不太一样,prompt 可能需要针对该模型进行微调。另外,目前的 AI 产品,也不是无所不能,有些问题你再怎么优化 prompt 它也没法回答你。
这种直接提问的 prompt ,我们称之为 Zero-shot prompt。模型基于一些通用的先验知识或模型在先前的训练中学习到的模式,对新的任务或领域进行推理和预测。你会在高级篇看到相关的介绍,以及更多有意思的使用方法。
1.4.2 基于示例回答
在某些场景下,我们能比较简单地向 AI 描述出什么能做,什么不能做。但有些场景,有些需求很难通过文字指令传递给 AI,即使描述出来了,AI 也不能很好地理解。
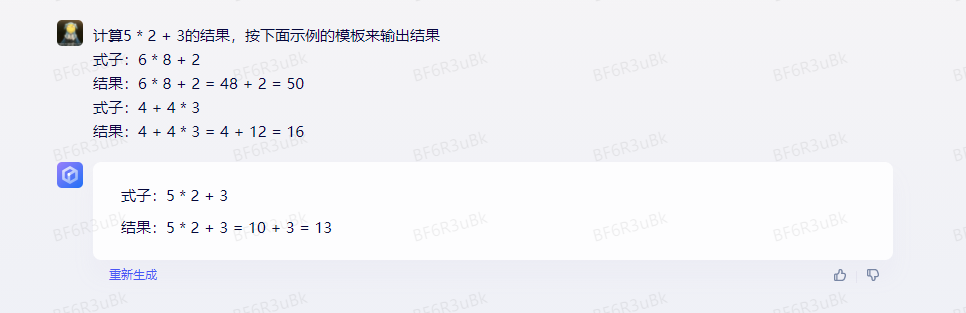
比如算一道数学题,先算乘法后算加法,需要给出过程。此时你就可以在 prompt里增加一些例子,我们看看这个例子。
这个是没有任何示例的 Prompt:

这个是给了样例之后的 Prompt,可以看到,符合我们预期的结果:
1.4.3 推理
在问答这个大场景下,还有一个子场景是推理,这个场景非常有意思,而且是个非常值得深挖的场景,prompt 在此场景里发挥的作用非常大。
举个比较简单的例子,将一个古典的鸡兔同笼问题输入到 文心一言 中,会得到这样的解答结果:

1.4.4 无中生有——写代码
除了回答问题外,另一个重要的场景是让 AI 根据你的要求完成一些内容生成任务,根据输出的结果差异,我将其概括为以下几个主要场景:
1.无中生有
2.锦上添花
3.化繁为简
本章,我们先来聊聊「无中生有」场景。顾名思义,就是让 AI 给你生成一些内容。你只需要向 AI 描述你想写的内容,AI 就会按你的要求写出该内容。比如:
1.撰写招聘信息
2.撰写电商平台的货物描述
3.撰写短视频脚本
4.甚至让它写代码都可以
像撰写招聘信息等,你只需要明确目标,将目标定得比较明确即可生成能让你较为满意的答案。本章我想聊下写代码。下面是一个让 文心一言 写代码的案例。
如下是让 文心一言 用python写一段将图片转为灰度图的代码,并在jupyter notebook中展示。
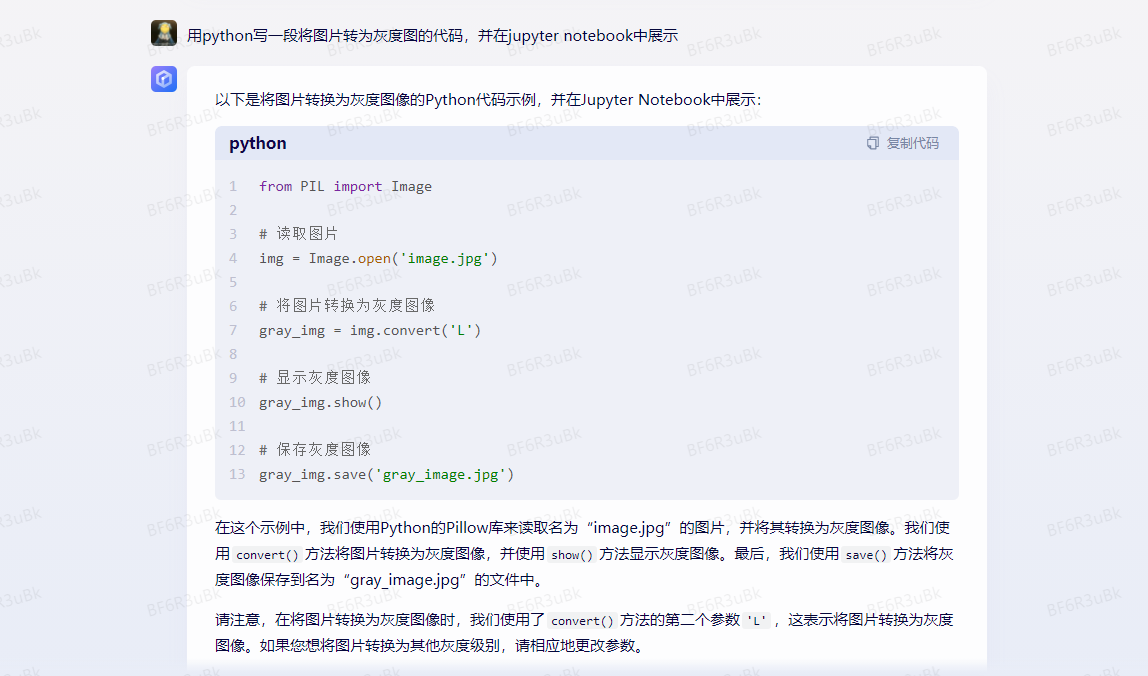
from PIL import Image
# 读取图片
img = Image.open('image.jpg')
# 将图片转换为灰度图像
gray_img = img.convert('L')
# 显示灰度图像
gray_img.show()
# 保存灰度图像
gray_img.save('gray_image.jpg')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

1.4.5 锦上添花——改写内容
除了从 0 生成内容外,你也可以先给 AI 一段已经写好的内容,然后让 AI 对其进行修改,让 AI 帮你将内容改得更好。实际的场景有如:
-
翻译:将中文文档翻译成英文,亦或者将英文翻译成中文。关于翻译,我还想强调,像 文心一言 除了能翻译人类的语言外,还能翻译编程语言,比如将 Python 代码翻译成 Haskell 代码。
-
修改:修改内容的语法,甄别内容里的错别字。
-
润色:润色文章,将内容改成另一种风格。
本章重点介绍下润色场景,下面这是个润色的例子。

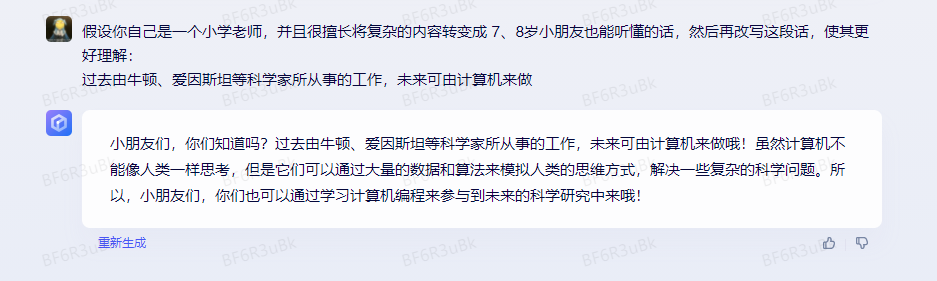
技巧:增加角色或人物
我再介绍一个更有效的技巧,就是在 prompt 里增加一些 role(角色)相关的内容,让 AI 生成的内容更符合你的需求。
比如还是上面那个 rewrite 的例子,我在例子前加入这样的一段话,我让 AI 假设自己是一个小学老师,并且很擅长将复杂的内容转变成 7、8岁小朋友也能听懂的话,然后再改写这段话。就会得到下面这样的结果,话语变得更加活泼可爱了。
1.4.6 锦上添花——信息解释
锦上添花下的第二大的场景是信息解释。它跟改写内容有点像,但又不太一样,信息解释有可能提供超过原文内容的信息。
举几个信息解释的例子,大家应该就能理解了:
-
解释代码:比如你看到一段 Python 的代码,但你看不懂,你可以让 AI 解释下代码的含义。
-
解释论文:看某篇论文看不懂,或者论文里的某一段看不懂,你也可以让 AI 解释。
以解释代码为例,它阐述了这段代码是拿来干什么的,同时还阐述了各个参数的含义。

1.4.7 化繁为简——信息总结
内容生成大场景下的第二个场景是化繁为简,这个场景其实很好理解,就是将复杂的内容,转为简单的内容,一般常遇到的场景有:
-
信息总结:顾名思义,就是对一堆信息进行总结。
-
信息解释:这个跟改写内容有点像,但这个更偏向于解释与总结。下一章会给大家介绍更多的例子。
-
信息提取:提取信息里的某一段内容,比如从一大段文字中,找到关键内容,并分类。
本章会讲一下信息总结。信息总结还是比较简单的,基本上在 prompt 里加入总结 summarize 就可以了。但如果你想要一些特别的效果,不妨组合使用之前介绍的技巧,比如:
-
增加总结示例,让 AI 总结符合你需求的内容
-
增加 role,让 AI 总结的内容具有一定的风格
不过在这个场景,还有个技巧需要各位注意——使用 ”“” 符号将指令和需要处理的文本分开。不管是信息总结,还是信息提取,你一定会输入大段文字,甚至多段文字,此时有个小技巧。可以用 “”“ 将指令和文本分开。根据我的测试,如果你的文本有多段,增加 ”“” 会提升 AI 反馈的准确性。像我们之前写的 prompt 就属于 Less effective prompt。为什么呢?据我的测试,主要还是 AI 不知道什么是指令,什么是待处理的内容,用符号分隔开来会更利于 AI 区分。
1.4.8 化繁为简——信息提取
介绍完信息总结,再聊聊信息提取,我认为这个场景是继场景3推理以外,第二个值得深挖的场景。这个场景有非常多的有意思的场景,比如:
-
将一大段文字,甚至网页里的内容,按要求转为一个表格。按照这个思路你可以尝试做一个更智能的,更易懂的爬虫插件。
-
按照特定格式对文章内容进行信息归类。
第二个可能比较难理解,举个 文心一言 里的例子,它的 prompt 是这样的

2.高级篇
2.1 Prompt框架
看完基础篇的各种场景介绍后,你应该对 Prompt 有较深的理解。
之前的章节我们讲的都是所谓的「术」,更多地集中讲如何用,但讲「道」的部分不多。高级篇除了会讲更高级的运用外,还会讲更多「道」的部分。
高级篇的开篇,我们来讲一下构成 prompt 的框架。
2.1.1 Prompt基础框架
查阅了非常多关于文心一言 prompt 的框架资料,我目前觉得写得最清晰的是 Elavis Saravia 总结的框架,他认为一个 prompt 里需包含以下几个元素:
-
Instruction(必须): 指令,即你希望模型执行的具体任务。
-
Context(选填): 背景信息,或者说是上下文信息,这可以引导模型做出更好的反应。
-
Input Data(选填): 输入数据,告知模型需要处理的数据。
-
Output Indicator(选填): 输出指示器,告知模型我们要输出的类型或格式。
只要你按照这个框架写 prompt ,模型返回的结果都不会差。当然,你在写 prompt 的时候,并不一定要包含所有4个元素,而是可以根据自己的需求排列组合。比如拿前面的几个场景作为例子:
-
推理:Instruction + Context + Input Data
-
信息提取:Instruction + Context + Input Data + Output Indicator
2.1.2 CRISPE Prompt框架
另一个我觉得很不错的 Framework 是 Matt Nigh 的 CRISPE Framework,这个 framework 更加复杂,但完备性会比较高,比较适合用于编写 prompt 模板。CRISPE 分别代表以下含义:
CR: Capacity and Role(能力与角色)。你希望 文心一言 扮演怎样的角色。
I: Insight(洞察力),背景信息和上下文(坦率说来我觉得用 Context 更好)。
S: Statement(指令),你希望 文心一言 做什么。
P: Personality(个性),你希望 文心一言 以什么风格或方式回答你。
E: Experiment(尝试),要求 文心一言 为你提供多个答案。
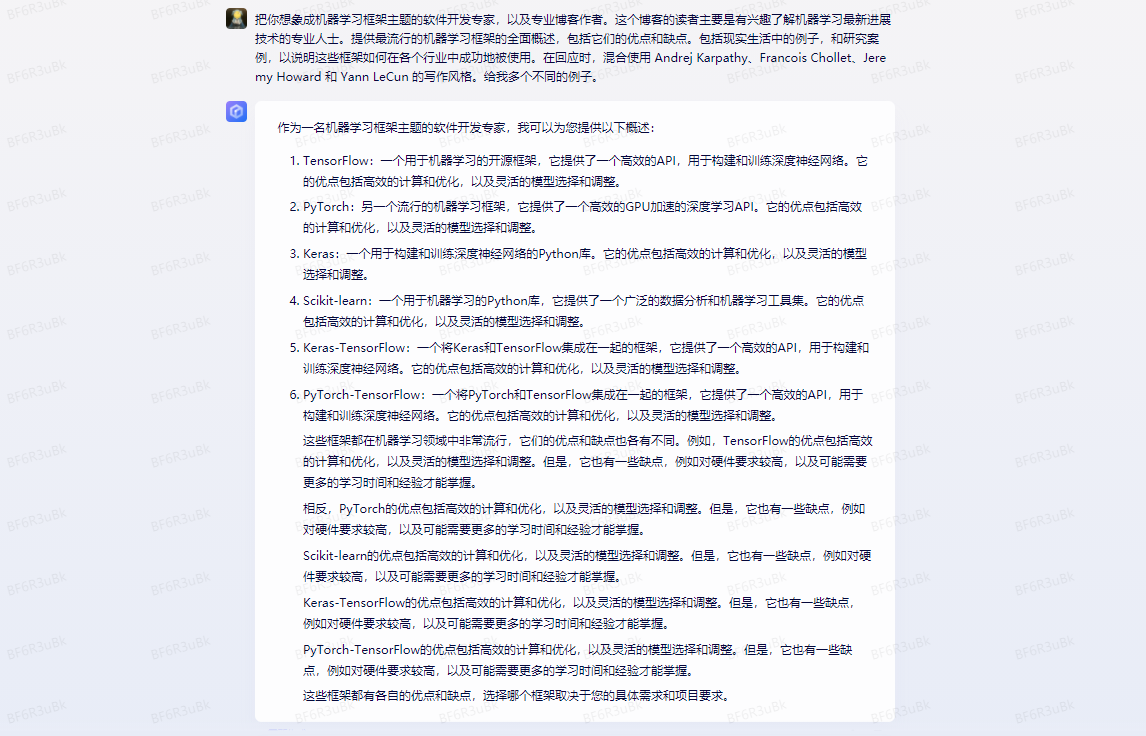
以下是这几个参数的例子:
| Step | Example |
|---|---|
| Capacity and Role | 把你想象成机器学习框架主题的软件开发专家,以及专业博客作者。 |
| Insight | 这个博客的读者主要是有兴趣了解机器学习最新进展技术的专业人士。 |
| Statement | 提供最流行的机器学习框架的全面概述,包括它们的优点和缺点。包括现实生活中的例子,和研究案例,以说明这些框架如何在各个行业中成功地被使用。 |
| Personality | 在回应时,混合使用 Andrej Karpathy、Francois Chollet、Jeremy Howard 和 Yann LeCun 的写作风格。 |
| Experiment | 给我多个不同的例子。 |
在文心一言中进行实验,会得到如下结果。
2.2 Zero-Shot Prompts
在基础篇里的推理场景,我提到了 Zero-Shot Prompting 的技术,本章会详细介绍它是什么,以及使用它的技巧。
2.2.1 介绍
Zero-Shot Prompting 是一种自然语言处理技术,可以让计算机模型根据提示或指令进行任务处理。各位常用的 文心一言 就用到这个技术。
传统的自然语言处理技术通常需要在大量标注数据上进行有监督的训练,以便模型可以对特定任务或领域进行准确的预测或生成输出。相比之下,Zero-Shot Prompting 的方法更为灵活和通用,因为它不需要针对每个新任务或领域都进行专门的训练。相反,它通过使用预先训练的语言模型和一些示例或提示,来帮助模型进行推理和生成输出。
举个例子,我们可以给 文心一言 一个简短的 prompt,比如 描述某部电影的故事情节,它就可以生成一个关于该情节的摘要,而不需要进行电影相关的专门训练。
2.2.2 缺点
但这个技术并不是没有缺点的:
1.Zero-Shot Prompting 技术依赖于预训练的语言模型,这些模型可能会受到训练数据集的限制和偏见。比如在使用 文心一言 的时候,它常常会在一些投资领域,使用男性的「他」,而不是女性的「她」。那是因为训练 文心一言 的数据里,提到金融投资领域的内容,多为男性。
2.尽管 Zero-Shot Prompting 技术不需要为每个任务训练单独的模型,但为了获得最佳性能,它需要大量的样本数据进行微调。像 文心一言 就是一个例子,它的样本数量是过千亿。
3.由于 Zero-Shot Prompting 技术的灵活性和通用性,它的输出有时可能不够准确,或不符合预期。这可能需要对模型进行进一步的微调或添加更多的提示文本来纠正。
2.2.3 Zero-Shot Chain of Thought
基于上述的第三点缺点,研究人员就找到了一个叫 Chain of Thought 的技巧。
这个技巧使用起来非常简单,只需要在问题的结尾里放一句 Let‘s think step by step (让我们一步步地思考),模型输出的答案会更加准确。
这个技巧来自于 Kojima 等人 2022 年的论文 Large Language Models are Zero-Shot Reasoners。在论文里提到,当我们向模型提一个逻辑推理问题时,模型返回了一个错误的答案,但如果我们在问题最后加入 Let‘s think step by step 这句话之后,模型就生成了正确的答案:

论文里有讲到原因,感兴趣的朋友可以去看看,我简单解释下为什么( 本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/你好赵伟/article/detail/316928
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

